如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop
Apache Eagle 官方网址:
https://eagle.apache.org/
本博客文章除特别声明,全部都是原创!
原创文章版权归过往记忆大数据(
过往记忆
)所有,未经许可不得转载。
本文链接:
【Apache Eagle: 分布式实时Hadoop数据安全方案】(https://www.iteblog.com/archives/2315.html)
喜欢 (
8
)
赏
分享 (
0
)
Apache SystemML:为大数据优化的声明式机器学习平台
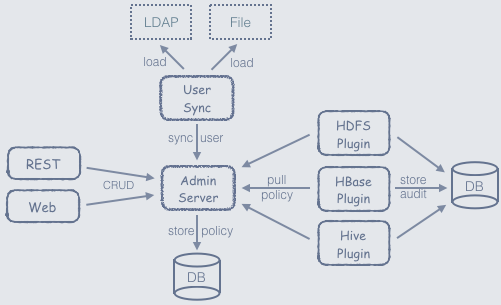
Apache Ranger:统一授权管理框架
Uber 向 Apache 软件基金会提交开源大数据存储库 Hudi
Open Distro for Elasticsearch:AWS 自家版本的开源 ElasticSearch
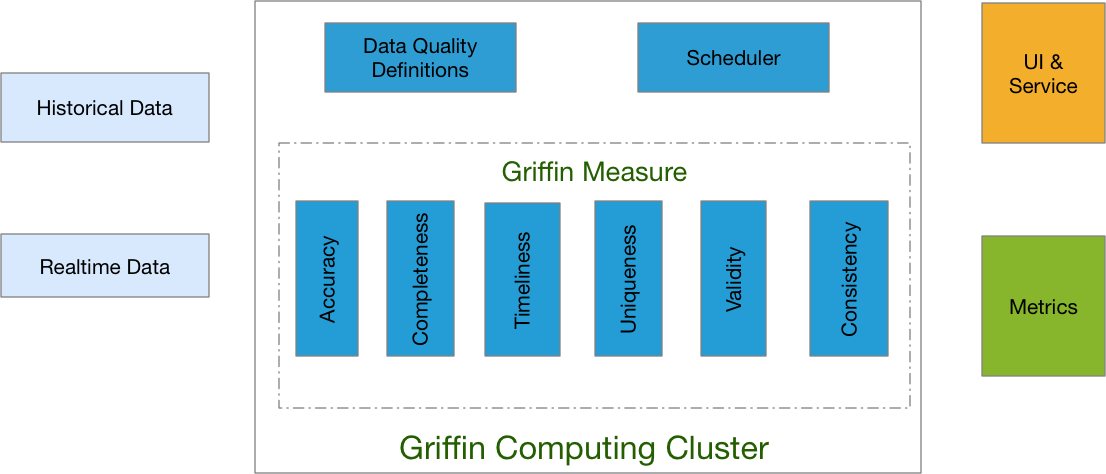
Apache Griffin:分布式系统的数据质量解决方案
盘点2018年晋升为Apache TLP的大数据相关项目
Apache Pulsar:雅虎开发的企业级发布订阅消息系统
Apache Ranger:统一授权管理框架
Apache SystemML:为大数据优化的声明式机器学习平台
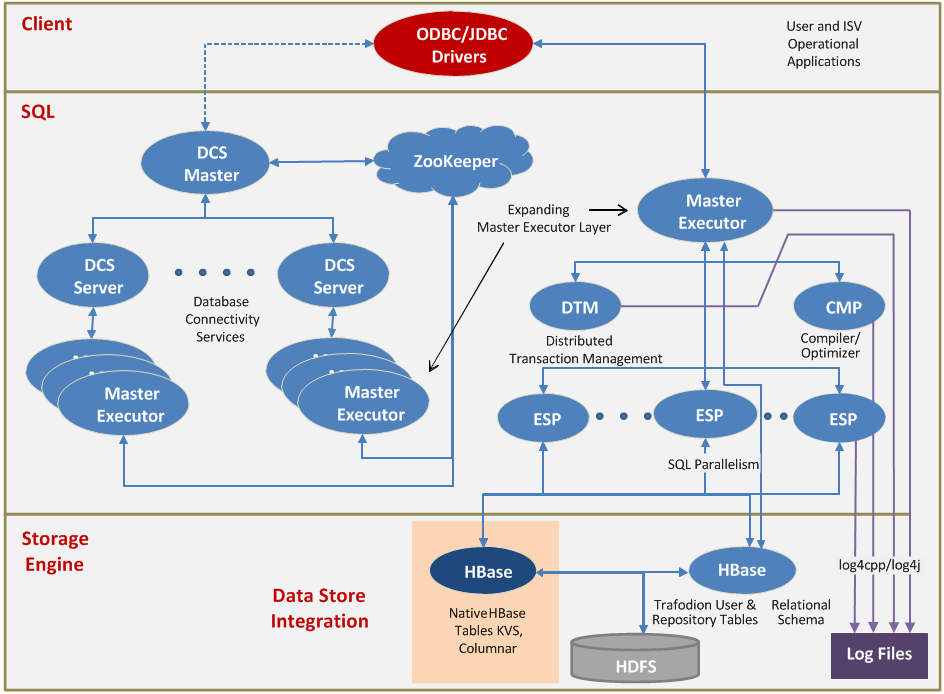
Apache Trafodion:基于 Hadoop 平台的事务数据库引擎
下面文章您可能感兴趣
MMLSpark:微软开源的用于Spark的深度学习库
Flume-0.9.4配置Hbase sink
用Hive分析nginx日志
Apache Beam发布第一个稳定版,适用于企业的部署
Guava学习之TreeMultimap
基于 Kubernetes 构建多集群的流水线
在Kafka中使用Avro编码消息:Producter篇
23种非常有用的ElasticSearch查询例子(3)
Hadoop2.2.0完全分布式集群平台安装与设置
Flink 1.11 与 Hive 批流一体数仓实践
Presto 常用函数介绍
解决Hive中show create table乱码问题
使用Python编写Hive UDF
Spark on YARN集群模式作业运行全过程分析
程序员都应该了解的日历计法:儒略历、格里历和外推格里历
HDFS RBF 在车好多的应用
Spark中函数addFile和addJar函数介绍
通过编程方式获取Kafka中Topic的Metadata信息
如何在CDH 5上运行Spark应用程序
一篇文章了解 Spark Shuffle 内存使用
发表我的评论
取消评论
提交评论
有人回复时邮件通知我
表情
本博客评论系统带有自动识别垃圾评论功能,请写一些有意义的评论,谢谢!
有人回复时邮件通知我
使用微博登录
使用GitHub登录
使用QQ登录