Apache Hudi : 未来发展
Apache Hudi 是如何处理小文件的
Apache Hudi 0.8.0 版本发布,Flink 集成有重大提升以及支持并行写
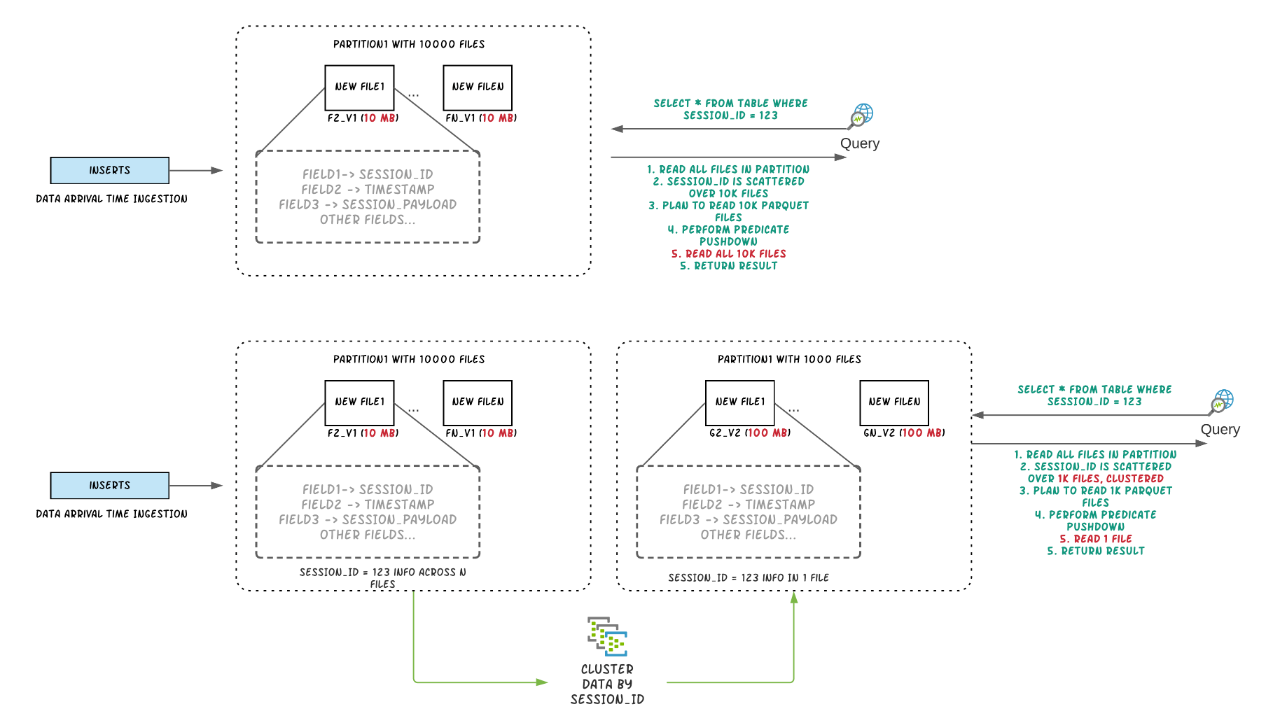
Apache Hudi Clustering 数据布局功能介绍
盘点2020年晋升为Apache TLP的大数据相关项目
Apache Hudi 现在也支持 Flink 引擎了
Apache Hudi 0.6.0 版本发布,新功能介绍
官宣,Apache Hudi 正式成为 Apache 顶级项目
下面文章您可能感兴趣
Apache Kafka
HBase 工程中 protobuf 版本冲突解决
Hadoop YARN中web服务的REST API介绍
[电子书]Mastering Elasticsearch 5.x - Third Edition PDF下载
使用 Python 编写 Hive UDF 环境问题
腾讯看点基于 Flink 构建万亿数据量下的实时数仓及实时查询系统
深入理解 Apache Spark Delta Lake 的事务日志
通过 Alluxio 来加速 Uber 的 Presto 集群
Hadoop面试题系列(4/11)
JVM体系结构解释
OpenTSDB 之 HBase的数据模型
Apache Spark 2.4 正式发布,重要功能详细介绍
[电子书]Spark Cookbook PDF下载
Guava学习之Splitter
Apache Iceberg 中三种操作表的方式
一条 SQL 在 Apache Spark 之旅(下)
Scala模式匹配和函数组合
Apache Spark 2.4 新增内置函数和高阶函数使用介绍
三种方法实现Hadoop(MapReduce)全局排序(1)
Uber 如何在 Apache Parquet 中使用 ZSTD 压缩减少大量存储空间实践
发表我的评论
取消评论
提交评论
有人回复时邮件通知我
表情
本博客评论系统带有自动识别垃圾评论功能,请写一些有意义的评论,谢谢!
有人回复时邮件通知我
使用微博登录
使用GitHub登录
使用QQ登录