下面的操作会影响到Spark输出RDD分区(partitioner)的: cogroup, groupWith, join, leftOuterJoin, rightOuterJoin, groupByKey, reduceByKey, combineByKey, partitionBy, sort, mapValues (如果父RDD存在partitioner), flatMapValues(如果父RDD存在partitioner), 和 filter (如果父RDD存在partitioner)。其他的transform操作不会影响到输出RDD的partitioner,一般来说是None,也就是没 w397090770 10年前 (2014-12-29) 16575℃ 0评论5喜欢
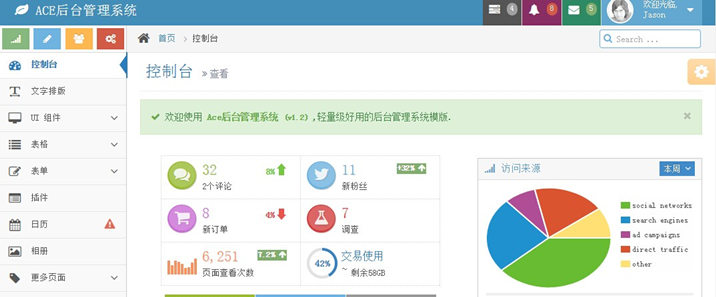
最近一段时间在做一个管理系统,在网上找了很久的前端展示框架,终于找到一款基于Bootstrap的后台管理系统模版:Ace。Bootstrap是Twitter 于2010年开发出来的前端框架,用过的同学应该知道,这款前端框架不仅界面很美观,而且兼容了很多的浏览器,大大加速了我们开发网站的速度!这篇文章讲到的Ace是基于Bootstrap的,所以界面自然 w397090770 10年前 (2015-01-19) 172226℃ 15评论459喜欢
Elasticsearch 5.0.0在2016年10月26日发布,该版本基于Lucene 6.2.0,这是最新的稳定版本,并且已经在Elastic Cloud上完成了部署。Elasticsearch 5.0.0是目前最快、最安全、最具弹性、最易用的版本,此版本带来了一系列的新功能和性能优化。ElasticSearch 5.0.0 release Note点击下载ElasticSearch 5.0.0阅读最新文档如果想及时了解Spark、Hadoop或者Hbase w397090770 8年前 (2016-11-02) 4953℃ 0评论10喜欢
1.文件大小默认为64M,改为128M有啥影响?2.RPC的原理?3.NameNode与SecondaryNameNode的区别与联系?4.介绍MadpReduce整个过程,比如把WordCount的例子的细节将清楚(重点讲解Shuffle)?5.MapReduce出现单点负载多大,怎么负载平衡?6.MapReduce怎么实现Top10?7.hadoop底层存储设计8.zookeeper有什么优点,用在什么场合9.Hbase中的meta w397090770 8年前 (2016-08-26) 3575℃ 0评论2喜欢
Data + AI Summit 2022 于2022年06月27日至30日举行。本次会议是在旧金山进行,中国的小伙伴是可以在线收听的,一共为期四天,第一天是培训,后面几天才是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,本次会议主要分为六大块:数据分析, BI 以及可视化:了解最新的数据分析、BI 和可视化技术以及 w397090770 2年前 (2022-07-10) 607℃ 0评论3喜欢
C的结构体内不允许有函数存在,C++允许有内部成员函数,且允许该函数是虚函数。所以C的结构体是没有构造函数、析构函数、和this指针的。 C的结构体对内部成员变量的访问权限只能是public,而C++允许public,protected,private三种。 C语言的结构体是不可以继承的,C++的结构体是可以从其他的结构体或者类继承过来的。在C中定义一 w397090770 12年前 (2013-04-05) 5133℃ 0评论0喜欢
每个 NodeManager 节点内置提供了检测自身健康状态的机制(详情参见 NodeHealthCheckerService);通过这种机制,NodeManager 会将诊断出来的监控状态通过心跳机制汇报给 ResourceManager,然后ResourceManager 端会通过 RMNodeEventType.STATUS_UPDATE 更新 NodeManager 的状态;如果此时的 NodeManager 节点不健康,那么 ResourceManager 将会把 NodeManager 状态变为 NodeState w397090770 7年前 (2017-06-08) 4223℃ 0评论18喜欢
在前面的文章《Apache Cassandra 快速入门指南(Quick Start)》 我们简单介绍了 Cassandra 的一些基本知识。在那篇文章里面我们使用了下面语句创建了一张名为 iteblog_user 的表:[code lang="sql"]cqlsh> use iteblog_keyspace;cqlsh:iteblog_keyspace> CREATE TABLE iteblog_user (first_name text , last_name text, PRIMARY KEY (first_name)) ;[/code]建表语句里面有个 PRIMARY KE w397090770 6年前 (2019-04-09) 1175℃ 2评论0喜欢
Avro有C, C++, C#, Java, PHP, Python, and Ruby等语言的实现,本文只简单介绍如何在Java中使用Avro进行数据的序列化(data serialization)。本文使用的是Avro 1.7.4,这是写这篇文章时最新版的Avro。读完本文,你将会学到如何使用Avro编译模式、如果用Avro序列化和反序列化数据。一、准备项目需要的jar包 文本的例子需要用到的Jar包有这四 w397090770 11年前 (2014-04-08) 45014℃ 4评论38喜欢
Apache Kafka 的核心设计是日志(Log)—— 一个简单的数据结构,使用顺序操作。以日志为中心的设计带来了高效的磁盘缓冲和 CPU 缓存使用、预取、零拷贝数据传输和许多其他好处,从而使 Kafka 能够提供高效率和吞吐量的功能。对于那些刚接触 Kafka 的人来说,主题(topic)以及提交日志的底层实现通常是他们学习的第一件事。但 w397090770 3年前 (2021-04-11) 757℃ 0评论4喜欢
一、先来先服务和短作业(进程)优先调度算法1.先来先服务调度算法先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。当在作业调度中采用该算法时,每次调度都是从后备作业队列中选择一个或多个最先进入该队列的作业,将它们调入内存,为它们分配资源、创建进程,然后放入 w397090770 12年前 (2013-04-10) 14317℃ 0评论19喜欢
本文原文:https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=85475081。Carbondata 1.4.0 下载Carbondata 官方文档Carbondata 源码Apache CarbonData社区很高兴发布1.4.0版本,在社区开发者和用户的共同努力下,1.4.0解决了超过230个JIRA Tickets(新特性和bug修复),欢迎大家试用。简介CarbonData是一个高性能的数据解决方案,目标是实现一份数据支持 w397090770 6年前 (2018-06-05) 4337℃ 0评论4喜欢
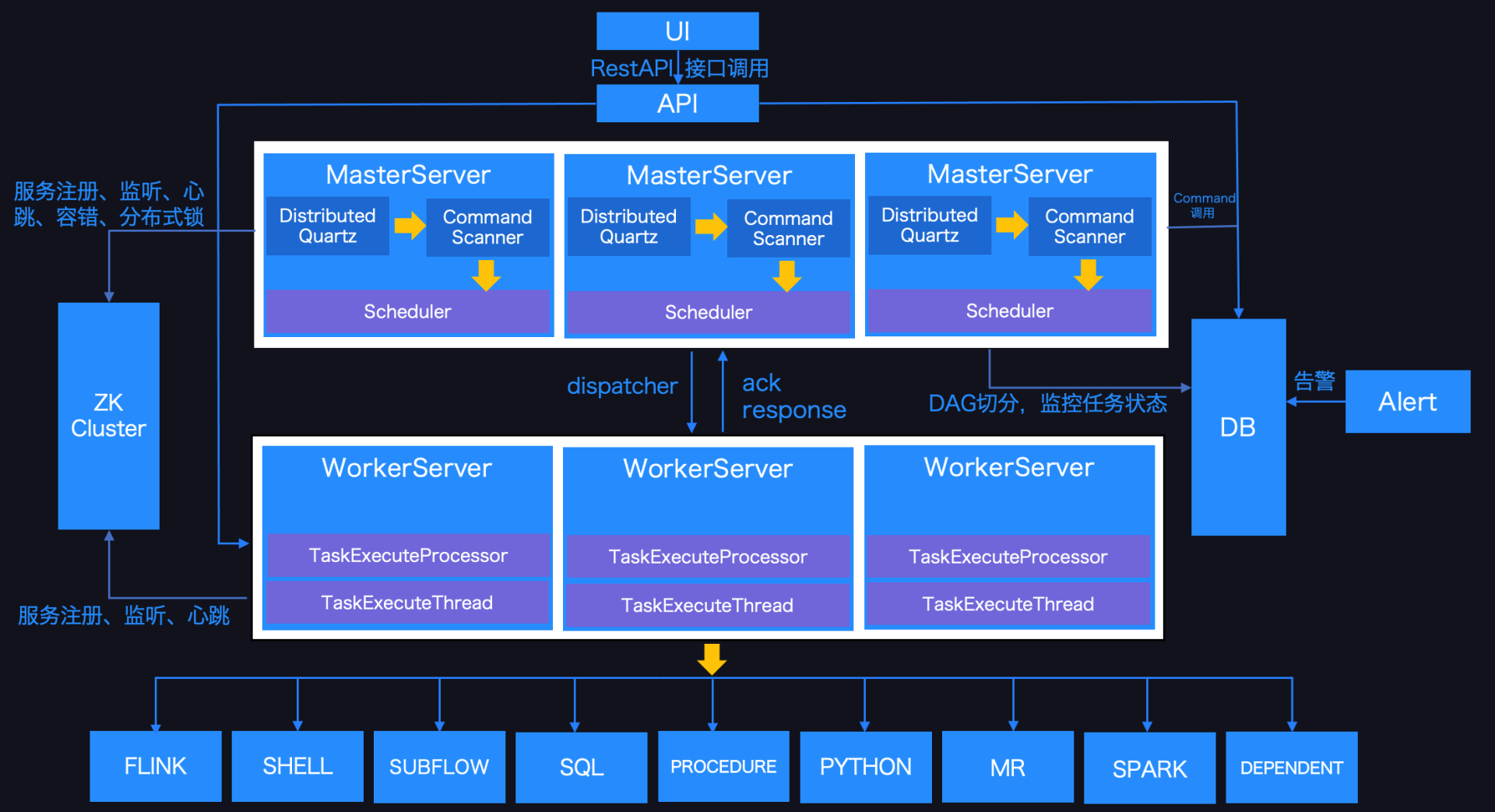
全球最大的开源软件基金会 Apache 软件基金会(以下简称 Apache)于北京时间 2021年4月9日在官方渠道宣布Apache DolphinScheduler 毕业成为Apache顶级项目。这是首个由国人主导并贡献到 Apache 的大数据工作流调度领域的顶级项目。DolphinScheduler™ 已经是联通、IDG、IBM、京东物流、联想、新东方、诺基亚、360、顺丰和腾讯等 400+ 公司在使用 w397090770 4年前 (2021-04-09) 1821℃ 0评论3喜欢
《Hadoop&Spark解决二次排序问题(Spark篇)》《Hadoop&Spark解决二次排序问题(Hadoop篇)》问题描述二次排序就是key之间有序,而且每个Key对应的value也是有序的;也就是对MapReduce的输出(KEY, Value(v1,v2,v3,......,vn))中的Value(v1,v2,v3,......,vn)值进行排序(升序或者降序),使得Value(s1,s2,s3,......,sn),si ∈ (v1,v2,v3,......,vn)且s1 < s2 < s3 < ..... w397090770 9年前 (2015-08-06) 11307℃ 6评论29喜欢
我们都知道,java中的Map结构是key->value键值对存储的,而且根据Map的特性,同一个Map中不存在两个Key相同的元素,而value不存在这个限制。换句话说,在同一个Map中Key是唯一的,而value不唯一。Map是一个接口,我们不能直接声明一个Map类型的对象,在实际开发中,比较常用的Map性数据结构是HashMap和TreeMap,它们都是Map的直接子类 w397090770 11年前 (2013-07-04) 30598℃ 2评论23喜欢
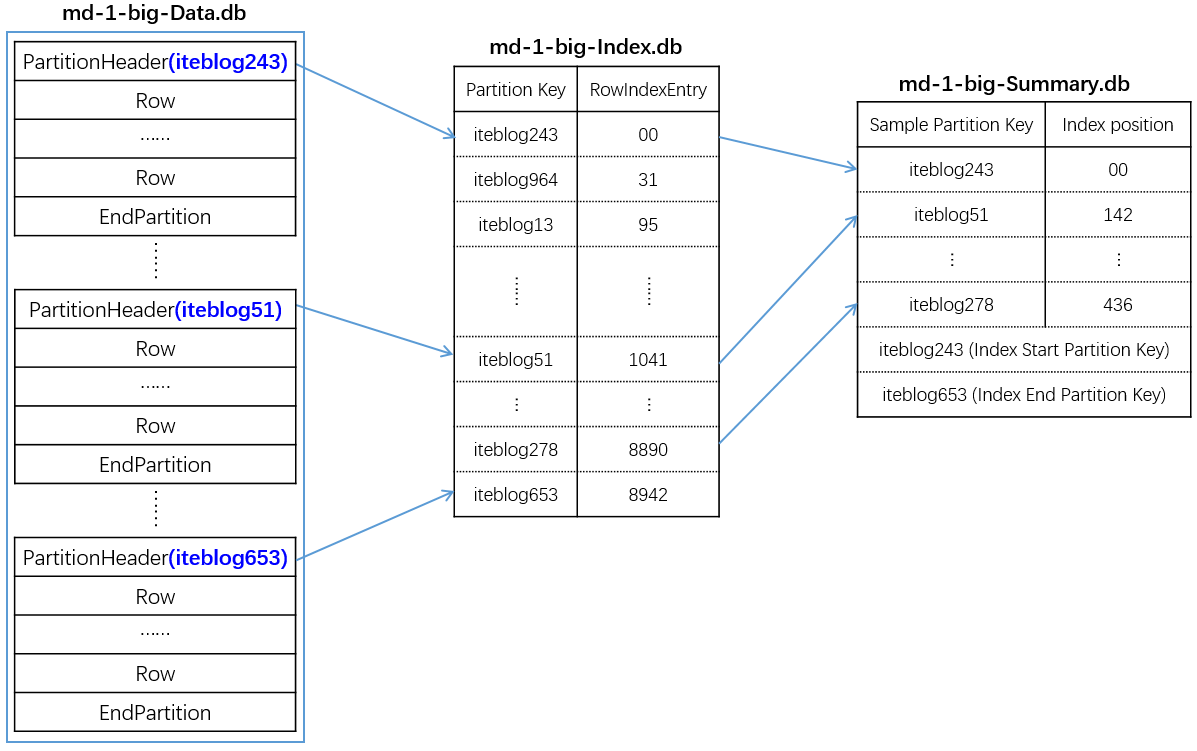
在 Cassandra 中,当达到一定条件触发 flush 的时候,表对应的 Memtable 中的数据会被写入到这张表对应的数据目录(通过 data_file_directories 参数配置)中,并生成一个新的 SSTable(Sorted Strings Table,这个概念是从 Google 的 BigTable 借用的)。每个 SSTable 是由一系列的不可修改的文件组成,这些文件在 Cassandra 中被称为 Component。本文是基于 Cas w397090770 5年前 (2019-05-05) 2172℃ 1评论4喜欢
最近发现离线任务对一个增量Hive表的查询越来越慢,这引起了我的注意,我在cmd窗口手动执行count操作查询发现,速度确实很慢,才不到五千万的数据,居然需要300s,这显然是有问题的,我推测可能是有小文件。我去hdfs目录查看了一下该目录:发现确实有很多小文件,有480个小文件,我觉得我找到了问题所在,那么合并一 zz~~ 3年前 (2021-08-20) 1193℃ 0评论4喜欢
《Spark RDD缓存代码分析》 《Spark Task序列化代码分析》 《Spark分区器HashPartitioner和RangePartitioner代码详解》 《Spark Checkpoint读操作代码分析》 《Spark Checkpoint写操作代码分析》 上次我对Spark RDD缓存的相关代码《Spark RDD缓存代码分析》进行了简要的介绍,本文将对Spark RDD的checkpint相关的代码进行相关的 w397090770 9年前 (2015-11-25) 8893℃ 5评论14喜欢
引言:把基于mapreduce的离线hiveSQL任务迁移到sparkSQL,不但能大幅缩短任务运行时间,还能节省不少计算资源。最近我们也把组内2000左右的hivesql任务迁移到了sparkSQL,这里做个简单的记录和分享,本文偏重于具体条件下的方案选择。迁移背景 SQL任务运行慢Hive SQL处理任务虽然较为稳定,但是其时效性已经达瓶颈,无法再进一 w397090770 3年前 (2021-10-19) 878℃ 0评论2喜欢
迁移指南如果从 0.5.3 以下版本迁移,请检查这个版本后面的其他版本的升级说明。如果需要升级到 0.8 版本,请参阅 0.6.0 版本的升级指南,因为本版本没有引入新的表版本(table versions)HoodieRecordPayload接口不建议使用现有方法,而推荐使用新方法,该方法还允许我们在运行时传递属性。 鼓励用户从不建议使用的方法中迁移 w397090770 3年前 (2021-04-14) 890℃ 0评论2喜欢
在很多场景中我们会使用Shell命令来发送邮件,而且我们还可能在邮件里面添加附件,本文将介绍使用Shell命令发送带附件邮件的几种方式,希望对大家有所帮助。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop使用mail命令mail命令是mailutils(On Debian)或mailx(On RedHat)包中的一部分,我们可以使 w397090770 8年前 (2017-02-23) 16263℃ 0评论12喜欢
在设计网站的时候,如果你某个页面的内容没有满屏,那你的footer会离浏览器底部很远,整体看起来很难看,这里用JavaScript提供一种方法来将footer固定在浏览器底部。[code lang="javascript"]function fixFooter(){ var mainHeight = document.getElementById('main').offsetHeight; var height = document.documentElement.clientHeight - document.g w397090770 10年前 (2014-11-22) 7576℃ 0评论4喜欢
Apache Flink 1.5.0 于昨天晚上正式发布了。在过去五个月的时间里,Flink 社区共解决了超过 780 个 issues。完整的 changelog 看这里: https://issues.apache.org/jira/secure/ReleaseNote.jspa?version=12341764&projectId=12315522。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopFlink 1.5.0 是 1.x.y 版本线上的第六个主要发行版。 w397090770 6年前 (2018-05-26) 3099℃ 0评论12喜欢
如果你在Spark SQL中运行的SQL语句过长的话,会出现 java.lang.StackOverflowError 异常:[code lang="java"]java.lang.StackOverflowError at org.apache.spark.sql.hive.HiveQl$$anonfun$22.apply(HiveQl.scala:924) at org.apache.spark.sql.hive.HiveQl$$anonfun$22.apply(HiveQl.scala:924) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244) at scala.collection.TraversableLike$$anonfun w397090770 7年前 (2017-05-17) 6266℃ 0评论7喜欢
在这篇我们介绍了 Spark Delta Lake 0.4.0 的发布,并提到这个版本支持 Python API 和部分 SQL。本文我们将详细介绍 Delta Lake 0.4.0 Python API 的使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop在本文中,我们将基于 Apache Spark™ 2.4.3,演示一个准时航班情况业务场景中,如何使用全新的 Delta Lake 0.4.0 w397090770 5年前 (2019-10-04) 963℃ 0评论1喜欢
本文将介绍如何通过简单地几步来开始编写你的 Flink Java 程序。要求 编写你的Flink Java程序唯一的要求是需要安装Maven 3.0.4(或者更高)和Java 7.x(或者更高) 创建Flink Java工程使用下面其中一个命令来创建Flink Java工程1、使用Maven archetypes:[code lang="bash"]$ mvn archetype:generate \ -DarchetypeGrou w397090770 9年前 (2016-04-06) 13883℃ 0评论8喜欢
最近修改了Spark的一些代码,然后编译Spark出现了以下的异常信息:[code lang="scala"]error file=/iteblog/spark-1.3.1/streaming/src/main/scala/org/apache/spark/streaming/StreamingContext.scalamessage=File line length exceeds 100 characters line=279error file=/iteblog/spark-1.3.1/streaming/src/main/scala/org/apache/spark/streaming/StreamingContext.scalamessage=File line length exceeds 100 characters w397090770 9年前 (2015-05-20) 6016℃ 0评论3喜欢
题目以及要求:把一个字符串的大写字母放到字符串的后面,各个字符的相对位置不变,不能申请额外的空间。我的实现类似冒泡排序。[code lang="CPP"]#include <stdio.h>#include <string.h>// Author: 397090770// E-mail:wyphao.2007@163.com// Blog: // Date: 2012/09/29//题目以及要求:把一个字符串的大写字母放到字符串的后面,// w397090770 12年前 (2013-04-02) 3908℃ 0评论1喜欢
Apache Cassandra 是一个开源的、分布式、无中心、弹性可扩展、高可用、容错、一致性可调、面向行的数据库,它基于 Amazon Dynamo 的分布式设计和 Google Bigtable 的数据模型,由 Facebook 创建,在一些最流行的网站中得到应用。更多特点请参见 一篇文章了解 Apache Cassandra 是什么。由于 Cassandra 数据库的众多优点,在国内外多达 1500+ 家公 w397090770 5年前 (2019-05-08) 1761℃ 0评论5喜欢
静态分区裁剪(Static Partition Pruning)用过 Spark 的同学都知道,Spark SQL 在查询的时候支持分区裁剪,比如我们如果有以下的查询:[code lang="sql"]SELECT * FROM Sales_iteblog WHERE day_of_week = 'Mon'[/code]Spark 会自动进行以下的优化:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop从上图可以看到,S w397090770 5年前 (2019-11-04) 2629℃ 0评论6喜欢