CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。 当前,CarbonData暂不支持修改表中已经存在的数据。但是在现实情况下,我们可能很希望这个功能,比如修改 w397090770 8年前 (2016-11-30) 2779℃ 0评论10喜欢
在《Spark读取Hbase中的数据》文章中我介绍了如何在Spark中读取Hbase中的数据,并提供了Java和Scala两个版本的实现,本文将接着上文介绍如何通过Spark将计算好的数据存储到Hbase中。 Spark中内置提供了两个方法可以将数据写入到Hbase:(1)、saveAsHadoopDataset;(2)、saveAsNewAPIHadoopDataset,它们的官方介绍分别如下: saveAsHad w397090770 8年前 (2016-11-29) 17846℃ 1评论29喜欢
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据。我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等。但是这些方式不是慢就是在导入的过程的占用Region资源导致效率低下,所以很不适合一次性导入大量数据。本文将针对这个问题介绍如何通过Hbase的BulkLoad方法来快速将海量数据导入到Hbas w397090770 8年前 (2016-11-28) 17636℃ 2评论52喜欢
Apache Flink开源大数据处理系统最近比较火,特别是其流处理框架的设计。本文并不打算介绍Apache Flink的相关概念,如果你感兴趣可以到本博客的Flink分类目录查看Flink的相关文章。 转入正题了,下面将一步一步教你如何提交你的代码到Flink社区。1、提交Issue 既然能够提交代码肯定是发现了什么Bug,或者有什么好 w397090770 8年前 (2016-11-21) 3343℃ 0评论4喜欢
本书作者Venkat Ankam,由Packt Publishing出版社在2016年09月发行,全书供326页。本书基于Spark 2.0和Hadoop 2.7版本介绍,是适合数据分析师和数据科学家的参考手册,当然也适合那些想入门的人。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[code lang="bash"]Chapter 1: Big Data Analytics at a 10 zz~~ 8年前 (2016-11-21) 4585℃ 0评论6喜欢
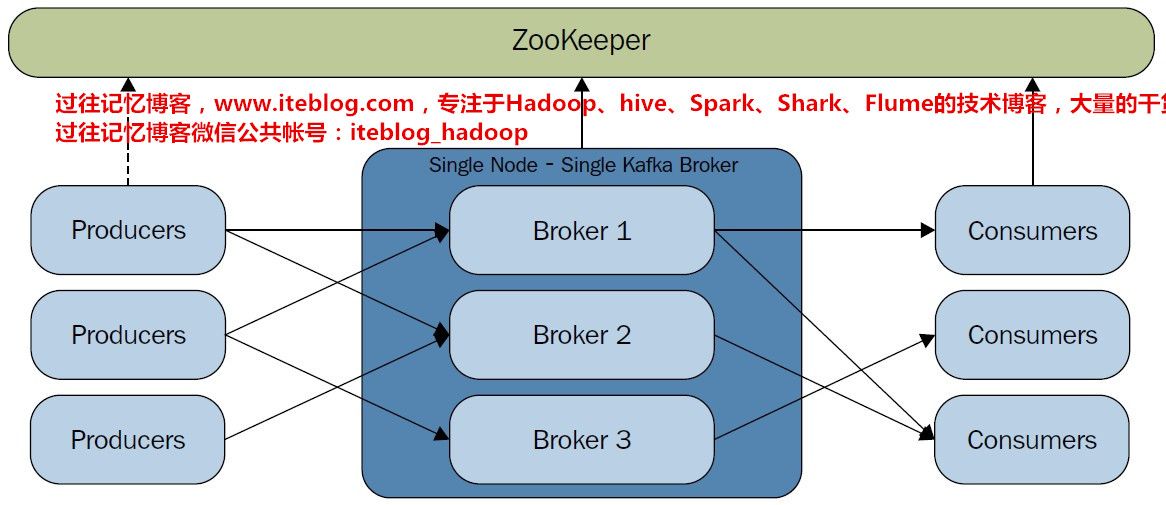
Kafka Cluster模式最大的优点:可扩展性和容错性,下图是关于Kafka集群的结构图:Kafka Broker个数决定因素 磁盘容量:首先考虑的是所需保存的消息所占用的总磁盘容量和每个broker所能提供的磁盘空间。如果Kafka集群需要保留 10 TB数据,单个broker能存储 2 TB,那么我们需要的最小Kafka集群大小 5 个broker。此外,如果启用副 w397090770 8年前 (2016-11-18) 13554℃ 0评论28喜欢
流式处理是大数据应用中的非常重要的一环,在Spark中Spark Streaming利用Spark的高效框架提供了基于micro-batch的流式处理框架,并在RDD之上抽象了流式操作API DStream供用户使用。 随着流式处理需求的复杂化,用户希望在流式数据中引入较为复杂的查询和分析,传统的DStream API想要实现相应的功能就变得较为复杂,同时随着Spark w397090770 8年前 (2016-11-16) 6086℃ 0评论13喜欢
我在《使用Hive读取ElasticSearch中的数据》文章中介绍了如何使用Hive读取ElasticSearch中的数据,本文将接着上文继续介绍如何使用Hive将数据写入到ElasticSearch中。在使用前同样需要加入 elasticsearch-hadoop-2.3.4.jar 依赖,具体请参见前文介绍。我们先在Hive里面建个名为iteblog的表,如下:[code lang="sql"]CREATE EXTERNAL TABLE iteblog ( id b w397090770 8年前 (2016-11-07) 19836℃ 1评论24喜欢
Spark Summit 2016 Europe会议于2016年10月25日至10月27日在布鲁塞尔进行。本次会议有上百位Speaker,来自业界顶级的公司。官方日程:https://spark-summit.org/eu-2016/schedule/。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料 w397090770 8年前 (2016-11-06) 3041℃ 0评论1喜欢
2016中国架构师大会大数据专场于10月27日在京进行,大数据专场有来自搜狐、优酷介绍其视频个性化推荐架构设计;也有来自饿了么的实时架构演变;有来自Qunar、宜信以及广发证券再金融中应用大数据的架构设计;也有华为CarbonData的介绍,干货十足!值得一看。主要涉及如下主题: 10月27 w397090770 8年前 (2016-11-03) 4639℃ 0评论9喜欢

![通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]](https://www.iteblog.com/pic/hbase_Bulkload_iteblog.png)

![[电子书]Big Data Analytics pdf下载](https://www.iteblog.com/pic/big-data-analytics-iteblog.jpg)


![Spark Summit 2016 Europe全部PPT下载[共75个]](https://www.iteblog.com/pic/iteblog.png)
