Apache Hudi : 未来发展
Apache Hudi 是如何处理小文件的
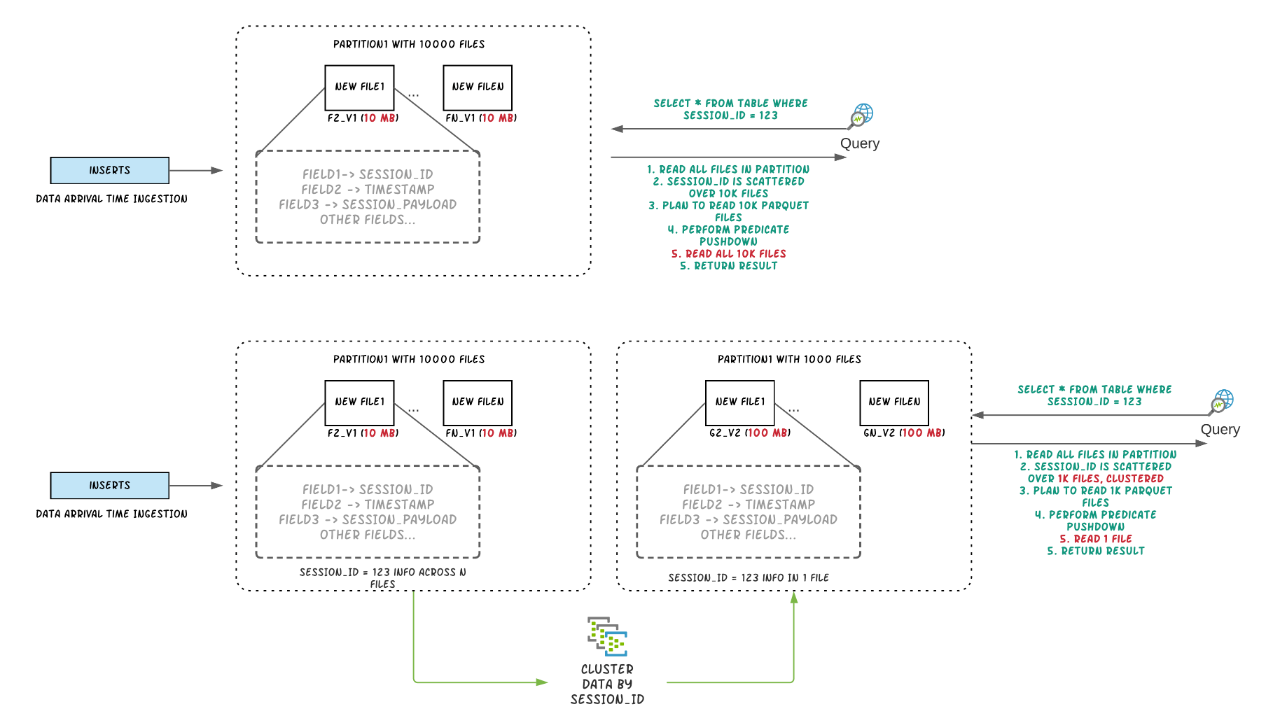
Apache Hudi Clustering 数据布局功能介绍
Apache Hudi 0.7.0 版本发布,新特性介绍
盘点2020年晋升为Apache TLP的大数据相关项目
Apache Hudi 现在也支持 Flink 引擎了
Apache Hudi 0.6.0 版本发布,新功能介绍
官宣,Apache Hudi 正式成为 Apache 顶级项目
下面文章您可能感兴趣
Base122介绍及其使用
Apache Iceberg 代码调试技巧
Akka学习笔记:ActorSystem(配置)
用Spark往Kafka里面写对象设计与实现
第四次杭州Spark Meetup活动详情
Apache Spark DataFrames入门指南:操作DataFrame
Apache HBase 1.3.0正式发布
《过往记忆》博客和iteblog_hadoop微信公共帐号完全整合
Spark 2.0技术预览:更容易、更快速、更智能
SHC:使用 Spark SQL 高效地读写 HBase
京东 ClickHouse 高可用实践
每个 Apache Kafka 开发者都应该知道的5件事
深入理解 Delta Lake 的 DML 实现原理 (Update, Delete, Merge)
图文介绍 Presto + Velox 整合
Linux平台下安装SSH
Spark 1.6.1正式发布
Spark会把数据都载入到内存么
一篇文章理清 NVMe 的前生今世
五年总结:过往记忆大数据公众号原创精选
通过Flink将数据以压缩的格式写入HDFS
发表我的评论
取消评论
提交评论
有人回复时邮件通知我
表情
本博客评论系统带有自动识别垃圾评论功能,请写一些有意义的评论,谢谢!
有人回复时邮件通知我
使用微博登录
使用GitHub登录
使用QQ登录