在Hive0.8开始支持Insert into语句,它的作用是在一个表格里面追加数据。标准语法语法如下:[code lang="sql"]用法一:INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;用法二:INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;[/code w397090770 11年前 (2013-10-30) 102119℃ 2评论69喜欢
Web挖掘的目标是从Web的超链接结构、网页内容和使用日志中探寻有用的信息。虽然Web挖掘使用了许多数据挖掘技术,但它不仅仅是传统数据挖掘的一个简单的应用。在过去的20年中,许多新的挖掘任务和算法被相继提出。依据在挖掘过程中使用的数据类别,Web挖掘任务可以分为三种类型:Web结构挖掘、Web内容挖掘和Web使用挖掘。 w397090770 12年前 (2013-04-29) 4252℃ 0评论8喜欢
如果你要寻求一种处理海量数据的解决方案,就会有很多可选项。选择哪一种取决于具体的用例和要对数据进行何种操作,可以从很多种数据处理框架中进行遴选。例如Apache的Samza、Storm和Spark等等。本文将重点介绍Spark的功能,Spark不但非常适合用来对数据进行批处理,也非常适合对时实的流数据进行处理。 Spark目前已经 w397090770 8年前 (2017-02-06) 1675℃ 0评论4喜欢
今天早上 06:53(2019年11月08日 06:53) 数砖的 Xingbo Jiang 大佬给社区发了一封邮件,宣布 Apache Spark 3.0 预览版正式发布,这个版本主要是为了对即将发布的 Apache Spark 3.0 版本进行大规模社区测试。无论是从 API 还是从功能上来说,这个预览版都不是一个稳定的版本,它的主要目的是为了让社区提前尝试 Apache Spark 3.0 的新特性。如果大家想 w397090770 5年前 (2019-11-08) 2064℃ 0评论6喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事 在Hive中,我们应该都听过RCFile这种格 w397090770 11年前 (2014-04-16) 83924℃ 9评论76喜欢
我在《在Kafka中使用Avro编码消息:Producter篇》文章中简单介绍了如何发送 Avro 类型的消息到 Kafka。本文接着上文介绍如何从 Kafka 读取 Avro 格式的消息。关于 Avro 我这就不再介绍了。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop从 Kafka 中读取 Avro 格式的消息从 Kafka 中读取 Avro 格式的消 w397090770 7年前 (2017-09-25) 6363℃ 0评论16喜欢
Spark SQL主要目的是使得用户可以在Spark上使用SQL,其数据源既可以是RDD,也可以是外部的数据源(比如Parquet、Hive、Json等)。Spark SQL的其中一个分支就是Spark on Hive,也就是使用Hive中HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业。本文就是来介绍如何通过Spark SQL来 w397090770 9年前 (2015-08-27) 74636℃ 19评论38喜欢
在 《Apache Solr 安装部署及索引创建》 文章中,我们搭建好一个单机版的 Solr 服务,并创建好一个名为 iteblog 的 core,iteblog 的索引数据是存放在 instanceDir 参数的 data 目录下。这会有以下几个问题:如果索引数据很大,可能本地的文件夹无法存储索引数据存放在本地,可能会导致索引数据丢失等幸运的是,Solr 支持将索引和事 w397090770 6年前 (2018-07-25) 1799℃ 0评论4喜欢
越来越多的公司采用流处理,并将现有的批处理应用迁移到流处理,或者对新的用例采用流处理实现的解决方案。其中许多应用集中在流数据分析上,分析的数据流来自各种源,例如数据库事务、点击、传感器测量或 IoT 设备。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Flink 非常 w397090770 7年前 (2017-07-20) 3521℃ 0评论16喜欢
活动时间 1月24日下午14:00活动地点 地址:海淀区中关村软件园二期,西北旺东路10号院东区,亚信大厦 一层会议室 地图:http://j.map.baidu.com/L_1hq 为了保证大家乘车方便,特提供活动大巴时间:13:20-13:40位置:http://j.map.baidu.com/SJOLy分享内容: 邵赛赛 Intel Spark Streaming driver high availability w397090770 10年前 (2015-01-22) 15586℃ 0评论2喜欢
关注 iteblog_hadoop 公众号并在这篇文章里面文末评论区留言(认真写评论,增加上榜的机会)。留言点赞数排名前5名的粉丝,各免费赠送一本《深入浅出深度学习:原理剖析与Python实践》,活动截止至08月22日18:00。这篇文章评论区留言才有资格参加送书活动:http://mp.weixin.qq.com/s/R6mqHuaNK819aLrE4tit6A如果想及时了解Spark、Hadoop或者 w397090770 7年前 (2017-08-15) 1591℃ 0评论4喜欢
最近使用ElasticSearch的时候遇到以下的异常[code land="bash"]2017-07-27 16:06:48.482 MessageHandler - message process error: java.lang.NoClassDefFoundError: Could not initialize class org.elasticsearch.common.xcontent.smile.SmileXContent at org.elasticsearch.common.xcontent.XContentFactory.contentBuilder(XContentFactory.java:124) ~[elasticsearch-2.3.4.jar:2.3.4] at org.elasticsearch.action.support.ToX w397090770 7年前 (2017-07-27) 8601℃ 0评论13喜欢
这几天由于项目的需要,需要将Flume收集到的日志插入到Hbase中,有人说,这不很简单么?Flume里面自带了Hbase sink,可以直接调用啊,还用说么?是的,我在本博客的《Flume-1.4.0和Hbase-0.96.0整合》文章中就提到如何用Flume和Hbase整合,从文章中就看出整个过程不太复杂,直接做相应的配置就行了。那么为什么今天还要特意提一下Flum w397090770 11年前 (2014-01-27) 5145℃ 1评论1喜欢
Apache Spark Graph Processing图书由Rindra Ramamonjison所著,全书共148页;Packt Publishing出版社于2015年09月出版。 通过本书你将学习到以下内容 (1)、Write, build and deploy Spark applications with the Scala Build Tool. (2)、Build and analyze large-scale network datasets (3)、Analyze and transform graphs using RDD and graph-specific operations (4) w397090770 8年前 (2017-02-12) 1863℃ 0评论1喜欢
在编写程序的时候,很多时候都需要检查输入的参数是否符合我们的需要,比如人的年龄需要大于0,名字不能为空;如果不符合这两个要求,我们将认为这个对象是不合法的,这时候我们需要编写判断这些参数是否合法的函数,我们可能这样写:[code lang="JAVA"]package com.wyp;import java.util.ArrayList;import java.util.List;/** * Crea w397090770 11年前 (2013-07-24) 6084℃ 4评论2喜欢
Spark Summit 2016 Europe会议于2016年10月25日至10月27日在布鲁塞尔进行。本次会议有上百位Speaker,来自业界顶级的公司。官方日程:https://spark-summit.org/eu-2016/schedule/。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料 w397090770 8年前 (2016-11-06) 3065℃ 0评论1喜欢
消息队列 消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。在分布式计算环境中,为了集成分布式应用,开发者需要对异构网络环 w397090770 9年前 (2015-08-11) 8104℃ 2评论17喜欢
本书是《Spark快速数据处理》第三版,全书基于Spark 2.0.0编写。本书适合Spark入门者,作者Krishna Sankar,由Packt出版社于2016年10月出版,全书共274页。通过本书你将学到以下知识: (1)、安装和设置你的Spark集群; (2)、使用Spark交互式Shell来实现简单的分布式应用程序; (3)、使用新的DataFrame API操作数据; w397090770 8年前 (2016-12-14) 4376℃ 0评论5喜欢
我们都知道,当我们的页面请求一个js文件、一个cs文件或者点击到其他页面,浏览器一般都会给这些请求头加上表示来源的 Referrer 字段。Referrer 在分析用户的来源时非常有用,比如大家熟悉的百度统计里面就利用到 Referrer 信息了。但是遗憾的是,目前百度统计仅仅支持来源于http页面的referrer头信息;也就是说,如果你网站是ht w397090770 8年前 (2017-01-10) 24452℃ 0评论19喜欢
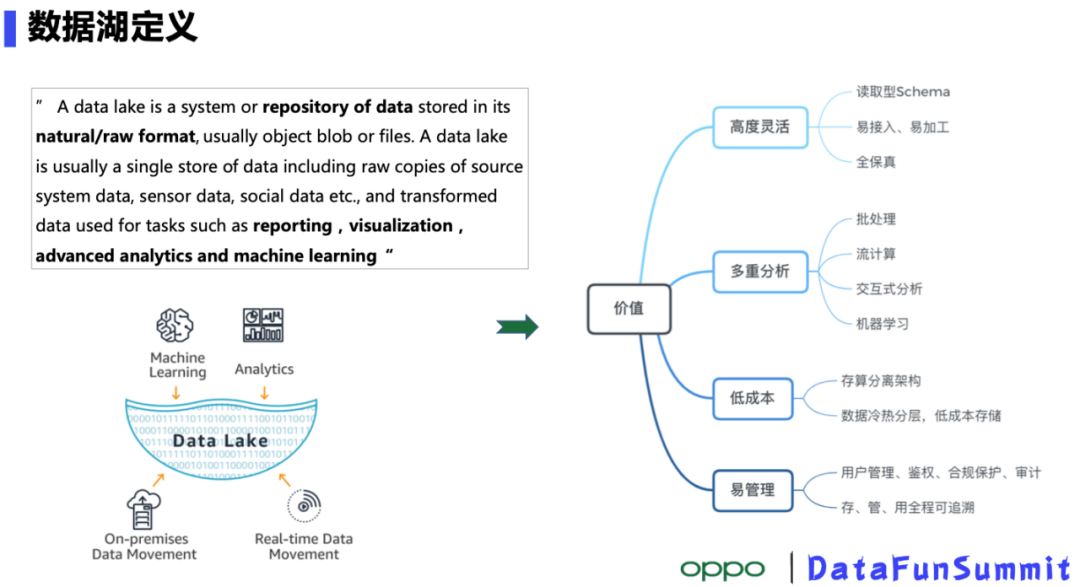
导读:OPPO是一家智能终端制造公司,有着数亿的终端用户,手机 、IoT设备产生的数据源源不断,设备的智能化服务需要我们对这些数据做更深层次的挖掘。海量的数据如何低成本存储、高效利用是大数据部门必须要解决的问题。目前业界流行的解决方案是数据湖,本次Xiaochun He老师介绍的OPPO自研数据湖存储系统CBFS在很大程度上可 zz~~ 3年前 (2021-09-24) 420℃ 0评论2喜欢
流处理系统月刊是一份专门收集关于Spark、Flink、Kafka、Apex等流处理系统的技术干货月刊,完全免费,每天更新,欢迎关注。下面资源如无法正常访问,请使用《最新可访问Google的Hosts文件》或《Tunnello:免费的浏览器翻墙插件》进行科学上网。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoo w397090770 8年前 (2016-10-07) 4348℃ 0评论5喜欢
在 HDFS 中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的 dfs.datanode.data.dir 参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。当 w397090770 7年前 (2018-03-28) 5312℃ 3评论24喜欢
Apache Spark 2.2.0 经过了大半年的紧张开发,从RC1到RC6终于在今天正式发布了。由于时间的缘故,我并没有在《Apache Spark 2.2.0正式发布》文章中过多地介绍 Apache Spark 2.2.0 的新特性,本文作为补充将详细介绍Apache Spark 2.2.0 的新特性。这个版本是 Structured Streaming 的一个重要里程碑,因为其终于可以正式在生产环境中使用,实验标签(ex w397090770 7年前 (2017-07-12) 9306℃ 0评论28喜欢
SPARK SUMMIT 2015会议于美国时间2015年06月15日到2015年06月17日在San Francisco(旧金山)进行,目前PPT已经全部公布了,不过很遗憾的是这个网站被墙了,无法直接访问,本博客将这些PPT全部整理免费下载。由于源网站限制,一天只能只能下载20个PPT,所以我只能一天分享20篇。如果想获取全部的PPT,请关站本博客。会议主旨 T w397090770 9年前 (2015-07-09) 3396℃ 1评论3喜欢
大家在查看分析网站访问日志的时候,很可能发现自己网站里面的很多图片被外部网站引用,这样给我们自己的博客带来了最少两点的不好: (1)、如果别的网站引用我们网站图片的次数非常多的话,会给咱们网站服务器带来很大的负载压力; (2)、被其他网站引用图片会消耗我们网站的流量,如果我们的网站服 w397090770 10年前 (2014-12-27) 5456℃ 0评论3喜欢
本文作者:汪愈舟 俞育才 郭晨钊 程浩(英特尔),李元健(百度)Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇到不少易用性和可扩展性的挑战。为了应对这些挑战,英特尔大数据技术团 w397090770 7年前 (2018-01-11) 90960℃ 0评论78喜欢
前言 OPPO的大数据离线计算发展,经历了哪些阶段?在生产中遇到哪些经典的大数据问题?我们是怎么解决的,从中有哪些架构上的升级演进?未来的OPPO离线平台有哪些方向规划?今天会给大家一一揭秘。OPPO大数据离线计算发展历史大数据行业发展阶段 一家公司的技术发展,离不开整个行业的发展背景。我们简短回归 w397090770 3年前 (2021-10-29) 735℃ 0评论2喜欢
面试题目:输入n个整数,输出其中最小的前k个数。 例如输入1,2,3,4,5,6,7和8这8个数字,则最小的3个数字为1,2,3。 分析:这道题最简单的思路莫过于把输入的n个整数排好序,然后输出前面k个数,这就是最小的前k个数。但是按照这种思路最好的时间复杂度为O(nlogn),是否还有比这个更快的算法呢? w397090770 12年前 (2013-05-21) 5637℃ 0评论2喜欢
本次的分享内容分成四个部分:系统概述:认识kudu,理解Kudu的系统设计与定位生产实践:分享网易内部的典型使用场景遇到的问题:实际使用过程中遇到的问题和问题的排障过程功能展望:对Kudu功能特性的展望Kudu定位与架构Kudu是一个存储引擎,可以接入Impala、Presto、Spark等Olap计算引擎进行数据分析,容易融入Hadoop社区 w397090770 3年前 (2021-07-17) 284℃ 0评论1喜欢
Uber 致力于在全球市场上提供更安全,更可靠的运输服务。为了实现这一目标,Uber 在很大程度上依赖于数据驱动的决策,从预测高流量事件期间骑手的需求到识别和解决我们的驾驶员-合作伙伴注册流程中的瓶颈。自2014年以来,Uber 一直致力于开发大数据解决方案,确保数据可靠性,可扩展性和易用性;现在 Uber 正专注于提高他们平 w397090770 5年前 (2019-06-06) 3258℃ 0评论8喜欢








![[电子书]Apache Spark Graph Processing PDF下载](https://www.iteblog.com/pic/books/Apache_Spark_Graph_Processing_iteblog.jpg)

![Spark Summit 2016 Europe全部PPT下载[共75个]](https://www.iteblog.com/pic/iteblog.png)

![[电子书]Fast Data Processing with Spark 2, 3rd Edition下载](https://www.iteblog.com/pic/books/Fast_Data_Processing_with_Spark_2_iteblog.jpg)