基本格式f1 f2 f3 f4 f5 program分 时 日 月 周 命令 第1列表示分钟1~59每分钟用*或者 */1表示;第2列表示小时1~23(0表示0点);第3列表示日期1~31;第4列表示月份1~12;第5列标识号星期0~6(0表示星期天);第6列要运行的命令 当 f1 为 * 时表示每分钟都要执行 program,f2 为* 时表示每小时都要执行程序, w397090770 10年前 (2015-02-22) 3925℃ 0评论7喜欢
本文详细地介绍了如何将Hadoop上的Mapreduce程序转换成Spark的应用程序。有兴趣的可以参考一下:The key to getting the most out of Spark is to understand the differences between its RDD API and the original Mapper and Reducer API.Venerable MapReduce has been Apache Hadoop‘s work-horse computation paradigm since its inception. It is ideal for the kinds of work for which Hadoop was originally des w397090770 10年前 (2014-09-07) 6441℃ 1评论9喜欢
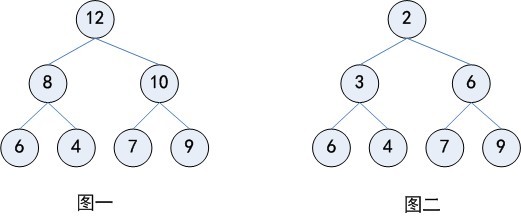
堆常用来实现优先队列,在这种队列中,待删除的元素为优先级最高(最低)的那个。在任何时候,任意优先元素都是可以插入到队列中去的,是计算机科学中一类特殊的数据结构的统称一、堆的定义最大(最小)堆是一棵每一个节点的键值都不小于(大于)其孩子(如果存在)的键值的树。大顶堆是一棵完全二叉树,同时也是 w397090770 12年前 (2013-04-01) 4882℃ 0评论3喜欢
Fedora安装完毕之后最头疼的问题就是软件更新,因为Fedora默认的更新源服务器是在国外,所以每次更新的速度奇慢!那么,我们是否可以修改Fedora的默认下载源呢?答案是可以的。目前国内有很多大学都提供了Fedora的更新包下载服务器,下载速度相对国外的快。下面以华中科技大学的源(http://mirrors.ustc.edu.cn/)为例(只能用在Fedora15、1 w397090770 12年前 (2013-04-02) 8827℃ 0评论0喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章中简单地介绍了Spark 2.0带来的新技术等。Spark 2.0是Apache Spark的下一个主要版本。此版本在架构抽象、API以及平台的类库方面带来了很大的变化,为该框架明年的发展方向奠定了方向,所以了解Spark 2.0的一些特性对我们能够使用它有着非常重要的作用。本博客将对Spark 2.0进行一 w397090770 9年前 (2016-05-24) 13079℃ 0评论26喜欢
Apache HBase 1.2.1 于2016-04-12正式发布了,HBase 1.2.1是HBase 1.2.z版本线上的第一个维护版本,该版本的主题仍然是为Hadoop和NoSQL社区带来稳定和可靠的数据库。此版本在1.2.0版本上解决了27个issues。主要的Bug修改* [HBASE-15441] - Fix WAL splitting when region has moved multiple times* [HBASE-15219] - Canary tool does not return non-zero exit code when w397090770 9年前 (2016-04-14) 3133℃ 0评论2喜欢
背景熟悉 Spark 的同学都知道,Spark 作业启动的时候我们需要指定 Exectuor 的个数以及内存、CPU 等信息。但是在 Spark 作业运行的时候,里面可能包含很多个 Stages,这些不同的 Stage 需要的资源可能不一样,由于目前 Spark 的设计,我们无法对每个 Stage 进行细粒度的资源设置。而且即使是一个资深的工程师也很难准确的预估一个比较 w397090770 5年前 (2020-01-10) 1497℃ 0评论2喜欢
如果你想知道Spark作业运行日志,可以查看这里《Spark应用程序运行的日志存在哪里》 Hadoop的日志有很多种,很多初学者往往遇到错而不知道怎么办,其实这时候就应该去看看日志里面的输出,这样往往可以定位到错误。Hadoop的日志大致可以分为两类:(1)、Hadoop系统服务输出的日志;(2)、Mapreduce程序输出来的日志 w397090770 11年前 (2014-03-14) 53033℃ 5评论40喜欢
2019年4月25日,微软的 Rahul Potharaju、Terry Kim 以及 Tyson Condie 在 Spark + AI Summit 2019 会议上为我们带来主题为 《Introducing .NET Bindings for Apache Spark 》的分享,并宣布 .NET for Apache Spark 预览版正式发布。.NET 框架是由微软开发,一个致力于敏捷软件开发、快速应用开发、平台无关性和网络透明化的免费软件框架,用于构建许多不同类型的 w397090770 6年前 (2019-04-28) 15580℃ 0评论4喜欢
Spark Release 1.0.2于2014年8月5日发布,Spark 1.0.2 is a maintenance release with bug fixes. This release is based on the branch-1.0 maintenance branch of Spark. We recommend all 1.0.x users to upgrade to this stable release. Contributions to this release came from 30 developers.如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopYou can download Spark 1.0.2 as w397090770 10年前 (2014-08-06) 5823℃ 2评论4喜欢
本文来自 submarine 团队投稿。作者: Wangda Tan & Sunil Govindan & Zhankun Tang(这篇博文由网易的刘勋和周全协助编写)。原文地址:https://hortonworks.com/blog/submarine-running-deep-learning-workloads-apache-hadoop/介绍Hadoop 是用于大型企业数据集的分布式处理的最流行的开源框架,它在本地和云端环境中都有很多重要用途。深度学习对于语 w397090770 6年前 (2019-01-01) 4048℃ 0评论4喜欢
NVIDIA (辉达) 于2020年5月15日宣布将与开源社群携手合作,将端到端的 GPU 加速技术导入 Apache Spark 3.0。全球超过五十万名资料科学家使用 Apache Spark 3.0 分析引擎处理大数据资料。透过预计于今年春末正式发表的 Spark 3.0,资料科学家与机器学习工程师将能首次把革命性的 GPU 加速技术应用于 ETL (撷取、转换、载入) 资料处理作业负载 w397090770 5年前 (2020-05-15) 744℃ 0评论2喜欢
我博客服务器使用的OpenSSL是1.0.1e版本,之所以需要升级到OpenSSL 1.0.1t版本是因为1.0.1t版本以下存在一个严重的Bug:Padding oracle in AES-NI CBC MAC check (CVE-2016-2107),我们可以到这里查看我们的网站是否有这个问题。官方对这个漏洞的描述是:[code lang="bash"]Padding oracle in AES-NI CBC MAC check (CVE-2016-2107)=============================================== w397090770 8年前 (2016-08-06) 2881℃ 0评论3喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopApache Iceberg 是一种用于跟踪超大规模表的新格式,是专门为对象存储(如S3)而设计的。 本文将介绍为什么 Netflix 需要构建 Iceberg,Apache Iceberg 的高层次设计,并会介绍那些能够更好地解决查询性能问题的细节。如果想及时了解Spark、Hadoop或者HBase w397090770 5年前 (2020-02-23) 3000℃ 0评论6喜欢
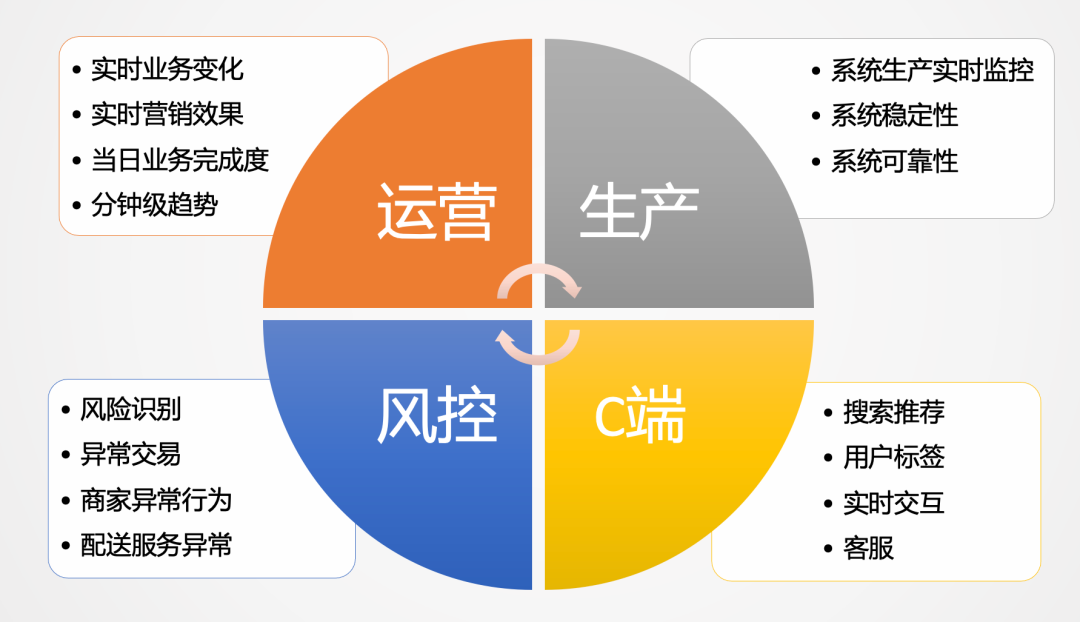
本文主要介绍一种通用的实时数仓构建的方法与实践。实时数仓以端到端低延迟、SQL标准化、快速响应变化、数据统一为目标。美团外卖数据智能组总结的最佳实践是:一个通用的实时生产平台跟一个通用交互式实时分析引擎相互配合,同时满足实时和准实时业务场景。两者合理分工,互相补充,形成易开发、易维护且效率高的流 zz~~ 3年前 (2021-09-24) 582℃ 0评论2喜欢
一、 问答题1、简单描述如何安装配置一个apache开源版hadoop,只描述即可,无需列出完整步骤,能列出步骤更好。1) 安装JDK并配置环境变量(/etc/profile)2) 关闭防火墙3) 配置hosts文件,方便hadoop通过主机名访问(/etc/hosts)4) 设置ssh免密码登录5) 解压缩hadoop安装包,并配置环境变量6) 修改配置文件($HADOOP_HOME/conf)hadoop-e w397090770 8年前 (2016-08-26) 7951℃ 0评论14喜欢
Apache Hadoop 2.7.1于美国时间2015年07月06日正式发布,本版本属于稳定版本,是自Hadoop 2.6.0以来又一个稳定版,同时也是Hadoop 2.7.x版本线的第一个稳定版本,也是 2.7版本线的维护版本,变化不大,主要是修复了一些比较严重的Bug(其中修复了131个Bugs和patches)。比较重要的特性请参见《Hadoop 2.7.0发布:不适用于生产和不支持JDK1.6》 w397090770 9年前 (2015-07-08) 17884℃ 0评论23喜欢
关于 Apache Spark 2.2.0 的详细新功能介绍请参见:《Apache Spark 2.2.0新特性详细介绍》Apache Spark 2.2.0 持续了半年的开发,从RC1 到 RC6 终于在今天正式发布了。本版本是 2.x 版本线的第三个版本。在这个版本 Structured Streaming 的实验性标记(experimental tag)已经被移除,这也意味着后面的 2.2.x 之后就可以放心在线上使用了。除此之外,这 w397090770 7年前 (2017-07-12) 2844℃ 0评论8喜欢
本文已经不再更新,谢谢支持。本页面长期更新最新 Google、谷歌学术、维基百科、ccFox.info、ProjectH、3DM、Battle.NET 、WordPress、Microsoft Live、GitHub、Box.com、SoundCloud、inoreader、Feedly、FlipBoard、Twitter、Facebook、Flickr、imgur、DuckDuckGo、Ixquick、Google Services、Google apis、Android、Youtube、Google Drive、UpLoad、Appspot、Googl eusercontent、Gstatic、Google othe w397090770 5年前 (2019-11-19) 1147℃ 0评论3喜欢
这里的方法貌似没有用,请参见本博客最新博文《CentOS 6.4安装谷歌浏览器(Chrome)》可以解决这个问题。 Google Chrome,又称Google浏览器,是一个由Google(谷歌)公司开发的开放原始码网页浏览器。如何在Cent OS里面安装Chrome呢?步骤如下: 第一步:打开终端,输入下面的命令[code lang="JAVA"]vim /etc/yum.repos.d/CentOS-Base.repo w397090770 11年前 (2013-08-07) 17740℃ 0评论5喜欢
本文将对 Spark 的内存管理模型进行分析,下面的分析全部是基于 Apache Spark 2.2.1 进行的。为了让下面的文章看起来不枯燥,我不打算贴出代码层面的东西。文章仅对统一内存管理模块(UnifiedMemoryManager)进行分析,如对之前的静态内存管理感兴趣,请参阅网上其他文章。我们都知道 Spark 能够有效的利用内存并进行分布式计算,其内 w397090770 7年前 (2018-04-01) 19839℃ 4评论92喜欢
本书是《Hadoop权威指南》第三版,新版新特色,内容更详细。本书是为程序员写的,可帮助他们分析任何大小的数据集。本书同时也是为管理员写的,帮助他们了解如何设置和运行Hadoop集群。 本书通过丰富的案例学习来解释Hadoop的幕后机理,阐述了Hadoop如何解决现实生活中的具体问题。第3版覆盖Hadoop的新动态,包括新增 zz~~ 8年前 (2016-12-16) 17291℃ 0评论43喜欢
一、前言本文主要介绍了 Presto 的简单原理,以及 Presto 在有赞的实践之路。二、Presto 介绍Presto 是由 Facebook 开发的开源大数据分布式高性能 SQL 查询引擎。起初,Facebook 使用 Hive 来进行交互式查询分析,但 Hive 是基于 MapReduce 为批处理而设计的,延时很高,满足不了用户对于交互式查询想要快速出结果的场景。为了解决 Hive w397090770 4年前 (2020-12-21) 816℃ 0评论2喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop回望过去10年,数据技术发展迅速,数据也在呈现爆炸式的增长,这也伴随着如下两个现象。一、数据更加分散:企业的数据是散落在不同的数据存储之中,如对象存储OSS,OLTP的MySQL,NoSQL的Mongo及HBase,以及数据仓库ADB之中,甚至是以服务的形式 w397090770 5年前 (2020-01-07) 1195℃ 0评论3喜欢
社区在Spark 1.3中开始引入了DataFrames,使得Apache Spark更加容易被使用。受R和Python中的data frames激发,Spark中的DataFrames提供了一些API,这些API在外部看起来像是操作单机的数据一样,而数据科学家对这些API非常地熟悉。统计是日常数据科学的一个重要组成部分。在即将发布的Spark 1.4中改进支持统计函数和数学函数(statistical and mathem w397090770 10年前 (2015-06-03) 14003℃ 2评论3喜欢
本书书名全名:Learning Spark Streaming:Best Practices for Scaling and Optimizing Apache Spark,于2017-06由 O'Reilly Media出版,作者 Francois Garillot, Gerard Maas,全书300页。本文提供的是本书的预览版。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Understand how Spark Streaming fits in the big pictureLearn c zz~~ 7年前 (2017-10-18) 6477℃ 0评论21喜欢
1、自动向 WordPress 编辑器插入文本 编辑当前主题目录的 functions.php 文件,并粘贴以下代码: [code lang="php"]< ?php add_filter( 'default_content', 'my_editor_content' ); function my_editor_content( $content ) { $content = "过往记忆,专注于Hadoop、Spark等"; return $content; } ?> [/code]2、获取 WordPress 注册用户数量 通过简单的 SQL 语句, w397090770 10年前 (2014-10-12) 2643℃ 0评论3喜欢
Facebook Spark 的使用情况在介绍下面文章之前我们来看看 Facebook 的 Spark 使用情况:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopSpark 是 Facebook 内部最大的 SQL 查询引擎(按 CPU 使用率计算)在存储计算分 w397090770 4年前 (2020-06-14) 1579℃ 0评论6喜欢
快速管理和访问 PB 级数据的能力对于整个数据生态系统的可伸缩增长是至关重要的。尽管如此,这种对规模和速度的综合需求并不总是自然地适合现有的批处理和流系统架构。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopHudi 于 2016 年以“Hoodie”为代号开发,旨在解决 Uber 大数据生态系统 w397090770 6年前 (2019-04-20) 939℃ 0评论1喜欢
题目描述:将一个长度超过100位数字的十进制非负整数转换为二进制数输出。输入:多组数据,每行为一个长度不超过30位的十进制非负整数。(注意是10进制数字的个数可能有30个,而非30bits的整数)输出:每行输出对应的二进制数。样例输入:0138样例输出:01111000分析:这个数不应该存储到一个int类型变量里面去 w397090770 12年前 (2013-04-03) 5956℃ 0评论5喜欢















![[电子书]Hadoop权威指南第3版中文版PDF下载](https://www.iteblog.com/pic/Hadoop_the_definitive_guide_Third_Edition.jpg)



![[电子书]Learning Spark Streaming PDF下载](https://www.iteblog.com/pic/books/Learning_Spark_Streaming_iteblog.jpg)

