如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
Apache Rya 是一个基于云的大数据三元组存储(subject-predicate-object)数据库,并提供毫秒级别响应查询时间。这个项目是由 The Laboratory for Telecommunication Sciences(美国的马里兰大学)开发,并于2015年09月进入提交给 Apache 孵化器,2019年09月24日 Apache 基金会正式宣布其成为 Apache 顶级项目。
Apache Rya 主要是用于存储 RDF 的数据,RDF 是 Resource Description Framework 的简写,即资源描述框架,其本质是一个数据模型(Data Model)。它提供了一个统一的标准,用于描述实体/资源。简单来说,就是表示事物的一种方法和手段。RDF 形式上表示为 SPO(subject-predicate-object)三元组,有时候也称为一条语句(statement),知识图谱中也称其为一条知识。
Apache Rya 是一个可伸缩的 RDF 数据管理系统,构建在 Apache Accumulo 之上。同时还实现了 MongoDB 后端。Rya 使用了新颖的存储方法、索引方案和查询处理技术,可以跨多个节点扩展到数十亿个三元组。Apache Rya 通过 SPARQL (一种用于RDF数据的传统查询机制)提供了对数据的快速、轻松的访问。
更多关于 Apache Rya 的介绍可以参见 http://rya.apache.org/。
Apache SINGA 是一个通用的分布式深度学习平台,面向训练大规模数据集上的大型深度学习模型。该项目最初于2014年在新加坡国立大学开发,并于2015年3月提交给 Apache 孵化器,2019年10月16日 Apache 基金会正式宣布其成为 Apache 顶级项目。
Apache SINGA 设计基于一种直观的编程模型,即深度学习中层(layer)的抽象。Apache SINGA 支持大部分深度学习模型,包括卷积神经网络(CNN)、受限波尔兹曼模型(RBM)和循环神经网络(RNN)等,为用户提供许多可直接使用的内建层。Apache SINGA 架构灵活,支持同步训练、异步训练和混合式训练。为了并行地训练深度学习模型,SINGA支持不同的神经网络划分机制,即批次维度划分(batch dimension partition),特征维度划分(feature dimension partition)和多维度混合划分(hybrid partition)。
作为一个分布式系统,Apache SINGA 的首要目标就是具有良好的可扩展性。换言之,Apache SINGA 希望在准确度一定的情况下,通过利用更多的计算资源(即计算机)减少模型的训练时间。
Apache SINGA 的另一个目标是易用性。对程序员来说,开发和训练深层的复杂结构的深度学习模型十分困难。分布式训练又进一步增加了程序员的负担,比如:数据和模型划分,网络通信等。因此,提供一个易用的编程模型是十分重要的,可以让程序员在实现自己的深度学习模型和算法时不必考虑底层的分布式平台。
更多关于 Apache SINGA 的介绍可以参见 http://singa.apache.org/
Apache Hudi(Hoodie) 是 Uber 为了解决大数据生态系统中需要插入更新及增量消费原语的摄取管道和 ETL 管道的低效问题,该项目在2016年开始开发,并于2017年开源,2019年1月进入 Apache 孵化器。
Hudi (Hadoop Upsert Delete and Incremental) 是一种分析和扫描优化的数据存储抽象,可在几分钟之内将变更应用于 HDFS 中的数据集中,并支持多个增量处理系统处理数据。通过自定义的 InputFormat 与当前 Hadoop 生态系统(包括 Apache Hive、Apache Parquet、Presto 和 Apache Spark)集成,使得该框架对最终用户来说是无缝的。
Hudi 的设计目标就是为了快速增量更新 HDFS 上的数据集,它提供了两种更新数据的方式:Copy On Write 和 Merge On Read。Copy On Write 模式就是我们更新数据的时候需要通过索引获取更新的数据所涉及的文件,然后把这些数据读出来和更新的数据进行合并,这种模式更新数据比较简单,但是当更新涉及到的数据比较大时,效率非常低;而 Merge On Read 就是将更新写到单独的新文件里面,然后我们可以选择同步或异步将更新的数据和原来的数据进行合并(可以称为 combination),因为更新的时候只写新的文件,所以这种模式更新的速度会比较快。
有了 Hudi 之后,我们可以实时采集 MySQL、HBase、Cassandra 里面的增量数据然后写到 Hudi 中,然后 Presto、Spark、Hive 可以很快地读取到这些增量更新的数据,如下:
更多关于 Apache Hudi 的介绍可以参见过往记忆大数据的 《Apache Hudi: Uber 开源的大数据增量处理框架》 以及 《Uber 大数据平台的演进(2014~2019)》的介绍,以及 Apache Hudi 的官方文档:http://hudi.apache.org/
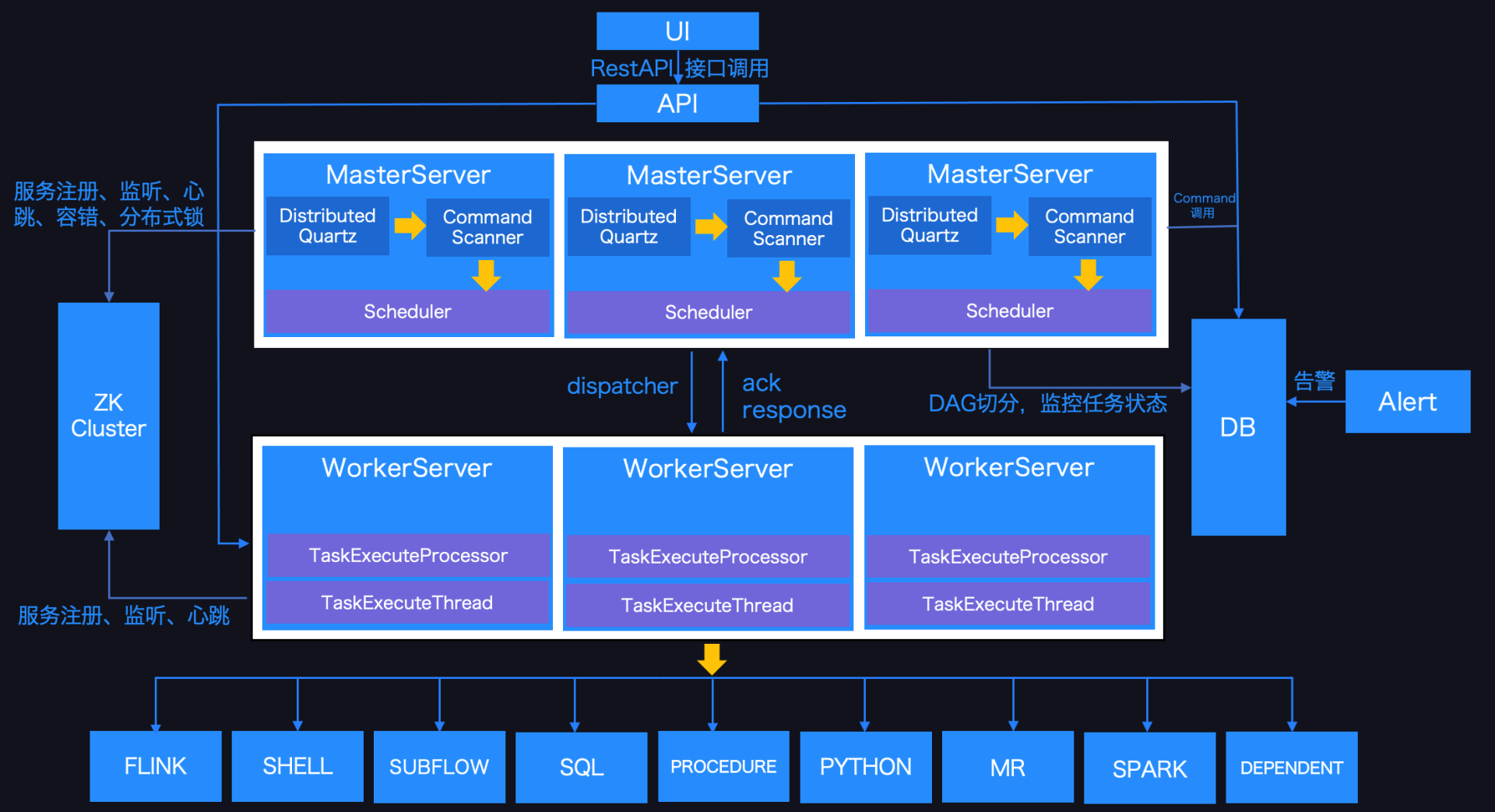
Apache DolphinScheduler 是一个分布式易扩展的可视化 DAG 工作流任务调度系统,致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。Apache DolphinScheduler 是由易观平台自主研发的大数据分布式调度系统,之前称为 Easy Scheduler,于2019年03月28日正式开源,2019年08月29日进入 Apache 孵化器。Apache DolphinScheduler 的主要目标如下:
Master/Worker cpu load,memory,cpu在线查看Apache DolphinScheduler 的架构如下:
其由如下几个模块组成
可以看出,Apache DolphinScheduler 和前面介绍的 Apache Airflow 功能有点类似,两者之间的详细区别请参见 https://dolphinscheduler.apache.org/ 这里就不详细介绍了。
TubeMQ 是腾讯在 2013 年自研的分布式消息中间件系统,专注服务大数据场景下海量数据的高性能存储和传输,经过近7年上万亿的海量数据沉淀,目前日均接入量超过25万亿条。较之于众多明星的开源MQ组件,TubeMQ 在海量实践(稳定性+性能)和低成本方面有着比较好的核心优势。该项目于 2019年11月03日正式进入 Apache 孵化器。
TubeMQ 系统架构思想源于Apache Kafka。在实现上,则完全采取自适应的方式,结合实战做了很多优化及研发工作,如分区管理、分配机制和全新节点通讯流程,自主开发高性能的底层RPC通讯模块等。 这些实现使得TubeMQ在保证实时性和一致性的前提下,具有很好的健壮性及更高的吞吐能力。
TubeMQ 非常适用于高并发、海量数据并允许在异常情况下少量数据丢失的场景,如海量日志采集、指标统计、监控等。TubeMQ 不适用于那些对数据可靠性要求非常严格的场景。
与其他消息队列系统一样,TubeMQ 也是基于发布-订阅模式构建的。也就是生产者将消息发布到主题,而消费者订阅这些主题。消费者处理完消息后,将给生产者发送确认。TubeMQ 的总体架构如下:
从上图可以看出,TubeMQ 总共由五个模块组成:
更多关于 Apache TubeMQ 的信息请参见 https://github.com/Tencent/TubeMQ
本博客文章除特别声明,全部都是原创!