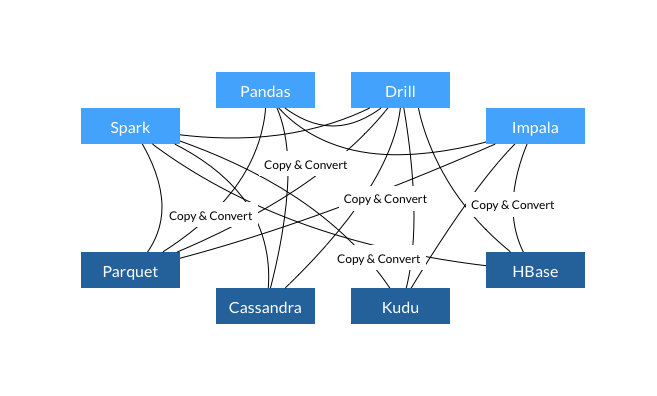
在使用Apache Arrow项目的系统数据交互过程中:(1)、所有系统都使用同一个内存格式;(2)、避免了系统间通信的开销;(3)、项目间可以共享功能(比如Parquet-to-Arrow reader)如下图所示: