Monarch 是 Pinterest 的批处理平台,由30多个 Hadoop YARN 集群组成,其中17k+节点完全建立在 AWS EC2 之上。2021年初,Monarch 还在使用五年前的 Hadoop 2.7.1。由于同步社区分支(特性和bug修复)的复杂性不断增加,我们决定是时候进行版本升级了。我们最终选择了Hadoop 2.10.0,这是当时 Hadoop 2 的最新版本。本文分享 Pinterest 将 Monarch 升级到 Ha w397090770 2年前 (2022-08-12) 594℃ 0评论3喜欢
本文介绍了如何使用 Presto 通过 Alluxio 查询 Iceberg 表。由于这项功能目前处于试验阶段,此处提供的信息可能会发生变化,请及时参考官方文档了解最新功能。关于如何使用 Presto 读取 Iceberg 上的数据请参考这里。我们知道,在 Hive 数据源上,Presto 支持两种形式的 Alluxio 缓存:通过 Alluxio local cache 以及 Alluxio Cluster,截止到本文章 w397090770 3年前 (2021-11-18) 1228℃ 0评论6喜欢
本文系奇虎360系统部相关工程师投稿。近两年人工智能技术发展迅速,以Google开源的TensorFlow为代表的各种深度学习框架层出不穷。为了方便算法工程师使用各类深度学习技术,减少繁杂的诸如运行环境部署运维等工作,提升GPU等硬件资源利用率,节省硬件投入成本,奇虎360系统部大数据团队与人工智能研究院联合开发了深度学习 w397090770 7年前 (2017-12-08) 2744℃ 0评论15喜欢
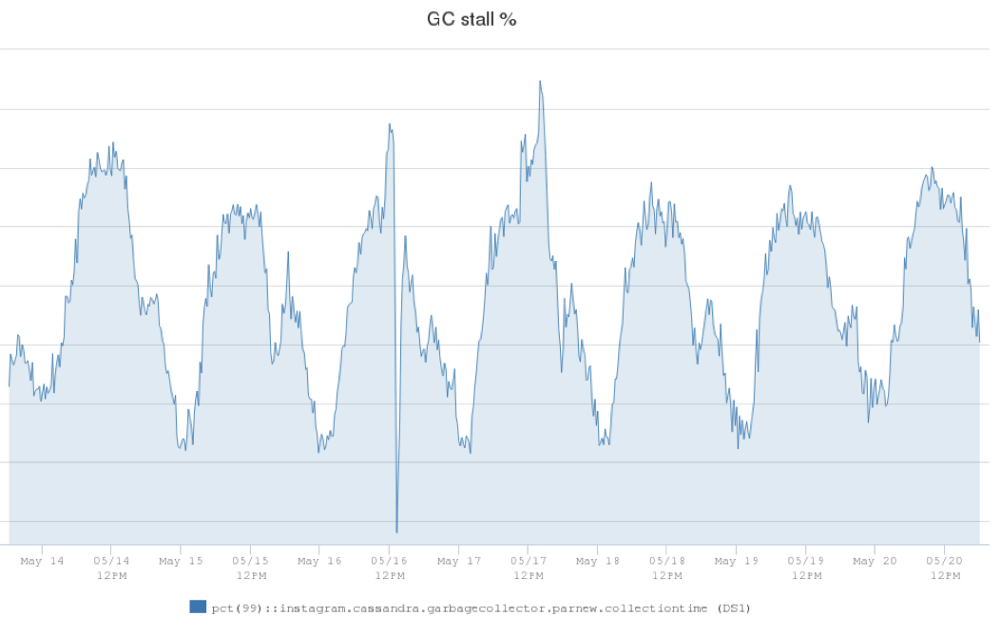
在 Instagram (Instagram 是 Facebook 公司旗下一款免费提供在线图片及视频分享的社交应用软件,于2010年10月发布。)上,我们拥有世界上最大的 Apache Cassandra 数据库部署。我们在 2012 年开始使用 Cassandra 取代 Redis ,在生产环境中支撑欺诈检测,Feed 和 Direct inbox 等产品。起初我们在 AWS 环境中运行了 Cassandra 集群,但是当 Instagram 架构发生 w397090770 5年前 (2019-05-08) 1142℃ 0评论0喜欢
一个功能健全的kafka集群可以处理相当大的数据量,由于消息系统是很多大型应用的基石,因此broker集群在性能上的缺陷,都会引起整个应用栈的各种问题。Kafka的度量指标主要有以下三类:1.Kafka服务器(Kafka)指标2.生产者指标3.消费者指标另外,由于Kafka的状态靠Zookeeper来维护,对于Zookeeper性能的监控也成为了整个Ka zz~~ 2年前 (2022-05-01) 1293℃ 0评论0喜欢
Spark Summit 2016 San Francisco会议于2016年6月06日至6月08日在美国San Francisco进行。本次会议有多达150位Speaker,来自业界顶级的公司。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料全部通过爬虫程序下载,如有问题 w397090770 8年前 (2016-06-15) 3368℃ 0评论9喜欢
我们先来看看aggregate函数的官方文档定义:Aggregate the elements of each partition, and then the results for all the partitions, using given combine functions and a neutral "zero value". This function can return a different result type, U, than the type of this RDD, T. Thus, we need one operation for merging a T into an U and one operation for merging two U's, as in scala.TraversableOnce. Both of these functions w397090770 10年前 (2015-02-12) 37385℃ 5评论23喜欢
本文来自上周(2020-11-17至2020-11-19)举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Spark SQL Beyond Official Documentation》的分享,作者 David Vrba,是 Socialbakers 的高级机器学习工程师。实现高效的 Spark 应用程序并获得最大的性能为目标,通常需要官方文档之外的知识。理解 Spark 的内部流程和特性有助于根据内部优化设计查询 w397090770 4年前 (2020-11-24) 1154℃ 0评论4喜欢
今天我有一个网站空间到期了,如果去续费空间是可以的,但是那空间是国内的,一般国内的空间都是比较贵,所以我突然想到为什么不一个网站空间配置两个独立的网站呢?虽然网站空间是一样的,但是结果配置可以使得两个不同域名访问的网站不一样,也就是说互不干扰。当然这个前提是你空间所在的服务器支持我们把一 w397090770 12年前 (2013-04-26) 4763℃ 1评论5喜欢
在 《Apache Solr 安装部署及索引创建》 文章里面我创建了一个名为 iteblog 的 core,并在里面导入了一些测试数据,然后在 《使用 Apache Solr 检索数据》 里面介绍了 Solr 中一些简单的查询。可能有同学按照上面文章介绍,在使用下面的查询发现啥都查不到:[code lang="bash"][root@iteblog.com /opt/solr-7.4.0]$ curl http://iteblog.com:8983/solr/iteblog/select w397090770 6年前 (2018-07-27) 1498℃ 0评论4喜欢
什么是SSH?Secure Shell(缩写为SSH),由IETF的网络工作小组(Network Working Group)所制定;SSH为一项创建在应用层和传输层基础上的安全协议,为计算机上的Shell(壳层)提供安全的传输和使用环境。传统的网络服务程序,如rsh、FTP、POP和Telnet其本质上都是不安全的;因为它们在网络上用明文传送数据、用户帐号和用户口令,很容 w397090770 11年前 (2013-10-22) 8709℃ 3评论2喜欢
一、简介1.14 新版本原本规划有 35 个比较重要的新特性以及优化工作,目前已经有 26 个工作完成;5 个任务不确定是否能准时完成;另外 4 个特性由于时间或者本身设计上的原因,会放到后续版本完成。[1]如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据1.14 相对于历届版本来说,囊 w397090770 3年前 (2021-09-02) 693℃ 0评论4喜欢
Apache Zeppelin 0.6.2发布。从上一个版本开始,Apache Zeppelin社区就在努力解决对Spark 2.0的支持以及一些Bug的修复。本次共有26位贡献者提供超过40多个补丁改进Apache Zeppelin和Bug修复。从Apache Zeppelin 0.6.1版本开始,编译的时候默认使用Scala 2.11。如果你想使用Scala 2.10来编译Apache Zeppelin,或者安装使用Scala 2.10编译的interpreter请参见官方文 w397090770 8年前 (2016-10-18) 2025℃ 0评论2喜欢
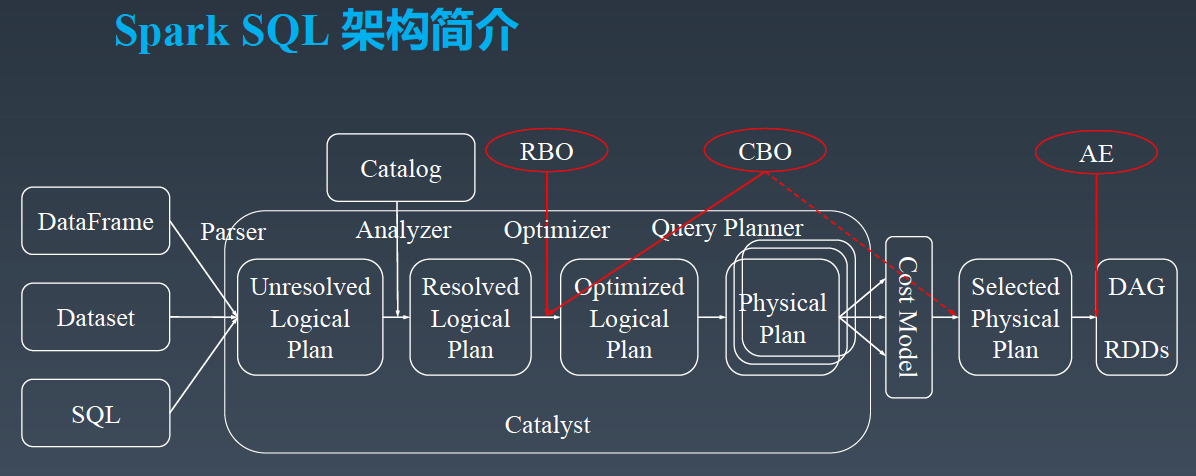
以下是字节跳动数据仓库架构负责人郭俊的分享主题沉淀,《字节跳动在Spark SQL上的核心优化实践》。PPT 请微信关注过往记忆大数据,并回复 bd_sparksql 获取。今天的分享分为三个部分,第一个部分是 SparkSQL 的架构简介,第二部分介绍字节跳动在 SparkSQL 引擎上的优化实践,第三部分是字节跳动在 Spark Shuffle 稳定性提升和性能 w397090770 5年前 (2019-12-03) 4298℃ 0评论3喜欢
Presto 是一个用于分析的开源分布式 ANSI SQL 查询引擎,支持计算和存储的分离。性能对于一些分析查询尤其重要,因此 Presto 有许多设计特性来最大化 Presto 的速度,比如内存中的流水线执行(memory pipelined execution)、分布式的扩展架构和大规模并行处理(MPP)设计。Presto支持的具体性能特性:数据压缩(SNAPPY, LZ4, ZSTD 以及 GZIP) w397090770 3年前 (2022-03-02) 1545℃ 0评论3喜欢
分享的内容主要包括三个内容:1)Kyuubi是什么?介绍Kyuubi的核心功能以及Kyuubi在各个使用场景中的解决方案;2)Kyuubi在网易内部的定位、角色和实际使用场景;3)通过案例分享Kyuubi在实际过程中如何起到作用。Kyuubi是什么开源Kyuubi是网易秉持开源理念的作品。Kyuubi是网易第一款贡献给Apache并进入孵化的开源项目。Kyuubi主要 zz~~ 3年前 (2021-12-23) 2249℃ 0评论4喜欢
我们在《Kafka创建Topic时如何将分区放置到不同的Broker中》文章中已经学习到创建 Topic 的时候分区是如何分配到各个 Broker 中的。今天我们来介绍分区分配到 Broker 中之后,会再哪个目录下创建文件夹。我们知道,在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录 w397090770 7年前 (2017-08-09) 5068℃ 0评论15喜欢
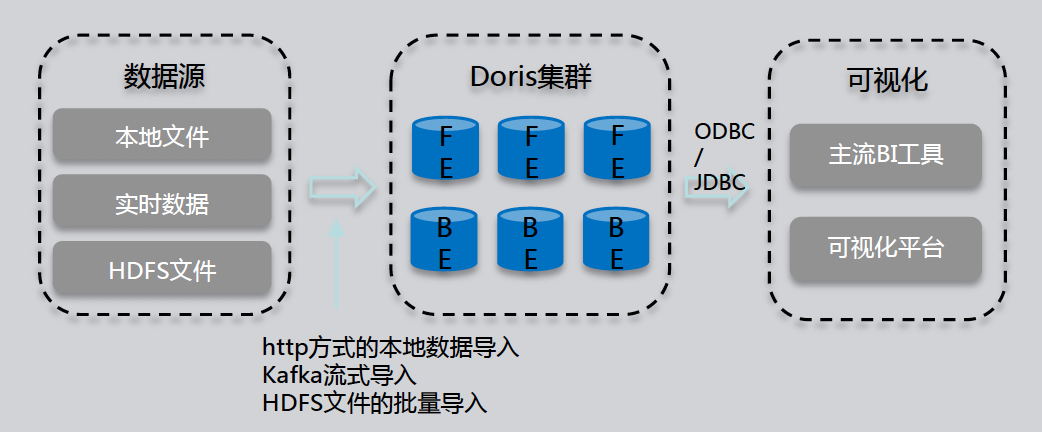
Apache Doris 简介Doris(原百度 Palo)是一款基于大规模并行处理技术的分布式 SQL 数据库,由百度在 2017 年开源,2018 年 8 月进入 Apache 孵化器。本次将主要从以下三部分介绍 Apache Doris.Doris 定位:即 Doris 所要面临的业务场景及解决的问题Doris 关键技术Doris 案例介绍01 Doris 定位实时数据仓库 Doris产品定位我们首先看一下 w397090770 5年前 (2019-12-11) 2942℃ 0评论4喜欢
这个文档只是简单的介绍如何快速地使用Spark。在下面的介绍中我将介绍如何通过Spark的交互式shell来使用API。Basics Spark shell提供一种简单的方式来学习它的API,同时也提供强大的方式来交互式地分析数据。Spark shell支持Scala和Python。可以通过以下方式进入到Spark shell中。[code lang="JAVA"]# 本文原文地址:https://www.iteblog.com/ar w397090770 10年前 (2014-06-10) 77085℃ 26评论156喜欢
写在前面的话,最近发现有很多网站转载我博客的文章,这个我都不介意的,但是这些网站转载我博客都将文章的出处去掉了,直接变成自己的文章了!!我强烈谴责他们,鄙视那些转载文章去掉出处的人!所以为了防止这些,我以后发表文章的时候,将会在文章里面加入一些回复之后才可见的内容!!请大家不要介意,本博 w397090770 11年前 (2014-05-13) 14113℃ 30评论3喜欢
在 Zookeeper 中限制 transaction log 总大小主要有两种方法。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop限制 Zookeeper Transaction Log 里面的事务条数默认情况下,在写入 snapCount(100000) 事务后,Zookeeper 事务日志将会切换。如果 Zookeeper 的数据目录的空间不足与存储三个版本的 Zookeeper Transaction Lo w397090770 4年前 (2020-10-28) 737℃ 0评论1喜欢
在很多场景中我们会使用Shell命令来发送邮件,而且我们还可能在邮件里面添加附件,本文将介绍使用Shell命令发送带附件邮件的几种方式,希望对大家有所帮助。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop使用mail命令mail命令是mailutils(On Debian)或mailx(On RedHat)包中的一部分,我们可以使 w397090770 8年前 (2017-02-23) 16263℃ 0评论12喜欢
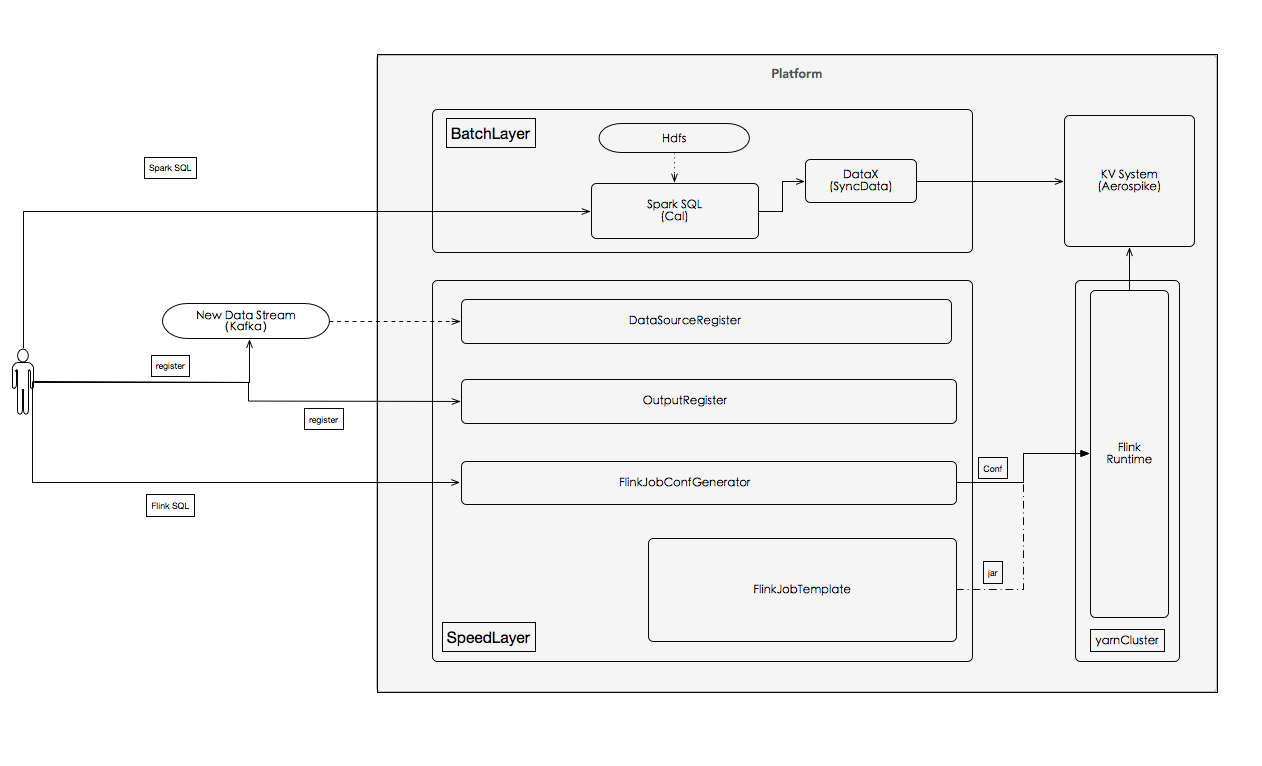
本文来自7月26日在上海举行的 Flink Meetup 会议,分享来自于刘康,目前在大数据平台部从事模型生命周期相关平台开发,现在主要负责基于flink开发实时模型特征计算平台。熟悉分布式计算,在模型部署及运维方面有丰富实战经验和深入的理解,对模型的算法及训练有一定的了解。本文主要内容如下:在公司实时特征开发的现 zz~~ 6年前 (2018-08-14) 7392℃ 0评论3喜欢
使用MEMORY_ONLY储存级别对RDD进行缓存,其内部实现是调用persist()函数的。官方文档定义:Persist this RDD with the default storage level (`MEMORY_ONLY`).函数原型[code lang="scala"]def cache() : this.type[/code]实例[code lang="scala"]/** * User: 过往记忆 * Date: 15-03-04 * Time: 下午06:30 * bolg: * 本文地址:/archives/1274 * 过往记忆博客, w397090770 10年前 (2015-03-04) 14185℃ 0评论8喜欢
导读:本文主要介绍Flink实时计算在bilibili的优化,将从以下四个方面展开: 1、Flink-connector稳定性优化 2、Flink sql优化 3、Flink-runtime优化 4、对未来的展望 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据 概述首先介绍下Flink实时计算在b站的应用场景。在b站,Flink on yarn w397090770 3年前 (2021-09-23) 851℃ 0评论4喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据Velox 利用了大量的运行时优化,例如过滤器和连接的重新排序(conjunct reordering)、数组和基于哈希的聚合和连接的 key 标准化、动态过滤器下推(dynamic filter pushdown)和自适应列预取(adaptive column prefetching)。考虑到从传入的数据批次中提取的 w397090770 2年前 (2022-09-05) 2147℃ 0评论3喜欢
在《Spark读取Hbase中的数据》文章中我介绍了如何在Spark中读取Hbase中的数据,并提供了Java和Scala两个版本的实现,本文将接着上文介绍如何通过Spark将计算好的数据存储到Hbase中。 Spark中内置提供了两个方法可以将数据写入到Hbase:(1)、saveAsHadoopDataset;(2)、saveAsNewAPIHadoopDataset,它们的官方介绍分别如下: saveAsHad w397090770 8年前 (2016-11-29) 17881℃ 1评论29喜欢
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器[code lang="JAVA"]$ sbin/mr-jobhistory-daemon.sh start historyserver w397090770 11年前 (2014-02-17) 29784℃ 8评论30喜欢
Flink可以在单台机器上运行,甚至是单个Java虚拟机(Java Virtual Machine)。这种机制使得用户可以在本地测试或者调试Flink程序。本节主要概述Flink本地模式的运行机制。 本地环境和执行器(executors)运行你在本地的Java虚拟机上运行Flink程序,或者是在属于正在运行程序的如何Java虚拟机上。对于大部分示例程序而言,你只需简单 w397090770 9年前 (2016-04-27) 16414℃ 0评论19喜欢
本书于2017-03由Packt Publishing出版,作者Muhammad Asif Abbasi,全书356页。通过本书你将学到以下知识:Get an overview of big data analytics and its importance for organizations and data professionalsDelve into Spark to see how it is different from existing processing platformsUnderstand the intricacies of various file formats, and how to process them with Apache Spark.Realize how to deploy Spark with YAR zz~~ 7年前 (2017-07-26) 14733℃ 0评论29喜欢



![Spark Summit 2016 San Francisco PPT免费下载[共95个]](https://www.iteblog.com/pic/iteblog.png)















![[电子书]Learning Apache Spark 2 PDF下载](https://www.iteblog.com/pic/books/Learning-Apache-Spark-2_iteblog.png)