我们在 Apache Spark DataSource V2 介绍及入门编程指南(上) 文章中介绍了 Apache Spark DataSource V1 的不足,所以才有了 Data Source API V2 的诞生。Data Source API V2为了解决 Data Source V1 的一些问题,从 Apache Spark 2.3.0 版本开始,社区引入了 Data Source API V2,在保留原有的功能之外,还解决了 Data Source API V1 存在的一些问题,比如不再依赖上层 API w397090770 5年前 (2019-08-13) 3810℃ 1评论9喜欢
R目前,越来越多的用户开始在 Presto 里面使用 Alluxio,它通过利用 SSD 或内存在 Presto workers 上缓存热数据集,避免从远程存储读取数据。 Presto 支持基于哈希的软亲和调度(hash-based soft affinity scheduling),强制在整个集群中只缓存一到两份相同的数据,通过允许本地缓存更多的热数据来提高缓存效率。 但是,当前使用的哈希算法在集 w397090770 3年前 (2022-04-01) 443℃ 0评论1喜欢
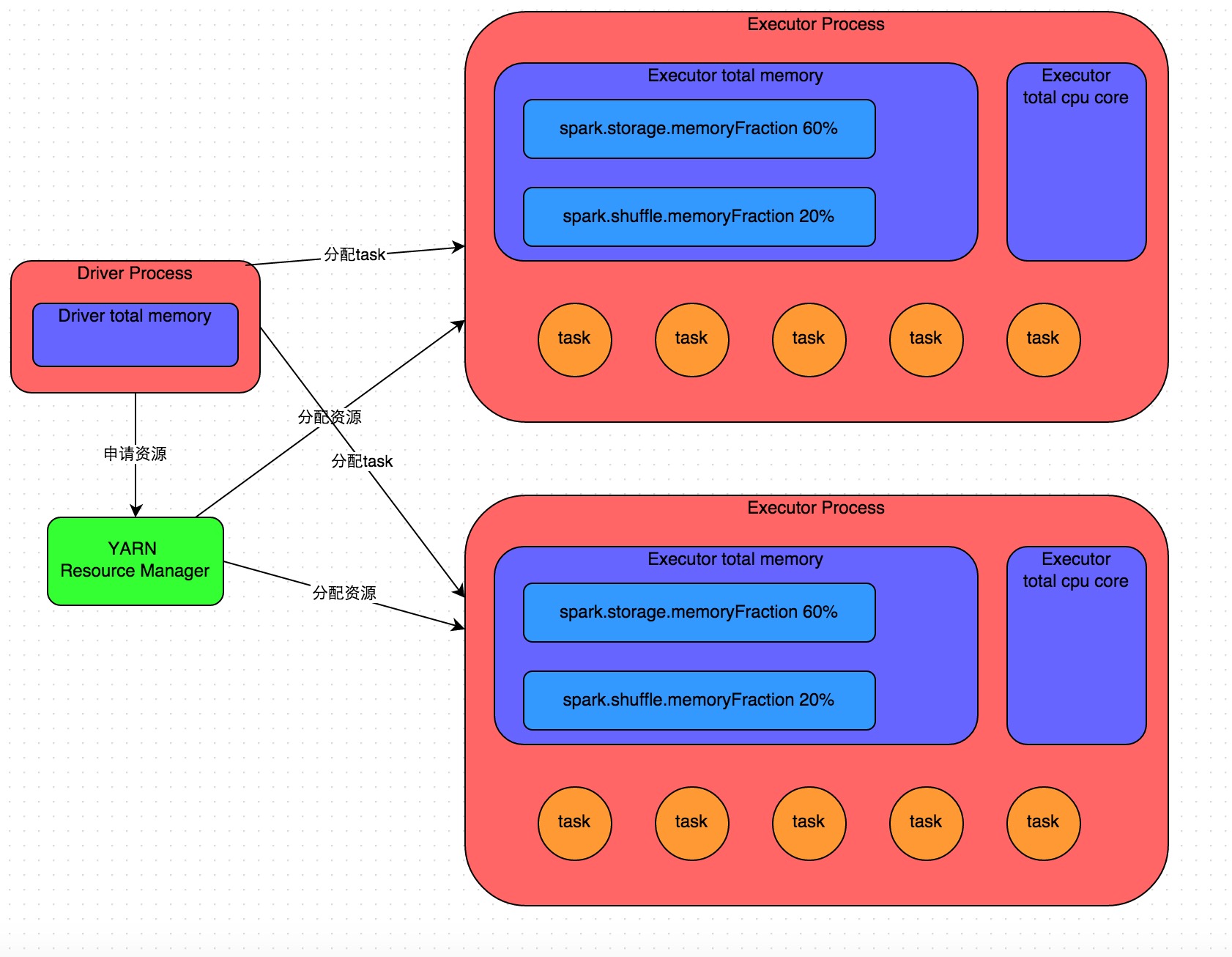
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在开发完Spark作业之后,就该为作业配置合适的资源了。Spark的资源参数,基本都可以在spark-submit命令中作为参数设置。很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置这些参 w397090770 9年前 (2016-05-04) 30886℃ 8评论38喜欢
背景熟悉 Spark 的同学都知道,Spark 作业启动的时候我们需要指定 Exectuor 的个数以及内存、CPU 等信息。但是在 Spark 作业运行的时候,里面可能包含很多个 Stages,这些不同的 Stage 需要的资源可能不一样,由于目前 Spark 的设计,我们无法对每个 Stage 进行细粒度的资源设置。而且即使是一个资深的工程师也很难准确的预估一个比较 w397090770 5年前 (2020-01-10) 1476℃ 0评论2喜欢
在本博客的《Spark快速入门指南(Quick Start Spark)》文章中简单地介绍了如何通过Spark shell来快速地运用API。本文将介绍如何快速地利用Spark提供的API开发Standalone模式的应用程序。Spark支持三种程序语言的开发:Scala (利用SBT进行编译), Java (利用Maven进行编译)以及Python。下面我将分别用Scala、Java和Python开发同样功能的程序:一、Scala w397090770 10年前 (2014-06-10) 16435℃ 2评论7喜欢
国内区 Apple ID 转美国区的教程参见:2021年最新中国区 Apple ID 转美国区教程注意:下面的操作步骤是在2021年10月29日进行的,过程中都没有使用到 VPN 软件。使用苹果手机的有可能知道,国内使用的 App Store 只能下载国内的一些 APP 应用。有一些 APP 并没有在国内 App Store 上架,这时候就无法下载。我们需要使用一个国外的 Apple I w397090770 3年前 (2021-10-22) 4246℃ 0评论7喜欢
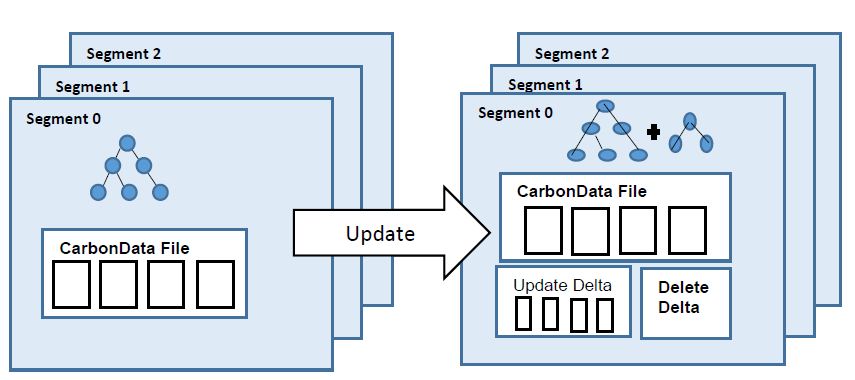
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。 当前,CarbonData暂不支持修改表中已经存在的数据。但是在现实情况下,我们可能很希望这个功能,比如修改 w397090770 8年前 (2016-11-30) 2808℃ 0评论10喜欢
有时候我们想对来自不同平台对同一页面的访问进行处理。比如访问 https://www.iteblog.com/test.html 页面,如果是电脑的浏览器访问,直接不处理;但是如果是手机的浏览器访问这个页面我们想跳转到其他页面去。这时候有几种方法可以实现:直接通过 JavaScript 进行处理;通过 Nginx 配置来处理如果想及时了解Spark、Hadoop或者Hbase w397090770 7年前 (2017-12-16) 1791℃ 0评论13喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》本博客收集到的Hadoop学习书籍分享地 w397090770 11年前 (2014-02-14) 202547℃ 5评论421喜欢
本次的分享内容分成四个部分: 1.汽车之家离线计算平台现状2.平台构建过程中遇到的问题3.基于构建过程中问题的解决方案4.离线计算平台未来规划 汽车之家离线计算平台现状 1. 汽车之家离线计算平台发展历程如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据 2013年的时候汽 w397090770 3年前 (2021-08-30) 571℃ 0评论4喜欢
昨天分享了《[电子书]Apache Spark 2 for Beginners pdf下载》,这本书很适合入门学习Spark,虽然书名上写着是Apache Spark 2,但是其内容介绍几乎和Spark 2毫无关系,今天要分享的图书也是一本适合入门的Spark电子书,也是Packt出版,2016年09月开始发行的,全书共339页,其面向读者是数据科学家,本书内容涵盖了Spark编程模型、DataFrame介绍 w397090770 8年前 (2016-10-24) 5071℃ 0评论13喜欢
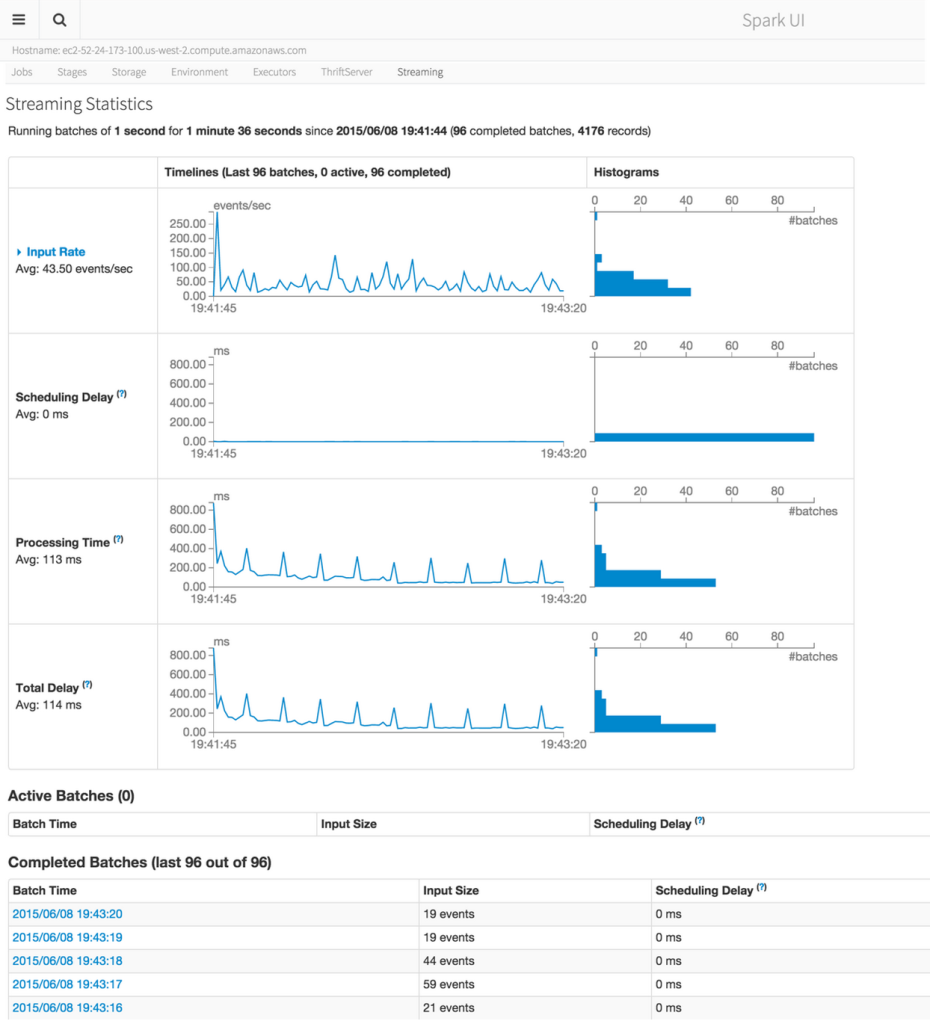
早上时间匆忙,我将于晚点时间详细地介绍Spark 1.4的更新,请关注本博客。 Apache Spark 1.4.0的新特性可以看这里《Apache Spark 1.4.0新特性详解》。 Apache Spark 1.4.0于美国时间的2015年6月11日正式发布。Python 3支持,R API,window functions,ORC,DataFrame的统计分析功能,更好的执行解析界面,再加上机器学习管道从alpha毕业成 w397090770 9年前 (2015-06-12) 4712℃ 0评论11喜欢
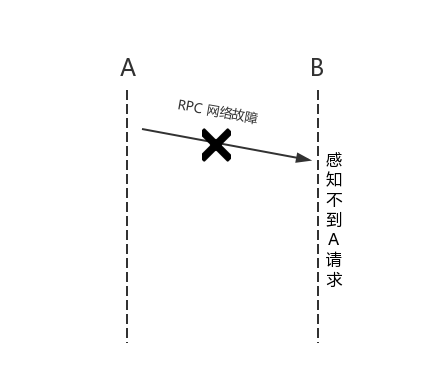
在传统的单机系统中,我们调用一个函数,这个函数要么返回成功,要么返回失败,其结果是确定的。可以概括为传统的单机系统调用只存在两态(2-state system):成功和失败。然而在分布式系统中,由于系统是分布在不同的机器上,系统之间的请求就相对于单机模式来说复杂度较高了。具体的,节点 A 上的系统通过 RPC (Remote Proc w397090770 7年前 (2018-04-20) 2504℃ 0评论9喜欢
本文转载至 http://www.ibm.com/developerworks/cn/java/j-dcl.html 单例创建模式是一个通用的编程习语。和多线程一起使用时,必需使用某种类型的同步。在努力创建更有效的代码时,Java 程序员们创建了双重检查锁定习语,将其和单例创建模式一起使用,从而限制同步代码量。然而,由于一些不太常见的 Java 内存模型细节的原因,并不能 w397090770 11年前 (2013-10-18) 4653℃ 4评论6喜欢
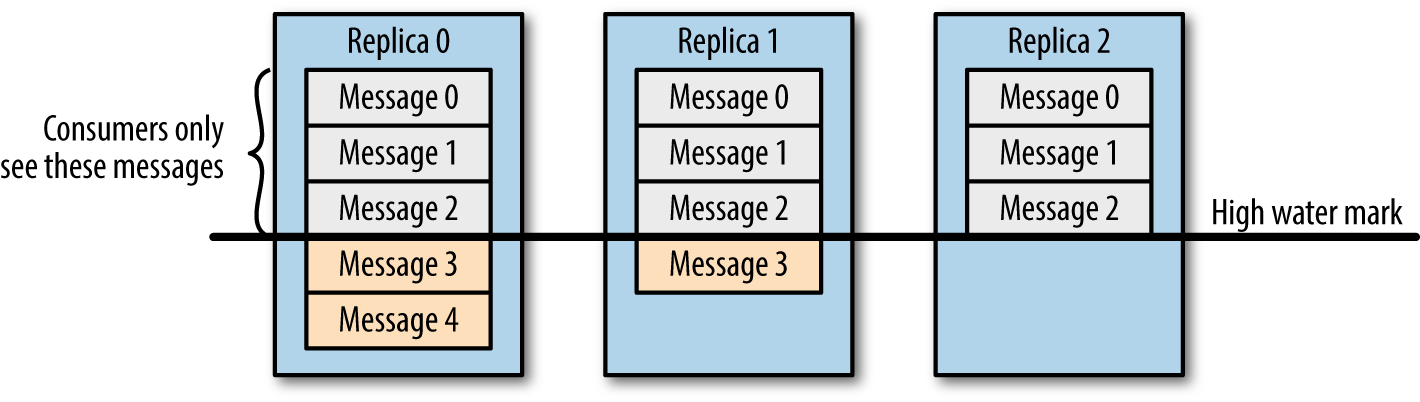
学过大数据的同学应该都知道 Kafka,它是分布式消息订阅系统,有非常好的横向扩展性,可实时存储海量数据,是流数据处理中间件的事实标准。本文将介绍 Kafka 是如何保证数据可靠性和一致性的。数据可靠性Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知。本文从 Producter 往 Broker 发送消息、Topic 分区副本以及 w397090770 5年前 (2019-06-11) 12821℃ 2评论42喜欢
在Linux C网络编程中,一共有两种方法来关闭一个已经连接好的网络通信,它们就是close函数和shutdown函数,它们的函数原型分别为:[code lang="CPP"]#include<unistd.h>int close(int sockfd)//返回:0——成功, 1——失败#include<sys/socket.h>int shutdown(int sockfd, int howto)//返回:0——成功, 1——失败[/code]close函数和shutdown函数 w397090770 12年前 (2013-04-04) 5562℃ 0评论2喜欢
到目前为止,Scala 环境下至少存在6种 Json 解析的类库,这里面不包括 Java 语言实现的 Json 类库。所有这些库都有一个非常相似的抽象语法树(AST)。而 json4s 项目旨在提供一个单一的 AST 树供其他 Scala 类库来使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopjson4s 的使用非常的简单,它可以将 w397090770 6年前 (2018-11-15) 1108℃ 0评论4喜欢
我们在编写Spark Application或者是阅读源码的时候,我们很想知道代码的运行情况,比如参数设置的是否正确等等。用Logging方式来调试是一个可以选择的方式,但是,logging方式调试代码有很多的局限和不便。今天我就来介绍如何通过IDE来远程调试Spark的Application或者是Spark的源码。本文以调试Spark Application为例进行说明,本文用到的I w397090770 10年前 (2014-11-05) 23970℃ 16评论21喜欢
本文来自于2018年10月20日由中国 HBase 技术社区在武汉举办的中国 HBase Meetup 第六次线下交流会。分享者为过往记忆。本文 PPT 下载 请关注 iteblog_hadoop 微信公众号,并回复 HBase 获取。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoop本次分享的内容主要分为以下五点:HBase基本知识;HBase读 w397090770 6年前 (2018-10-25) 6344℃ 0评论23喜欢
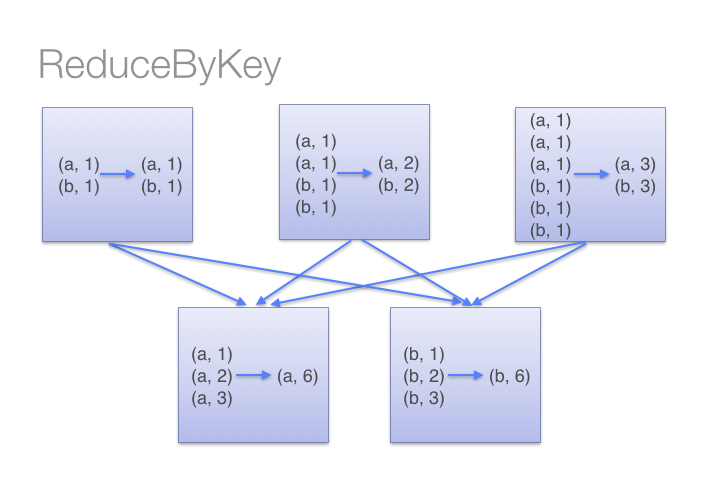
为什么建议尽量在Spark中少用GroupByKey,让我们看一下使用两种不同的方式去计算单词的个数,第一种方式使用 reduceByKey ;另外一种方式使用groupByKey,代码如下:[code lang="scala"]# User: 过往记忆# Date: 2015-05-18# Time: 下午22:26# bolg: # 本文地址:/archives/1357# 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量 w397090770 9年前 (2015-05-18) 33468℃ 0评论51喜欢
由于Spark基于内存计算的特性,集群的任何资源都可以成为Spark程序的瓶颈:CPU,网络带宽,或者内存。通常,如果内存容得下数据,瓶颈会是网络带宽。不过有时你同样需要做些优化,例如将RDD以序列化到磁盘,来降低内存占用。这个教程会涵盖两个主要话题:数据序列化,它对网络性能尤其重要并可以减少内存使用,以及内存调优 w397090770 6年前 (2019-02-20) 3198℃ 0评论8喜欢
《Spark Streaming作业提交源码分析接收数据篇》、《Spark Streaming作业提交源码分析数据处理篇》 最近一段时间在使用Spark Streaming,里面遇到很多问题,只知道参照官方文档写,不理解其中的原理,于是抽了一点时间研究了一下Spark Streaming作业提交的全过程,包括从外部数据源接收数据,分块,拆分Job,提交作业全过程。 w397090770 10年前 (2015-04-28) 9194℃ 2评论9喜欢
CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号。在本文中的CSV格式的数据就不是简单的逗号分割的),其文件以纯文本形式存储表格数据(数字和文本)。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字 w397090770 10年前 (2015-01-26) 9643℃ 0评论12喜欢
为什么要升级在2017年底, Hadoop3.0 发布了,到目前为止, Hadoop 发布的最新版本为3.2.1。在 Hadoop3 中有很多有用的新特性出现,如支持 ErasureCoding、多 NameNode、Standby NameNode read、DataNode Disk Balance、HDFS RBF 等等。除此之外,还有很多性能优化以及 BUG 修复。其中最吸引我们的就是 ErasureCoding 特性,数据可靠性保持不变的情况下可以降 w397090770 5年前 (2020-01-05) 2574℃ 0评论11喜欢
今天早上我在博文里面更新了Spark 1.4.0正式发布,由于时间比较匆忙(要上班啊),所以在那篇文章里面只是简单地介绍了一下Spark 1.4.0,本文详细将详细地介绍Spark 1.4.0特性。如果你想尽早了解Spark等相关大数据消息,请关注本博客,或者本博客微信公共帐号iteblog_hadoop。 Apache Spark 1.4.0版本于美国时间2015年06月11日正式发 w397090770 9年前 (2015-06-12) 5044℃ 1评论1喜欢
Spark 1.1.0中兼容大部分Hive特性,我们可以在Spark中使用Hive。但是默认的Spark发行版本并没有将Hive相关的依赖打包进spark-assembly-1.1.0-hadoop2.2.0.jar文件中,官方对此的说明是:Spark SQL also supports reading and writing data stored in Apache Hive. However, since Hive has a large number of dependencies, it is not included in the default Spark assembly 所以,如果你直 w397090770 10年前 (2014-09-26) 12834℃ 5评论9喜欢
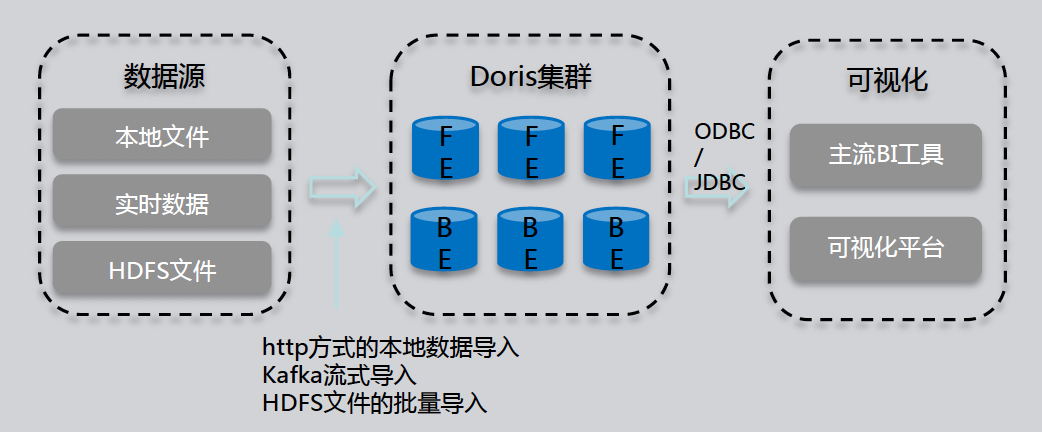
Apache Doris 简介Doris(原百度 Palo)是一款基于大规模并行处理技术的分布式 SQL 数据库,由百度在 2017 年开源,2018 年 8 月进入 Apache 孵化器。本次将主要从以下三部分介绍 Apache Doris.Doris 定位:即 Doris 所要面临的业务场景及解决的问题Doris 关键技术Doris 案例介绍01 Doris 定位实时数据仓库 Doris产品定位我们首先看一下 w397090770 5年前 (2019-12-11) 2942℃ 0评论4喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 今天我很激动地宣布Spark 1.1.0发布了,Spark 1.1.0引入了许多新特征(new features)包括了可扩展性和稳定性方面的提升。这篇文章主要是介绍了Spark 1.1.0主要的特性,下面的介绍主要是根据各个特征重要性的优先级进行说明的。在接下来的两个星 w397090770 10年前 (2014-09-12) 4691℃ 2评论8喜欢
默认情况下,nginx将每天网站访问的日志都写在一个文件里面,随着时间的推移,这个文件势必越来越大,最终成为问题。不过我们可以写个脚本来自动地按天(或者小时)切割日志,并压缩(节约磁盘空间)。 脚本的内容如下:[code lang="bash"]#!/bin/bash logspath="/alidata/log/Nginx/access/"yesterday=`date -d '-1 day' +%Y%m%d`mv ${lo w397090770 10年前 (2015-01-02) 15873℃ 0评论10喜欢
2017年04月25日发布的nginx 1.13.0支持了TLSv1.3,而TLSv1.3相比之前的TLSv1.2、TLSv1.1等性能大幅提升。所以我迫不及待地将nginx升级到最新版1.13.0。下面记录如何升级nginx,本文基于CentOS release 6.6,其他的操作系统略有不同。如果你不知道你的系统是啥版本,可以通过下面的几个命令查询[code lang="bash"][root@iteblog.com ~]$ cat /etc/issueCentOS w397090770 7年前 (2017-05-23) 12338℃ 2评论10喜欢




![传智播客Hadoop课程视频资料[共七天]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/9.jpg)

![[电子书]Spark for Data Science PDF下载](https://www.iteblog.com/pic/books/spark_for_data_science_iteblog.JPG)