Spark 1.1.1于美国时间的2014年11月26日正式发布。基于branch-1.1分支,主要修复了一些bug。推荐所有的1.1.0用户更新到这个稳定版本。本次更新共有55位开发者参与。 spark.shuffle.manager仍然使用Hash作为默认值,说明了SORT的Shuffle还不怎么成熟。等待1.2版本吧。Fixes Spark 1.1.1修复了几个组件的bug。在下面将会列出一些代表性的b w397090770 10年前 (2014-11-28) 3302℃ 0评论5喜欢
Angle Admin Template是一款后台管理模板,使用Bootstrap3.x作为界面框架,支持响应式布局。Angle包含JQuery和AngularJS两种js框架,方便SPA的使用,并且该模板提供了ASP.NET MVC、Angular、Rails等项目模板以及相应的种子模板,方便使用。点击下载Angle 3.5.4主题 该系列由于界面清爽,插件足够多、代码使用方便,文档齐全(英文), w397090770 8年前 (2017-02-25) 3222℃ 0评论16喜欢
Spark 1.5.0是1.x线上的第6个发行版。这个版本共处理了来自230+contributors和80+机构的1400+个patches。Spark 1.5的许多改变都是围绕在提升Spark的性能、可用性以及操作稳定性。Spark 1.5.0焦点在Tungsten项目,它主要是通过对低层次的组建进行优化从而提升Spark的性能。Spark 1.5版本为Streaming增加了operational特性,比如支持backpressure。另外比较重 w397090770 9年前 (2015-09-09) 2997℃ 0评论12喜欢
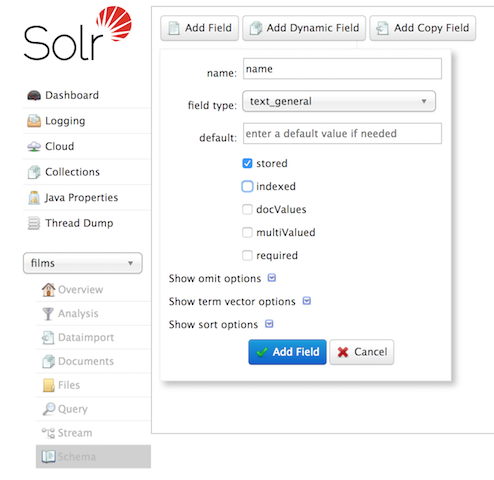
到目前为止,我们往 Solr 里面导数据都没有定义模式,也就是说让 Solr 去猜我们数据的类型以及解析方式,这种方式成为无模式(Schemaless)。Apache Solr 里面的定义为:One reason for this is we’re going to use a feature in Solr called "field guessing", where Solr attempts to guess what type of data is in a field while it’s indexing it. It also automatically creates new fields in th w397090770 6年前 (2018-08-01) 1694℃ 0评论4喜欢
本文是《A Scala Tutorial for Java programmers》英文的翻译,英文版地址A Scala Tutorial for Java programmers。是Michel Schinz和Philipp Haller编写,由Bearice成中文,dongfengyee(东风雨)整理.一、简介二、 第一个Scala例子三、Scala与Java交互四、Scala:万物皆对象五、Scala类六、Scala的模式匹配和条件类七、Scala Trait八、Scala的泛型九、 w397090770 10年前 (2015-04-18) 16254℃ 0评论37喜欢
这里用到的nginx日志是网站的访问日志,比如:[code lang="java"]180.173.250.74 - - [08/Jan/2015:12:38:08 +0800] "GET /avatar/xxx.png HTTP/1.1" 200 968 "/archives/994" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36"[/code] 这条日志里面有九列(为了展示的美观,我在里面加入了换行 w397090770 10年前 (2015-01-08) 14242℃ 2评论17喜欢
C++允许为模板类中的类型参数指定为一个迷人类型,例如:我们可以将int赋予通用类Stack中的类型参数T,作为默认类型,如下所示:[code lang="CPP"]templateclass Stack{//other operator};[/code]现在我们就可以像如下代码一样使用默认类型来声明模板类对象了:[code lang="CPP"]Stack<> stack; //store int value[/code]但是需要注意 w397090770 12年前 (2013-04-04) 4187℃ 1评论0喜欢
在 LinkedIn,我们使用 Hadoop 作为大数据分析和机器学习的基础组件。随着数据量呈指数级增长,并且公司在机器学习和数据科学方面进行了大量投资,我们的集群规模每年都在翻倍,以匹配计算工作负载的增长。我们最大的集群现在有大约 10,000 个节点,是全球最大(如果不是最大的)Hadoop 集群之一。多年来,扩展 Hadoop YARN 已成为 w397090770 3年前 (2021-09-18) 536℃ 0评论4喜欢
来自于requests的灵感,因为它很简单;并且由lxml驱动,因为它速度很快。 Newspaper是一个惊人的新闻、全文以及文章元数据抽取开源的Python类库,这个类库支持10多种语言,所有的东西都是用unicode编码的。我们可以使用下面命令查看:[code lang="python"]/** * User: 过往记忆 * Date: 2015-05-20 * Time: 下午23:14 * bolg: * 本文地 w397090770 9年前 (2015-05-20) 2748℃ 0评论0喜欢
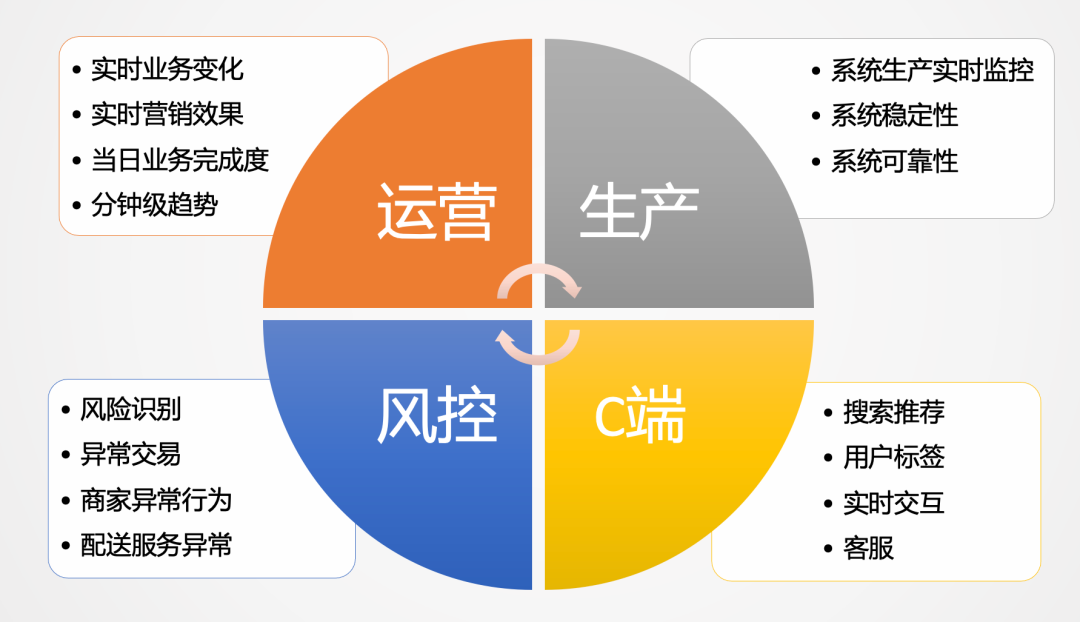
本文主要介绍一种通用的实时数仓构建的方法与实践。实时数仓以端到端低延迟、SQL标准化、快速响应变化、数据统一为目标。美团外卖数据智能组总结的最佳实践是:一个通用的实时生产平台跟一个通用交互式实时分析引擎相互配合,同时满足实时和准实时业务场景。两者合理分工,互相补充,形成易开发、易维护且效率高的流 zz~~ 3年前 (2021-09-24) 561℃ 0评论2喜欢
目前Spark支持四种方式从数据库中读取数据,这里以Mysql为例进行介绍。一、不指定查询条件 这个方式链接MySql的函数原型是:[code lang="scala"]def jdbc(url: String, table: String, properties: Properties): DataFrame[/code] 我们只需要提供Driver的url,需要查询的表名,以及连接表相关属性properties。下面是具体例子:[code lang="scala" w397090770 9年前 (2015-12-28) 37731℃ 1评论61喜欢
我们在《Apache Cassandra 简介》文章中介绍了 Cassandra 的数据模型类似于 Google 的 Bigtable,对应的开源实现为 Apache HBase,而且我们在 《HBase基本知识介绍及典型案例分析》 文章中简单介绍了 Apache HBase 的数据模型。按照这个思路,Apache Cassandra 的数据模型应该和 Apache HBase 的数据模型很类似,那么这两者的数据存储模型是不是一样的呢? w397090770 5年前 (2019-04-28) 1762℃ 0评论4喜欢
基于社区开发者们的观察,绝大多数的Spark应用程序的瓶颈不在于I/O或者网络,而在于CPU和内存。基于这个事实,开发者们发起了Tungsten项目,而Spark 1.5是Tungsten项目的第一阶段。Tungsten项目主要集中在三个方面,于此来提高Spark应用程序的内存和CPU的效率,使得性能能够接近硬件的限制。Tungsten项目的三个阶段内存管理和二 w397090770 9年前 (2015-09-09) 7374℃ 0评论5喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Improve Presto Architectural Decisions with Shadow Cache at Facebook》的分享,作者来自 Facebook 的 Ke Wang 和 普林斯顿CS系的 Zhenyu Song。Ke Wang is a software engineer at Facebook. She is currently developing solutions to help low latency queries in Presto at Facebook.Zhenyu Song is a Ph.D. student at Princeton CS Department. He works on using mach w397090770 3年前 (2021-11-16) 259℃ 0评论1喜欢
一、概述有时候我们需要设计这样一种数据结构:它能快速在要求位置插入或者删除一段数据。先考虑两种简单的数据结构:数组和链表。数组的优点是能够在O(1)的时间内找到所要执行操作的位置,但其缺点是无论是插入或删除都要移动之后的所有数据,复杂度是O(n)的。链表优点是能够在O(1)的时间内插入和删除一段数据,但缺点 w397090770 12年前 (2013-04-03) 5830℃ 0评论7喜欢
spark.cleaner.ttl参数的原意是清除超过这个时间的所有RDD数据,以便腾出空间给后来的RDD使用。周期性清除保证在这个时间之前的元数据会被遗忘,对于那些运行了几小时或者几天的Spark作业(特别是Spark Streaming)设置这个是很有用的。注意:任何内存中的RDD只要过了这个时间就会被清除掉。官方文档是这么介绍的:Duration (secon w397090770 9年前 (2015-05-20) 8113℃ 0评论7喜欢
我们在安装软件的时候,有时会出现由于依赖的软件没有被安装,会导致软件安装的失败,其实我们可以用命令来安装依赖的软件,这里以Ubuntu为例进行说明。 我在安装wps-office的时候,显示安装成功了,但是还是无法运行,后来才知道原来有些依赖的软件没有安装,导致wps无法运行。我们可以用户下面的命令查看依赖的 w397090770 10年前 (2014-11-21) 7106℃ 0评论2喜欢
本书旨在通过教你如何扩展Spark的功能,将你对Spark的有限知识提升到一个新的水平。全书从Spark生态系统开始概述,您将学习如何使用MLlib创建一个完全的神经网络系统,然后您将了解如何调整流处理以获得最佳性能并确保并行处理。本书作者Mike Frampton,由Packt 于2015年09月出版,全书318页,通过本书你将学到以下知识: ( w397090770 8年前 (2016-12-04) 3796℃ 0评论9喜欢
随着越来越多的公司广泛部署 Presto,Presto 不仅用于查询,还用于数据摄取和 ETL 作业。所有很有必要提高 Presto 文件写入的性能,尤其是流行的列文件格式,如 Parquet 和 ORC。本文我们将介绍 Presto 的全新原生的 Parquet writer ,它可以直接将 Presto 的列式数据结构写到 Parquet 的列式格式,最高可提高6倍的吞吐量,并减少 CPU 和内存开销 w397090770 3年前 (2021-08-14) 513℃ 0评论2喜欢
在《Hadoop 1.x中fsimage和edits合并实现》文章中提到,Hadoop的NameNode在重启的时候,将会进入到安全模式。而在安全模式,HDFS只支持访问元数据的操作才会返回成功,其他的操作诸如创建、删除文件等操作都会导致失败。 NameNode在重启的时候,DataNode需要向NameNode发送块的信息,NameNode只有获取到整个文件系统中有99.9%(可以配 w397090770 11年前 (2014-03-13) 17328℃ 3评论16喜欢
我们先来看看官方文档是怎么对Tachyon进行描述的:Tachyon is a memory-centric distributed storage system enabling reliable data sharing at memory-speed across cluster frameworks, such as Spark and MapReduce. It achieves high performance by leveraging lineage information and using memory aggressively. Tachyon caches working set files in memory, thereby avoiding going to disk to load datasets that are frequently w397090770 9年前 (2015-08-27) 3176℃ 4评论2喜欢
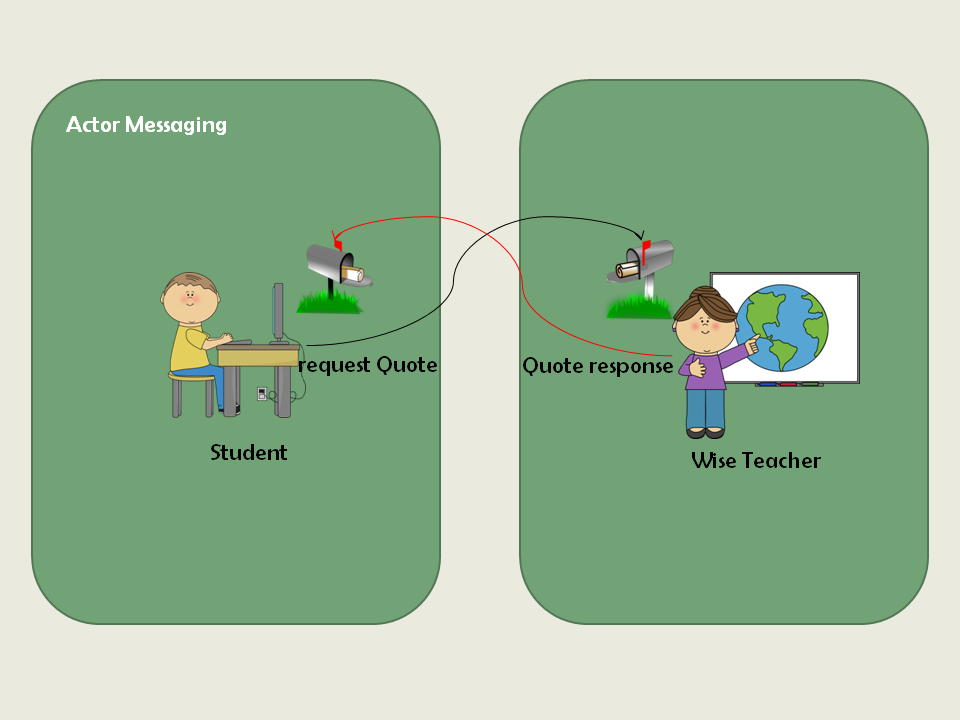
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-12) 28228℃ 4评论119喜欢
Marius Eriksen, Twitter Inc. marius@twitter.com (@marius) [translated by hongjiang(@hongjiang), tongqing(@tongqing)]序言 Scala是Twitter使用的主要应用编程语言之一。很多我们的基础架构都是用scala写的,我们也有一些大的库支持我们使用。虽然非常有效, Scala也是一门大的语言,经验教会我们在实践中要非常小心。 它有什么陷阱?哪些特 w397090770 10年前 (2015-04-11) 7430℃ 0评论3喜欢
本博客曾经介绍了《如何手动添加依赖的jar文件到本地Maven仓库》这里的方法非常的简单,而且局限性很大:只能提供给本人开发使用,无法共享给其他需要的人。本文将介绍如何把自己开发出来的Java包发布到Maven中央仓库(http://search.maven.org/),这样任何人都可以搜索到这个包并使用它。如果你现在还不了解Maven是啥东西,请你 w397090770 8年前 (2016-09-27) 9709℃ 2评论23喜欢
在《Flink本地模式安装(Local Setup)》的文章中,我简单地介绍了如何本地模式安装(Local Setup)Flink,本文将介绍如何Flink集群模式安装,主要是Standalone方式。要求(Requirements)Flink可以在Linux, Mac OS X 以及Windows(通过Cygwin)等平台上运行。集群模式主要是由一个master节点和一个或者多个worker节点组成。在你启动集群的各个组件之前 w397090770 9年前 (2016-04-20) 11865℃ 0评论9喜欢
一、首先到oracle的官网下载Berkeley db数据库源文件下载地址http://download.oracle.com/otn/berkeley-db/db-5.3.15.tar.gz二、下载之后的文件是一个打包好的文件,需要在命令行里面利用tar来解压(当然你也可以利用一些可视化工具来解压),步骤如下在命令行里面输入[code lang="CPP"] tar -zxvf db-5.3.15.tar.gz[/code]解压之后进入db-5.3.15目录有以下 w397090770 12年前 (2013-04-04) 3942℃ 0评论0喜欢
Hadoop权威指南英文版第四版,它的内容组织得当,思路清晰,紧密结合实际。但是要把它翻译成中文介绍给中国的读者,并非易事。它不单单要求译者能够熟练地掌握英文,还要求他们对书中的技术性内容有深入、准确的了解和掌握。从这两点来审视,本书的译者团队完全足以胜任。作为大学老师,他们不仅在大数据领域从事一线 w397090770 9年前 (2015-08-15) 4775℃ 0评论9喜欢
Hadoop 2.5.2 w397090770 10年前 (2014-12-01) 11811℃ 0评论5喜欢
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。详情参见《CarbonData:华为开发并支持Hadoop的列式文件格式》,本文是单机模式下使用CarbonData的,如果你需要集群模 w397090770 8年前 (2016-07-01) 8378℃ 3评论6喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ 如果你想查询某个表的某 w397090770 11年前 (2013-11-13) 17994℃ 4评论17喜欢











![[电子书]Mastering Apache Spark下载](https://www.iteblog.com/pic/books/Mastering_Apache_Spark.jpg)