默认情况下,使用WordPress系统的博客登录页面都比较简单,登陆页面显示的logo是WordPress 的logo,链接也是WordPress的链接,如下图所示:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 值得高兴的是,WordPress博客系统为我们提供了很多钩子(hook)来自定义这些信息,比如Logo、链接、提 w397090770 8年前 (2016-09-03) 1906℃ 0评论6喜欢
Pandas 用户定义函数(UDF)是 Apache Spark 中用于数据科学的最重要的增强之一,它们带来了许多好处,比如使用户能够使用 Pandas API和提高性能。 但是,随着时间的推移,Pandas UDFs 已经有了一些新的发展,这导致了一些不一致性,并在用户之间造成了混乱。即将推出的 Apache Spark 3.0 完整版将为 Pandas UDF 引入一个新接口,该接口利用 w397090770 4年前 (2020-05-30) 926℃ 0评论1喜欢
如果你要寻求一种处理海量数据的解决方案,就会有很多可选项。选择哪一种取决于具体的用例和要对数据进行何种操作,可以从很多种数据处理框架中进行遴选。例如Apache的Samza、Storm和Spark等等。本文将重点介绍Spark的功能,Spark不但非常适合用来对数据进行批处理,也非常适合对时实的流数据进行处理。 Spark目前已经 w397090770 8年前 (2017-02-06) 1675℃ 0评论4喜欢
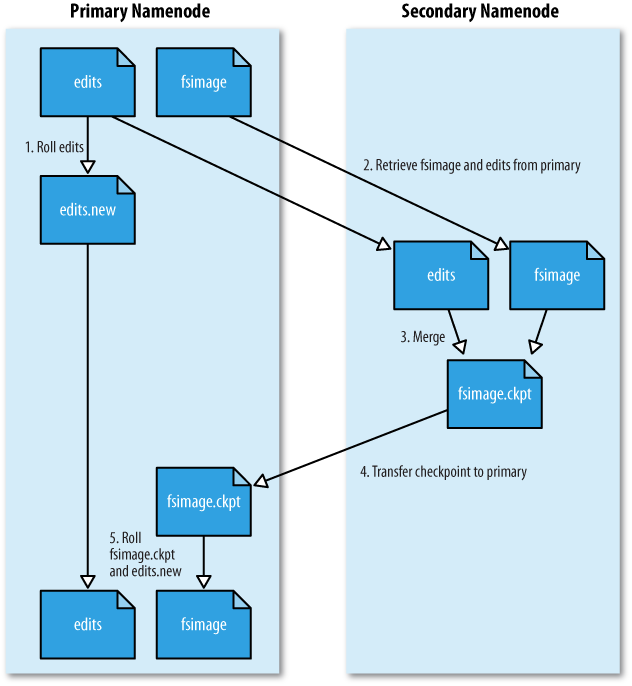
在《Hadoop文件系统元数据fsimage和编辑日志edits》文章中谈到了fsimage和edits的概念、作用等相关知识,正如前面说到,在NameNode运行期间,HDFS的所有更新操作都是直接写到edits中,久而久之edits文件将会变得很大;虽然这对NameNode运行时候是没有什么影响的,但是我们知道当NameNode重启的时候,NameNode先将fsimage里面的所有内容映像到 w397090770 11年前 (2014-03-10) 9758℃ 2评论18喜欢
2017年04月25日发布的nginx 1.13.0支持了TLSv1.3,而TLSv1.3相比之前的TLSv1.2、TLSv1.1等性能大幅提升。所以我迫不及待地将nginx升级到最新版1.13.0。下面记录如何升级nginx,本文基于CentOS release 6.6,其他的操作系统略有不同。如果你不知道你的系统是啥版本,可以通过下面的几个命令查询[code lang="bash"][root@iteblog.com ~]$ cat /etc/issueCentOS w397090770 7年前 (2017-05-23) 12338℃ 2评论10喜欢
本博客的《Spark与Mysql(JdbcRDD)整合开发》和《Spark RDD写入RMDB(Mysql)方法二》文章中介绍了如何通过Spark读写Mysql中的数据。 在生产环境下,很多公司都会使用PostgreSQL数据库,这篇文章将介绍如何通过Spark获取PostgreSQL中的数据。我将使用Spark 1.3中的DataFrame(也就是之前的SchemaRDD),我们可以通过SQLContext加载数据库中的数据, w397090770 9年前 (2015-05-23) 13001℃ 0评论11喜欢
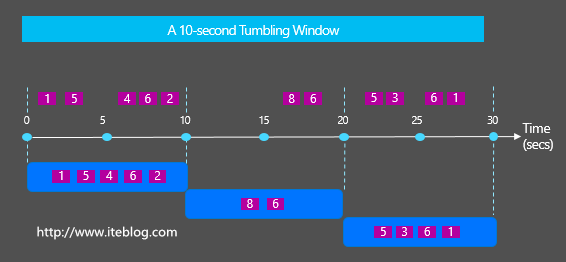
在流系统中通常会经常使用到Windows来统计一定范围的数据,比如按照固定时间、按个数等统计。一般会存在两种类型的Windows:Tumbling Windows vs Sliding Windows,它们很容易被初学者混淆,那么Tumbling Windows vs Sliding Windows之间到底有啥区别与联系呢?这就是本文将要展开的。 Tumbling的中文意思是摔跤,翻跟头,翻筋斗;Sliding中 w397090770 8年前 (2016-07-26) 3416℃ 0评论4喜欢
在互联网网络中,当网络发生拥塞(congestion)时,交换机将开始丢弃数据包。这可能导致数据重发(retransmissions)、数据包查询(query packets),这些操作将进一步导致网络的拥塞。为了防止网络拥塞(network congestion),需限制流出网络的流量,使流量以比较均匀的速度向外发送。主要有两种限流算法:漏桶算法(Leaky Bucket)和 w397090770 6年前 (2018-06-04) 3334℃ 0评论4喜欢
《Spark RDD缓存代码分析》 《Spark Task序列化代码分析》 《Spark分区器HashPartitioner和RangePartitioner代码详解》 《Spark Checkpoint读操作代码分析》 《Spark Checkpoint写操作代码分析》 上次介绍了RDD的Checkpint写过程(《Spark Checkpoint写操作代码分析》),本文将介绍RDD如何读取已经Checkpint的数据。在RDD Checkpint w397090770 9年前 (2015-12-23) 6392℃ 0评论10喜欢
大家在查看分析网站访问日志的时候,很可能发现自己网站里面的很多图片被外部网站引用,这样给我们自己的博客带来了最少两点的不好: (1)、如果别的网站引用我们网站图片的次数非常多的话,会给咱们网站服务器带来很大的负载压力; (2)、被其他网站引用图片会消耗我们网站的流量,如果我们的网站服 w397090770 10年前 (2014-12-27) 5456℃ 0评论3喜欢
Akka学习笔记系列文章: 《Akka学习笔记:ACTORS介绍》 《Akka学习笔记:Actor消息传递(1)》 《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》 《Akka学习笔记:测试Actors》 《Akka学习笔记:Actor消息处理-请求和响应(1) 》 《Akka学习笔记:Actor消息处理-请求和响应(2) 》 《Akka学 w397090770 10年前 (2014-12-12) 10132℃ 1评论5喜欢
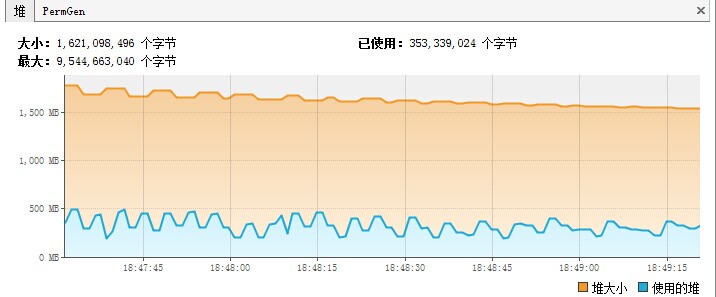
jvisualvm工具JDK自带的一个监控工具,该工具是用来监控java运行程序的cpu、内存、线程等的使用情况,并且使用图表的方式监控java程序、还具有远程监控能力,不失为一个用来监控Java程序的好工具。 同样,我们可以使用jvisualvm来监控Spark应用程序(Application),从而可以看到Spark应用程序堆,线程的使用情况,从而根据这 w397090770 9年前 (2015-05-13) 10690℃ 0评论9喜欢
Apache CarbonData 是一种新的融合存储解决方案,利用先进的列式存储,索引,压缩和编码技术提高计算效率,从而加快查询速度,其查询速度比 PetaBytes 数据快一个数量级。 鉴于目前使用 Apache CarbonData 用户越来越多,其中就包含了大量的中国用户,这些中国用户可能有很多人英文不是特别好,或者没那么多时间去看英文文档。基于 w397090770 6年前 (2018-05-09) 10788℃ 0评论22喜欢
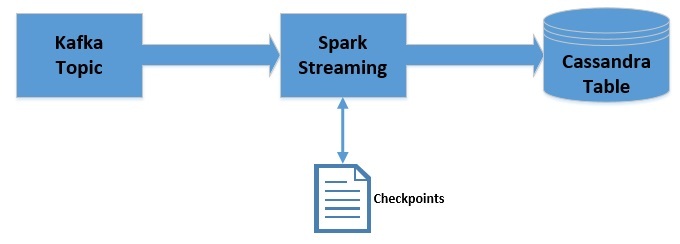
Apache Kafka 是一个可扩展,高性能,低延迟的平台,允许我们像消息系统一样读取和写入数据。我们可以很容易地在 Java 中使用 Kafka。Spark Streaming 是 Apache Spark 的一部分,是一个可扩展、高吞吐、容错的实时流处理引擎。虽然是使用 Scala 开发的,但是支持 Java API。Apache Cassandra 是分布式的 NoSQL 数据库。在这篇文章中,我们将 w397090770 5年前 (2019-09-08) 4041℃ 0评论8喜欢
有时候我们在发送HTTP请求的时候会使用到POST方式,如果是传送普通的表单数据那将很方便,直接将参数到一个Key-value形式的Map中即可。但是如果我们需要传送的参数是Json格式的,会稍微有点麻烦,我们可以使用HttpClient类库提供的功能来实现这个需求。假设我们需要发送的数据是:[code lang="java"]{ "blog": "", w397090770 9年前 (2015-06-01) 84725℃ 0评论72喜欢
本文所列的 Hive 函数均为 Hive 内置的,共计294个,Hive 版本为 3.1.0。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop!! a - Logical not,和not逻辑操作符含义一致[code lang="sql"]hive> select !(true);OKfalse[/code]!=a != b - Returns TRUE if a is not equal to b,和操作符含义一致[code lang="sql"]hive> se w397090770 6年前 (2018-07-22) 9635℃ 0评论10喜欢
2020年12月01日,IntelliJ IDEA 2020.3 正式发布,这是2020年的第三个里程碑版本。2020年其他两个版本可以参见IntelliJ IDEA 2020.2 稳定版发布 和 IntelliJ IDEA 2020.1 稳定版发布。本文主要介绍 IntelliJ IDEA 2020.3 的新功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop用户体验重新设置欢迎界面这个 w397090770 4年前 (2020-12-10) 1035℃ 0评论0喜欢
gossip 是什么gossip 协议(gossip protocol)又称 epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议,在分布式系统中被广泛使用,比如我们可以使用 gossip 协议来确保网络中所有节点的数据一样。gossip protocol 最初是由施乐公司帕洛阿尔托研究中心(Palo Alto Research Center)的研究员艾伦·德默斯(Al w397090770 6年前 (2019-01-24) 19689℃ 1评论15喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章介绍了Spark的三大新特性,本文是Reynold Xin在2016年5月5日的演讲,视频可以到这里看:http://go.databricks.com/apache-spark-2.0-presented-by-databricks-co-founder-reynold-xinPPT下载地址见下面。 w397090770 8年前 (2016-05-24) 3267℃ 0评论4喜欢
Spark 1.1.0中兼容大部分Hive特性,我们可以在Spark中使用Hive。但是默认的Spark发行版本并没有将Hive相关的依赖打包进spark-assembly-1.1.0-hadoop2.2.0.jar文件中,官方对此的说明是:Spark SQL also supports reading and writing data stored in Apache Hive. However, since Hive has a large number of dependencies, it is not included in the default Spark assembly 所以,如果你直 w397090770 10年前 (2014-09-26) 12834℃ 5评论9喜欢
This topic describes tips for tuning parallelism and memory in Presto. The tips are categorized as follows:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopTuning Parallelism at a Task LevelThe number of splits in a cluster = node-scheduler.max-splits-per-node * number of worker nodes.The node-scheduler.max-splits-per-node denotes the target value for the total num w397090770 4年前 (2021-02-20) 1152℃ 0评论4喜欢
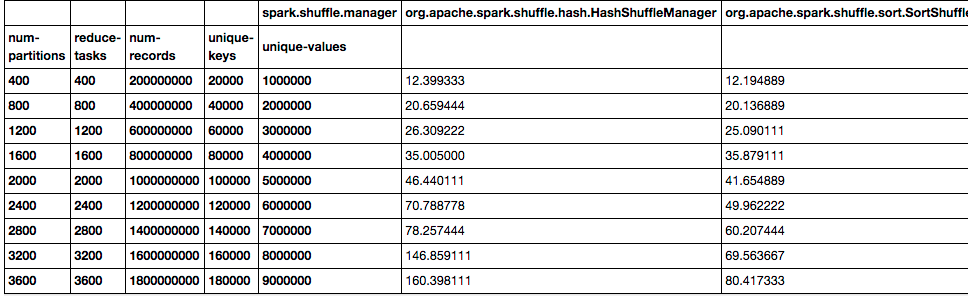
我们都知道Hadoop中的shuffle(不知道原理?可以参见《MapReduce:详细介绍Shuffle的执行过程》),Hadoop中的shuffle是连接map和reduce之间的桥梁,它是基于排序的。同样,在Spark中也是存在shuffle,Spark 1.1之前,Spark的shuffle只存在一种方式实现方式,也就是基于hash的。而在最新的Spark 1.1.0版本中引进了新的shuffle实现(《Spark 1.1.0正式发 w397090770 10年前 (2014-09-23) 15643℃ 3评论15喜欢
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。详情参见《CarbonData:华为开发并支持Hadoop的列式文件格式》,本文是单机模式下使用CarbonData的,如果你需要集群模 w397090770 8年前 (2016-07-01) 8378℃ 3评论6喜欢
为了提高本博客的用户体验,我于去年七月写了一份代码,将博客与微信公共帐号关联起来(可以参见本博客),用户可以在里面输入相关的关键字(比如new、rand、hot),但是那时候关键字有限制,只能对文章的分类进行搜索。不过,今天我修改了自动回复功能相关代码,目前支持对任意的关键字进行全文搜索,其结果相关与调用 w397090770 9年前 (2015-11-07) 2109℃ 0评论8喜欢
Resources提供提供操作classpath路径下所有资源的方法。除非另有说明,否则类中所有方法的参数都不能为null。虽然有些方法的参数是URL类型的,但是这些方法实现通常不是以HTTP完成的;同时这些资源也非classpath路径下的。 下面两个函数都是根据资源的名称得到其绝对路径,从函数里面可以看出,Resources类中的getResource函数 w397090770 11年前 (2013-09-25) 6491℃ 0评论4喜欢
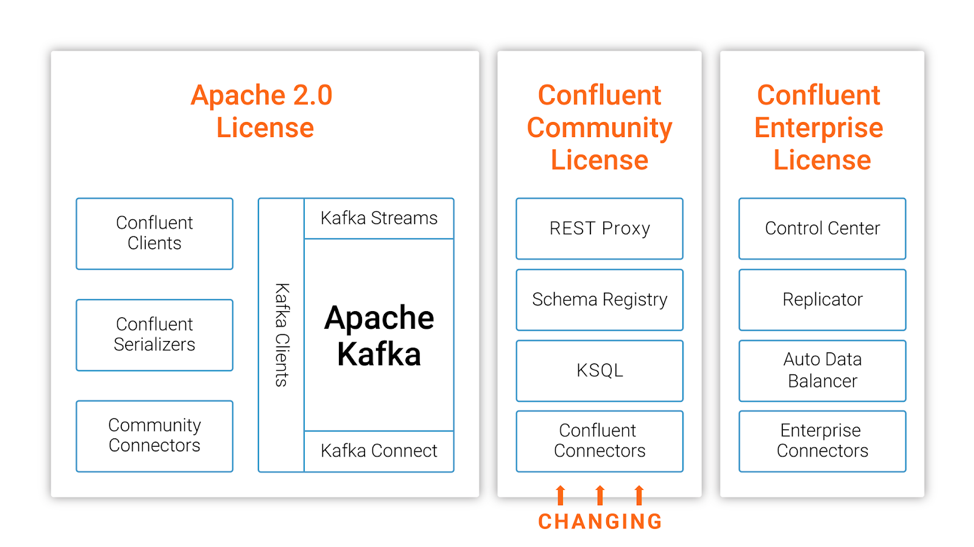
在今年的十月份,MongoDB 宣布其开源许可证从 GNU AGPLv3 切换到 Server Side Public License (SSPL),十一月份,图数据库 Neo4j 也宣布企业版彻底闭源。今天,Confluent 公司的联合创始人兼 CEO Jay Kreps 在 Confluent 官方博客宣布 Confluent 平台部分开源组件从 Apache 2.0 切换到 Confluent Community License,参见这里,下面是这篇文章的全部翻译。我们正在将 w397090770 6年前 (2018-12-15) 1998℃ 0评论3喜欢
2020年12月27日,Martin Traverso、 Dain Sundstrom 以及 David Phillips 大佬们宣布将 PrestoSQL 项目的名字更名为 Trino。新的项目地址为 https://trino.io/。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop正如上图的描述,这个仅仅是更改名字,之前的社区和软件都还在那的,这个项目还是由 Presto 的创始人和创 w397090770 4年前 (2020-12-28) 1999℃ 0评论1喜欢
一. 问答题1. 用mapreduce实现sql语句select count(x) from a group by b?2. 简述MapReduce大致流程,map -> shuffle -> reduce3. HDFS如何定位replica4. Hadoop参数调优: cluster level: JVM, map/reduce slots, job level: reducer, memory, use combiner? use compression?5. hadoop运行的原理?6. mapreduce的原理?7. HDFS存储的机制?8. 如何确认Hadoop集群的健康状况? w397090770 8年前 (2016-08-26) 3396℃ 0评论3喜欢
本书作者:Bill Chambers、Matei Zaharia、Shrey Mehrotra,由O'Reilly Media出版社于2017年1月出版,全书共450页。这里提供的是本书的 Early Release 版本,正式版尚未出版,而且目前还没有完整的内容。由于这本书有Matei Zaharia参与编写,所有很值得一看。通过本书将学习到以下的知识:Get a gentle overview of big data and SparkLearn about DataFrames, SQL, a zz~~ 7年前 (2017-06-22) 6789℃ 0评论26喜欢
将于2016年6月5日星期天下午1:30在杭州市西湖区教工路88号立元大厦3楼沃创空间沃创咖啡进行,本次场地由挖财公司提供。分享主题1. 陈超, 七牛:《Spark 2.0介绍》(13:30 ~ 14:10)2. 雷宗雄, 花名念钧:《spark mllib大数据实践和优化》(14:10 ~ 14:50)3. 陈亮,华为:《Spark+CarbonData(New File Format For Faster Data Analysis)》(15:10 ~ 15:50)4 w397090770 8年前 (2016-06-06) 2290℃ 0评论2喜欢












![[电子书]Spark: The Definitive Guide Early Release PDF下载](https://www.iteblog.com/pic/books/Spark_The_Definitive_Guide_iteblog.jpg)