桔妹导读:滴滴ElasticSearch平台承接了公司内部所有使用ElasticSearch的业务,包括核心搜索、RDS从库、日志检索、安全数据分析、指标数据分析等等。平台规模达到了3000+节点,5PB 的数据存储,超过万亿条数据。平台写入的峰值写入TPS达到了2000w/s,每天近 10 亿次检索查询。为了承接这么大的体量和丰富的使用场景,滴滴ElasticSearch需要 w397090770 4年前 (2020-08-19) 1425℃ 0评论8喜欢
PrestoCon Day 2021 在3月24日于在线的形式举办,会议的议程可以参见这里。这里主要是收集了本次会议的 PPT 和视频等资料供大家学习交流使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据下载途径关注微信公众号 过往记忆大数据 或者 Java与大数据架构 并回复 10011 获取。可下载 w397090770 3年前 (2021-07-31) 441℃ 0评论4喜欢
即日起,关注@Spark技术博客 及@ 一位微博好友并转发本文章到微博有机会获取《Spark大数据分析实战》:/archives/1590。3月12日在微博抽奖平台抽取1位同学并赠送此书。本活动已经结束,抽奖信息已经在新浪微博抽奖平台公布 《Spark大数据分析实战》由高彦杰和倪亚宇编写,通过典型数据分析应用场景、算法与系统架构,结 w397090770 9年前 (2016-03-02) 8515℃ 0评论44喜欢
Data + AI Summit 2022 于2022年06月27日至30日举行。本次会议是在旧金山进行,中国的小伙伴是可以在线收听的,一共为期四天,第一天是培训,后面几天才是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,本次会议主要分为六大块:数据分析, BI 以及可视化:了解最新的数据分析、BI 和可视化技术以及 w397090770 2年前 (2022-07-20) 1304℃ 0评论1喜欢
在进程运行过程中,若其所要访问的页面不在内存而需把它们调入内存,但内存已无空闲空间时,为了保证该进程能正常运行,系统必须从内存中调出一页程序或数据送磁盘的对换区中。但应将哪个页面调出,须根据一定的算法来确定。通常,把选择换出页面的算法称为页面置换算法(Page-Replacement Algorithms)。置换算法的好坏,将直接 w397090770 12年前 (2013-04-11) 5378℃ 0评论2喜欢
在 Zookeeper 中限制 transaction log 总大小主要有两种方法。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop限制 Zookeeper Transaction Log 里面的事务条数默认情况下,在写入 snapCount(100000) 事务后,Zookeeper 事务日志将会切换。如果 Zookeeper 的数据目录的空间不足与存储三个版本的 Zookeeper Transaction Lo w397090770 4年前 (2020-10-28) 737℃ 0评论1喜欢
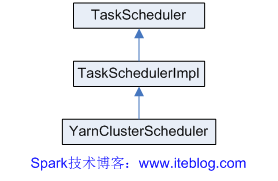
《Spark源码分析:多种部署方式之间的区别与联系(1)》 《Spark源码分析:多种部署方式之间的区别与联系(2)》 从官方的文档我们可以知道,Spark的部署方式有很多种:local、Standalone、Mesos、YARN.....不同部署方式的后台处理进程是不一样的,但是如果我们从代码的角度来看,其实流程都差不多。 从代码中,我们 w397090770 10年前 (2014-10-24) 7705℃ 2评论14喜欢
2010年,几个大胡子年轻人在旧金山成立了一家名为 dotCloud 的 PaaS 平台的公司。dotCloud 主要是基于 PaaS 平台为开发者或开发商提供技术服务。PaaS 的全称是 Platform as a Service,也就是平台即服务。dotCloud 把需要花费大量时间的手工工作和重复劳动抽象成组件和服务,并放到了云端,另外,它还提供了各种监控、告警和控制功能,方便开 w397090770 5年前 (2020-01-15) 853℃ 0评论8喜欢
昨天晚上,Apache Beam发布了第一个稳定版2.0.0,Apache Beam 社区声明:未来版本的发布将保持 API 的稳定性,并让 Beam 适用于企业的部署。Apache Beam 的第一个稳定版本是此社区第三个重要里程碑。Apache Beam 是在2016年2月加入 Apache 孵化器(Apache Incubator),并在同年的12月成功毕业成为 Apache 基金会的顶级项目(《Apache Beam成为Apache顶级项目 w397090770 7年前 (2017-05-18) 1730℃ 0评论3喜欢
本文仅仅是简单地介绍如何在Ubuntu/Debian系统上安装Node.js(任何版本)和npm(Node Package Manager的简写),其他类Linux系统安装步骤和这个类似。 一、更新你的系统[code lang="bash"]iteblog# sudo apt-get updateiteblog# sudo apt-get install git-core curl build-essential openssl libssl-dev[/code] 二、安装Node.js 首先我们先从github上将Node w397090770 10年前 (2015-04-11) 27759℃ 0评论22喜欢
Elasticsearch是一个分布式系统。当documents被创建、更新或者删除,其新版本会被复制到集群的其它节点。Elasticsearch既是异步的(asynchronous )也是同步的(concurrent),其含义是复制请求都是并行发送的,但是到达目的地的顺序是无序的。Elasticsearch系统需要一种方法使得老版本的文档永远都无法覆盖新的版本。 每当文档被改变的 w397090770 8年前 (2016-08-11) 3685℃ 1评论2喜欢
在社会关系网中,入度越多的实体权威性越大;反之则越小。从上面的定义可以看出,权威性的衡量必须在有向图中进行,无向图是没有权威性的概念,不过无向图中可以用中心度去衡量实体的重要性。目前,比较常见的用于计算结点权威性的模型主要有三种:度权威(Degree Prestige)、邻近权威(Proximity Prestige)以及等级权威(Rank w397090770 11年前 (2013-05-30) 4077℃ 1评论5喜欢
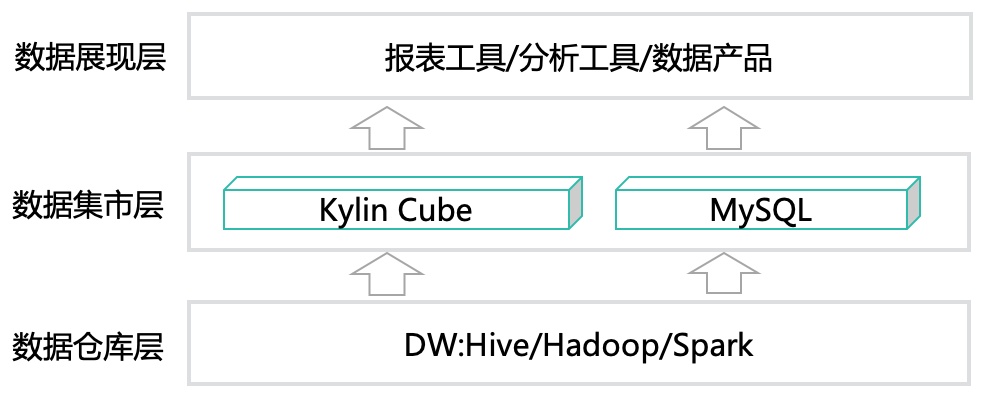
序言美团外卖数据仓库技术团队负责支撑日常业务运营及分析师的日常分析,由于外卖业务特点带来的数据生产成本较高和查询效率偏低的问题,他们通过引入Apache Doris引擎优化生产方案,实现了低成本生产与高效查询的平衡。并以此分析不同业务场景下,基于Kylin的MOLAP模式与基于Doris引擎的ROLAP模式的适用性问题。希望能对大家有 w397090770 4年前 (2020-04-17) 2371℃ 0评论3喜欢
今年是我创建这个微信公众号的第五年,五年来,收获了6.8万粉丝。这个数字,在自媒体圈子,属于十八线小规模的那种,但是在纯技术圈,还是不错的成绩,我很欣慰。我花在这个号上面的时间挺多的。我平时下班比较晚,一般下班到家了,老婆带着孩子已经安睡了,我便轻手轻脚的拿出电脑,带上耳机,开始我一天的知识盘 w397090770 5年前 (2019-08-13) 5635℃ 2评论33喜欢
在 《如何在Spark、MapReduce和Flink程序里面指定JAVA_HOME》文章中我简单地介绍了如何自己指定 JAVA_HOME 。有些人可能注意到了,上面设置的方法有个前提就是要求集群的所有节点的同一路径下都安装部署好了 JDK,这样才没问题。但是在现实情况下,我们需要的 JDK 版本可能并没有在集群上安装,这个时候咋办?是不是就没办法呢?答案 w397090770 7年前 (2017-12-05) 2994℃ 0评论18喜欢
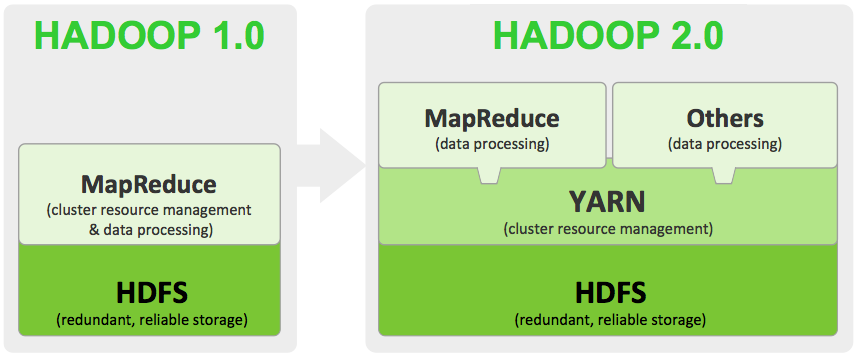
hadoop更新实在是太快了,现在已经更新到Hadoop-2.3.0版本(2014-02-11)。看了一下文档,和之前Hadoop-2.2.0的文档大部分类似,这篇文章主要是翻译一下Hadoop-2.3.0的文档。 Apache Hadoop 2.3.0和之前的Hadoop-1.x稳定版有了很大的提升。本篇文章主要是简要说说Hadoop 2.3.0中的HDFS和Mapreduce的提升(4、5两个特性是Hadoop2.x开始就支持的)。 w397090770 11年前 (2014-02-26) 7585℃ 2评论2喜欢
什么是数据迁移Apache Kafka 对于数据迁移的官方说法是分区重分配。即重新分配分区在集群的分布情况。官方提供了kafka-reassign-partitions.sh脚本来执行分区重分配操作。其底层实现主要有如下三步: 通过副本复制的机制将老节点上的分区搬迁到新的节点上。 然后再将Leader切换到新的节点。 最后删除老节点上的分区。重分 zz~~ 3年前 (2021-09-24) 847℃ 0评论5喜欢
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Bytedance》,分享者常鹏飞,字节跳动软件工程师。Presto 在字节跳动中得到了广泛的应用,如数据仓库、BI工具、广告等。与此同时,字节跳动的 presto 团队也提供了许多重要的特性和优化,如 Hive UDF Wrapper、多个协调器、运行时过滤器等,扩展了 presto w397090770 3年前 (2021-12-14) 719℃ 0评论1喜欢
一. 问答题1. 用mapreduce实现sql语句select count(x) from a group by b?2. 简述MapReduce大致流程,map -> shuffle -> reduce3. HDFS如何定位replica4. Hadoop参数调优: cluster level: JVM, map/reduce slots, job level: reducer, memory, use combiner? use compression?5. hadoop运行的原理?6. mapreduce的原理?7. HDFS存储的机制?8. 如何确认Hadoop集群的健康状况? w397090770 8年前 (2016-08-26) 3396℃ 0评论3喜欢
JMX(Java Management Extensions,即Java管理扩展)是一个为应用程序、设备、系统等植入管理功能的框架。JMX可以跨越一系列异构操作系统平台、系统体系结构和网络传输协议,灵活的开发无缝集成的系统、网络和服务管理应用。启动JMX监控,在启动java程序的时候最少需要在环境变量里面配置以下的选项:[code lang="bash"]-Dcom.sun.m w397090770 9年前 (2016-03-25) 6185℃ 0评论10喜欢
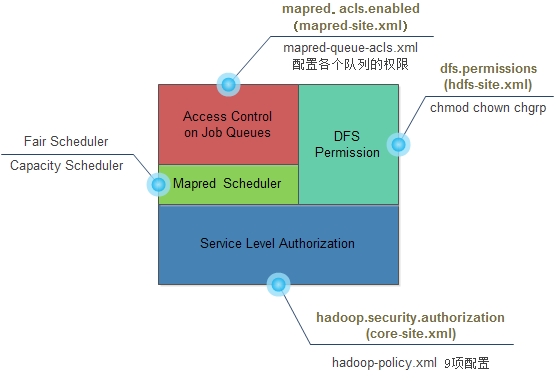
Hadoop在服务层进行了授权(Service Level Authorization)控制,这是一种机制可以保证客户和Hadoop特定的服务进行链接,比如说我们可以控制哪个用户/哪些组可以提交Mapreduce任务。所有的这些配置可以在$HADOOP_CONF_DIR/hadoop-policy.xml中进行配置。它是最基础的访问控制,优先于文件权限和mapred队列权限验证。可以看看下图[caption id="attach w397090770 11年前 (2014-03-20) 9091℃ 0评论8喜欢
第十四次Shanghai Apache Spark Meetup聚会,由中国平安银行大力支持。活动将于2017年12月23日12:30~17:00在上海浦东新区上海海神诺富特酒店三楼麦哲伦厅举行。举办地点交通方便,靠近地铁4号线浦东大道站。座位有限,先到先得。大会主题《Spark在金融领域的算法实践》(13:20 – 14:05)演讲嘉宾:潘鹏举,平安银行大数据平台架构师 zz~~ 7年前 (2017-12-06) 2020℃ 0评论11喜欢
默认情况下,Apache Zeppelin启动Spark是以本地模式起的,master的值是local[*],我们可以通过修改conf/zeppelin-env.sh文件里面的MASTER的值如下:[code lang="bash"]export MASTER= yarn-clientexport HADOOP_HOME=/home/q/hadoop/hadoop-2.2.0export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/[/code]然后启动Zeppelin,但是我们有时会发现日志出现了以下的异常信息:ERRO w397090770 9年前 (2016-01-22) 12062℃ 16评论12喜欢
这几天由于项目的需要,需要将Flume收集到的日志插入到Hbase中,有人说,这不很简单么?Flume里面自带了Hbase sink,可以直接调用啊,还用说么?是的,我在本博客的《Flume-1.4.0和Hbase-0.96.0整合》文章中就提到如何用Flume和Hbase整合,从文章中就看出整个过程不太复杂,直接做相应的配置就行了。那么为什么今天还要特意提一下Flum w397090770 11年前 (2014-01-27) 5145℃ 1评论1喜欢
AdminLTE是一个完全响应式管理并基于Bootstrap 3.x的免费高级管理控制面板主题。高度可定制的,易于使用。自适应多种屏幕分辨率,兼容PC端和手机移动端,内置了多个模板页面,包括仪表盘、邮箱、日历、锁屏、登录及注册、404错误、500错误等页面。AdminLTE是基于模块化设计,很容易在其之上定制和重制。本文撰写的时候AdminLTE w397090770 8年前 (2016-07-17) 18602℃ 0评论24喜欢
随着我们使用 Docker 的次数越来越多,我们电脑里面可能已经存在很多 Docker 镜像,大量的镜像会占据大量的存储空间,所有很有必要清理一些不需要的镜像。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop镜像的删除在删除镜像之前,我们可以看下系统里面都有哪些镜像:[code lang="bash"][ite w397090770 5年前 (2020-04-14) 573℃ 0评论1喜欢
课程讲师:Cloudy 课程分类:Java 适合人群:初级 课时数量:8课时 用到技术:Zookeeper、Web界面监控 涉及项目:案例实战 此视频百度网盘免费下载。本站所有下载资源收集于网络,只做学习和交流使用,版权归原作者所有,若为付费视频,请在下载后24小时之内自觉删除,若作商业用途,请购 w397090770 10年前 (2015-04-18) 34785℃ 2评论57喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 112.19.121.141 8123 高匿名 HTTP w397090770 9年前 (2015-05-15) 23799℃ 0评论6喜欢
北京第九次Spark Meetup活动于2015年08月22日下午14:00-18:00在北京市海淀区丹棱街5号 微软亚太研发集团总部大厦1号楼进行。活动内容如下: 1、《Keynote》 ,分享人:Sejun Ra ,CEO of NFLabs.com 2、《An introduction to Zeppelin with a demo》,分享人: Anthony Corbacho, Engineer from NFLabs and Apache Zeppelin committer 3、《Apache Kylin introductio w397090770 9年前 (2015-09-04) 2669℃ 0评论4喜欢
在Spark 1.x版本,我们收到了很多询问SparkContext, SQLContext和HiveContext之间关系的问题。当人们想使用DataFrame API的时候把HiveContext当做切入点的确有点奇怪。在Spark 2.0,引入了SparkSession,作为一个新的切入点并且包含了SQLContext和HiveContext的功能。为了向后兼容,SQLContext和HiveContext被保存下来。SparkSession拥有许多特性,下面将展示SparkS w397090770 8年前 (2016-05-26) 14024℃ 0评论13喜欢