昨天我提到了如何在《Flink Streaming中实现多路文件输出(MultipleTextOutputFormat)》,里面我们实现了一个MultipleTextOutputFormatSinkFunction类,其中封装了mutable.Map[String, TextOutputFormat[String]],然后根据key的不一样选择不同的TextOutputFormat从而实现了文件的多路输出。本文将介绍如何在Flink batch模式下实现文件的多路输出,这种模式下比较简单 w397090770 9年前 (2016-05-11) 4049℃ 3评论6喜欢
从上周开始,我博客就经常出现了Bad Request (Invalid Hostname)错误,询问网站服务器商只得知网站的并发过高,从而被服务器商限制网站访问。可是我天天都会去看网站的流量统计,没有一点异常,怎么可能会并发过高?后来我查看了一下网站的搜索引擎抓取网站的日志,发现每分钟都有大量的页面被搜索引擎抓取!难怪网站的并 w397090770 10年前 (2014-11-14) 3211℃ 0评论6喜欢
1.文件大小默认为64M,改为128M有啥影响?2.RPC的原理?3.NameNode与SecondaryNameNode的区别与联系?4.介绍MadpReduce整个过程,比如把WordCount的例子的细节将清楚(重点讲解Shuffle)?5.MapReduce出现单点负载多大,怎么负载平衡?6.MapReduce怎么实现Top10?7.hadoop底层存储设计8.zookeeper有什么优点,用在什么场合9.Hbase中的meta w397090770 8年前 (2016-08-26) 3583℃ 0评论2喜欢
我们是负责58同城商业广告变现的商业工程技术团队,负责竞价排名类广告系统研发,包含广告投放系统,广告检索系统,以及广告投放策略的研究、实现。在这里,你将面临严密的商业逻辑的挑战,高并发、大数据量的挑战,如何认知数据、应用数据的挑战。高级大数据研发工程师 工作职责:负责或参与58商业数据仓库 w397090770 5年前 (2020-05-21) 1370℃ 0评论8喜欢
一. 问答题1. 简单说说map端和reduce端溢写的细节2. hive的物理模型跟传统数据库有什么不同3. 描述一下hadoop机架感知4. 对于mahout,如何进行推荐、分类、聚类的代码二次开发分别实现那些接口5. 直接将时间戳作为行健,在写入单个region 时候会发生热点问题,为什么呢?二. 计算题1. 比方:如今有10个文件夹, 每个 w397090770 8年前 (2016-08-26) 3152℃ 0评论1喜欢
用 Kafka 这么久,从来都没去了解 Kafka 消息的格式。今天特意去网上搜索了以下,发现这方面的资料真少,很多资料都是官方文档的翻译;而且 Kafka 消息支持压缩,对于压缩消息的格式的介绍更少。基于此,本文将以图文模式介绍 Kafka 0.7.x、0.8.x 以及 0.10.x 等版本 Message 格式,因为 Kafka 0.9.x 版本的消息格式和 0.8.x 一样,我就不单独 w397090770 7年前 (2017-08-11) 3724℃ 0评论16喜欢
学过计算机编程的就知道,在计算机中,浮点数是不可能用浮点数精确的表达的,如果你需要精确的表达这个小数,我们最好是用分数的形式来表示,而且有限小数或无限小数都是可以转化为分数的形式。比如下面的几个小数:[code lang="bash"]0.3333(3) = 1/3的(其中括号中的数字是表示循环节)0.3 = 3 / 100.25 = 1 / 40. 285714(285714) = w397090770 12年前 (2013-03-31) 5446℃ 1评论8喜欢
Spark目前被越来越多的企业使用,和Hadoop一样,Spark也是以作业的形式向集群提交任务,那么在内部实现Spark和Hadoop作业模型都一样吗?答案是不对的。 熟悉Hadoop的人应该都知道,用户先编写好一个程序,我们称为Mapreduce程序,一个Mapreduce程序就是一个Job,而一个Job里面可以有一个或多个Task,Task又可以区分为Map Task和Reduce T w397090770 10年前 (2014-11-11) 21152℃ 1评论34喜欢
Apache Spark 2.1.0是 2.x 版本线的第二个发行版。此发行版在为Structured Streaming进入生产环境做出了重大突破,Structured Streaming现在支持了event time watermarks了,并且支持Kafka 0.10。此外,此版本更侧重于可用性,稳定性和优雅(polish),并解决了1200多个tickets。以下是本版本的更新:Core and Spark SQL Spark官方发布新版本时,一般 w397090770 8年前 (2016-12-30) 4245℃ 0评论8喜欢
Apache Kafka 2.6.0 于2020年08月03日正式发布。在这个版本中,社区做了很多显著的性能改进,特别是当 Broker 有非常多的分区时。Broker 关闭性能得到了显著提高;当生产者使用压缩时,性能也得到了显著提高。ACL 使用的各个方面都有不同程度的提升,并且需要更少的内存。这个版本还增加了对 Java 14 的支持。在过去的几个版本中,社 w397090770 4年前 (2020-08-23) 898℃ 0评论0喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 122.246.148.77 8090 高匿名 HTTP 浙 w397090770 10年前 (2015-05-15) 41137℃ 0评论0喜欢
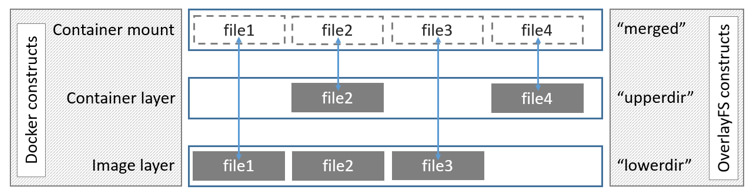
我们在 Docker 入门教程:镜像分层 和 Docker 入门教程:Docker 基础技术 Union File System 已经介绍了一些前提基础知识,本文我们来介绍 Union File System 在 Docker 的应用。为了使 Docker 能够在 container 的 writable layer 写一些比较小的数据(如果需要写大量的数据可以通过挂载盘去写),Docker 为我们实现了存储驱动(storage drivers)。Docker 使 w397090770 5年前 (2020-02-16) 788℃ 0评论5喜欢
分布式计算开源框架Hadoop近日发布了今年的第一个版本Hadoop-2.3.0,新版本不仅增强了核心平台的大量功能,同时还修复了大量bug。新版本对HDFS做了两个非常重要的增强:(1)、支持异构的存储层次;(2)、通过数据节点为存储在HDFS中的数据提供了内存缓存功能。 借助于HDFS对异构存储层次的支持,我们将能够在同一个Hado w397090770 11年前 (2014-03-02) 4138℃ 0评论1喜欢
分享嘉宾:Xiaochun He OPPO,编辑整理:门君仪 澳洲国立大学 导读:OPPO是一家智能终端制造公司,有着数亿的终端用户,手机 、IoT设备产生的数据源源不断,设备的智能化服务需要我们对这些数据做更深层次的挖掘。海量的数据如何低成本存储、高效利用是大数据部门必须要解决的问题。目前业界流行的解决方案是数据湖,本次 w397090770 3年前 (2022-02-18) 426℃ 0评论2喜欢
使用 MAC 写移动硬盘的时候会出现 Read-only file system,我们可以使用下面方法来解决。[code code="bash"]iteblog: iteblog $ diskutil info /Volumes/Seagate\ Backup\ Plus\ Drive/ Device Identifier: disk2s1 Device Node: /dev/disk2s1[/code]记下上面的 Device Node。然后使用下面命令弹出我们插入的移动硬盘:[code code="bash"]iteblog: iteblog $ hdiutil eje w397090770 4年前 (2021-01-05) 2292℃ 0评论2喜欢
Apache Hudi 对个人和组织何时有用如果你希望将数据快速提取到HDFS或云存储中,Hudi可以提供帮助。另外,如果你的ETL /hive/spark作业很慢或占用大量资源,那么Hudi可以通过提供一种增量式读取和写入数据的方法来提供帮助。作为一个组织,Hudi可以帮助你构建高效的数据湖,解决一些最复杂的底层存储管理问题,同时将数据更快 w397090770 5年前 (2019-12-23) 1908℃ 0评论2喜欢
目前,Apache Kafka 使用 Apache ZooKeeper 来存储它的元数据,比如分区的位置和主题的配置等数据就是存储在 ZooKeeper 集群中。在 2019 年社区提出了一个计划,以打破这种依赖关系,并将元数据管理引入 Kafka 本身。所以 Apache Kafka 为什么要移除 Zookeeper 的依赖?Zookeeper 有什么问题?实际上,问题不在于 ZooKeeper 本身,而在于外部元数据 w397090770 5年前 (2020-05-19) 1415℃ 0评论1喜欢
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》High Level Consumer 很多时候,客户程序只是希望从Kafka读取数据,不太关心消息offset的处理。同时也希望提供一些语义,例如同 w397090770 9年前 (2015-09-08) 9647℃ 0评论22喜欢
当前 Spark 计算引擎能够利用一些统计信息选择合适的 Join 策略(关于 Spark 支持的 Join 策略可以参见每个 Spark 工程师都应该知道的五种 Join 策略),但是由于各种原因,比如统计信息缺失、统计信息不准确等原因,Spark 给我们选择的 Join 策略不是正确的,这时候我们就可以人为“干涉”,Spark 从 2.2.0 版本开始(参见SPARK-16475),支 w397090770 4年前 (2020-09-15) 3489℃ 0评论3喜欢
我下载的Apache Zeppelin和Apache Spark版本分别为:0.6.0-incubating-SNAPSHOT和1.5.2,在Zeppelin中使用SQLContext读取Json文件创建DataFrame的过程中出现了以下的异常:[code lanh="scala"]val profilesJsonRdd =sqlc.jsonFile("hdfs://www.iteblog.com/tmp/json")val profileDF=profilesJsonRdd.toDF()profileDF.printSchema()profileDF.show()profileDF.registerTempTable("profiles") w397090770 9年前 (2016-01-21) 6860℃ 2评论11喜欢
题目描述:将一个长度超过100位数字的十进制非负整数转换为二进制数输出。输入:多组数据,每行为一个长度不超过30位的十进制非负整数。(注意是10进制数字的个数可能有30个,而非30bits的整数)输出:每行输出对应的二进制数。样例输入:0138样例输出:01111000分析:这个数不应该存储到一个int类型变量里面去 w397090770 12年前 (2013-04-03) 5956℃ 0评论5喜欢
1、Hive内部表和外部表的区别? 1、在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而表则不一样; 2、在删除表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的! 那么, w397090770 8年前 (2016-08-26) 5658℃ 2评论20喜欢
流处理系统月刊是一份专门收集关于Spark、Flink、Kafka、Apex等流处理系统的技术干货月刊,完全免费,每天更新,欢迎关注。下面资源如无法正常访问,请使用《最新可访问Google的Hosts文件》或《Tunnello:免费的浏览器翻墙插件》进行科学上网。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoo w397090770 8年前 (2016-10-07) 4353℃ 0评论5喜欢
前两篇文章,《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 和 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 分别介绍了两种方法读取加盐之后的 HBase 表。本文将介绍如何在 MapReduce 读取加盐之后的表。在 MapReduce 中也可以使用 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 文章里面的 SaltRangeTableInputForm w397090770 6年前 (2019-02-27) 2946℃ 0评论7喜欢
SBT默认的日志级别是Info,我们可以根据自己的需要去设置它的默认日志级别,比如我们在开发过程中,就可以打开Debug日志级别,这样可以看出SBT是如何工作的。SBT的日志级别在sbt.Level类里面定义:[code lang="scala"]object Level extends Enumeration{ val Debug = Value(1, "debug") val Info = Value(2, "info") val Warn = Value(3, "warn&q w397090770 9年前 (2015-12-24) 3458℃ 0评论8喜欢
在今年的09月08日,Google在其安全博客中宣布:为了让用户更加方便了解他们与网站之间的连接是否安全,从2017年1月份正式发布的Chrome 56开始,Google将彻底把含有密码登录和交易支付等个人隐私敏感内容的HTTP页面标记为【不安全】,并且将会在后续更新的Chrome版本中,逐渐把所有的HTTP网站标记为【不安全】。HTTPS已成为网站的 w397090770 8年前 (2016-12-15) 3250℃ 0评论8喜欢
在本博客的《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(一)》《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(二)》两篇文章中我介绍了如何在Hadoop中根据Key或者Value的不同将属于不同的类型记录写到不同的文件中。在里面用到了MultipleOutputFormat这个类。 因为Spark内部写文件方式其实调用的都是Hadoop那一套东 w397090770 10年前 (2015-03-11) 21001℃ 19评论17喜欢
随着 Uber 业务的扩张,为其提供支持的基础数据呈指数级增长,因此处理成本也越来越高。 当大数据成为我们最大的运营开支之一时,我们开始了一项降低数据平台成本的举措,该计划将挑战分为三部分:平台效率、供应和需求。 本文将讨论我们为提高数据平台效率和降低成本所做的努力。如果想及时了解Spark、Hadoop或者HBase w397090770 3年前 (2021-09-05) 442℃ 0评论2喜欢
如今大数据和机器学习已经有了很大的结合,在机器学习里面,因为计算迭代的时间可能会很长,开发人员一般会选择使用 GPU、FPGA 或 TPU 来加速计算。在 Apache Hadoop 3.1 版本里面已经开始内置原生支持 GPU 和 FPGA 了。作为通用计算引擎的 Spark 肯定也不甘落后,来自 Databricks、NVIDIA、Google 以及阿里巴巴的工程师们正在为 Apache Spark 添加 w397090770 6年前 (2019-03-10) 6473℃ 0评论9喜欢
重庆博尼施科技有限公司是一家商用车全周期方案服务商,利用车联网、云计算、移动互联网技术,在物流领域 为商用车的生产、销售、使用、售后、回收各个环节提供一站式解决方案,其中的新能源车辆监控系统就是由该公司提供的,本文是阿里云客户重庆博尼施科技有限公司介绍如何使用阿里云 HBase 来实现新能源车辆监控系统 w397090770 6年前 (2018-11-29) 4289℃ 2评论16喜欢