我们使用数据库可以快速访问业务数据,但是随着时间的推移,数据库会不断增长,提取信息所需的时间也会更长,数据操作成为瓶颈。这时候我们就需要对数据进行分区(partition)了。分区是将数据库或其组成元素划分为不同的独立部分。数据库分区通常是出于可管理性、性能或可用性或负载平衡的原因而进行的。在分布式数据 w397090770 4年前 (2020-05-14) 1074℃ 0评论2喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 125.117.130.174 9000 高匿名 HTTP w397090770 9年前 (2015-05-13) 46383℃ 0评论0喜欢
本文英文原文:https://hudi.apache.org/releases.html下载信息源码:Apache Hudi 0.6.0 Source Release (asc, sha512)二进制Jar包:nexus如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop2. 迁移指南如果您从0.5.3以前的版本迁移至0.6.0,请仔细核对每个版本的迁移指南;0.6.0版本从基于list的rollback策略变更为 w397090770 4年前 (2020-09-02) 879℃ 0评论0喜欢
Spark SQL也是可以直接部署在当前的Hive wareHouse。 Spark SQL 1.1.0的 Thrift JDBC server 被设计成兼容当前的Hive数据仓库。你不需要修改你的Hive元数据,或者是改变表的数据存放目录以及分区。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 以下列出来的是当前Spark SQL(1.1.0)对Hive特性的 w397090770 10年前 (2014-09-11) 9410℃ 1评论8喜欢
《Apache Kafka消息格式的演变(0.7.x~0.10.x)》《图解Apache Kafka消息偏移量的演变(0.7.x~0.10.x)》《Kafka消息时间戳及压缩消息对时间戳的处理》本博客的《Apache Kafka消息格式的演变(0.7.x~0.10.x)》文章中介绍了 Kafka 各个版本的格式变化。其中 Kafka 0.10.x 消息的一大变化是引入了消息时间戳的字段。本文将介绍 Kafka 消息引入时间戳的必要性 w397090770 7年前 (2017-09-01) 7535℃ 0评论23喜欢
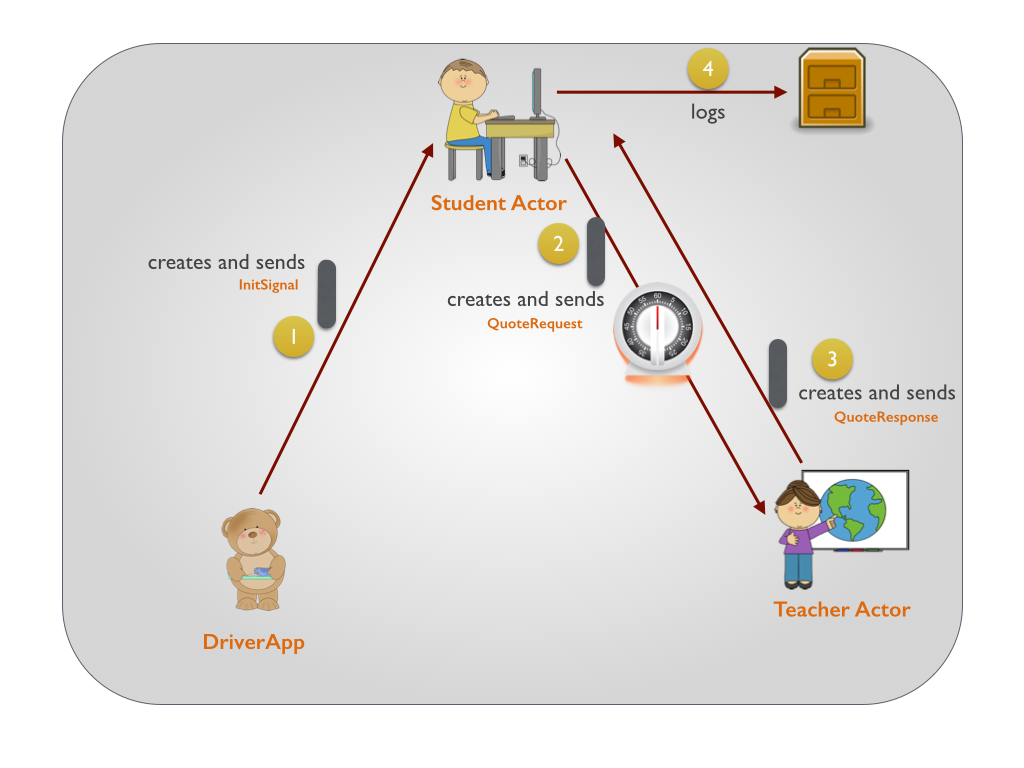
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-22) 19202℃ 3评论14喜欢
来自于requests的灵感,因为它很简单;并且由lxml驱动,因为它速度很快。 Newspaper是一个惊人的新闻、全文以及文章元数据抽取开源的Python类库,这个类库支持10多种语言,所有的东西都是用unicode编码的。我们可以使用下面命令查看:[code lang="python"]/** * User: 过往记忆 * Date: 2015-05-20 * Time: 下午23:14 * bolg: * 本文地 w397090770 9年前 (2015-05-20) 2748℃ 0评论0喜欢
题目:有一堆石头质量分别为W1,W2,W3...WN.(W<=100000)现在需要你将石头合并为两堆,使两堆质量的差为最小。这道题目可以用01背包问题来解决。即求出和最接近sum/2的一个子集 令f(i, j)表示前i个元素中和最接近j的子集的和(有点绕),则有: f(i, j) = max( f(i-1, j), f(i-1, j-a[i])+a[i] ) ,其中a数组是用来存储所有石头的质量的。源 w397090770 12年前 (2013-03-31) 3208℃ 0评论5喜欢
本文出自本公众号ChinaScala,由陈超所述。一、Spark能否取代Hadoop? 答: Hadoop包含了Common,HDFS,YARN及MapReduce,Spark从来没说要取代Hadoop,最多也就是取代掉MapReduce。事实上现在Hadoop已经发展成为一个生态系统,并且Hadoop生态系统也接受更多优秀的框架进来,如Spark (Spark可以和HDFS无缝结合,并且可以很好的跑在YARN上).。 w397090770 9年前 (2015-08-26) 7189℃ 1评论42喜欢
如果你的Driver内存容量不能容纳一个大型RDD里面的所有数据,那么不要做以下操作:[code lang="scala"]val values = iteblogVeryLargeRDD.collect()[/code] Collect 操作会试图将 RDD 里面的每一条数据复制到Driver上,如果你Driver端的内存无法装下这些数据,这时候会发生内存溢出和崩溃。 相反,你可以调用take或者 takeSample来限制数 w397090770 9年前 (2015-05-20) 3119℃ 0评论4喜欢
2019年10月22日上午 Databricks 宣布,已经完成了由安德森-霍洛维茨基金(Andreessen Horowitz)牵头的4亿美元F轮融资,参与融资的有微软(Microsoft)、Alkeon Capital Management、贝莱德(BlackRock)、Coatue Management、Dragoneer Investment Group、Geodesic、Green Bay Ventures、New Enterprise Associates、T. Rowe Price和Tiger Global Management。经过这次融资,Databricks 的估值高达62亿美 w397090770 5年前 (2019-10-22) 1119℃ 0评论0喜欢
新年伊始,上海Spark meetup第七次聚会将于2016年1月23日(周六)在上海市长宁区金钟路968号凌空SOHO 8号楼 进行。此次聚会由Intel联合携程举办,此次活动特别邀请到来自 携程,Splunk以及intel大数据的专家和大家分享Spark技术及实践经验,幸运听众还会得到一本签名版的Spark技术书籍。 大会主题 1、开场/Opening Keynote: 张翼,携 w397090770 9年前 (2016-01-16) 2756℃ 0评论3喜欢
Apache Hadoop 2.7.0发布。一共修复了来自社区的535个JIRAs,其中:Hadoop Common有160个;HDFS有192个;YARN有148个;MapReduce有35个。Hadoop 2.7.0是2015年第一个Hadoop release版本,不过需要注意的是 (1)、不要将Hadoop 2.7.0用于生产环境,因为一些关键Bug还在测试中,如果需要在生产环境使用,需要等Hadoop 2.7.1/2.7.2,这些版本很快会发布。 w397090770 10年前 (2015-04-24) 8837℃ 0评论14喜欢
在Spark中内置支持两种系列化格式:(1)、Java serialization;(2)、Kryo serialization。在默认情况下,Spark使用的是Java的ObjectOutputStream系列化框架,它支持所有继承java.io.Serializable的类系列化,虽然Java系列化非常灵活,但是它的性能不佳。然而我们可以使用Kryo 库来系列化,它相比Java serialization系列化高效,速度很快(通常比Java快1 w397090770 10年前 (2015-04-23) 14764℃ 0评论15喜欢
越来越多的公司采用流处理,并将现有的批处理应用迁移到流处理,或者对新的用例采用流处理实现的解决方案。其中许多应用集中在流数据分析上,分析的数据流来自各种源,例如数据库事务、点击、传感器测量或 IoT 设备。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Flink 非常 w397090770 7年前 (2017-07-20) 3521℃ 0评论16喜欢
Flink内置提供了将DataStream中的数据写入到ElasticSearch中的Connector(flink-connector-elasticsearch2_2.10),但是并没有提供将DateSet的数据写入到ElasticSearch。本文介绍如何通过自定义OutputFormat将Flink DateSet里面的数据写入到ElasticSearch。 如果需要将DateSet中的数据写入到外部存储系统(比如HDFS),我们可以通过writeAsText、writeAsCsv、write等内 w397090770 8年前 (2016-10-11) 5804℃ 0评论8喜欢
本文介绍了如何使用 Presto 通过 Alluxio 查询 Iceberg 表。由于这项功能目前处于试验阶段,此处提供的信息可能会发生变化,请及时参考官方文档了解最新功能。关于如何使用 Presto 读取 Iceberg 上的数据请参考这里。我们知道,在 Hive 数据源上,Presto 支持两种形式的 Alluxio 缓存:通过 Alluxio local cache 以及 Alluxio Cluster,截止到本文章 w397090770 3年前 (2021-11-18) 1228℃ 0评论6喜欢
youtube-dl是一个精悍的命令程序,它可以从YouTube.com以及其他网站上下载视频。它是使用Python开发的,依赖于Python 2.6, 2.7, 或者3.2+解释器,而且这个视频下载命令是跨平台的,作者为我们带来了Windows执行文件(https://yt-dl.org/latest/youtube-dl.exe),其中就包含了Python。youtube-dl可以在Unix box,Windows或者是 Mac OS X平台上运行,支持众多视频网 w397090770 9年前 (2016-04-09) 6668℃ 0评论6喜欢
Apache Maven,是一个软件(特别是Java软件)项目管理及自动构建工具,由Apache软件基金会所提供。基于项目对象模型(缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。曾是Jakarta项目的子项目,现为独立Apache项目。 大家肯定遇到过想在pom文件中加入自己开发的依赖包,这些包肯定是 w397090770 11年前 (2013-08-02) 39406℃ 0评论19喜欢
我目前使用的Hive版本是apache-hive-1.2.0-bin,每次在使用 show create table 语句的时候如果你字段中有中文注释,那么Hive得出来的结果如下:hive> show create table iteblog;OKCREATE TABLE `iteblog`( `id` bigint COMMENT '�id', `uid` bigint COMMENT '(7id', `name` string COMMENT '(7�')ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTF w397090770 8年前 (2016-06-08) 11284℃ 0评论13喜欢
使用MEMORY_ONLY储存级别对RDD进行缓存,其内部实现是调用persist()函数的。官方文档定义:Persist this RDD with the default storage level (`MEMORY_ONLY`).函数原型[code lang="scala"]def cache() : this.type[/code]实例[code lang="scala"]/** * User: 过往记忆 * Date: 15-03-04 * Time: 下午06:30 * bolg: * 本文地址:/archives/1274 * 过往记忆博客, w397090770 10年前 (2015-03-04) 14185℃ 0评论8喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2015-04-25) 37445℃ 8评论55喜欢
Apache Maven,是一个软件(特别是Java软件)项目管理及自动构建工具,由Apache软件基金会所提供。基于项目对象模型(缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。曾是Jakarta项目的子项目,现为独立Apache项目。 那么,如何在Linux平台下面安装Maven呢?下面以CentOS平台为例,说明如 w397090770 11年前 (2013-10-21) 32225℃ 3评论13喜欢
第一题,基础题: 1. 数据库及线程产生死锁的原理和必要条件,如何避免死锁。 2. 列举面向对象程序设计的三个要素和五项基本原则。 3.Windows内存管理的方式有哪些?各自的优缺点。第二题,算法与程序设计: 1.公司举行羽毛球比赛,采用淘汰赛,有1001个人参加,要决出“羽毛球最高选手”,应如何组织这 w397090770 12年前 (2013-04-20) 9126℃ 0评论10喜欢
在互联网网络中,当网络发生拥塞(congestion)时,交换机将开始丢弃数据包。这可能导致数据重发(retransmissions)、数据包查询(query packets),这些操作将进一步导致网络的拥塞。为了防止网络拥塞(network congestion),需限制流出网络的流量,使流量以比较均匀的速度向外发送。主要有两种限流算法:漏桶算法(Leaky Bucket)和 w397090770 6年前 (2018-06-04) 3334℃ 0评论4喜欢
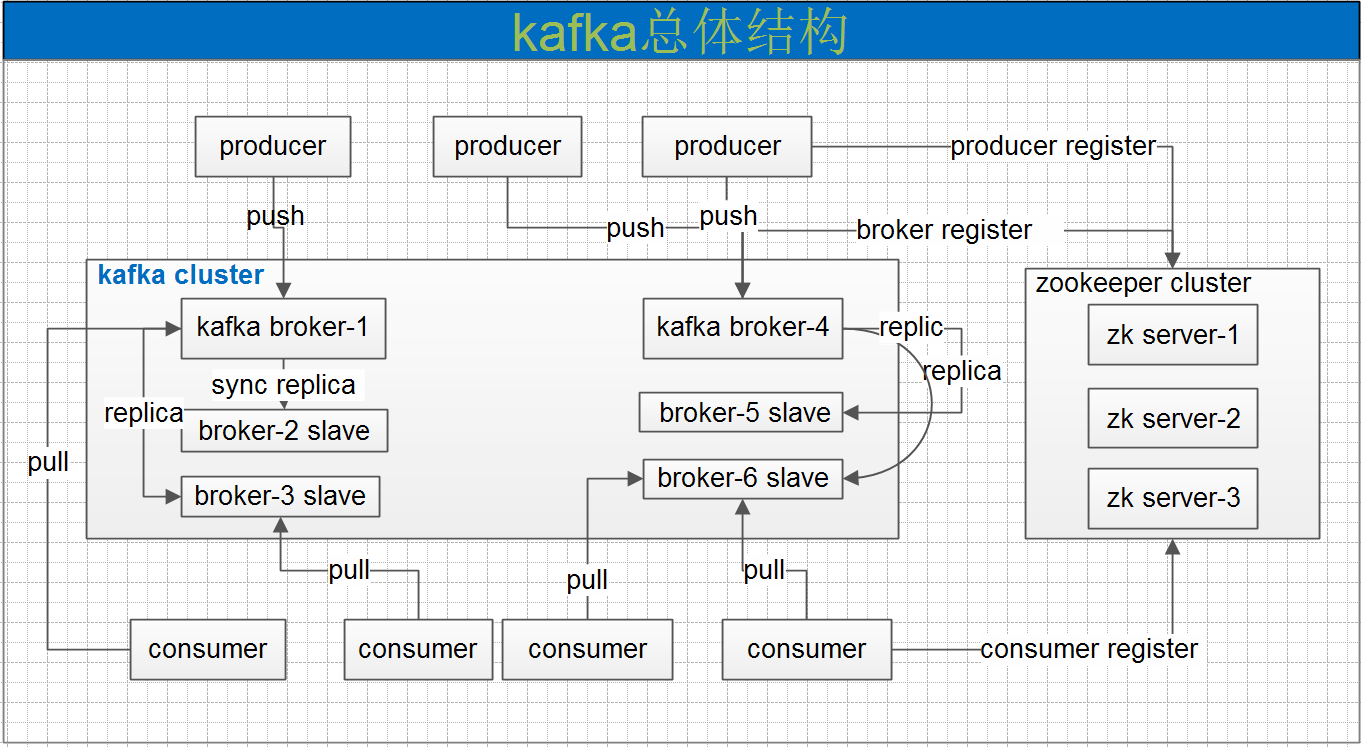
Kafka的基本介绍Kafka最初由Linkedin公司开发,是一个分布式、分区、多副本、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常用于web/nginx日志、访问日志,消息服务等等场景。Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。主要应用场景是:日志收集系统和消息系统。Kafka主要设计目标如下: w397090770 7年前 (2017-08-03) 5391℃ 0评论14喜欢
在即将发布的Apache Spark 2.0中将会提供机器学习模型持久化能力。机器学习模型持久化(机器学习模型的保存和加载)使得以下三类机器学习场景变得容易: 1、数据科学家开发ML模型并移交给工程师团队在生产环境中发布; 2、数据工程师把一个Python语言开发的机器学习模型训练工作流集成到一个Java语言开发的机器 w397090770 8年前 (2016-06-04) 3482℃ 3评论3喜欢
最近修改了Spark的一些代码,然后编译Spark出现了以下的异常信息:[code lang="scala"]error file=/iteblog/spark-1.3.1/streaming/src/main/scala/org/apache/spark/streaming/StreamingContext.scalamessage=File line length exceeds 100 characters line=279error file=/iteblog/spark-1.3.1/streaming/src/main/scala/org/apache/spark/streaming/StreamingContext.scalamessage=File line length exceeds 100 characters w397090770 9年前 (2015-05-20) 6016℃ 0评论3喜欢
JMX(Java Management Extensions,即Java管理扩展)是一个为应用程序、设备、系统等植入管理功能的框架。JMX可以跨越一系列异构操作系统平台、系统体系结构和网络传输协议,灵活的开发无缝集成的系统、网络和服务管理应用。启动JMX监控,在启动java程序的时候最少需要在环境变量里面配置以下的选项:[code lang="bash"]-Dcom.sun.m w397090770 9年前 (2016-03-25) 6185℃ 0评论10喜欢
随着越来越多的公司广泛部署 Presto,Presto 不仅用于查询,还用于数据摄取和 ETL 作业。所有很有必要提高 Presto 文件写入的性能,尤其是流行的列文件格式,如 Parquet 和 ORC。本文我们将介绍 Presto 的全新原生的 Parquet writer ,它可以直接将 Presto 的列式数据结构写到 Parquet 的列式格式,最高可提高6倍的吞吐量,并减少 CPU 和内存开销 w397090770 3年前 (2021-08-14) 513℃ 0评论2喜欢