本文是 2021-10-13 日周三下午13:30 举办的议题为《Apache Hudi : The Path Forward》的分享,作者来自Apache Hudi 项目的原始创建者和副总裁 Vinoth Chandar 和 Zendesk 的 Raymond Xu。Raymond Xu leads the Data Lake team at Zendesk. He is also a PMC member and committer for Apache Hudi.Vinoth Chandar is the original creator & VP of the Apache Hudi project, which has changed the face of data lake archi w397090770 3年前 (2021-11-16) 463℃ 0评论1喜欢
经过几个星期的开发,本博客微信小程序(过往记忆大数据技术博客)正式上线了!至此大家可以通过微信公众号、微信小程序等方式访问本博客了。下面来看看本博客微信公众号的一些预览:微信小程序首页在首页可以查看本博客最新的文章,热门文章以及搜索等。文章页文章页可以文章的详情,功 w397090770 7年前 (2018-01-28) 1948℃ 0评论7喜欢
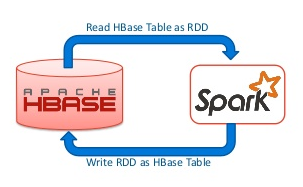
在使用Spark操作Hbase的时候,其返回的数据类型是RDD[ImmutableBytesWritable,Result],我们可能会对这个结果进行其他的操作,比如join等,但是因为org.apache.hadoop.hbase.io.ImmutableBytesWritable 和 org.apache.hadoop.hbase.client.Result 并没有实现 java.io.Serializable 接口,程序在运行的过程中可能发生以下的异常:[code lang="bash"]Serialization stack: - object not ser w397090770 8年前 (2017-03-23) 5385℃ 1评论13喜欢
导语:此套面试题来自于各大厂的真实面试题及常问的知识点。如果能理解吃透这些问题,你的大数据能力将会大大提升,进入大厂指日可待。如果公司急招人,你回答出来面试官70%,甚至50%的问题他都会要你,如果这个公司不是真正缺人,或者只是作人才储备,那么你回答很好,他也可能不要你,只是因为没有眼缘;所以面 zz~~ 3年前 (2021-09-24) 2303℃ 0评论9喜欢
美国时间2015年2月09日Spark 1.2.1正式发布了,邮件如下:Hi All,I've just posted the 1.2.1 maintenance release of Apache Spark. We recommend all 1.2.0 users upgrade to this release, as this release includes stability fixes across all components of Spark.- Download this release: http://spark.apache.org/downloads.html- View the release notes: http://spark.apache.org/releases/spark-release-1-2-1.html- w397090770 10年前 (2015-02-10) 3480℃ 0评论2喜欢
Apache Spark是目前非常强大的分布式计算框架。其简单易懂的计算框架使得我们很容易理解。虽然Spark是在操作大数据集上很有优势,但是它仍然需要将数据持久化存储,HDFS是最通用的选择,和Spark结合使用,因为它基于磁盘的特点,导致在实时应用程序中会影响性能(比如在Spark Streaming计算中)。而且Spark内置就不支持事务提交( w397090770 10年前 (2015-04-22) 10189℃ 0评论8喜欢
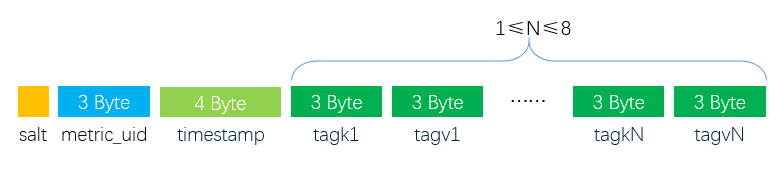
我们在 《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》 文章中已经简单介绍了 OpenTSDB 的 RowKey 设计的思路,并简单介绍了列簇以及列名的组成。本文将比较详细的介绍 OpenTSDB 在 HBase 的数据存储模型。OpenTSDB RowKey 设计关于 OpenTSDB 的 RowKey 为什么这么设计可以参见 《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》文章了。这里主要介绍 R w397090770 6年前 (2018-12-05) 2973℃ 0评论3喜欢
在过去一年有很多 Apache 孵化项目顺利毕业成顶级项目(Top-Level Project ,简称 TLP ),在这里我将给大家盘点 2020 年晋升为 Apache TLP 的大数据相关项目。在2020年一共有四个大数据相关项目顺利毕业成顶级项目,主要是 Apache® ShardingSphere™、Apache® Hudi™、Apache® Iceberg™ 以及 Apache® IoTDB™,这里以毕业的时间顺序依次介绍。关于过 w397090770 4年前 (2021-01-03) 1405℃ 0评论5喜欢
网易云音乐作为一个MAU已经超过亿级的业务,在数据仓库、数据体系、数据应用建设是怎么做的?在近日举办的“网易数帆技术沙龙”上,网易云音乐数据专家雷剑波就此话题做了全面的分享,介绍了数仓建设的目标,为此建立的一系列规范和机制,如何通过系统保证这些规范和机制的落地,以及取得的效果。数仓建设痛点与目 w397090770 3年前 (2021-06-30) 975℃ 0评论1喜欢
本文将介绍使用Spark batch作业处理存储于Hive中Twitter数据的一些实用技巧。首先我们需要引入一些依赖包,参考如下:[code lang="scala"]name := "Sentiment"version := "1.0"scalaVersion := "2.10.6"assemblyJarName in assembly := "sentiment.jar"libraryDependencies += "org.apache.spark" % "spark-core_2.10" % "1.6.0&qu zz~~ 8年前 (2016-08-31) 3333℃ 0评论5喜欢
经过近一个月时间,终于差不多将之前在Flume 0.9.4上面编写的source、sink等插件迁移到Flume-ng 1.5.0,包括了将Flume 0.9.4上面的TailSource、TailDirSource等插件的迁移(当然,我们加入了许多新的功能,比如故障恢复、日志的断点续传、按块发送日志以及每个一定的时间轮询发送日志而不是等一个日志发送完才发送另外一个日志)。现在 w397090770 10年前 (2014-06-18) 17494℃ 13评论15喜欢
如果你对Hadoop有基本的了解,并希望将您的知识用于企业的大数据解决方案,那你就来阅读本书吧。本书提供了六个使用Hadoop生态系统解决实际问题的例子,使得您的Hadoop知识提升到一个新的水平。本书作者:Anurag Shrivastava,由Packt出版社于2016年9月出版,全书共316页。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关 zz~~ 8年前 (2016-12-20) 3230℃ 1评论6喜欢
Introduce Apache Flink 提供了可以恢复数据流应用到一致状态的容错机制。确保在发生故障时,程序的每条记录只会作用于状态一次(exactly-once),当然也可以降级为至少一次(at-least-once)。 容错机制通过持续创建分布式数据流的快照来实现。对于状态占用空间小的流应用,这些快照非常轻量,可以高频率创建而对性能影 zz~~ 8年前 (2017-02-08) 4559℃ 0评论7喜欢
用 Kafka 这么久,从来都没去了解 Kafka 消息的格式。今天特意去网上搜索了以下,发现这方面的资料真少,很多资料都是官方文档的翻译;而且 Kafka 消息支持压缩,对于压缩消息的格式的介绍更少。基于此,本文将以图文模式介绍 Kafka 0.7.x、0.8.x 以及 0.10.x 等版本 Message 格式,因为 Kafka 0.9.x 版本的消息格式和 0.8.x 一样,我就不单独 w397090770 7年前 (2017-08-11) 3691℃ 0评论16喜欢
Apache HBase 是构建在 HDFS 之上的数据库,使用 HBase 我们可以随机读写存储在 HDFS 上的数据,但是我们都知道,HDFS 上的文件仅仅只支持追加(Append),其默认是不支持修改已经写好的文件。所以很多人就会问,HBase 是如何实现低延迟的读写能力呢?文本将试图介绍 HBase 写数据的过程。其实 HBase 写数据包括 put 和 delete 操作,在 HBase w397090770 6年前 (2019-01-02) 2567℃ 0评论12喜欢
以较低的硬件成本扩展我们的数据基础设施,同时保持高性能和服务可靠性并非易事。 为了适应 Uber 数据存储和分析计算的指数级增长,数据基础设施团队通过结合硬件重新设计软件层,以扩展 Apache Hadoop® HDFS :HDFS Federation、Warm Storage、YARN 在 HDFS 数据节点上共存,以及 YARN 利用率的提高提高了系统的 CPU 和内存使用效率将多 w397090770 3年前 (2021-10-21) 430℃ 0评论3喜欢
本文节选自《大数据之路:阿里巴巴大数据实践》,关注 iteblog_hadoop 公众号并在这篇文章里面文末评论区留言(认真写评论,增加上榜的机会)。留言点赞数排名前5名的粉丝,各免费赠送一本《大数据之路:阿里巴巴大数据实践》,活动截止至08月11日18:00。这篇文章评论区留言才有资格参加送书活动:https://mp.weixin.qq.com/s/BR7M8Rty w397090770 7年前 (2017-08-03) 1681℃ 0评论11喜欢
活动时间 1月24日下午14:00活动地点 地址:海淀区中关村软件园二期,西北旺东路10号院东区,亚信大厦 一层会议室 地图:http://j.map.baidu.com/L_1hq 为了保证大家乘车方便,特提供活动大巴时间:13:20-13:40位置:http://j.map.baidu.com/SJOLy分享内容: 邵赛赛 Intel Spark Streaming driver high availability w397090770 10年前 (2015-01-22) 15586℃ 0评论2喜欢
本文将介绍如何手动更新Kafka存在Zookeeper中的偏移量。我们有时候需要手动将某个主题的偏移量设置成某个值,这时候我们就需要更新Zookeeper中的数据了。Kafka内置为我们提供了修改偏移量的类:kafka.tools.UpdateOffsetsInZK,我们可以通过它修改Zookeeper中某个主题的偏移量,具体操作如下:[code lang="bash"][iteblog@www.iteblog.com ~]$ bin/ka w397090770 9年前 (2016-04-19) 15167℃ 0评论12喜欢
Carlos E. Perez对深度学习的2017年十大预测,让我们不妨看一看。有兴趣的话,可以在一年之后回顾这篇文章,看看这十大预测有多少准确命中硬件将加速一倍摩尔定律(即2017年2倍) 如果你跟踪Nvidia和Intel的发展,这当然是显而易见的。Nvidia将在整个2017年占据主导地位,只因为他们拥有最丰富的深度学习生态系统。没有头 w397090770 8年前 (2016-12-13) 2196℃ 0评论3喜欢
《Spark RDD API扩展开发(1)》、《Spark RDD API扩展开发(2):自定义RDD》 我们都知道,Apache Spark内置了很多操作数据的API。但是很多时候,当我们在现实中开发应用程序的时候,我们需要解决现实中遇到的问题,而这些问题可能在Spark中没有相应的API提供,这时候,我们就需要通过扩展Spark API来实现我们自己的方法。我们可 w397090770 10年前 (2015-03-30) 7184℃ 2评论15喜欢
Shanghai Apache Spark Meetup第十次聚会活动将于2016年09月10日12:30 至 17:20在四星级的上海通茂大酒店 (浦东新区陆家嘴金融区松林路357号)。距离地铁2、4、6、9号线的世纪大道站1000米,距离地铁4号线浦电路站740米。本次活动分别请到了运营商和高校系统的讲师来分享经验,主题覆盖了从研发到应用的各种不同视角,希望带给大家耳目 w397090770 8年前 (2016-08-25) 1399℃ 5评论2喜欢
样本数据集 现在我们对于基本的东西已经有了一些认识,现在让我们尝试使用一些更加贴近现实的数据集。我准备了一些假想的客户银行账户信息的JSON文档样本。文档具有以下的模式(schema):[code lang="java"]{ "account_number": 0, "balance": 16623, "firstname": "Bradshaw", "lastname": &quo zz~~ 8年前 (2016-09-04) 1035℃ 0评论5喜欢
存储计算分离是整个行业的发展趋势,这种架构的存储和计算可以各自独立发展,它帮助云提供商降低成本。Presto 原生就支持这样的架构,数据可以从 Presto 服务器之外的远程存储节点传输过来。然而,存储计算分解也为查询延迟带来了新的挑战,因为当网络饱和时,通过网络扫描大量数据将受到 IO 限制。 此外,元数据的读取 w397090770 3年前 (2021-12-05) 765℃ 0评论2喜欢
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。 本文并不打算介绍ElasticSearch的概 w397090770 8年前 (2016-08-10) 36792℃ 2评论73喜欢
Presto 内部提供了大量内置的函数,可以满足我们大部分的日常需求。但总是有一些场景需要我们自己写 UDF,为了满足这个需求,Presto 给我们提供了 Function Namespace Managers 模块使得我们可以实现直接的 UDF。本文将给大家介绍一下如何使用 Presto 的 UDF 功能。如果需要使用 Function Namespace Managers 功能,需要把 presto-catalog-managers 模块里 w397090770 3年前 (2022-03-15) 1001℃ 0评论1喜欢
最近,本博客由于流量增加,网站响应速度变慢,于是将全站页面全部静态化了;其中采取的方式主要是(1)、把所有https://www.iteblog.com/archives/\d{1,}全部跳转成https://www.iteblog.com/archives/\d{1,}.html,比如之前访问https://www.iteblog.com/archives/1983链接会自动跳转到https://www.iteblog.com/archives/1983.html;(2)、所有https://www.iteblog.com/page页 w397090770 8年前 (2017-02-22) 3716℃ 2评论9喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 今天我很激动地宣布Spark 1.1.0发布了,Spark 1.1.0引入了许多新特征(new features)包括了可扩展性和稳定性方面的提升。这篇文章主要是介绍了Spark 1.1.0主要的特性,下面的介绍主要是根据各个特征重要性的优先级进行说明的。在接下来的两个星 w397090770 10年前 (2014-09-12) 4691℃ 2评论8喜欢
为期三天的 SPARK + AI SUMMIT Europe 2019 于 2019年10月15日-17日荷兰首都阿姆斯特丹举行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。Spark+AI Summit Europe 2019 是欧洲最大的数据和机器学习会议,大约有1700多名数据科学家、工程师和分析师参加此次会议。本次会议的提议包括了A w397090770 5年前 (2019-11-01) 1496℃ 1评论0喜欢
在本博客的《Flume-1.4.0和Hbase-0.96.0整合》我们已经学习了如何使用Flume-1.4.0和Hbase-0.96.0进行整合。我们可以很容易的配置Hbase sink,并和最新版的Hbase整合,但是由于项目的特殊情况,我需要将Flume-0.9.4和Hbase-0.96整合,搞过这个的人应该知道,Flume-0.9.4和Hbase-0.96非常棘手,各种版本的不兼容等情况,最终通过我和同事的两天奋战 w397090770 11年前 (2014-01-25) 7144℃ 1评论2喜欢






![[电子书]Hadoop Blueprints pdf下载](https://www.iteblog.com/pic/Hadoop_Blueprints-iteblog.jpg)














![Spark+AI Summit Europe 2019 PPT 下载[共122个]](https://www.iteblog.com/pic/spark/spark+ai_summit_europe_2019-iteblog.jpg)