我们在安装软件的时候,有时会出现由于依赖的软件没有被安装,会导致软件安装的失败,其实我们可以用命令来安装依赖的软件,这里以Ubuntu为例进行说明。 我在安装wps-office的时候,显示安装成功了,但是还是无法运行,后来才知道原来有些依赖的软件没有安装,导致wps无法运行。我们可以用户下面的命令查看依赖的 w397090770 10年前 (2014-11-21) 7106℃ 0评论2喜欢
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 在前面的两篇文章中我们介绍了如何编译和部署Apache Zeppelin、如何使用Apache Zeppelin。这篇文章中将介绍如何将外部依赖库加入到Apache Zeppelin中。 在现实情况下,我们编写程序一般都是需要依赖外部的相关类库 w397090770 9年前 (2016-02-04) 8099℃ 0评论7喜欢
本书于2017-05由Packt Publishing出版,作者Rishi Yadav,全书294页。从书名就可以看出这是一本讲解技巧的书。本书副标题:Over 70 recipes to help you use Apache Spark as your single big data computing platform and master its libraries。本书适合数据工程师,数据科学家以及那些想使用Spark的读者。阅读本书之前最好有Scala的编程基础。通过本书你将学到以下知识 zz~~ 7年前 (2017-07-07) 4842℃ 0评论16喜欢
最近升级了 WordPress,但是出现了以下的异常:[code lang="bash"]Your server is running PHP version 5.4.16 but WordPress 5.4.4 requires at least 5.6.20.[/code]可见 WordPress 5.4.4 版本需要 PHP 5.6.20 及以上才可以正常运行,所以本文记录 PHP 的升级过程。检查当前安装的 PHP我们可以使用下面命令看下当前服务器上的 PHP 版本[code lang="bash"][root@iteblog.com w397090770 4年前 (2020-10-06) 323℃ 0评论0喜欢
本课程是Scala语言的入门课程,面向没有或仅有少量编程语言基础的同学,当然,具有一定的Java或C、C++语言基础将有助于本课程的学习。在本课程内,将更注重scala的各种语言规则与简单直接的应用,而不在于其是如何具体实现,通过学习本课程能具备初步的Scala语言实际编程能力。 此视频保证可以全部浏览,百度网盘 w397090770 10年前 (2015-03-21) 21924℃ 6评论46喜欢
本文来自 Kyligence 主办的 Data & AI Meetup(第二期),会议时间为 11月16日。本期会议特别邀请了 Spark 社区大佬范文臣带来 Spark 3.2.0 新特性的首发解读。范文臣,Databricks 开源组技术主管,Apache Spark PMC member,Spark 社区最活跃的贡献者之一,目前主要负责 Spark Core/SQL 的设计开发和开源社区管理。Spark 作为目前大数据领域使用最普及的 w397090770 3年前 (2021-11-30) 666℃ 0评论0喜欢
什么是 Alluxio Local Cache随着云计算在基础设施领域的市场份额持续上升,主流数据分析引擎纷纷选择独立扩展存储、计算来适配云基础设施,并以此为云提供商降低成本。但是,存储计算分离也为查询延迟带来了新的挑战,因为当网络饱和时,通过网络扫描大量数据将受到 IO 限制。此外,元数据也面临远程网络来检索的性能问题。 w397090770 3年前 (2022-03-21) 718℃ 0评论3喜欢
Apache Flume 1.5.0 发布于5月22日正式发布(可以在http://flume.apache.org/download.html下载)。Flume是一个分布式、可靠和高可用的服务,用于收集、聚合以及移动大量日志数据,使用一个简单灵活的架构,就流数据模型。这是一个可靠、容错的服务。下面是Apache Flume-ng 1.5.0的Changelog:What's new in Apache Flume 1.5.0:May 22nd, 2014New Feature: Int w397090770 10年前 (2014-05-27) 7007℃ 1评论4喜欢
一、 问答题1、简单描述如何安装配置一个apache开源版hadoop,只描述即可,无需列出完整步骤,能列出步骤更好。1) 安装JDK并配置环境变量(/etc/profile)2) 关闭防火墙3) 配置hosts文件,方便hadoop通过主机名访问(/etc/hosts)4) 设置ssh免密码登录5) 解压缩hadoop安装包,并配置环境变量6) 修改配置文件($HADOOP_HOME/conf)hadoop-e w397090770 8年前 (2016-08-26) 7946℃ 0评论14喜欢
Short URL or tiny URL is an URL used to represent a long URL. For example, http://tinyurl.com/45lk7x will be redirect to http://www.snippetit.com/2008/10/implement-your-own-short-url.There are 2 main advantages of using short URL: Easy to remember - Instead of remember an URL with 50 or more characters, you only need to remember a few (5 or more depending on application's implementation). More portable - Some systems have limi w397090770 12年前 (2013-04-15) 20484℃ 0喜欢
本书于2015年02月出版,全书共322页,这里提供的是本身的完整版。 w397090770 9年前 (2015-08-21) 3905℃ 0评论7喜欢
全球最大的开源软件基金会 Apache 软件基金会(以下简称 Apache)于美国时间 2022 年 6 月 16 日 宣布,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)。 以下内容译自 Apache Doris 官网(https://doris.apache.org/ )。Apache Doris 是一个基于 MPP 的现代化、高性能、实时的分析型数据库,以极速易用的 zz~~ 2年前 (2022-06-16) 654℃ 0评论2喜欢
由于Hadoop自身的一些特点,它只适合用于将Linux作为操作系统的生产环境。在实际应用场景中,管理员适当对Linux内核参数进行调优,可在一定程度上提高作业的运行效率,比较有用的调整选项如下。一、增大同时打开的文件描述符和网络连接上限 在Hadoop集群中,由于涉及的作业和任务数目非常多,对于某个节点,由于 w397090770 11年前 (2014-04-02) 13057℃ 1评论7喜欢
最近升级了迅雷9,新版本精简了任务列表的面积,然而增加了一个硕大的内置浏览器面板,大概占据了四分之三的窗口面积,并且不能关闭!界面如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop就个人观点而言,实在不能理解为什么需要让一个下载工具的附加功能占据主要使用区 w397090770 8年前 (2017-02-18) 6421℃ 0评论20喜欢
本文出自本公众号ChinaScala,由陈超所述。一、Spark能否取代Hadoop? 答: Hadoop包含了Common,HDFS,YARN及MapReduce,Spark从来没说要取代Hadoop,最多也就是取代掉MapReduce。事实上现在Hadoop已经发展成为一个生态系统,并且Hadoop生态系统也接受更多优秀的框架进来,如Spark (Spark可以和HDFS无缝结合,并且可以很好的跑在YARN上).。 w397090770 9年前 (2015-08-26) 7189℃ 1评论42喜欢
Hadoop Streaming 是 Hadoop 提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer 作业。比如下面的例子[code lang="bash"]mapred streaming \ -input myInputDirs \ -output myOutputDir \ -mapper /bin/cat \ -reducer /usr/bin/wc[/code]Hadoop Streaming程序是如何工作的Hadoop Streaming 使用了 Unix 的标准 w397090770 8年前 (2017-03-21) 9994℃ 0评论15喜欢
假设现在的分支名称为 oldName,想要修改为 newName如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本地分支重命名这种情况是你的代码还没有推送到远程,分支只是在本地存在,那直接执行下面的命令即可:[code lang="bash"]git branch -m oldName newName[/code]远程分支重命名 如果你的分支已经推 w397090770 8年前 (2017-03-02) 728℃ 0评论1喜欢
本 hosts 文件更新时间为 2018年07月22日。原作者为 Google Hosts 组织本页面长期更新最新 Google、谷歌学术、维基百科、ccFox.info、ProjectH、3DM、Battle.NET 、WordPress、Microsoft Live、GitHub、Box.com、SoundCloud、inoreader、Feedly、FlipBoard、Twitter、Facebook、Flickr、imgur、DuckDuckGo、Ixquick、Google Services、Google apis、Android、Youtube、Google Drive、UpLoad、Appspot、 w397090770 7年前 (2018-01-09) 16185℃ 1评论43喜欢
基于社区开发者们的观察,绝大多数的Spark应用程序的瓶颈不在于I/O或者网络,而在于CPU和内存。基于这个事实,开发者们发起了Tungsten项目,而Spark 1.5是Tungsten项目的第一阶段。Tungsten项目主要集中在三个方面,于此来提高Spark应用程序的内存和CPU的效率,使得性能能够接近硬件的限制。Tungsten项目的三个阶段内存管理和二 w397090770 9年前 (2015-09-09) 7374℃ 0评论5喜欢
背景数据湖(Data Lake),湖仓一体(Data Lakehouse)俨然已经成为了大数据领域最为火热的流行词,在接受这些流行词洗礼的时候,身为技术人员我们往往会发出这样的疑问,这是一种新的技术吗,还是仅仅只是概念上的翻新(新瓶装旧酒)呢?它到底解决了什么问题,拥有什么样新的特性呢?它的现状是什么,还存在什么问题呢? w397090770 4年前 (2020-11-28) 5704℃ 0评论7喜欢
本文来自7月26日在上海举行的 Flink Meetup 会议,分享来自于刘康,目前在大数据平台部从事模型生命周期相关平台开发,现在主要负责基于flink开发实时模型特征计算平台。熟悉分布式计算,在模型部署及运维方面有丰富实战经验和深入的理解,对模型的算法及训练有一定的了解。本文主要内容如下:在公司实时特征开发的现 zz~~ 6年前 (2018-08-14) 7392℃ 0评论3喜欢
经过几个星期的开发,本博客微信小程序(过往记忆大数据技术博客)正式上线了!至此大家可以通过微信公众号、微信小程序等方式访问本博客了。下面来看看本博客微信公众号的一些预览:微信小程序首页在首页可以查看本博客最新的文章,热门文章以及搜索等。文章页文章页可以文章的详情,功 w397090770 7年前 (2018-01-28) 1948℃ 0评论7喜欢
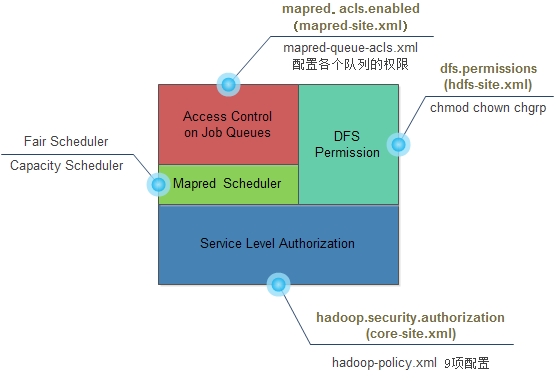
Hadoop在服务层进行了授权(Service Level Authorization)控制,这是一种机制可以保证客户和Hadoop特定的服务进行链接,比如说我们可以控制哪个用户/哪些组可以提交Mapreduce任务。所有的这些配置可以在$HADOOP_CONF_DIR/hadoop-policy.xml中进行配置。它是最基础的访问控制,优先于文件权限和mapred队列权限验证。可以看看下图[caption id="attach w397090770 11年前 (2014-03-20) 9091℃ 0评论8喜欢
2010年,Facebook 的工程师在 ICDC(IEEE International Conference on Data Engineering) 发表了一篇 《RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems》 的论文,介绍了其为基于 MapReduce 的数据仓库设计的高效存储结构,这就是我们熟知的 RCFile(Record Columnar File)。下面介绍 RCFile 的一些诞生背景和设计。背景早在2010 w397090770 4年前 (2020-06-16) 1302℃ 0评论8喜欢
下面文档是今天早上翻译的,因为要上班,时间比较仓促,有些部分没有翻译,请见谅。2017年06月01日儿童节 Apache Flink 社区正式发布了 1.3.0 版本。此版本经历了四个月的开发,共解决了680个issues。Apache Flink 1.3.0 是 1.x.y 版本线上的第四个主要版本,其 API 和其他 1.x.y 使用 @Public 注释的API是兼容的。此外,Apache Flink 社区目前制 w397090770 7年前 (2017-06-01) 2590℃ 1评论10喜欢
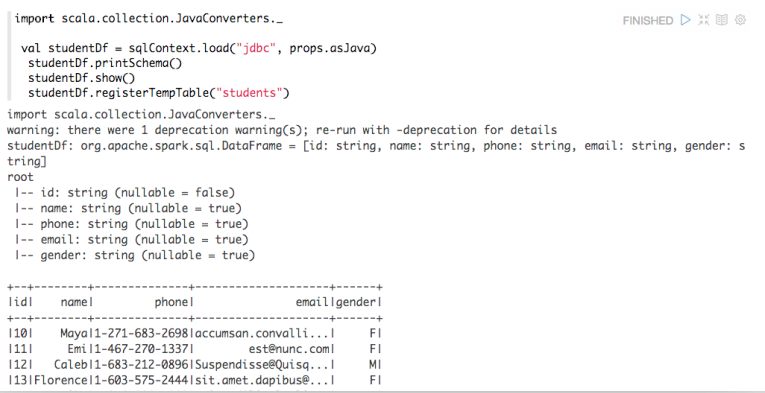
Delta Lake 的 Delete 功能是由 0.3.0 版本引入的,参见这里,对应的 Patch 参见这里。在介绍 Apache Spark Delta Lake 实现逻辑之前,我们先来看看如何使用 delete 这个功能。Delta Lake 删除使用Delta Lake 的官方文档为我们提供如何使用 Delete 的几个例子,参见这里,如下:[code lang="scala"]import io.delta.tables._val iteblogDeltaTable = DeltaTable.forPath(spa w397090770 5年前 (2019-09-27) 1517℃ 0评论2喜欢
Apache Flink 1.10.0 于 2020年02月11日正式发布。Flink 1.10 是一个历时非常长、代码变动非常大的版本,也是 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。 w397090770 5年前 (2020-02-12) 3459℃ 0评论3喜欢
在今年的09月08日,Google在其安全博客中宣布:为了让用户更加方便了解他们与网站之间的连接是否安全,从2017年1月份正式发布的Chrome 56开始,Google将彻底把含有密码登录和交易支付等个人隐私敏感内容的HTTP页面标记为【不安全】,并且将会在后续更新的Chrome版本中,逐渐把所有的HTTP网站标记为【不安全】。HTTPS已成为网站的 w397090770 8年前 (2016-12-15) 3234℃ 0评论8喜欢
2019年10月22日上午 Databricks 宣布,已经完成了由安德森-霍洛维茨基金(Andreessen Horowitz)牵头的4亿美元F轮融资,参与融资的有微软(Microsoft)、Alkeon Capital Management、贝莱德(BlackRock)、Coatue Management、Dragoneer Investment Group、Geodesic、Green Bay Ventures、New Enterprise Associates、T. Rowe Price和Tiger Global Management。经过这次融资,Databricks 的估值高达62亿美 w397090770 5年前 (2019-10-22) 1119℃ 0评论0喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/好久没写Hive的那些事了,今 w397090770 11年前 (2014-02-19) 92554℃ 5评论132喜欢
![[电子书]Apache Spark 2.x Cookbook, 2nd Edition PDF下载](https://www.iteblog.com/pic/books/apache-spark-2x-cookbook_iteblog.png)

![练数成金—Scala语言入门视频百度网盘下载[全五课]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/3.jpg)