Spark SQL 是 Spark 众多组件中技术最复杂的组件之一,它同时支持 SQL 查询和 DataFrame DSL。通过引入了 SQL 的支持,大大降低了开发人员的学习和使用成本。目前,整个 SQL 、Spark ML、Spark Graph 以及 Structured Streaming 都是运行在 Catalyst Optimization & Tungsten Execution 之上的,如下图所示:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关 w397090770 5年前 (2019-06-12) 10773℃ 0评论31喜欢
题目:一个数组里,除了三个数是唯一出现的,其余的都出现偶数个,找出这三个数中的任一个。比如数组元素为【1, 2,4,5,6,4,2】,只有1,5,6这三个数字是唯一出现的,我们只需要输出1,5,6中的一个就行。下面是我的思路:这个数组元素个数一定为奇数,而且那要求的三个数一定不可能每一bit位都相同,所以我们可以找到其中一个b w397090770 12年前 (2013-03-31) 4066℃ 1评论4喜欢
我们知道,Flume可以和许多的系统进行整合,包括了Hadoop、Spark、Kafka、Hbase等等;当然,强悍的Flume也是可以和Mysql进行整合,将分析好的日志存储到Mysql(当然,你也可以存放到pg、oracle等等关系型数据库)。 不过我这里想多说一些:Flume是分布式收集日志的系统;既然都分布式了,数据量应该很大,为什么你要将Flume分 w397090770 10年前 (2014-09-04) 25722℃ 21评论40喜欢
在《在Kafka中使用Avro编码消息:Producter篇》 和 《在Kafka中使用Avro编码消息:Consumer篇》 两篇文章里面我介绍了直接使用原生的 Kafka API生成和消费 Avro 类型的编码消息,本文将继续介绍如何通过 Spark 从 Kafka 中读取这些 Avro 格式化的消息。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop其 zz~~ 7年前 (2017-09-26) 4756℃ 0评论19喜欢
youtube-dl是一个精悍的命令程序,它可以从YouTube.com以及其他网站上下载视频。它是使用Python开发的,依赖于Python 2.6, 2.7, 或者3.2+解释器,而且这个视频下载命令是跨平台的,作者为我们带来了Windows执行文件(https://yt-dl.org/latest/youtube-dl.exe),其中就包含了Python。youtube-dl可以在Unix box,Windows或者是 Mac OS X平台上运行,支持众多视频网 w397090770 9年前 (2016-04-09) 6668℃ 0评论6喜欢
上海Spark meetup第七次聚会将于2016年1月23日(周六)在上海市长宁区金钟路968号凌空SOHO 8号楼 进行。此次聚会由Intel联合携程举办。大会主题 1、开场/Opening Keynote: 张翼,携程大数据平台的负责人 个人介绍:本科和研究生都是浙江大学;2015年加入携程,推动携程大数据平台的演进;对大数据底层框架Hadoop,HIVE,Spark w397090770 9年前 (2016-01-28) 2556℃ 0评论6喜欢
相关图标矢量字库:《Font Awesome:图标字体》、《阿里巴巴矢量图标库:Iconfont》 Iconfont.cn是由阿里巴巴UX部门推出的矢量图标管理网站,也是国内首家推广Webfont形式图标的平台。网站涵盖了1000多个常用图标并还在持续更新中(目前加上用户上传的图标近70000个,我们可以通过搜索来找到他们。)。、 Iconfont平台为用 w397090770 10年前 (2015-02-26) 29376℃ 0评论27喜欢
静态分区裁剪(Static Partition Pruning)用过 Spark 的同学都知道,Spark SQL 在查询的时候支持分区裁剪,比如我们如果有以下的查询:[code lang="sql"]SELECT * FROM Sales_iteblog WHERE day_of_week = 'Mon'[/code]Spark 会自动进行以下的优化:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop从上图可以看到,S w397090770 5年前 (2019-11-04) 2629℃ 0评论6喜欢
我在《使用Hive读取ElasticSearch中的数据》文章中介绍了如何使用Hive读取ElasticSearch中的数据,本文将接着上文继续介绍如何使用Hive将数据写入到ElasticSearch中。在使用前同样需要加入 elasticsearch-hadoop-2.3.4.jar 依赖,具体请参见前文介绍。我们先在Hive里面建个名为iteblog的表,如下:[code lang="sql"]CREATE EXTERNAL TABLE iteblog ( id b w397090770 8年前 (2016-11-07) 19951℃ 1评论24喜欢
本文节选自《大数据之路:阿里巴巴大数据实践》,关注 iteblog_hadoop 公众号并在这篇文章里面文末评论区留言(认真写评论,增加上榜的机会)。留言点赞数排名前5名的粉丝,各免费赠送一本《大数据之路:阿里巴巴大数据实践》,活动截止至08月11日18:00。这篇文章评论区留言才有资格参加送书活动:https://mp.weixin.qq.com/s/BR7M8Rty w397090770 7年前 (2017-08-03) 1681℃ 0评论11喜欢
Apache软件基金会在2017年01月10正式宣布Apache Beam从孵化项目毕业,成为Apache的顶级项目。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领 w397090770 8年前 (2017-01-12) 3158℃ 0评论7喜欢
1、新增"Explain dependency"语法,以json格式输出执行语句会读取的input table和input partition信息,这样debug语句会读取哪些表就很方便了[code lang="JAVA"]hive> explain dependency select count(1) from p;OK{"input_partitions":[{"partitionName":"default@p@stat_date=20110728/province=bj"},{"partitionName":"default@p@stat_date=20110728/provinc w397090770 11年前 (2013-11-04) 7532℃ 2评论4喜欢
本文总结了几个本人在使用 Carbondata 的时候遇到的几个问题及其解决办法。这里使用的环境是:Spark 2.1.0、Carbondata 1.2.0。必须指定 HDFS nameservices在初始化 CarbonSession 的时候,如果不指定 HDFS nameservices,在数据导入是没啥问题的;但是数据查询会出现相关数据找不到问题:[code lang="scala"]scala> val carbon = SparkSession.builder().temp w397090770 7年前 (2017-11-09) 6597℃ 5评论14喜欢
《Spark RDD API扩展开发(1)》、《Spark RDD API扩展开发(2):自定义RDD》 在本博客的《Spark RDD API扩展开发(1)》文章中我介绍了如何在现有的RDD中添加自定义的函数。本文将介绍如何自定义一个RDD类,假如我们想对没见商品进行打折,我们想用Action操作来实现这个操作,下面我将定义IteblogDiscountRDD类来计算商品的打折,步骤如 w397090770 10年前 (2015-03-31) 11975℃ 0评论8喜欢
本 hosts 文件更新时间为 2018年07月22日。原作者为 Google Hosts 组织本页面长期更新最新 Google、谷歌学术、维基百科、ccFox.info、ProjectH、3DM、Battle.NET 、WordPress、Microsoft Live、GitHub、Box.com、SoundCloud、inoreader、Feedly、FlipBoard、Twitter、Facebook、Flickr、imgur、DuckDuckGo、Ixquick、Google Services、Google apis、Android、Youtube、Google Drive、UpLoad、Appspot、 w397090770 7年前 (2018-01-09) 16185℃ 1评论43喜欢
本书于2015年7月出版,共206页,这里提供的只有第一章,属于预览版。 w397090770 9年前 (2015-08-21) 2546℃ 0评论3喜欢
Apache Flume 1.7.0是自Flume成为Apache顶级项目的第十个版本。Apache Flume 1.7.0可以在生产环境下使用。Flume 1.7.0 User Guide下载Flume 1.7.0Flume 1.7.0 Developer GuideChanges[code lang="bash"]** New Feature[FLUME-2498] - Implement Taildir Source** Improvement[FLUME-1899] - Make SpoolDir work with Sub-Directories[FLUME-2526] - Build flume by jdk 7 in default[FLUME-2628] - Add an optiona w397090770 8年前 (2016-10-19) 3684℃ 0评论11喜欢
假设现在的分支名称为 oldName,想要修改为 newName如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本地分支重命名这种情况是你的代码还没有推送到远程,分支只是在本地存在,那直接执行下面的命令即可:[code lang="bash"]git branch -m oldName newName[/code]远程分支重命名 如果你的分支已经推 w397090770 8年前 (2017-03-02) 728℃ 0评论1喜欢
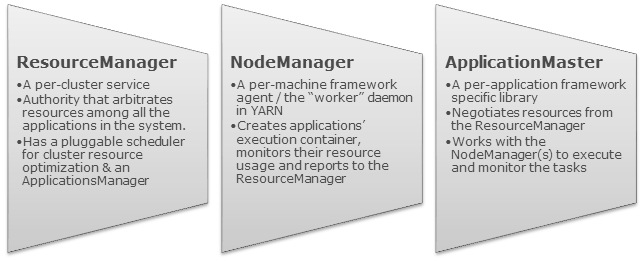
Apache YARN是将之前Hadoop 1.x的 JobTracker 功能分别拆到不同的组件里面了,每个组件分别负责不同的功能。在Hadoop 1.x中, JobTracker 负责管理集群的资源,作业调度以及作业监控;YARN把这些功能分别拆到ResourceManager 和 ApplicationMaster 中了。而之前的TaskTracker被NodeManager替代。下面分别介绍YAEN的各个组件的作用。如果想及时了解Spark、Had w397090770 7年前 (2017-06-01) 3985℃ 0评论31喜欢
背景 B站的YARN以社区的2.8.4分支构建,采用CapacityScheduler作为调度器, 期间进行过多次核心功能改造,目前支撑了B站的离线业务、实时业务以及部分AI训练任务。2020年以来,随着B站业务规模的迅速增长,集群总规模达到8k左右,其中单集群规模已经达到4k+ ,日均Application(下文简称App)数量在20w到30w左右。当前最大单集群整体cpu w397090770 2年前 (2022-04-11) 788℃ 0评论2喜欢
gossip 是什么gossip 协议(gossip protocol)又称 epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议,在分布式系统中被广泛使用,比如我们可以使用 gossip 协议来确保网络中所有节点的数据一样。gossip protocol 最初是由施乐公司帕洛阿尔托研究中心(Palo Alto Research Center)的研究员艾伦·德默斯(Al w397090770 6年前 (2019-01-24) 19689℃ 1评论15喜欢
在使用Maven打包工程运行的时候,有时会出现以下的异常:[code lang="bash"]-bash-4.1# java -cp iteblog-1.0-SNAPSHOT.jar com.iteblog.ClientException in thread "main" java.lang.SecurityException: Invalid signature file digest for Manifest main attributes at sun.security.util.SignatureFileVerifier.processImpl(SignatureFileVerifier.java:287) at sun.security.util.SignatureFileVerifier.process(Signatu w397090770 9年前 (2016-01-20) 13248℃ 0评论9喜欢
根据官方文档(Apache Hadoop MapReduce - Migrating from Apache Hadoop 1.x to Apache Hadoop 2.x:http://hadoop.apache.org/docs/r2.2.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduce_Compatibility_Hadoop1_Hadoop2.html)所述,Hadoop2.x是对Hadoop1.x程序兼容的,由于Hadoop2.x对Hadoop1.x做了重大的结构调整,很多程序依赖库被拆分了,所以以前(Hadoop1.x)的依赖库不再可 w397090770 11年前 (2013-11-26) 9592℃ 3评论2喜欢
Few months ago, I introduced a simple algorithm that allow users to implement their own short URL into their system. Today, I have some spare time so I decided to write the short URL algorithm's implementation in PHP.At first, we define a function called shorturl() that receives a URL as the input and returns an array that contains 4 hashed values (each 6 characters).[php]function shorturl($input) { ... // return array of w397090770 12年前 (2013-04-14) 3837℃ 0评论1喜欢
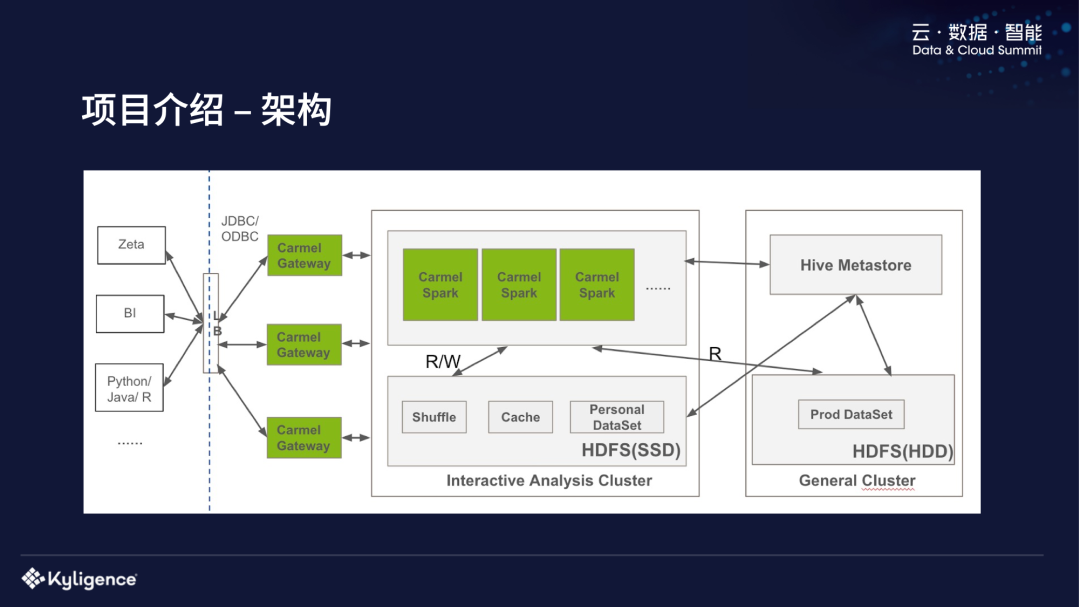
系统介绍我们这个系统的名字叫 Carmel,它是基于开源的 Hadoop 和 Spark 来替换传统的数据仓库,我们是 2019 年开始做我们这个项目的,当时是基于 Spark 2.3.1,最近刚刚升到 Spark 3.0。面临的主要技术挑战,第一个是功能方面的缺失,包括访问控制,还有一些 Update 和 Delete 的支持;在性能方面跟传统数仓,特别是交互式的分析查询中性 zz~~ 3年前 (2021-09-24) 647℃ 0评论2喜欢
Hive on Spark功能目前只增加下面九个参数,具体含义可以参见下面介绍。hive.spark.client.future.timeout Hive client请求Spark driver的超时时间,如果没有指定时间单位,默认就是秒。Expects a time value with unit (d/day, h/hour, m/min, s/sec, ms/msec, us/usec, ns/nsec), which is sec if not specified. Timeout for requests from Hive client to remote Spark driver.hive.spark.job.mo w397090770 9年前 (2015-12-07) 24550℃ 2评论11喜欢
SQL Join 是最重要和最昂贵的 SQL 操作之一,需要数据库工程师深入理解才能编写高效的 SQL 查询。 从数据库工程师的角度来看,了解 JOIN 操作的工作原理有助于他们优化 JOIN 以实现高效执行。 本文介绍了开源分布式计算引擎 Presto SQL 支持的 join 操作。几乎所有众所周知的数据库都支持以下五种类型的 JOIN 操作:Cross Join, Inner Join, L w397090770 3年前 (2021-11-01) 1470℃ 0评论1喜欢
Apache Spark是快速的通用集群计算系统。它在Java、Scala以及Python等语言提供了高层次的API,并且在通用的图形计算方面提供了一个优化的引擎。同时,它也提供了丰富的高层次工具,这些工具包括了Spark SQL、结构化数据处理、机器学习工具(MLlib)、图形计算(GraphX)以及Spark Streaming。如果想及时了解Spark、Hadoop或者Hbase相关的文章, w397090770 10年前 (2014-09-18) 3599℃ 0评论6喜欢
Learning Apache Kafka, 2nd Edition于2015年02月出版,全书共112页。 w397090770 9年前 (2015-08-25) 5633℃ 2评论10喜欢
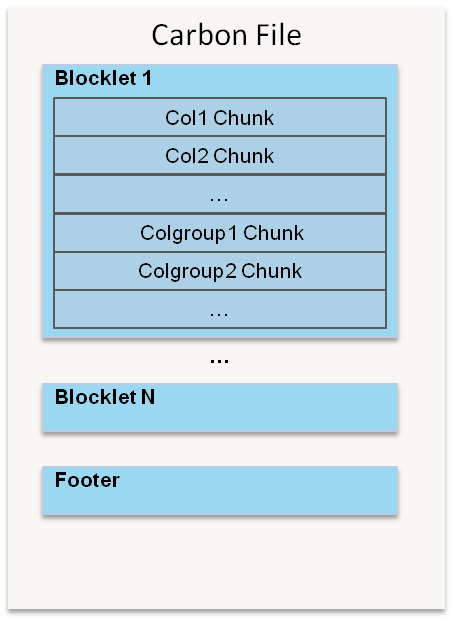
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。为什么重新设计一种文件格式目前华为针对数据的需求分析主要有以下5点要求: 1、支持海量数据扫描并 w397090770 8年前 (2016-06-13) 5484℃ 0评论7喜欢