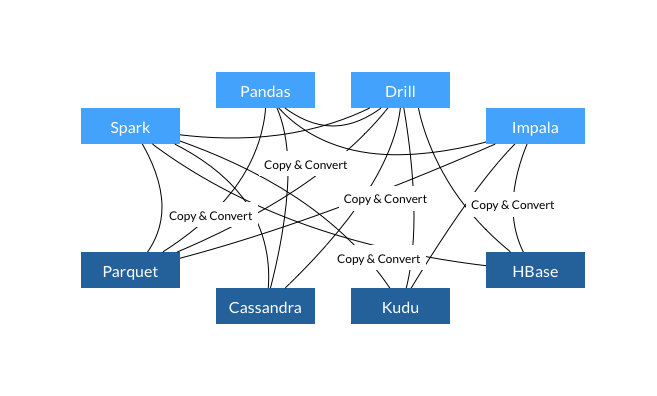
在 Apache Iceberg 中有很多种方式可以来创建表,其中就包括使用 Catalog 方式或者实现 org.apache.iceberg.Tables 接口。下面我们来简单介绍如何使用。.如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop使用 Hive catalog从名字就可以看出,Hive catalog 是通过连接 Hive 的 MetaStore,把 Iceberg 的表存储到其中,它 w397090770 4年前 (2020-11-08) 2301℃ 0评论5喜欢
昨天晚上,Apache Beam发布了第一个稳定版2.0.0,Apache Beam 社区声明:未来版本的发布将保持 API 的稳定性,并让 Beam 适用于企业的部署。Apache Beam 的第一个稳定版本是此社区第三个重要里程碑。Apache Beam 是在2016年2月加入 Apache 孵化器(Apache Incubator),并在同年的12月成功毕业成为 Apache 基金会的顶级项目(《Apache Beam成为Apache顶级项目 w397090770 7年前 (2017-05-18) 1730℃ 0评论3喜欢
在互联网网络中,当网络发生拥塞(congestion)时,交换机将开始丢弃数据包。这可能导致数据重发(retransmissions)、数据包查询(query packets),这些操作将进一步导致网络的拥塞。为了防止网络拥塞(network congestion),需限制流出网络的流量,使流量以比较均匀的速度向外发送。主要有两种限流算法:漏桶算法(Leaky Bucket)和 w397090770 6年前 (2018-06-04) 3334℃ 0评论4喜欢
4月16日在http://mirror.bit.edu.cn/apache/hive/hive-0.13.0/网址就可以下载Hive 0.13,这个版本在Hive执行速度、扩展性、SQL以及其他方面做了相当多的修改:一、执行速度 用户可以选择基于Tez的查询,基于Tez的查询可以大大提高Hive的查询速度(官网上上可以提升100倍)。下面一些技术对查询速度的提升: (1)、Broadcast Joins:和M w397090770 11年前 (2014-04-25) 8307℃ 1评论1喜欢
Apache Maven,是一个软件(特别是Java软件)项目管理及自动构建工具,由Apache软件基金会所提供。基于项目对象模型(缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。曾是Jakarta项目的子项目,现为独立Apache项目。 那么,如何在Linux平台下面安装Maven呢?下面以CentOS平台为例,说明如 w397090770 11年前 (2013-10-21) 32225℃ 3评论13喜欢
今天由于某些原因需要卸载掉服务器上的php软件,然后我使用下面命令显示出本机安装的所有和php相关的软件,如下:[code lang="bash"]iteblog$ rpm -qa | grep phpphp-mysqlnd-5.6.25-0.1.RC1.el6.remi.x86_64php-fpm-5.6.25-0.1.RC1.el6.remi.x86_64php-pecl-jsonc-1.3.10-1.el6.remi.5.6.x86_64php-pecl-memcache-3.0.8-3.el6.remi.5.6.x86_64php-pdo-5.6.25-0.1.RC1.el6.remi.x86_64php-mbstrin w397090770 8年前 (2016-08-08) 2286℃ 0评论2喜欢
一、背景介绍1. 需要解决的业务痛点推荐系统对于推荐同学来说,想知道一个推荐策略在不同人群中的推荐效果是怎么样的。运营对于运营的同学来说,想知道在广东省的用户中,最火的广东地域内容是哪些?方便做地域 push。审核对于审核的同学,想知道过去 5 分钟游戏类被举报最多的内容和账号是哪些, zz~~ 3年前 (2021-10-08) 466℃ 0评论0喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事在本博客的《Hive几种数据导入方式》文章 w397090770 11年前 (2014-02-23) 76258℃ 5评论49喜欢
Apache Arrow项目为列式内存存储的处理和交互提供了规范。目前来自Apache Hadoop社区的开发者们致力于将它制定为大数据系统项目的事实性标准。 Apache Arrow主要有以下几点的优势: 1、列式的内存布局可以使得随机访问的速度达到O(1)。这种内存布局在处理分析流和允许SIMD(Single input multiple data) 优化的现代处理器上非常 w397090770 9年前 (2016-02-22) 6226℃ 0评论6喜欢
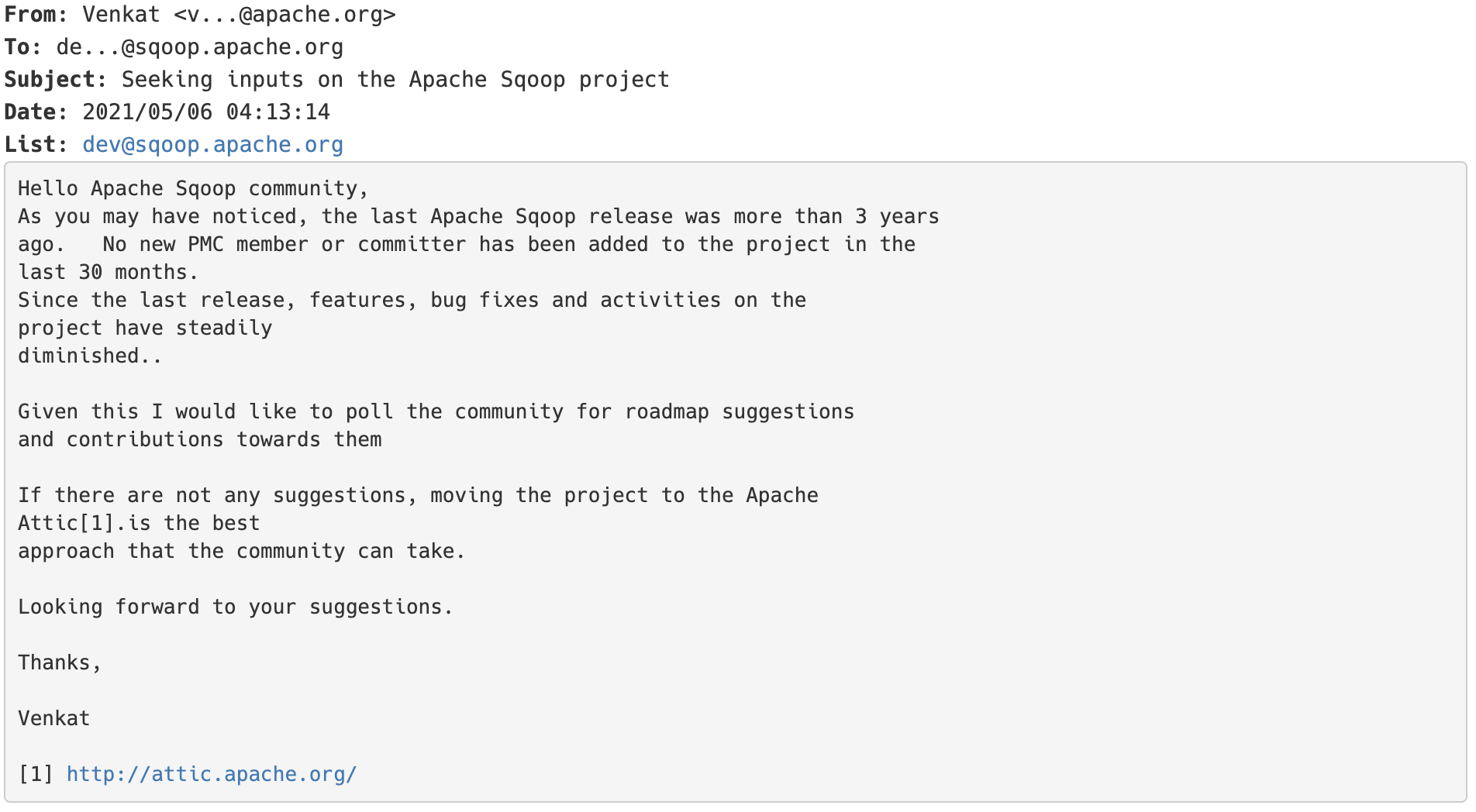
2021年05月06日,Apache Sqoop 的 PMC venkatrangan 给 Sqoop 项目的 dev 邮件列表发送了一篇名为《Seeking inputs on the Apache Sqoop project》的邮件:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据从邮件内容可以看出,Apache Sqoop 最后一次 release 的时间是三年前,最近30个月没有任何新的 PMC 和 committer 加入到 w397090770 3年前 (2021-06-27) 746℃ 0评论2喜欢
分享的内容主要包括三个内容:1)Kyuubi是什么?介绍Kyuubi的核心功能以及Kyuubi在各个使用场景中的解决方案;2)Kyuubi在网易内部的定位、角色和实际使用场景;3)通过案例分享Kyuubi在实际过程中如何起到作用。Kyuubi是什么开源Kyuubi是网易秉持开源理念的作品。Kyuubi是网易第一款贡献给Apache并进入孵化的开源项目。Kyuubi主要 zz~~ 3年前 (2021-12-23) 2249℃ 0评论4喜欢
今天凌晨(2016-10-05)Apache Spark 2.0.1稳定版正式发布。Apache Spark 2.0.1是一个维护版本,一共处理了300个Issues,推荐所有使用Spark 2.0.0的用户升级到此版本。Apache Spark 2.0为我们带来了许多新的功能: DataFrame和Dataset统一(可以参见《Spark 2.0技术预览:更容易、更快速、更智能》):https://www.iteblog.com/archives/1668.html SparkSession:一个 w397090770 8年前 (2016-10-05) 3169℃ 0评论7喜欢
我们知道,电脑里面的10000的数阶乘结果肯定是不能用int类型存储的,也就是说,平常的方法是不能来求得这个结果的。下面,我介绍一些用向量来模拟这个算法,其中向量里面的每一位都是代表一个数。[code lang="CPP"]#include <iostream>#include <vector>using namespace std;//就是n的阶乘void calculate(int n){ vector<int> v w397090770 12年前 (2013-03-31) 3879℃ 0评论5喜欢
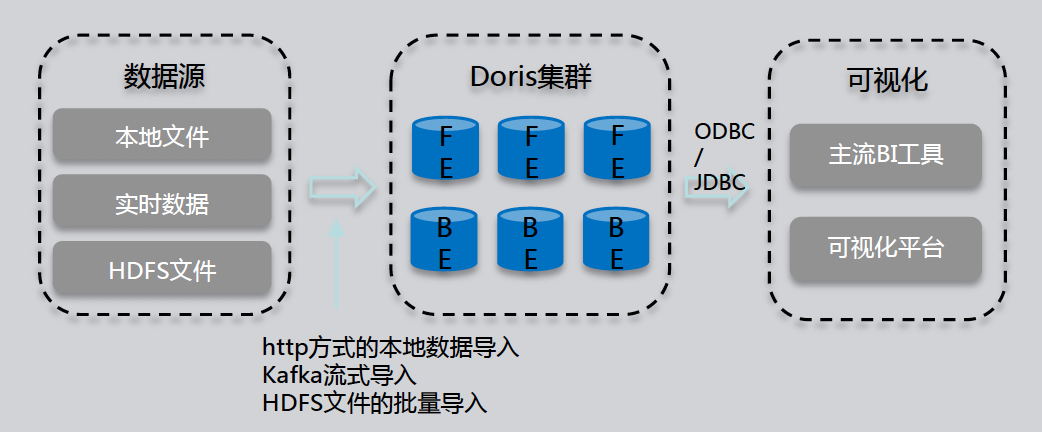
Apache Doris 简介Doris(原百度 Palo)是一款基于大规模并行处理技术的分布式 SQL 数据库,由百度在 2017 年开源,2018 年 8 月进入 Apache 孵化器。本次将主要从以下三部分介绍 Apache Doris.Doris 定位:即 Doris 所要面临的业务场景及解决的问题Doris 关键技术Doris 案例介绍01 Doris 定位实时数据仓库 Doris产品定位我们首先看一下 w397090770 5年前 (2019-12-11) 2942℃ 0评论4喜欢
和Hadoop类似,在Spark中也存在很多的Metrics配置相关的参数,它是基于Coda Hale Metrics Library的可配置Metrics系统,我们可以通过配置文件进行配置,通过Spark的Metrics系统,我们可以把Spark Metrics的信息报告到各种各样的Sink,比如HTTP、JMX以及CSV文件。Spark的Metrics系统目前支持以下的实例:master:Spark standalone模式的master进程;worker:S w397090770 10年前 (2015-05-05) 14324℃ 0评论15喜欢
本书于2014年12月出版,共374页,这里提供的本身完整版。 w397090770 9年前 (2015-08-21) 2628℃ 0评论3喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 第三次北京Spark Meetup活动将于2014年10月26日星期日的下午1:30到6:00在海淀区中关村科学院南路2号融科资讯中心A座8层举行,本次分享的主题主要是MLlib与分布式机器学 w397090770 10年前 (2014-10-09) 4463℃ 6评论6喜欢
经过近一个月时间,终于差不多将之前在Flume 0.9.4上面编写的source、sink等插件迁移到Flume-ng 1.5.0,包括了将Flume 0.9.4上面的TailSource、TailDirSource等插件的迁移(当然,我们加入了许多新的功能,比如故障恢复、日志的断点续传、按块发送日志以及每个一定的时间轮询发送日志而不是等一个日志发送完才发送另外一个日志)。现在 w397090770 10年前 (2014-06-18) 17494℃ 13评论15喜欢
一、线段树基本概念线段树是一种二叉搜索树,与区间树相似,它将一个区间划分成一些单元区间,每个单元区间对应线段树中的一个叶结点。对于线段树中的每一个非叶子节点[a,b],它的左儿子表示的区间为[a,(a+b)/2],右儿子表示的区间为[(a+b)/2+1,b]。因此线段树是平衡二叉树,最后的子节点数目为N,即整个线段区间的长度。 w397090770 12年前 (2013-04-03) 4953℃ 0评论4喜欢
由于需要在Flume里面加入一些我需要的代码,这时候就需要重新编译Flume代码,因为在编译Flume源码的时候出现了很多问题,所以写出这篇博客,以此分享给那些也需要编译代码的人一些参考,这里以如何编译Flume-0.9.4源码为例进行说明。 首先下载Flume0.9.4源码(可以到https://repository.cloudera.com/content/repositories/releases/com/cloudera/fl w397090770 11年前 (2014-01-22) 12258℃ 1评论4喜欢
一、活动时间 5月10日下午14:00-18:00二、活动地点北京市海淀区丹棱街5号 微软亚太研发集团总部大厦1号楼1层 地图: http://j.map.baidu.com/yVWh0三、活动内容: 1、鲁小亿 美国俄亥俄州立大学计算机科学与工程系 Senior Research Associate,演讲主题:<spark & RDMA> 2、董旭 滴滴打车 高级软件工程师,高性能计算负责 w397090770 10年前 (2015-05-05) 3030℃ 0评论6喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/好久没写Hive的那些事了,今 w397090770 11年前 (2014-02-19) 92554℃ 5评论132喜欢
Apache Hive Essentials于2015年02月出版,全书共208页。 w397090770 9年前 (2015-08-25) 5194℃ 0评论8喜欢
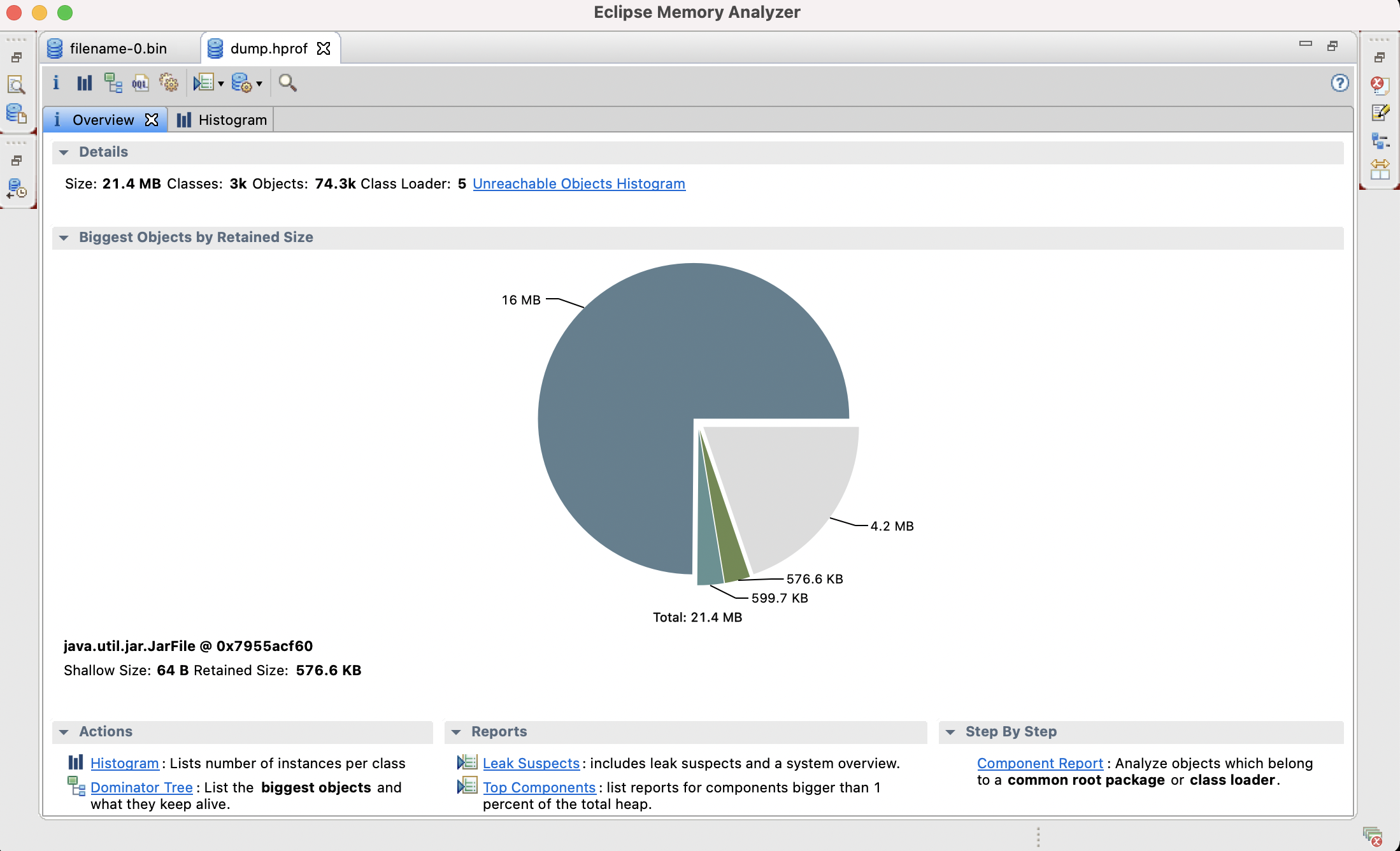
在安装完 JDK 之后,会自带安装一些常用的小工具,而 jmap 就是其中一个比较常用的。jmap 打印给定进程、core file 或远程调试服务器的共享对象内存映射或堆内存细节。我们可以查看下 jmap 的命令使用:[code lang="bash"]iteblog@iteblog.com:~|⇒ jmapUsage: jmap [option] <pid> (to connect to running process) jmap [option] <executable <co w397090770 3年前 (2021-08-02) 825℃ 0评论0喜欢
写在前面的话,最近发现有很多网站转载我博客的文章,这个我都不介意的,但是这些网站转载我博客都将文章的出处去掉了,直接变成自己的文章了!!我强烈谴责他们,鄙视那些转载文章去掉出处的人!所以为了防止这些,我以后发表文章的时候,将会在文章里面加入一些回复之后才可见的内容!!请大家不要介意,本博 w397090770 11年前 (2014-05-13) 14113℃ 30评论3喜欢
在大规模数据量的数据分析及建模任务中,往往针对全量数据进行挖掘分析时会十分耗时和占用集群资源,因此一般情况下只需要抽取一小部分数据进行分析及建模操作。本文就介绍 Hive 中三种数据抽样的方法块抽样(Block Sampling)Hive 本身提供了抽样函数,使用 TABLESAMPLE 抽取指定的 行数/比例/大小,举例:[code lang="sql"]CREA w397090770 8年前 (2017-02-10) 6183℃ 0评论7喜欢
关于 Apache Spark 2.2.0 的详细新功能介绍请参见:《Apache Spark 2.2.0新特性详细介绍》Apache Spark 2.2.0 持续了半年的开发,从RC1 到 RC6 终于在今天正式发布了。本版本是 2.x 版本线的第三个版本。在这个版本 Structured Streaming 的实验性标记(experimental tag)已经被移除,这也意味着后面的 2.2.x 之后就可以放心在线上使用了。除此之外,这 w397090770 7年前 (2017-07-12) 2814℃ 0评论8喜欢
第十二次Shanghai Apache Spark Meetup聚会,由Splunk中国大力支持。活动将于2017年03月18日12:30~16:45在上海淞沪路303号901 (大学路智星路路口汇丰银行楼9楼)Splunk 中国进行。 举办地点交通方便,靠近地铁10号线江湾体育场站,座位有限(大约120),先到先得,速速行动啊。大会主题《利用Spark开发高并发,高可靠的分布式大数据采集调 w397090770 8年前 (2017-03-09) 1441℃ 0评论2喜欢
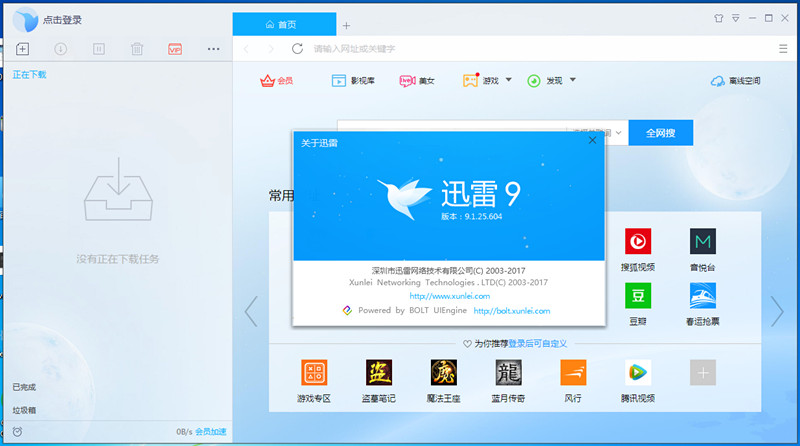
最近升级了迅雷9,新版本精简了任务列表的面积,然而增加了一个硕大的内置浏览器面板,大概占据了四分之三的窗口面积,并且不能关闭!界面如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop就个人观点而言,实在不能理解为什么需要让一个下载工具的附加功能占据主要使用区 w397090770 8年前 (2017-02-18) 6421℃ 0评论20喜欢
Spark的其中一个目标就是使得大数据应用程序的编写更简单。Spark的Scala和Python的API接口很简洁;但由于Java缺少函数表达式(function expressions), 使得Java API有些冗长。Java 8里面增加了lambda表达式,Spark开发者们更新了Spark的API来支持Java8的lambda表达式,而且与旧版本的Java保持兼容。这些支持将会在Spark 1.0可用。如果想及时了解 w397090770 10年前 (2014-07-10) 13193℃ 0评论18喜欢