一、活动时间 北京第九次Spark Meetup活动将于2015年08月22日进行;下午14:00-18:00。二、活动地点 北京市海淀区丹棱街5号 微软亚太研发集团总部大厦1号楼三、活动内容 1、《Keynote》 ,分享人:Sejun Ra ,CEO of NFLabs.com 2、《An introduction to Zeppelin with a demo》,分享人: Anthony Corbacho, Engineer from NFLabs and w397090770 9年前 (2015-08-07) 2843℃ 0评论1喜欢
Avro有C, C++, C#, Java, PHP, Python, and Ruby等语言的实现,本文只简单介绍如何在Java中使用Avro进行数据的序列化(data serialization)。本文使用的是Avro 1.7.4,这是写这篇文章时最新版的Avro。读完本文,你将会学到如何使用Avro编译模式、如果用Avro序列化和反序列化数据。一、准备项目需要的jar包 文本的例子需要用到的Jar包有这四 w397090770 11年前 (2014-04-08) 45081℃ 4评论38喜欢
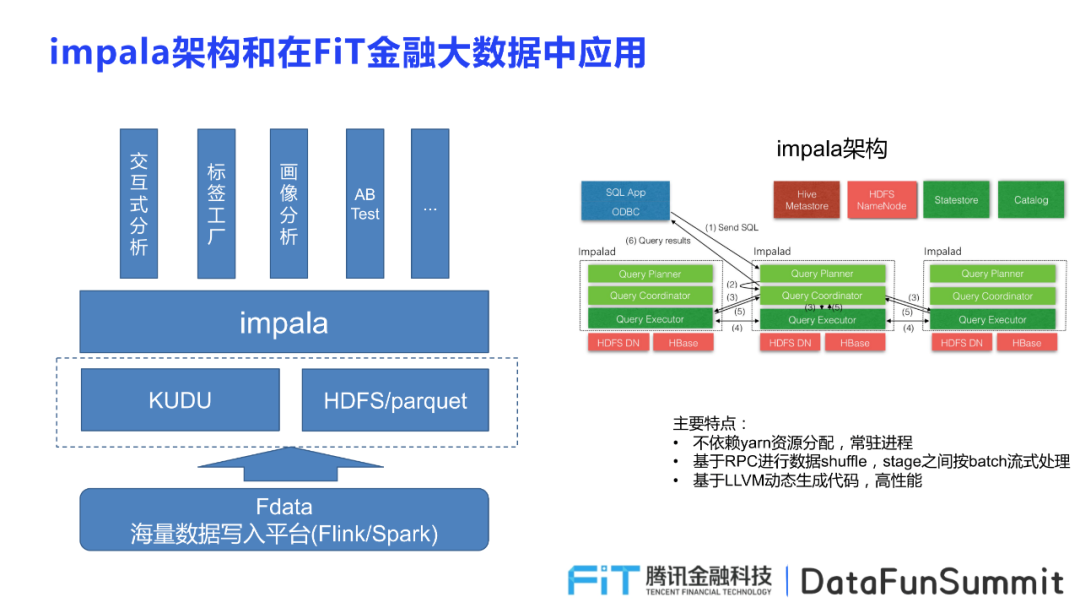
导读:在腾讯金融场景,我们每天都会产生大量的数据,为了提升分析的交互性,让决策更加敏捷,我们引入了Impala来解决我们的分析需求。所以,本文将和大家分享Impala在腾讯金融大数据场景中的应用架构,Impala的原理,落地过程的案例和优化以及总结思考。Impala的架构 首先介绍Impala的整体架构,帮助大家从宏观角度理 w397090770 3年前 (2021-10-28) 417℃ 0评论1喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive的内置数据类型可以分 w397090770 11年前 (2013-12-23) 15508℃ 1评论14喜欢
Programming Hive: Data Warehouse and Query Language for Hadoop 1st Edition 于2012年09月出版,全书共350页,是学习Hive经典的一本书。图书信息如下:Publisher : O'Reilly Media; 1st edition (October 16, 2012)Language : EnglishPaperback : 350 pagesISBN-10 : 1449319335ISBN-13 : 978-1449319335这本指南将向您介绍 Apache Hive, 它是 Hadoop 的数据仓库基础设施。通过这本书将快速 w397090770 9年前 (2015-08-25) 38868℃ 3评论21喜欢
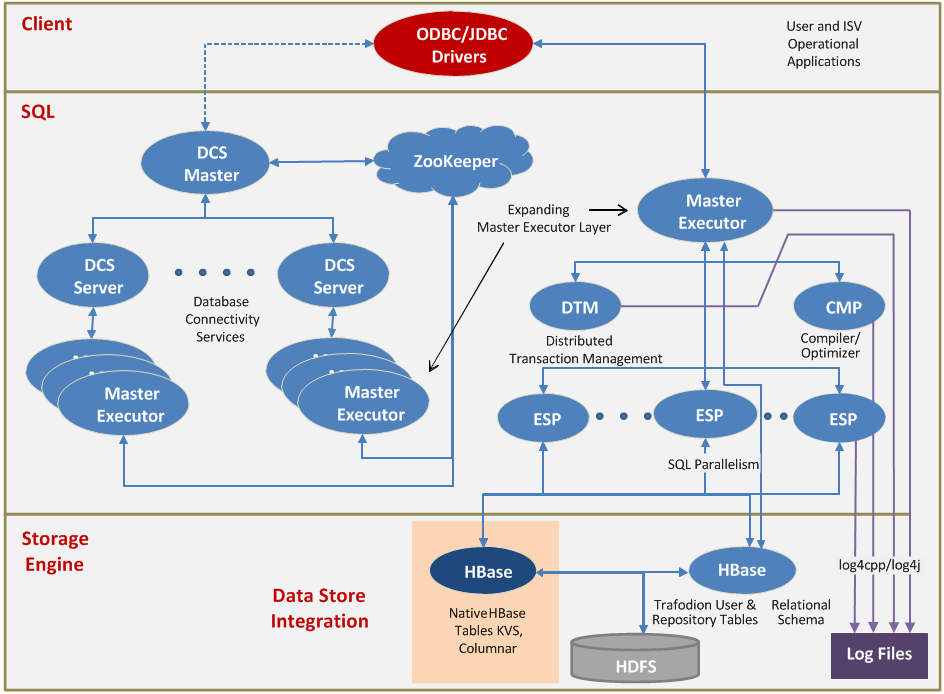
Apache Trafodion 是由惠普开发并开源的基于 Hadoop 平台的事务数据库引擎。提供了一个基于Hadoop平台的交易型SQL引擎。它是一个擅长处理交易型负载的Hadoop大数据解决方案。其主要特性包括:完整的ANSI SQL语言支持完整的ACID事务支持。对于读、写查询,Trafodion支持跨行,跨表和跨语句的事务保护支持多种异构存储引擎的直接访问为应 w397090770 7年前 (2018-01-07) 2398℃ 0评论5喜欢
《Kafka in Action》于 2022年01月由 Manning 出版, ISBN 为 9781617295232 ,全书 272 页。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop图书介绍作者有多年使用 Kafka 的真实世界的经验,这本书的实地感觉真的让它与众不同。---- From the foreword by Jun Rao, Confluent CofounderMaster the wicked-fast Apache Kafka streaming w397090770 3年前 (2022-03-02) 629℃ 0评论3喜欢
点击试试使用Github登录我博客。 随着使用Github的人越来越多,为自己的网站添加Github登录功能也越来越有必要了。Github开放了登录API,第三方网站可以通过调用Github的OAuth相关API读取到登录用户的基本信息,从而使得用户可以通过Github登录到我们的网站。今天来介绍一下如何使用Github的OAuth相关API登录到Wordpress。 w397090770 10年前 (2015-04-12) 11967℃ 9评论12喜欢
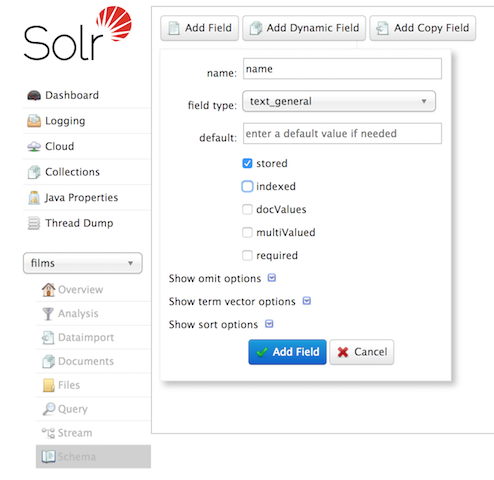
到目前为止,我们往 Solr 里面导数据都没有定义模式,也就是说让 Solr 去猜我们数据的类型以及解析方式,这种方式成为无模式(Schemaless)。Apache Solr 里面的定义为:One reason for this is we’re going to use a feature in Solr called "field guessing", where Solr attempts to guess what type of data is in a field while it’s indexing it. It also automatically creates new fields in th w397090770 6年前 (2018-08-01) 1720℃ 0评论4喜欢
我目前使用的Hive版本是apache-hive-1.2.0-bin,每次在使用 show create table 语句的时候如果你字段中有中文注释,那么Hive得出来的结果如下:hive> show create table iteblog;OKCREATE TABLE `iteblog`( `id` bigint COMMENT '�id', `uid` bigint COMMENT '(7id', `name` string COMMENT '(7�')ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTF w397090770 9年前 (2016-06-08) 11314℃ 0评论13喜欢
在开发Wordpress的时候,我们可能需要获取到设备的类型,比如手机、电脑或者iPad等,然后做出不同的决定,这就要求我们精确地判断出当前设备的类型。熟悉Wordpress的同学会知道,Wordpress中安装目录下的wp-includes/vars.php文件里面有个名为wp_is_mobile的函数,其代码如下:[code lang="php"]function wp_is_mobile() { static $is_mobile = null; w397090770 9年前 (2016-03-01) 2286℃ 0评论1喜欢
我们先来看看官方文档是怎么对Tachyon进行描述的:Tachyon is a memory-centric distributed storage system enabling reliable data sharing at memory-speed across cluster frameworks, such as Spark and MapReduce. It achieves high performance by leveraging lineage information and using memory aggressively. Tachyon caches working set files in memory, thereby avoiding going to disk to load datasets that are frequently w397090770 9年前 (2015-08-27) 3184℃ 4评论2喜欢
本书于2017-08由 Packt 出版,作者 Manish Kumar, Chanchal Singh,全书269页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Learn the basics of Apache Kafka from scratchUse the basic building blocks of a streaming applicationDesign effective streaming applications with Kafka using Spark, Storm &, and HeronUnderstand the i zz~~ 7年前 (2017-11-08) 6659℃ 0评论31喜欢
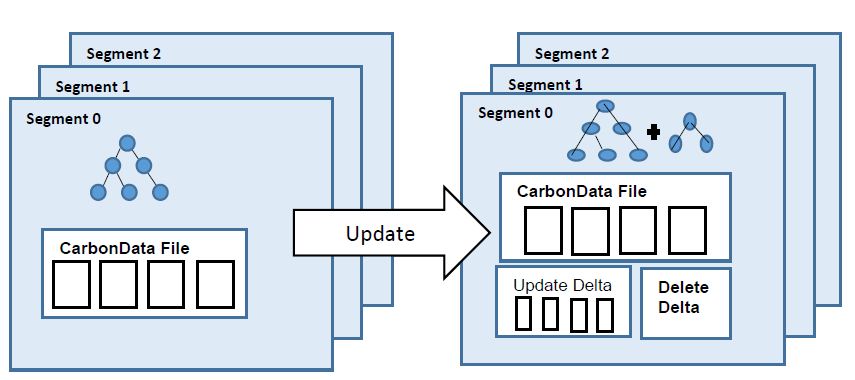
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。 当前,CarbonData暂不支持修改表中已经存在的数据。但是在现实情况下,我们可能很希望这个功能,比如修改 w397090770 8年前 (2016-11-30) 2812℃ 0评论10喜欢
HDFS 架构介绍 HDFS离线存储平台是Hadoop大数据计算的底层架构,在B站应用已经超过5年的时间。经过多年的发展,HDFS存储平台目前已经发展成为总存储数据量近EB级,元数据总量近百亿级,NameSpace 数量近20组,节点数量近万台,日均吞吐几十PB数据量的大型分布式文件存储系统。 首先我们来介绍一下B站的HDFS离线存储平台的总体架 w397090770 3年前 (2022-04-01) 1132℃ 0评论4喜欢
This topic describes tips for tuning parallelism and memory in Presto. The tips are categorized as follows:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopTuning Parallelism at a Task LevelThe number of splits in a cluster = node-scheduler.max-splits-per-node * number of worker nodes.The node-scheduler.max-splits-per-node denotes the target value for the total num w397090770 4年前 (2021-02-20) 1165℃ 0评论4喜欢
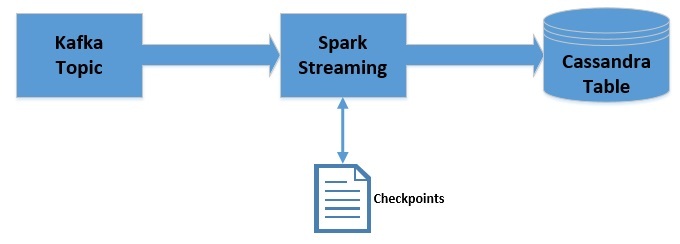
Apache Kafka 是一个可扩展,高性能,低延迟的平台,允许我们像消息系统一样读取和写入数据。我们可以很容易地在 Java 中使用 Kafka。Spark Streaming 是 Apache Spark 的一部分,是一个可扩展、高吞吐、容错的实时流处理引擎。虽然是使用 Scala 开发的,但是支持 Java API。Apache Cassandra 是分布式的 NoSQL 数据库。在这篇文章中,我们将 w397090770 5年前 (2019-09-08) 4061℃ 0评论8喜欢
如果你要寻求一种处理海量数据的解决方案,就会有很多可选项。选择哪一种取决于具体的用例和要对数据进行何种操作,可以从很多种数据处理框架中进行遴选。例如Apache的Samza、Storm和Spark等等。本文将重点介绍Spark的功能,Spark不但非常适合用来对数据进行批处理,也非常适合对时实的流数据进行处理。 Spark目前已经 w397090770 8年前 (2017-02-06) 1682℃ 0评论4喜欢
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计 w397090770 9年前 (2016-05-04) 16852℃ 3评论45喜欢
Flink内置提供了将DataStream中的数据写入到ElasticSearch中的Connector(flink-connector-elasticsearch2_2.10),但是并没有提供将DateSet的数据写入到ElasticSearch。本文介绍如何通过自定义OutputFormat将Flink DateSet里面的数据写入到ElasticSearch。 如果需要将DateSet中的数据写入到外部存储系统(比如HDFS),我们可以通过writeAsText、writeAsCsv、write等内 w397090770 8年前 (2016-10-11) 5838℃ 0评论8喜欢
现象大家在使用 Apache Spark 2.x 的时候可能会遇到这种现象:虽然我们的 Spark Jobs 已经全部完成了,但是我们的程序却还在执行。比如我们使用 Spark SQL 去执行一些 SQL,这个 SQL 在最后生成了大量的文件。然后我们可以看到,这个 SQL 所有的 Spark Jobs 其实已经运行完成了,但是这个查询语句还在运行。通过日志,我们可以看到 driver w397090770 6年前 (2019-01-14) 4239℃ 0评论18喜欢
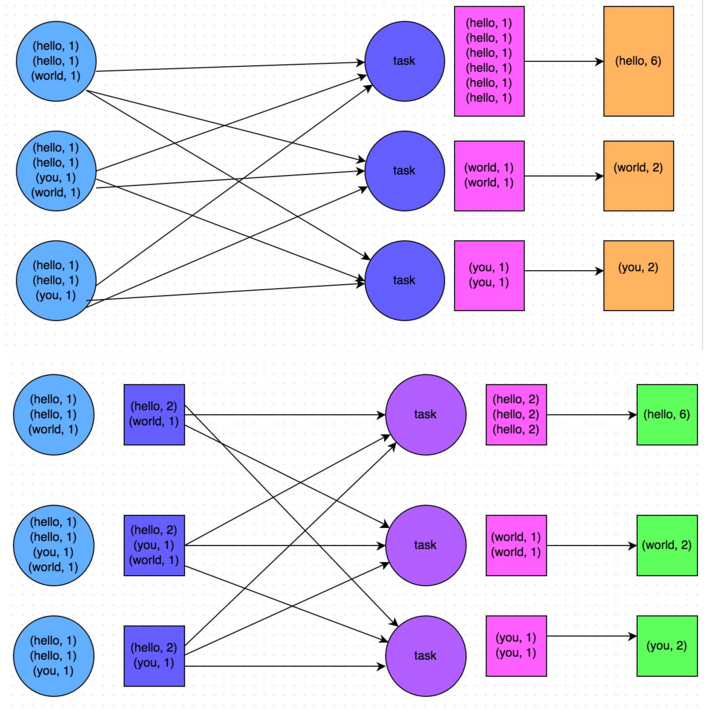
使用用户设置好的聚合函数对每个Key中的Value进行组合(combine)。可以将输入类型为RDD[(K, V)]转成成RDD[(K, C)]。函数原型[code lang="scala"]def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C) : RDD[(K, C)]def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitio w397090770 10年前 (2015-03-19) 22581℃ 0评论23喜欢
Spark Summit East 2016:视频,PPT Spark Summit East 2016会议于2016年2月16日至2月18日在美国纽约进行。总体来说,Spark Summit一年比一年火,单看纽约的峰会中,规模已从900人增加到500个公司的1300人,更吸引到更多大型公司的分享,包括Bloomberg、Capital One、Novartis、Comcast等公司。而在这次会议上,Databricks还发布了两款产品——Commu w397090770 9年前 (2016-02-27) 5675℃ 0评论14喜欢
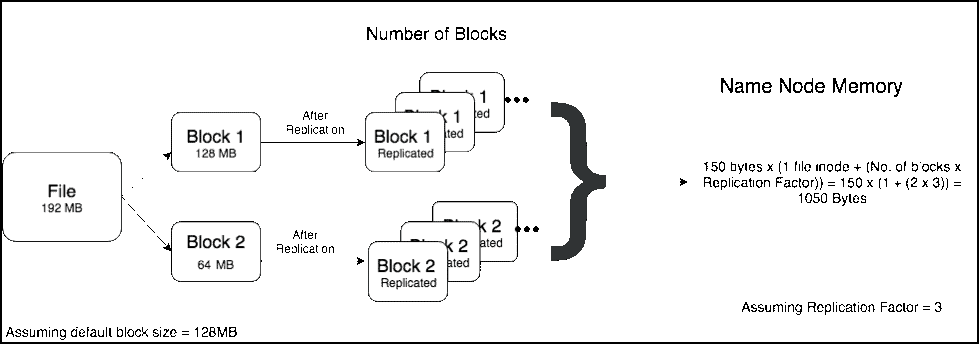
在使用Hadoop过程中,小文件是一种比较常见的挑战,如果不小心处理,可能会带来一系列的问题。HDFS是为了存储和处理大数据集(M以上)而开发的,大量小文件会导致Namenode内存利用率和RPC调用效率低下,block扫描吞吐量下降,应用层性能降低。通过本文,我们将定义小文件存储的问题,并探讨如何对小文件进行治理。什么是小 w397090770 4年前 (2021-02-24) 1055℃ 0评论6喜欢
Apache Hudi 是一种数据湖平台技术,它提供了构建和管理数据湖所需的几个功能。hudi 提供的一个关键特性是自我管理文件大小,这样用户就不需要担心手动维护表。拥有大量的小文件将使计算更难获得良好的查询性能,因为查询引擎不得不多次打开/读取/关闭文件以执行查询。但是对于流数据湖用例来说,可能每次都只会写入很少的 w397090770 3年前 (2021-08-03) 1097℃ 0评论1喜欢
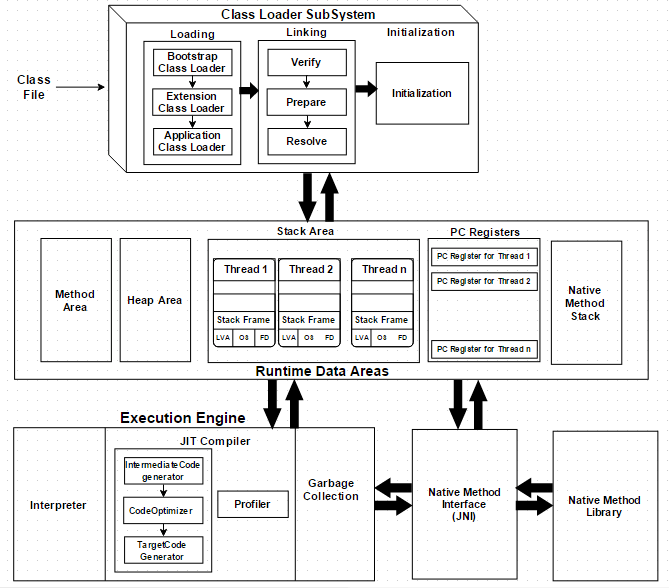
每个Java开发人员都知道字节码经由JRE(Java运行时环境)执行。但他们或许不知道JRE其实是由Java虚拟机(JVM)实现,JVM分析字节码,解释并执行它。作为开发人员,了解JVM的架构是非常重要的,因为它使我们能够编写出更高效的代码。本文中,我们将深入了解Java中的JVM架构和JVM的各个组件。JVM 虚拟机是物理机的软件 w397090770 8年前 (2017-01-01) 3613℃ 0评论12喜欢
在C++中,对象所占的内存在程序结束运行之前一直被占用,需要我们明确释放;而在Java中,当没有对象引用指向原先分配给某个对象的内存时,该内存便成为垃圾。JVM的一个系统级线程会自动释放该内存块。 垃圾收集意味着程序不再需要的对象是"无用信息",这些信息将被丢弃。当一个对象不再被引用的时候,内存回收它 w397090770 11年前 (2013-10-14) 7466℃ 2评论9喜欢
1、Hive内部表和外部表的区别? 1、在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而表则不一样; 2、在删除表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的! 那么, w397090770 8年前 (2016-08-26) 5658℃ 2评论20喜欢
Spark支持读取很多格式的文件,其中包括了所有继承了Hadoop的InputFormat类的输入文件,以及平时我们常用的Text、Json、CSV (Comma Separated Values) 以及TSV (Tab Separated Values)文件。本文主要介绍如何通过Spark来读取Json文件。很多人会说,直接用Spark SQL模块的jsonFile方法不就可以读取解析Json文件吗?是的,没错,我们是可以通过那个读取Json w397090770 10年前 (2015-01-06) 26964℃ 10评论15喜欢
在前面的文章《Kafka集群扩展以及重新分布分区》中,我们将介绍如何通过Kafka自带的工具来增加Topic的分区数量。本文将简单地介绍如何通过Kafka自带的工具来动态增加Tpoic的副本数。首先来看看我们操作的Topic相关的信息[iteblog@www.iteblog.com ~]$ kafka-topics.sh --topic iteblog --describe --zookeeper www.iteblog.com:2181Topic:iteblog PartitionCount:2 w397090770 9年前 (2016-04-18) 11454℃ 0评论14喜欢








![[电子书]Building Data Streaming Applications with Apache Kafka PDF下载](https://www.iteblog.com/pic/books/building-data-streaming-applications-apache-kafka-iteblog.png)