我们在《Kafka创建Topic时如何将分区放置到不同的Broker中》文章中已经学习到创建 Topic 的时候分区是如何分配到各个 Broker 中的。今天我们来介绍分区分配到 Broker 中之后,会再哪个目录下创建文件夹。我们知道,在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录 w397090770 7年前 (2017-08-09) 5068℃ 0评论15喜欢
前两篇文章,《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 和 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 分别介绍了两种方法读取加盐之后的 HBase 表。本文将介绍如何在 MapReduce 读取加盐之后的表。在 MapReduce 中也可以使用 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 文章里面的 SaltRangeTableInputForm w397090770 6年前 (2019-02-27) 2933℃ 0评论7喜欢
如果你想配置完全分布式平台请参见本博客《Hadoop2.2.0完全分布式集群平台安装与设置》 首先,你得在电脑上面安装好jdk7,如何安装,这里就不说了,网上一大堆教程!然后安装好ssh,如何安装请参见本博客《Linux平台下安装SSH》、并设置好无密码登录(《Ubuntu和CentOS如何配置SSH使得无密码登陆》)。好了,上面的 w397090770 11年前 (2013-10-28) 9439℃ 7评论7喜欢
我们都知道,目前 Apache Beam 仅仅提供了 Java 和 Python 两种语言的 API,尚不支持 Scala 相关的 API。基于此全球最大的流音乐服务商 Spotify 开发了 Scio ,其为 Apache Beam 和 Google Cloud Dataflow 提供了Scala API,使得我们可以直接使用 Scala 来编写 Beam 应用程序。Scio 开发受 Apache Spark 和 Scalding 的启发,目前最新版本是 Scio 0.3.0,0.3.0版本之前依赖 w397090770 7年前 (2017-07-25) 1269℃ 0评论7喜欢
HDFS 简介因为 HDFS 这样一个系统已经存在了非常长的时间,应用的场景已经非常成熟了,所以这部分我们会比较简单地介绍。HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:和本地文件系统一样的目录树视图Append Only 的写入(不支持 w397090770 5年前 (2020-01-10) 2382℃ 0评论4喜欢
从名字就可以看出这是笛卡儿的意思,就是对给的两个RDD进行笛卡儿计算。官方文档说明:Return the Cartesian product of this RDD and another one, that is, the RDD of all pairs of elements (a, b) where a is in `this` and b is in `other`.函数原型[code lang="scala"]def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)][/code] 该函数返回的是Pair类型的RDD,计算结果 w397090770 10年前 (2015-03-07) 11253℃ 0评论5喜欢
今天,Apache Beam 0.5.0 发布了,此版本通过新的State API添加对状态管道的支持,并通过新的Timer API添加对计时器的支持。 此外,该版本还为Elasticsearch和MQ Telemetry Transport(MQTT)添加了新的IO连接器,以及常见的一些错误修复和改进。对于此版本中的所有主要更改,请参阅release notes。如果想及时了解Spark、Hadoop或者Hbase相关的文 w397090770 8年前 (2017-02-10) 1027℃ 0评论2喜欢
在数据量日益增长的当下,传统数据库的查询性能已满足不了我们的业务需求。而Clickhouse在OLAP领域的快速崛起引起了我们的注意,于是我们引入Clickhouse并不断优化系统性能,提供高可用集群环境。本文主要讲述如何通过Clickhouse结合大数据生态来定制一套完善的数据分析方案、如何打造完备的运维管理平台以降低维护成本,并结合具 w397090770 4年前 (2021-01-22) 1813℃ 0评论2喜欢
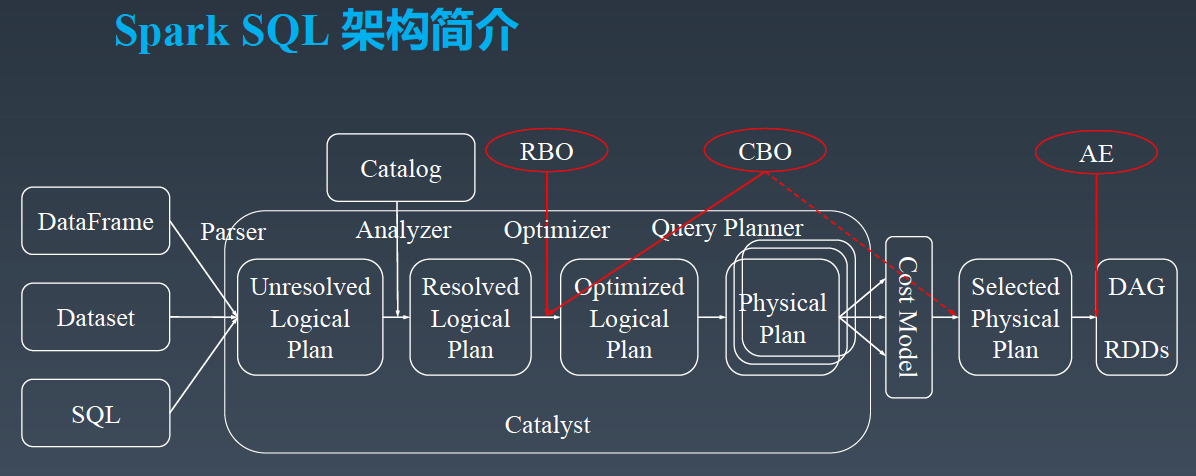
以下是字节跳动数据仓库架构负责人郭俊的分享主题沉淀,《字节跳动在Spark SQL上的核心优化实践》。PPT 请微信关注过往记忆大数据,并回复 bd_sparksql 获取。今天的分享分为三个部分,第一个部分是 SparkSQL 的架构简介,第二部分介绍字节跳动在 SparkSQL 引擎上的优化实践,第三部分是字节跳动在 Spark Shuffle 稳定性提升和性能 w397090770 5年前 (2019-12-03) 4298℃ 0评论3喜欢
近日,红杏官方为了方便开发人员,公布了红杏公益版代理,该代理地址和端口为hx.gy:1080,可以在浏览器、IDE里面进行设置,并且访问很多常用的网站。目前支持的域名如下:[code lang="scala"]android.combitbucket.orgbintray.comchromium.orgclojars.orgregistry.cordova.iodartlang.orgdownload.eclipse.orggithub.comgithubusercontent.comgolang.orggoogl w397090770 10年前 (2015-04-15) 18250℃ 0评论22喜欢
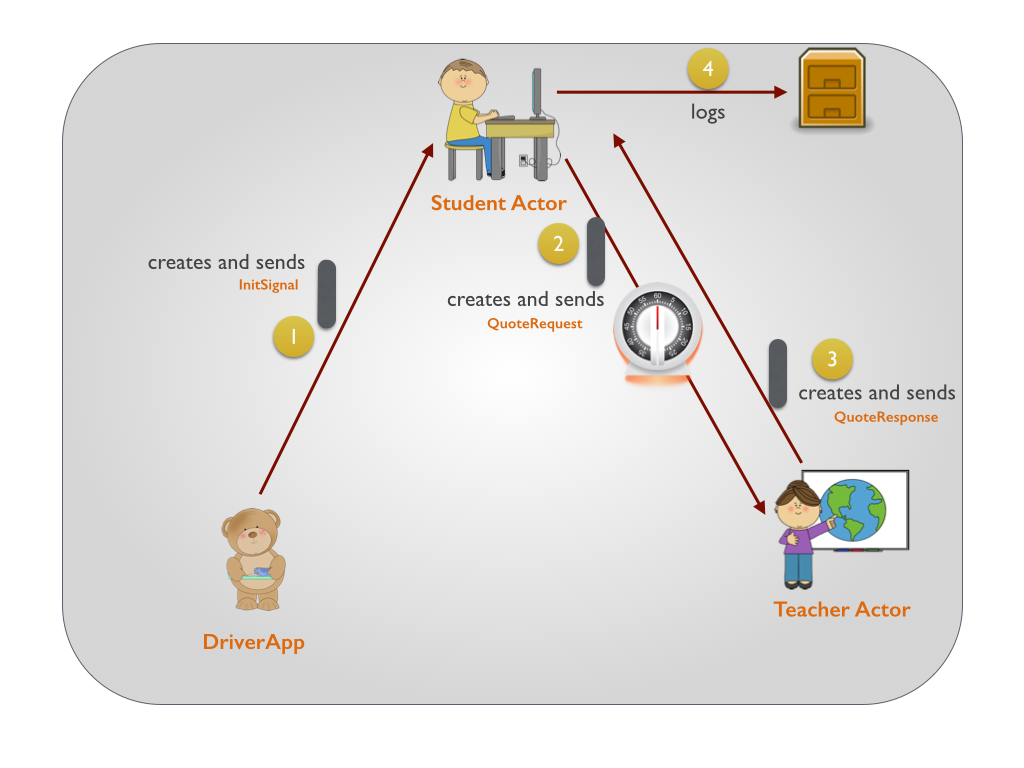
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-22) 19202℃ 3评论14喜欢
下面论文均为大数据和分布式比较经典的论文,包括:CAP、BASE、2PC、一致性协议、一致性哈希、逻辑时钟、Leases 等。如果大家还有比较好的论文,欢迎在下面评论。分布式理论 Time, Clocks, and the Ordering of Events in a Distributed System Reaching Agreement in the Presence of Faults The Byzantine General Problem (CAP) Brewer's Conjecture and the Feasibility of w397090770 8年前 (2017-02-15) 3677℃ 0评论10喜欢
想必大家在使用Maven从仓库下载Jar的时候都感觉速度非常慢吧。前几年国内的开源中国还提供了免费的Maven镜像,但是由于运营成本过高,此Maven仓库在运营两年后被迫关闭了。不过高兴的是,阿里云在2016年08月悄悄上线了Maven仓库,点这里:http://maven.aliyun.com。我们可以把下面的配置复制到$MAVEN_HOME/conf/setting.xml里面:如果想及时 w397090770 8年前 (2017-02-16) 18302℃ 1评论6喜欢
在介绍 HBase 是不是列式存储数据库之前,我们先来了解一下什么是行式数据库和列式数据库。行式数据库和列式数据库在维基百科里面,对行式数据库和列式数据库的定义为:列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理(OLAP)和即时查询。相对应的是行式数据库,数据以行相关的存储体 w397090770 6年前 (2019-01-08) 6332℃ 0评论31喜欢
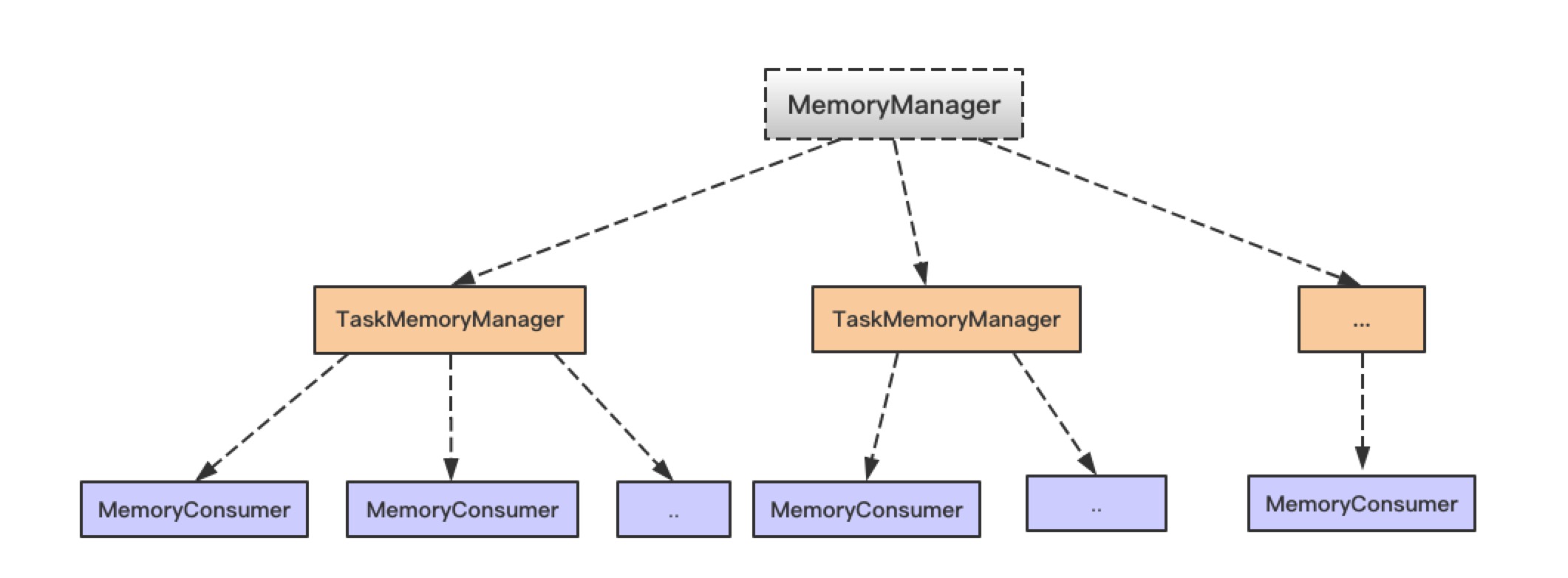
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段。那么在 Spark Shuffle 中具体是哪些地方会使用比较多的内存而有可能导致 OOM 呢? 为此,本文将围绕以上问题梳理 Spark 内存管理和 Shuffle 过程中与内存使用相关的知识;然后,简要分析下在 Spark Shuffle 中有可能导致 OOM w397090770 6年前 (2019-03-17) 5358℃ 0评论19喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事在《Hive内置数据类型》文章中,我们提到了Hive w397090770 11年前 (2014-01-07) 139346℃ 1评论481喜欢
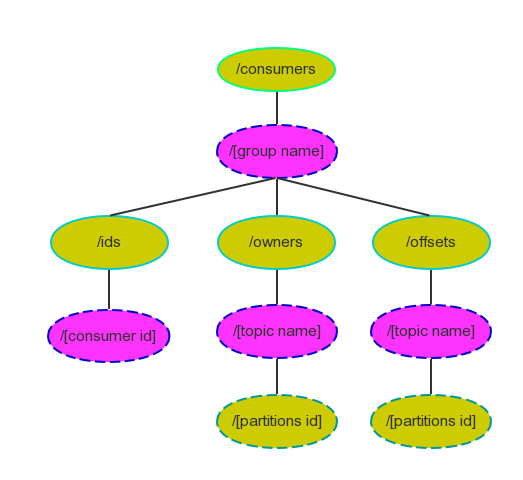
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》High Level Consumer 很多时候,客户程序只是希望从Kafka读取数据,不太关心消息offset的处理。同时也希望提供一些语义,例如同 w397090770 9年前 (2015-09-08) 9635℃ 0评论22喜欢
在这篇文章中,我将介绍一下Spark SQL对Json的支持,这个特性是Databricks的开发者们的努力结果,它的目的就是在Spark中使得查询和创建JSON数据变得非常地简单。随着WEB和手机应用的流行,JSON格式的数据已经是WEB Service API之间通信以及数据的长期保存的事实上的标准格式了。但是使用现有的工具,用户常常需要开发出复杂的程序 w397090770 10年前 (2015-02-04) 14334℃ 1评论16喜欢
本文将介绍如何通过简单地几步来开始编写你的 Flink Java 程序。要求 编写你的Flink Java程序唯一的要求是需要安装Maven 3.0.4(或者更高)和Java 7.x(或者更高) 创建Flink Java工程使用下面其中一个命令来创建Flink Java工程1、使用Maven archetypes:[code lang="bash"]$ mvn archetype:generate \ -DarchetypeGrou w397090770 9年前 (2016-04-06) 13883℃ 0评论8喜欢
第一题,基础题: 1. 数据库及线程产生死锁的原理和必要条件,如何避免死锁。 2. 列举面向对象程序设计的三个要素和五项基本原则。 3.Windows内存管理的方式有哪些?各自的优缺点。第二题,算法与程序设计: 1.公司举行羽毛球比赛,采用淘汰赛,有1001个人参加,要决出“羽毛球最高选手”,应如何组织这 w397090770 12年前 (2013-04-20) 9126℃ 0评论10喜欢
Spark Summit East 2016:视频,PPT Spark Summit East 2016会议于2016年2月16日至2月18日在美国纽约进行。总体来说,Spark Summit一年比一年火,单看纽约的峰会中,规模已从900人增加到500个公司的1300人,更吸引到更多大型公司的分享,包括Bloomberg、Capital One、Novartis、Comcast等公司。而在这次会议上,Databricks还发布了两款产品——Commu w397090770 9年前 (2016-02-27) 5667℃ 0评论14喜欢
随着网站的文章越来越多,网站的图片也不知不觉的多了起来,图片多起来带来的问题就是访问的人多的时候会导致页面加载速度越来越慢,这严重影响了网站的用户体验,所以网站图片异步加载势在必行。 图片异步加载就是图片只有在视野范围内才加载,没出现在范围内的图片就暂不加载,等用户滑动滚动条时再逐步 w397090770 8年前 (2016-07-08) 3443℃ 0评论7喜欢
Alluxio Meetup 上海站由 Alluxio、七牛主办,示说网、过往记忆协办,本次会议将于2018年10月27日 13:30-17:00 在上海市张江高科博霞路66号浦东软件园Q座举行。报名地址扫描下面二维码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动详情Alluxio:未来是数据的时代,数据的高效管理、存储 w397090770 6年前 (2018-10-17) 1308℃ 0评论1喜欢
我们在开发过程中,难免会进行一些误操作,比如下面我们提交 723cc1e commit 的时候把 2b27deb 和 0ff665e 不小心也提交到这个分支了。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据0ff665e 是属于其他还没有合并到 master 分支的 MR,所以我们这里肯定不能把它带上来。我们需要把它删了。值得 w397090770 3年前 (2021-07-09) 581℃ 0评论1喜欢
本书于2017-08由 Packt 出版,作者 Manish Kumar, Chanchal Singh,全书269页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Learn the basics of Apache Kafka from scratchUse the basic building blocks of a streaming applicationDesign effective streaming applications with Kafka using Spark, Storm &, and HeronUnderstand the i zz~~ 7年前 (2017-11-08) 6643℃ 0评论31喜欢
Elasticsearch 5.0.0在2016年10月26日发布,该版本基于Lucene 6.2.0,这是最新的稳定版本,并且已经在Elastic Cloud上完成了部署。Elasticsearch 5.0.0是目前最快、最安全、最具弹性、最易用的版本,此版本带来了一系列的新功能和性能优化。ElasticSearch 5.0.0 release Note点击下载ElasticSearch 5.0.0阅读最新文档如果想及时了解Spark、Hadoop或者Hbase w397090770 8年前 (2016-11-02) 4953℃ 0评论10喜欢
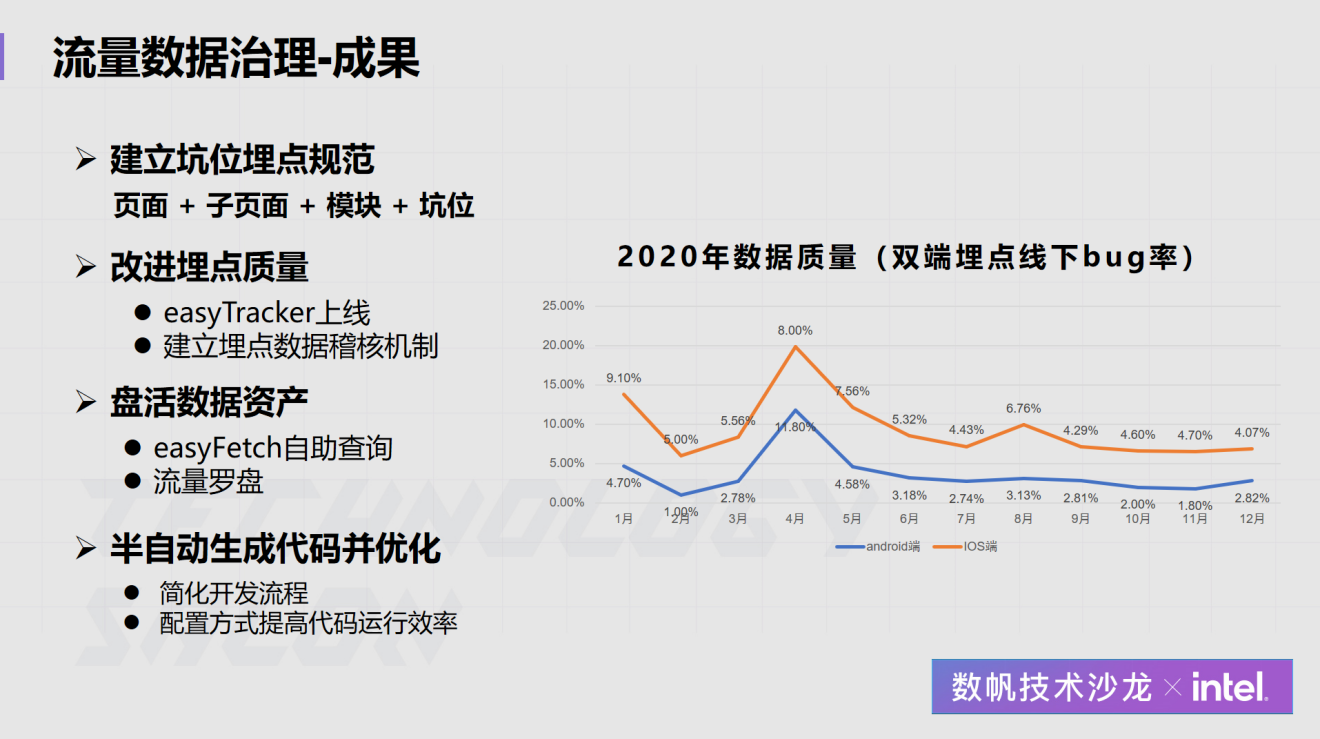
网易云音乐作为一个MAU已经超过亿级的业务,在数据仓库、数据体系、数据应用建设是怎么做的?在近日举办的“网易数帆技术沙龙”上,网易云音乐数据专家雷剑波就此话题做了全面的分享,介绍了数仓建设的目标,为此建立的一系列规范和机制,如何通过系统保证这些规范和机制的落地,以及取得的效果。数仓建设痛点与目 w397090770 3年前 (2021-06-30) 975℃ 0评论1喜欢
目前,Apache Kafka 使用 Apache ZooKeeper 来存储它的元数据,比如分区的位置和主题的配置等数据就是存储在 ZooKeeper 集群中。在 2019 年社区提出了一个计划,以打破这种依赖关系,并将元数据管理引入 Kafka 本身。所以 Apache Kafka 为什么要移除 Zookeeper 的依赖?Zookeeper 有什么问题?实际上,问题不在于 ZooKeeper 本身,而在于外部元数据 w397090770 4年前 (2020-05-19) 1384℃ 0评论1喜欢
Starburst provides connectors to the most popular data sources included in many of these connectors are a number of exclusive enhancements. Many of Starburst’s connectors when compared with open source Trino have enhanced extensions such as parallelism, pushdown and table statistics, that drastically improve the overall performance. Parallelism distributes query processing across workers, and uses many connections to the data source a w397090770 2年前 (2022-04-15) 595℃ 0评论0喜欢
导言本文主要介绍如何快速的通过Spark访问 Iceberg table。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopSpark通过DataSource和DataFrame API访问Iceberg table,或者进行Catalog相关的操作。由于Spark Data Source V2 API还在持续的演进和修改中,所以Iceberg在不同的Spark版本中的使用方式有所不同。版本对比 w397090770 4年前 (2020-06-10) 9992℃ 0评论4喜欢








![Spark Summit East 2016 PPT免费下载[共65个]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/5.jpg)



![[电子书]Building Data Streaming Applications with Apache Kafka PDF下载](https://www.iteblog.com/pic/books/building-data-streaming-applications-apache-kafka-iteblog.png)