在默认情况下,Wordpress是不带有博客访问或者是博文的访问次数的,这对于某些人(比如我)来说是很不喜欢的,我想统计一下我博客或者博文到底被人家看了多少次。如下图所示: 在前面的两篇博文中(为WordPress的suffusion主题添加文章浏览次数,怎么给wordPress3.5.1添加文章统计)谈到了如何给博文添加访客浏览记录。 w397090770 12年前 (2013-04-30) 7945℃ 2评论9喜欢
Suffusion 是一款功能十分强大的免费WordPress主题,可以对样式模板、整体框架、内容调用进行自定义设置。本文主要来分享一下如何给文章添加统计次数。 安装WP-PostViews插件,这个是用来统计文章浏览次数的。 依次选择 外观-->编辑-->post-header.php 在里面找到[code lang="CPP"]<span class="comments">[/code] 可以 w397090770 12年前 (2013-04-20) 3519℃ 0评论5喜欢
为了提高 HBase 存储的利用率,很多 HBase 使用者会对 HBase 表中的数据进行压缩。目前 HBase 可以支持的压缩方式有 GZ(GZIP)、LZO、LZ4 以及 Snappy。它们之间的区别如下:GZ:用于冷数据压缩,与 Snappy 和 LZO 相比,GZIP 的压缩率更高,但是更消耗 CPU,解压/压缩速度更慢。Snappy 和 LZO:用于热数据压缩,占用 CPU 少,解压/压缩速度比 w397090770 8年前 (2017-02-09) 1954℃ 0评论1喜欢
和其他大数据系统类似,Flink 内置也提供 metric system 供我们监控 Flink 程序的运行情况,包括了JobManager、TaskManager、Job、Task以及Operator等组件的运行情况,大大方便我们调试监控我们的程序。系统提供的一些监控指标名字有下面几个: metrics.scope.jm 默认值: <host>.jobmanager job manager范围内的所有metrics将会使用这 w397090770 7年前 (2017-08-01) 3118℃ 0评论6喜欢
从上周开始,我博客就经常出现了Bad Request (Invalid Hostname)错误,询问网站服务器商只得知网站的并发过高,从而被服务器商限制网站访问。可是我天天都会去看网站的流量统计,没有一点异常,怎么可能会并发过高?后来我查看了一下网站的搜索引擎抓取网站的日志,发现每分钟都有大量的页面被搜索引擎抓取!难怪网站的并 w397090770 10年前 (2014-11-14) 3193℃ 0评论6喜欢
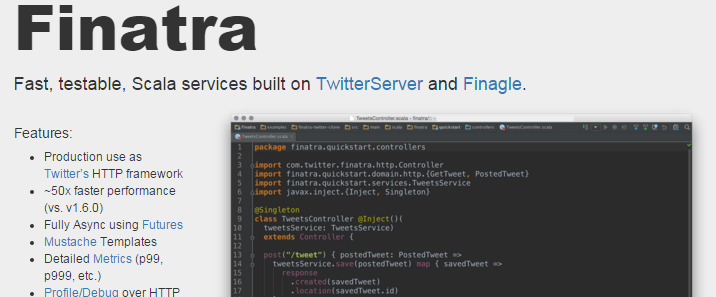
Finatra Finatra是一款基于TwitterServer和Finagle的快速、可测试的Scala异步框架。Finatra is a fast, testable, Scala services built on TwitterServer and Finagle.Play Play是一款轻量级、无状态的WEB友好框架。使用Java和Scala可以很方便地创建web应用程序。Play is based on a lightweight, stateless, web-friendly architecture.Play Framework makes it easy to build web application w397090770 9年前 (2015-12-25) 12562℃ 0评论15喜欢
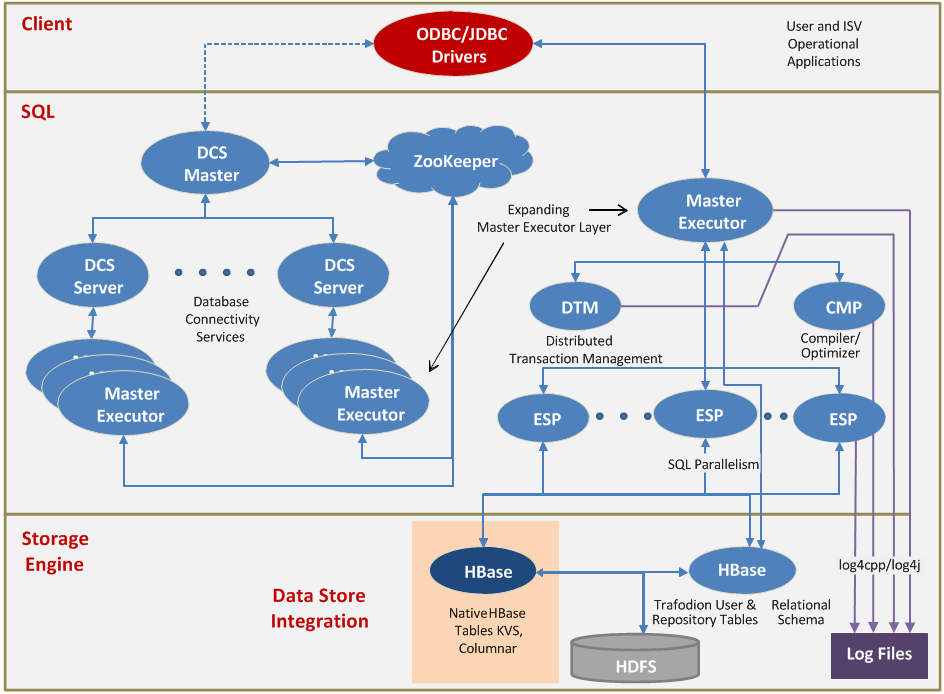
Apache Trafodion 是由惠普开发并开源的基于 Hadoop 平台的事务数据库引擎。提供了一个基于Hadoop平台的交易型SQL引擎。它是一个擅长处理交易型负载的Hadoop大数据解决方案。其主要特性包括:完整的ANSI SQL语言支持完整的ACID事务支持。对于读、写查询,Trafodion支持跨行,跨表和跨语句的事务保护支持多种异构存储引擎的直接访问为应 w397090770 7年前 (2018-01-07) 2360℃ 0评论5喜欢
今天由于某些原因需要卸载掉服务器上的php软件,然后我使用下面命令显示出本机安装的所有和php相关的软件,如下:[code lang="bash"]iteblog$ rpm -qa | grep phpphp-mysqlnd-5.6.25-0.1.RC1.el6.remi.x86_64php-fpm-5.6.25-0.1.RC1.el6.remi.x86_64php-pecl-jsonc-1.3.10-1.el6.remi.5.6.x86_64php-pecl-memcache-3.0.8-3.el6.remi.5.6.x86_64php-pdo-5.6.25-0.1.RC1.el6.remi.x86_64php-mbstrin w397090770 8年前 (2016-08-08) 2286℃ 0评论2喜欢
Starburst provides connectors to the most popular data sources included in many of these connectors are a number of exclusive enhancements. Many of Starburst’s connectors when compared with open source Trino have enhanced extensions such as parallelism, pushdown and table statistics, that drastically improve the overall performance. Parallelism distributes query processing across workers, and uses many connections to the data source a w397090770 2年前 (2022-04-15) 595℃ 0评论0喜欢
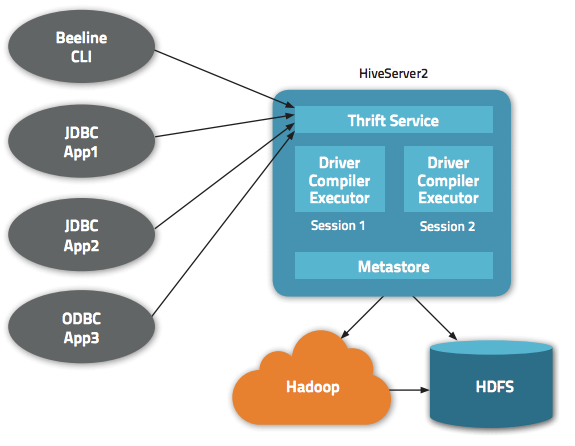
Hive 除了为我们提供一个 CLI 方式来查询数据之外,还给我们提供了基于 JDBC/ODBC 的方式来连接 Hive,这就是 HiveServer2(HiveServer)。但是默认情况下通过 JDBC 连接 HiveServer2 不需要任何的权限认证(hive.server2.authentication = NONE);这意味着任何知道 ThriftServer 地址的人都可以连接我们的 Hive,并执行一些操作。更可怕的是,这些人甚至可 w397090770 7年前 (2018-01-11) 13301℃ 5评论18喜欢
Depending on the complexity of your SQL query there are many, often exponential, query plans that return the same result. However, the performance of each plan can vary drastically; taking only seconds to finish or days given the chosen plan.That places a significant burden on analysts who will then have to know how to write performant SQL. This problem gets worse as the complexity of questions and SQL queries increases. In the abse w397090770 2年前 (2022-04-20) 612℃ 0评论1喜欢
在本博客的《Spark将计算结果写入到Mysql中》文章介绍了如果将Spark计算后的RDD最终 写入到Mysql等关系型数据库中,但是这些写操作都是自己实现的,弄起来有点麻烦。不过值得高兴的是,前几天发布的Spark 1.3.0已经内置了读写关系型数据库的方法,我们可以直接在代码里面调用。 Spark 1.3.0中对数据库写操作是通过DataFrame类 w397090770 10年前 (2015-03-17) 13539℃ 6评论16喜欢
本文讲解的Hive和HBase整合意思是使用Hive读取Hbase中的数据。我们可以使用HQL语句在HBase表上进行查询、插入操作;甚至是进行Join和Union等复杂查询。此功能是从Hive 0.6.0开始引入的,详情可以参见HIVE-705。Hive与HBase整合的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive-hbase-handler-1.2.0.jar工具里面的类实现 w397090770 8年前 (2016-07-31) 17436℃ 0评论42喜欢
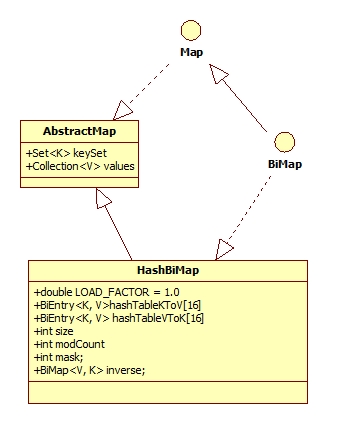
HashBiMap存储的键和值都只能唯一,不存在键与键、值与值相同的情况(详细分析见我博客:Guava学习之BiMap)。HashBiMap类继承了AbstractMap类并实现了BiMap接口,其类继承关系如下图所示:[caption id="attachment_705" align="aligncenter" width="356"] HashBiMap[/caption] AbstractMap类实现了Map接口定义的一些方法,而BiMap类定义了其子类需要实现的 w397090770 11年前 (2013-09-16) 4363℃ 0评论3喜欢
本版本迁移指南 If migrating from release older than 0.5.3, please also check the upgrade instructions for each subsequent release below. Specifically check upgrade instructions for 0.6.0. This release does not introduce any new table versions. The HoodieRecordPayload interface deprecated existing methods, in favor of new ones that also lets us pass properties at runtime. Users areencouraged to migrate out of the depr w397090770 4年前 (2021-01-31) 308℃ 0评论0喜欢
Spark 1.1.0已经在前几天发布了(《Spark 1.1.0发布:各个模块得到全面升级》、《Spark 1.1.0正式发布》),本博客对Hive部分进行了部分说明:《Spark SQL 1.1.0和Hive的兼容说明》、《Shark迁移到Spark 1.1.0 编程指南》,在这个版本对Hive的支持更加完善了,如果想在Spark SQL中加入Hive,并加入JDBC server和CLI,我们可以在编译的时候通过加上参 w397090770 10年前 (2014-09-17) 18504℃ 8评论10喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/好久没写Hive的那些事了,今 w397090770 11年前 (2014-02-19) 92554℃ 5评论132喜欢
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个广泛应用于统计计算和统计制图的优秀编程语言,但是其交互式使用通常局限于一台机器。为了能够使用R语言分析大规模分布式的数据,UC Berkeley给我们带来了SparkR,SparkR就是用R语言编写Spark程序,它允许数据科学家分析 w397090770 10年前 (2015-04-14) 12909℃ 0评论17喜欢
Apache Maven,是一个软件(特别是Java软件)项目管理及自动构建工具,由Apache软件基金会所提供。基于项目对象模型(缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。曾是Jakarta项目的子项目,现为独立Apache项目。 那么,如何在Linux平台下面安装Maven呢?下面以CentOS平台为例,说明如 w397090770 11年前 (2013-10-21) 32225℃ 3评论13喜欢
如果你对Hadoop有基本的了解,并希望将您的知识用于企业的大数据解决方案,那你就来阅读本书吧。本书提供了六个使用Hadoop生态系统解决实际问题的例子,使得您的Hadoop知识提升到一个新的水平。本书作者:Anurag Shrivastava,由Packt出版社于2016年9月出版,全书共316页。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关 zz~~ 8年前 (2016-12-20) 3230℃ 1评论6喜欢
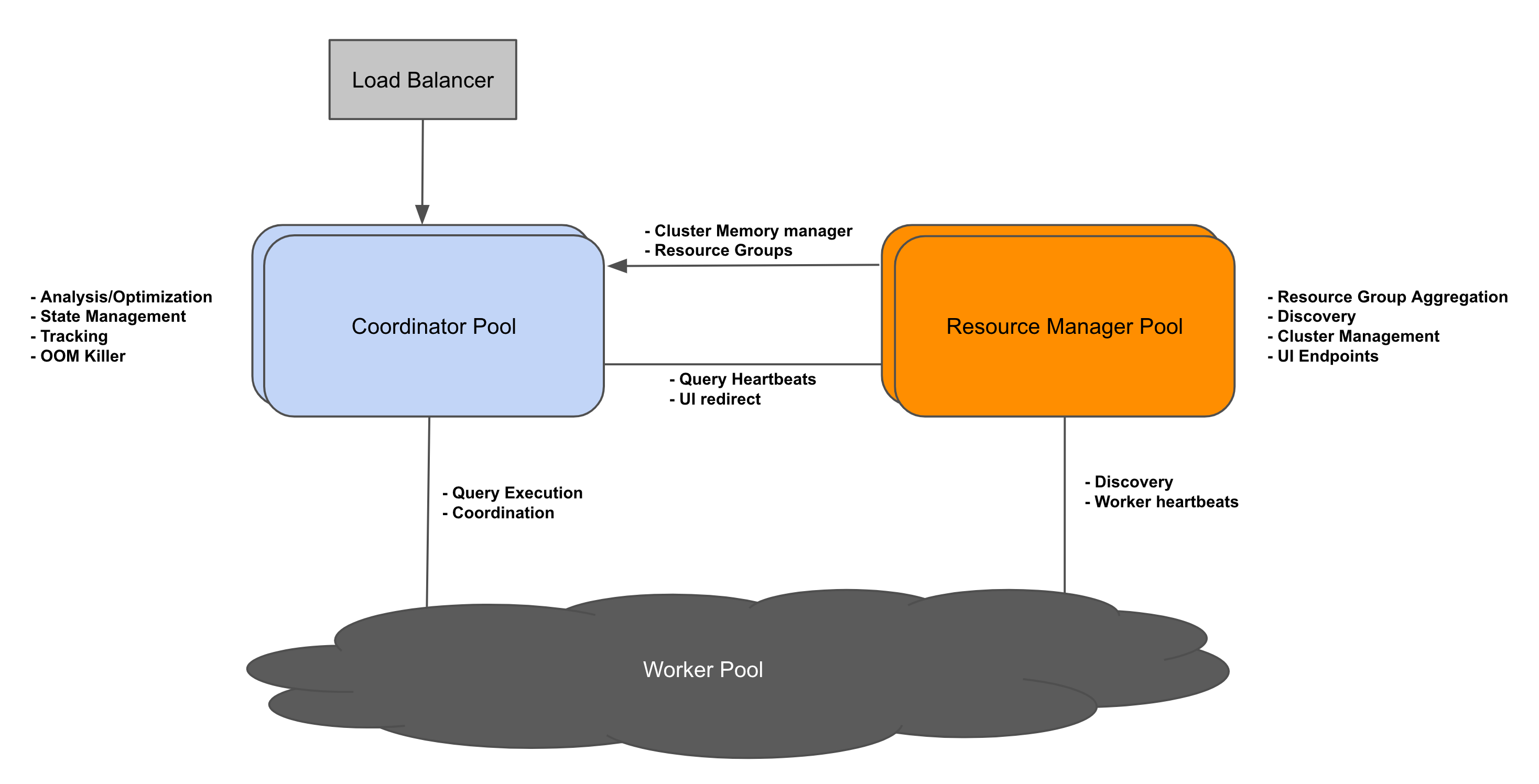
背景Presto 的架构最初只支持一个 coordinator 和多个 workers。多年来,这种方法一直很有效,但也带来了一些新挑战。使用单个 coordinator,集群可以可靠地扩展到一定数量的 worker。但是运行复杂、多阶段查询的大集群可能会使供应不足的 coordinator 不堪重负,因此需要升级硬件来支持工作负载的增加。单个 coordinator 存在单点故障 zz~~ 2年前 (2022-04-22) 909℃ 0评论1喜欢
1、Hive内部表和外部表的区别? 1、在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而表则不一样; 2、在删除表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的! 那么, w397090770 8年前 (2016-08-26) 5654℃ 2评论20喜欢
《Hadoop&Spark解决二次排序问题(Spark篇)》《Hadoop&Spark解决二次排序问题(Hadoop篇)》问题描述二次排序就是key之间有序,而且每个Key对应的value也是有序的;也就是对MapReduce的输出(KEY, Value(v1,v2,v3,......,vn))中的Value(v1,v2,v3,......,vn)值进行排序(升序或者降序),使得Value(s1,s2,s3,......,sn),si ∈ (v1,v2,v3,......,vn)且s1 < s2 < s3 < ..... w397090770 9年前 (2015-08-06) 11307℃ 6评论29喜欢
搜索API允许开发者执行搜索查询,返回匹配查询的搜索结果。这既可以通过查询字符串也可以通过查询体实现。多索引多类型所有的搜索API都可以跨多个类型使用,也可以通过多索引语法跨索引使用。例如,我们可以搜索twitter索引的跨类型的所有文档。[code lang="java"]$ curl -XGET 'http://localhost:9200/twitter/_search?q=user:kimchy'[/ zz~~ 8年前 (2016-09-22) 1667℃ 0评论2喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 8月31日(13:30-17:30),杭州第 w397090770 10年前 (2014-09-01) 26586℃ 230评论17喜欢
在TCP/IP状态图中,有很多种的状态,它们之间有的是可以互相转换的,也就是说,从一种状态转到另一种状态,但是这种转换不是随便发送的,是要满足一定的条件。TCP/IP状态图看起来更像是自动机。下图即为TCP/IP状态。由上图可以看出,一共有11种不同的状态。这11种状态描述如下: CLOSED:关闭状态,没有连接活动或正在进 w397090770 12年前 (2013-04-03) 11237℃ 0评论15喜欢
Spark和Flume-ng整合,可以参见本博客:《Spark和Flume-ng整合》《使用Spark读取HBase中的数据》如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 大家可能都知道很熟悉Spark的两种常见的数据读取方式(存放到RDD中):(1)、调用parallelize函数直接从集合中获取数据,并存入RDD中;Java版本如 w397090770 10年前 (2014-06-29) 74987℃ 47评论58喜欢
本书由Robert D. Schneider所著,全书共45页,这里提供的是完整版。 w397090770 9年前 (2015-08-21) 2541℃ 0评论2喜欢
Spark目前被越来越多的企业使用,和Hadoop一样,Spark也是以作业的形式向集群提交任务,那么在内部实现Spark和Hadoop作业模型都一样吗?答案是不对的。 熟悉Hadoop的人应该都知道,用户先编写好一个程序,我们称为Mapreduce程序,一个Mapreduce程序就是一个Job,而一个Job里面可以有一个或多个Task,Task又可以区分为Map Task和Reduce T w397090770 10年前 (2014-11-11) 21136℃ 1评论34喜欢
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数# 查看物理CPU个数cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l# 查看每个物理CPU中core的个数(即核数)cat /proc/cpuinfo| grep "cpu cores"| uniq# 查看逻辑CPU的个数cat /proc/cpuinfo| grep "processor"| wc -l复制代码 查看CPU信息(型号)ca w397090770 3年前 (2021-11-01) 782℃ 0评论3喜欢











![[电子书]Hadoop Blueprints pdf下载](https://www.iteblog.com/pic/Hadoop_Blueprints-iteblog.jpg)