
Alluxio Local Cache 加速 Presto 查询在 Uber 的应用
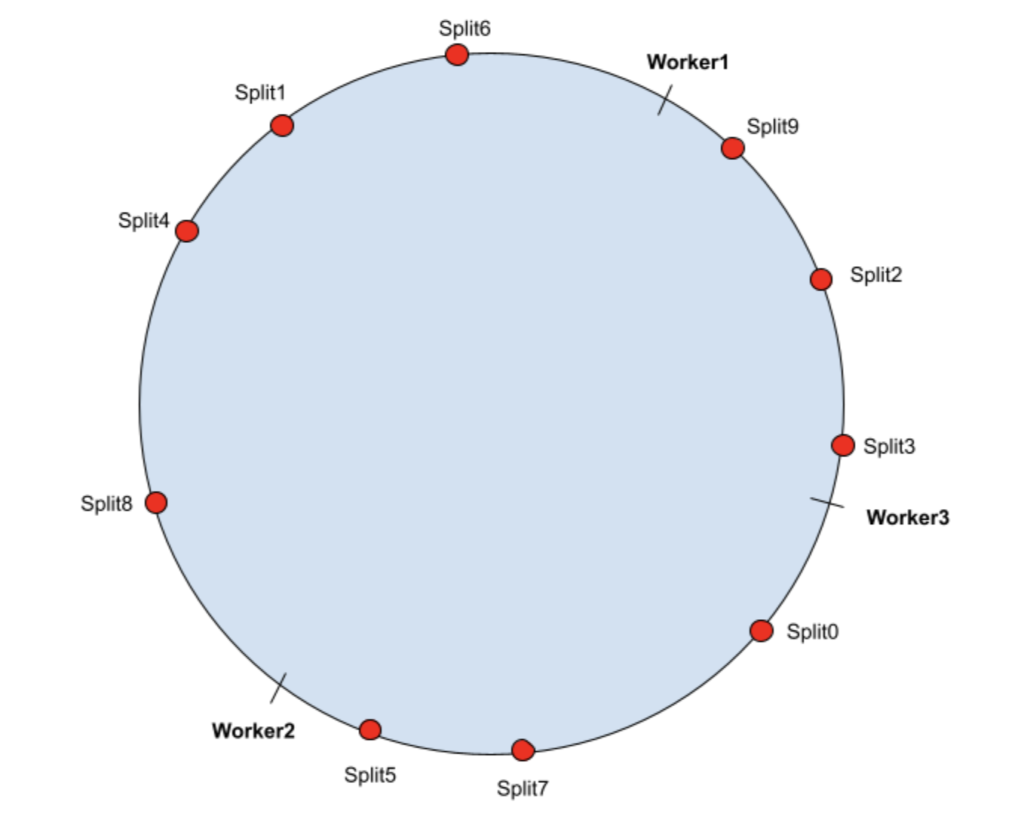
在 Presto 中使用一致性哈希来改善动态集群的缓存命中率

Alluxio 对 Presto 的查询性能加速测试报告

Presto Alluxio Local Cache 监控指南

通过 Alluxio 来加速 Uber 的 Presto 集群

RaptorX: 将 Presto 性能提升十倍

在 Presto Iceberg 数据源上使用 Alluxio 缓存

使用 Shadow Cache 改进 Presto 架构决策在 Facebook 的实践
下面文章您可能感兴趣