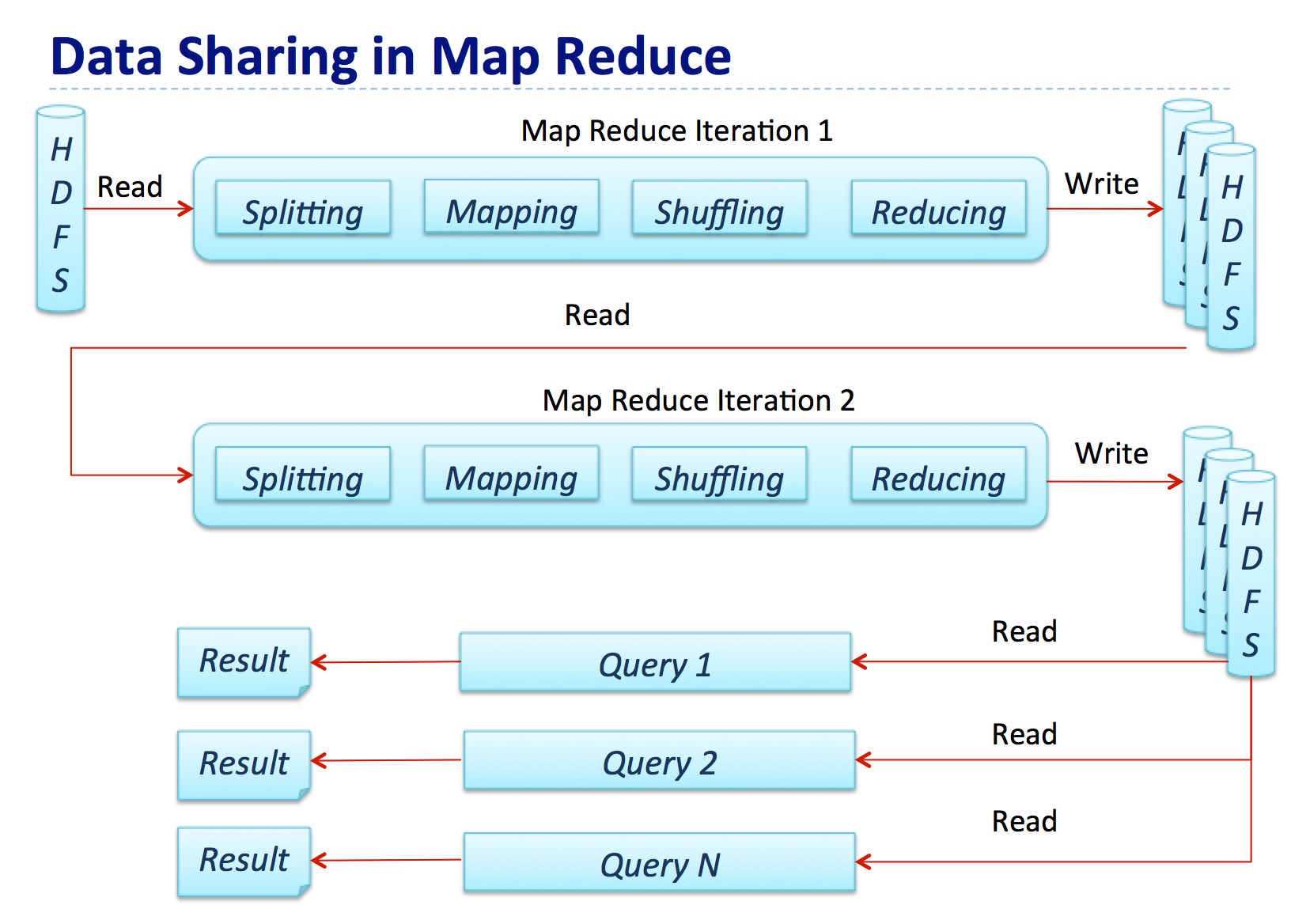
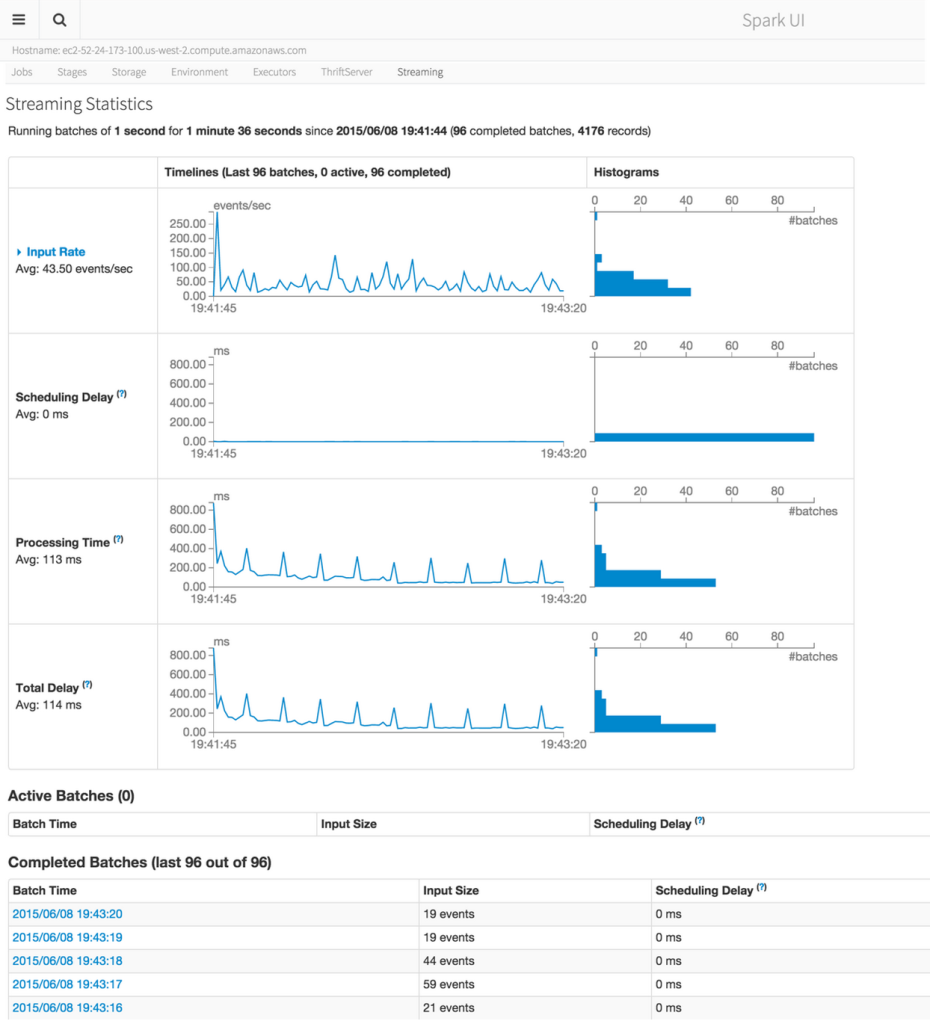
在 《Apache Solr 安装部署及索引创建》 文章中,我们搭建好一个单机版的 Solr 服务,并创建好一个名为 iteblog 的 core,iteblog 的索引数据是存放在 instanceDir 参数的 data 目录下。这会有以下几个问题:如果索引数据很大,可能本地的文件夹无法存储索引数据存放在本地,可能会导致索引数据丢失等幸运的是,Solr 支持将索引和事 w397090770 6年前 (2018-07-25) 1799℃ 0评论4喜欢
《Spark Streaming作业提交源码分析接收数据篇》、《Spark Streaming作业提交源码分析数据处理篇》 在昨天的文章中介绍了Spark Streaming作业提交的数据接收部分的源码(《Spark Streaming作业提交源码分析接收数据篇》),今天来介绍Spark Streaming中如何处理这些从外部接收到的数据。 在调用StreamingContext的start函数的时候, w397090770 10年前 (2015-04-29) 4398℃ 2评论9喜欢
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Materialized Column- An Efficient Way to Optimize Queries on Nested Columns》的分享,作者为字节跳动的郭俊。本文相关 PPT 可以关注 Java与大数据架构 公众号并回复 9910 获取。在数据仓库领域,使用复杂类型(如map)中的一列或多列,或者将许多子字段放入其中的场景是非常 w397090770 4年前 (2020-12-13) 854℃ 0评论3喜欢
2021年2月4日,负责维护 Docker 引擎的 Justin Cormack 在 Docker 官方博客宣布把 Docker 发行版(Docker Distribution)捐献给了 CNCF,全文如下:我们很高兴地宣布,Docker 已经把 Docker 发行版(Docker Distribution)捐献给了 CNCF。Docker 致力于开源社区和我们许多项目的开放标准,这一举动将确保 Docker 发行版有一个广泛的团队来维护许多注册中心 w397090770 4年前 (2021-02-06) 288℃ 0评论2喜欢
在 Apache 软件基金会近期发布的年度报告中,Apache Flink 再次跻身最活跃项目前 5 名!该项目最新发布的 1.14.0 版本同样体现了其非凡的活跃力,囊括了来自超过 200 名贡献者的 1000 余项贡献。整个社区为项目的推进付出了持之以恒的努力,我们引以为傲。新版本在 SQL API、更多连接器支持、Checkpoint 机制、PyFlink 等多个方面带来了大 zz~~ 3年前 (2021-10-09) 908℃ 0评论4喜欢
highlight.js是一款轻量级的Web代码语法高亮库,它主要有以下几个特点: (1)、支持118种语言(看这里https://github.com/isagalaev/highlight.js/tree/master/src/languages)和54中样式(看这里https://github.com/isagalaev/highlight.js/tree/master/src/styles); (2)、可以自动检测编程语言; (3)、同时为多种编程语言代码高亮; (4) w397090770 10年前 (2015-04-16) 14217℃ 0评论13喜欢
Uber 致力于在全球市场上提供更安全,更可靠的运输服务。为了实现这一目标,Uber 在很大程度上依赖于数据驱动的决策,从预测高流量事件期间骑手的需求到识别和解决我们的驾驶员-合作伙伴注册流程中的瓶颈。自2014年以来,Uber 一直致力于开发大数据解决方案,确保数据可靠性,可扩展性和易用性;现在 Uber 正专注于提高他们平 w397090770 5年前 (2019-06-06) 3258℃ 0评论8喜欢
本文来自7月26日在上海举行的 Flink Meetup 会议,分享来自于刘康,目前在大数据平台部从事模型生命周期相关平台开发,现在主要负责基于flink开发实时模型特征计算平台。熟悉分布式计算,在模型部署及运维方面有丰富实战经验和深入的理解,对模型的算法及训练有一定的了解。本文主要内容如下:在公司实时特征开发的现 zz~~ 6年前 (2018-08-14) 7392℃ 0评论3喜欢
由Databricks、UC Berkeley以及MIT联合为Apache Spark开发了一款图像处理类库,名为:GraphFrames,该类库是构建在DataFrame之上,它既能利用DataFrame良好的扩展性和强大的性能,同时也为Scala、Java和Python提供了统一的图处理API。什么是GraphFrames 与Apache Spark的GraphX类似,GraphFrames支持多种图处理功能,但得益于DataFrame因此GraphFrames与G w397090770 9年前 (2016-04-09) 4768℃ 0评论6喜欢
IntelliJ IDEA 2020.2 稳定版已发布,此版本带来了不少新功能,包括支持在 IDE 中审查和合并 GitHub PR、新增加的 Inspections 小组件(Inspections Widget)支持在文件的警告和错误之间快速导航、使用 Problems 工具窗口查看当前文件中的完整问题列表,并在更改会破坏其他文件时收到通知。此外还有针对部分框架和技术的新功能,包括支持使 w397090770 4年前 (2020-07-29) 373℃ 0评论2喜欢
Hive 设计之初,就被定位一款离线数仓产品,虽然Hortonworks喊出了Make Apache Hive 100x Faster的牛逼口号,也在上面做了大量的优化,然而性能提升依旧不大。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆而随着OPPO数据量一步步的增多,动辄运行几个小时的hive再也满足不了交互查询的需求,因此我们 w397090770 4年前 (2021-03-05) 989℃ 0评论6喜欢
Storm和Spark Streaming两个都是分布式流处理的开源框架。但是这两者之间的区别还是很大的,正如你将要在下文看到的。处理模型以及延迟 虽然两框架都提供了可扩展性(scalability)和可容错性(fault tolerance),但是它们的处理模型从根本上说是不一样的。Storm可以实现亚秒级时延的处理,而每次只处理一条event,而Spark Streaming w397090770 10年前 (2015-03-12) 16667℃ 1评论6喜欢
假设现在的分支名称为 oldName,想要修改为 newName如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本地分支重命名这种情况是你的代码还没有推送到远程,分支只是在本地存在,那直接执行下面的命令即可:[code lang="bash"]git branch -m oldName newName[/code]远程分支重命名 如果你的分支已经推 w397090770 8年前 (2017-03-02) 728℃ 0评论1喜欢
Linux提供了spilt命令来切割文件,我们可以按照行、文件大小对一个大的文件进行切割。先来看看这个命令的帮助:[code lang="shell"][iteblog@iteblog iteblog]$ split --helpUsage: split [OPTION]... [INPUT [PREFIX]]Output fixed-size pieces of INPUT to PREFIXaa, PREFIXab, ...; defaultsize is 1000 lines, and default PREFIX is `x'. With no INPUT, or when INPUTis -, read standard input. w397090770 9年前 (2015-12-14) 3660℃ 0评论5喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 今天我很激动地宣布Spark 1.1.0发布了,Spark 1.1.0引入了许多新特征(new features)包括了可扩展性和稳定性方面的提升。这篇文章主要是介绍了Spark 1.1.0主要的特性,下面的介绍主要是根据各个特征重要性的优先级进行说明的。在接下来的两个星 w397090770 10年前 (2014-09-12) 4691℃ 2评论8喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopApache Iceberg 是一种用于跟踪超大规模表的新格式,是专门为对象存储(如S3)而设计的。 本文将介绍为什么 Netflix 需要构建 Iceberg,Apache Iceberg 的高层次设计,并会介绍那些能够更好地解决查询性能问题的细节。如果想及时了解Spark、Hadoop或者HBase w397090770 5年前 (2020-02-23) 2975℃ 0评论6喜欢
Spark Summit 2016 San Francisco会议于2016年6月06日至6月08日在美国San Francisco进行。本次会议有多达150位Speaker,来自业界顶级的公司。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料全部通过爬虫程序下载,如有问题 w397090770 8年前 (2016-06-15) 3368℃ 0评论9喜欢
我们在这篇文章简单介绍了 Apache Cassandra 是什么,以及有什么值得关注的特性。本文将简单介绍 Apache Cassandra 的安装以及简单使用,可以帮助大家快速了解 Apache Cassandra。我们到 Apache Cassandra 的官方网站下载最新版本的 Cassandra,在本文写作时最新版本的 Cassandra 为 3.11.4。Apache Cassandra 可以在 Linux、Unix、Mac OS 以及 Windows 上进行安装 w397090770 6年前 (2019-04-07) 5070℃ 0评论8喜欢
Web挖掘的目标是从Web的超链接结构、网页内容和使用日志中探寻有用的信息。虽然Web挖掘使用了许多数据挖掘技术,但它不仅仅是传统数据挖掘的一个简单的应用。在过去的20年中,许多新的挖掘任务和算法被相继提出。依据在挖掘过程中使用的数据类别,Web挖掘任务可以分为三种类型:Web结构挖掘、Web内容挖掘和Web使用挖掘。 w397090770 12年前 (2013-04-29) 4252℃ 0评论8喜欢
Apache HBase 是构建在 HDFS 之上的数据库,使用 HBase 我们可以随机读写存储在 HDFS 上的数据,但是我们都知道,HDFS 上的文件仅仅只支持追加(Append),其默认是不支持修改已经写好的文件。所以很多人就会问,HBase 是如何实现低延迟的读写能力呢?文本将试图介绍 HBase 写数据的过程。其实 HBase 写数据包括 put 和 delete 操作,在 HBase w397090770 6年前 (2019-01-02) 2567℃ 0评论12喜欢
在本博客的《Spark快速入门指南(Quick Start Spark)》文章中简单地介绍了如何通过Spark shell来快速地运用API。本文将介绍如何快速地利用Spark提供的API开发Standalone模式的应用程序。Spark支持三种程序语言的开发:Scala (利用SBT进行编译), Java (利用Maven进行编译)以及Python。下面我将分别用Scala、Java和Python开发同样功能的程序:一、Scala w397090770 10年前 (2014-06-10) 16435℃ 2评论7喜欢
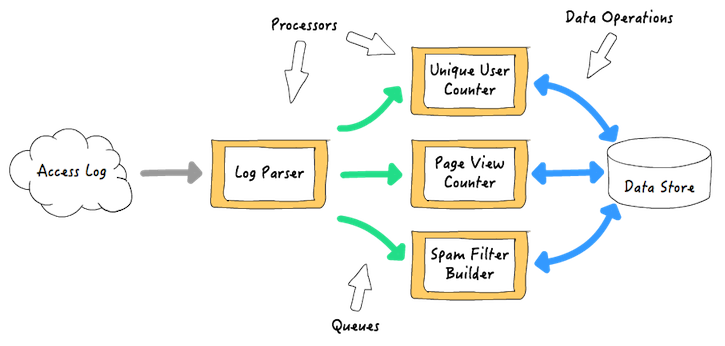
一个实时流处理框架通常需要两个基础架构:处理器和队列。处理器从队列中读取事件,执行用户的处理代码,如果要继续对结果进行处理,处理器还会把事件写到另外一个队列。队列由框架提供并管理。队列做为处理器之间的缓冲,传输数据和事件,这样处理器可以单独操作和扩展。例如,一个web 服务访问日志处理应用,可能是 w397090770 7年前 (2017-07-12) 584℃ 0评论0喜欢
Spark SQL小文件是指文件大小显著小于hdfs block块大小的的文件。过于繁多的小文件会给HDFS带来很严重的性能瓶颈,对任务的稳定和集群的维护会带来极大的挑战。一般来说,通过Hive调度的MR任务都可以简单设置如下几个小文件合并的参数来解决任务产生的小文件问题:[code lang="sql"]set hive.merge.mapfiles=true;set hive.merge.mapredfiles=true w397090770 4年前 (2020-07-03) 2393℃ 0评论3喜欢
前提条件:安装好相应版本的Hadoop(可以参见《在Fedora上部署Hadoop2.2.0伪分布式平台》)、安装好JDK1.6或以上版本(可以参见《如何在Linux平台命令行环境下安装Java1.6》) Hive的下载地址:http://archive.apache.org/dist/hive/,你可以选择你适合的版本去下载。本博客下载的Hive版本为0.8.0。你可以运行下面的命令去下载Hive,并解压:[ w397090770 11年前 (2013-11-01) 15347℃ 6评论3喜欢
本课程是Scala语言的入门课程,面向没有或仅有少量编程语言基础的同学,当然,具有一定的Java或C、C++语言基础将有助于本课程的学习。在本课程内,将更注重scala的各种语言规则与简单直接的应用,而不在于其是如何具体实现,通过学习本课程能具备初步的Scala语言实际编程能力。 此视频保证可以全部浏览,百度网盘 w397090770 10年前 (2015-03-21) 21924℃ 6评论46喜欢
程序的问题:已知数组a[n],求数组b[n].要求:b[i]=a[0]*a[1]*……*a[n-1]/a[i],不能用除法。a.时间复杂度O(n),空间复杂度O(1)。 b.除了迭代器i,不允许使用任何其它变量(包括栈临时变量等)大家有什么解法?先不要看我下面的解法。希望大家讨论讨论一下,留个言,一起交流一下。下面给出我的解法一:[code lang="CPP"]#include <stdio. w397090770 12年前 (2013-04-03) 4252℃ 0评论3喜欢
《Apache Spark快速入门:基本概念和例子(1)》 《Apache Spark快速入门:基本概念和例子(2)》 本文聚焦Apache Spark入门,了解其在大数据领域的地位,覆盖Apache Spark的安装及应用程序的建立,并解释一些常见的行为和操作。一、 为什么要选择Apache Spark 当前,我们正处在一个“大数据"的时代,每时每刻,都有各 w397090770 9年前 (2015-07-13) 6131℃ 1评论24喜欢
在 Spark AI Summit 的第一天会议中,数砖重磅发布了 Delta Engine。这个引擎 100% 兼容 Apache Spark 的向量化查询引擎,并且利用了现代化的 CPU 架构,优化了 Spark 3.0 的查询优化器和缓存功能。这些特性显著提高了 Delta Lake 的查询性能。当然,这个引擎目前只能在 Databricks Runtime 7.0 中使用。数砖研发 Delta Engine 的目的过去十年,存储的速 w397090770 4年前 (2020-06-28) 1020℃ 0评论1喜欢
一、活动时间 北京第八次Spark Meetup活动将于2015年06月27日进行;下午14:00-18:00。二、活动地点 海淀区海淀大街1号中关村梦想实验室(原中关村国际数字设计中心)4层三、活动内容 1、基于mesos和docker的spark实践 -- 马越 数人科技大数据核心开发工程师 2、Spark 1.4.0 新特性介绍 -- 朱诗雄 Databricks新晋 w397090770 9年前 (2015-06-17) 3085℃ 2评论2喜欢
今天早上我在博文里面更新了Spark 1.4.0正式发布,由于时间比较匆忙(要上班啊),所以在那篇文章里面只是简单地介绍了一下Spark 1.4.0,本文详细将详细地介绍Spark 1.4.0特性。如果你想尽早了解Spark等相关大数据消息,请关注本博客,或者本博客微信公共帐号iteblog_hadoop。 Apache Spark 1.4.0版本于美国时间2015年06月11日正式发 w397090770 9年前 (2015-06-12) 5044℃ 1评论1喜欢

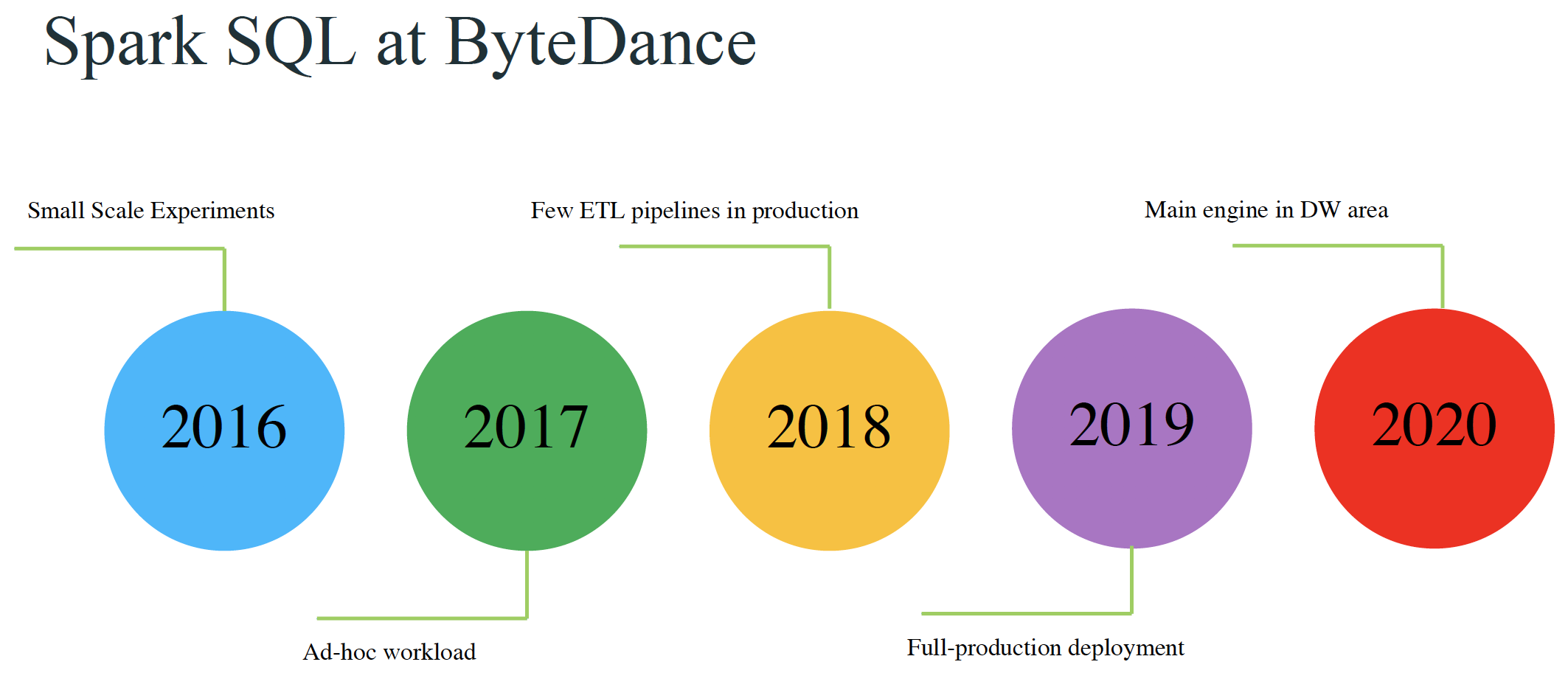


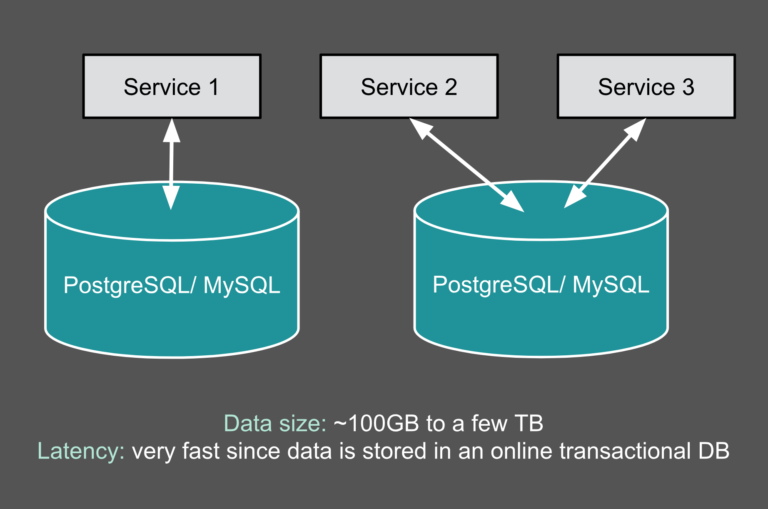










![练数成金—Scala语言入门视频百度网盘下载[全五课]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/3.jpg)