导读:在腾讯金融场景,我们每天都会产生大量的数据,为了提升分析的交互性,让决策更加敏捷,我们引入了Impala来解决我们的分析需求。所以,本文将和大家分享Impala在腾讯金融大数据场景中的应用架构,Impala的原理,落地过程的案例和优化以及总结思考。Impala的架构 首先介绍Impala的整体架构,帮助大家从宏观角度理 w397090770 3年前 (2021-10-28) 389℃ 0评论1喜欢
本文系奇虎360系统部相关工程师投稿。近两年人工智能技术发展迅速,以Google开源的TensorFlow为代表的各种深度学习框架层出不穷。为了方便算法工程师使用各类深度学习技术,减少繁杂的诸如运行环境部署运维等工作,提升GPU等硬件资源利用率,节省硬件投入成本,奇虎360系统部大数据团队与人工智能研究院联合开发了深度学习 w397090770 7年前 (2017-12-08) 2744℃ 0评论15喜欢
Lists类主要提供了对List类的子类构造以及操作的静态方法。在Lists类中支持构造ArrayList、LinkedList以及newCopyOnWriteArrayList对象的方法。其中提供了以下构造ArrayList的函数:下面四个构造一个ArrayList对象,但是不显式的给出申请空间的大小:[code lang="JAVA"] newArrayList() newArrayList(E... elements) newArrayList(Iterable<? w397090770 11年前 (2013-09-10) 19702℃ 2评论8喜欢
里氏替换法则(Liskov Substitution Principle LSP)是面向对象设计的六大基本原则之一(单一职责原则、里氏替换原则、依赖倒置原则、接口隔离原则、迪米特法则以及开闭原则)。这里说说里氏替换法则:父类的一个方法返回值是一个类型T,子类相同方法(重载或重写)返回值为S,那么里氏替换法则就要求S必须小于等于T,也就是说要么 w397090770 11年前 (2013-09-12) 4262℃ 3评论0喜欢
Spark已经取代Hadoop成为最活跃的开源大数据项目。但是,在选择大数据框架时,企业不能因此就厚此薄彼。近日,著名大数据专家Bernard Marr在一篇文章(http://www.forbes.com/sites/bernardmarr/2015/06/22/spark-or-hadoop-which-is-the-best-big-data-framework/)中分析了Spark和Hadoop的异同。 Hadoop和Spark均是大数据框架,都提供了一些执行常见大数据任务 w397090770 9年前 (2015-12-01) 9543℃ 0评论31喜欢
这里的方法貌似没有用,请参见本博客最新博文《CentOS 6.4安装谷歌浏览器(Chrome)》可以解决这个问题。 Google Chrome,又称Google浏览器,是一个由Google(谷歌)公司开发的开放原始码网页浏览器。如何在Cent OS里面安装Chrome呢?步骤如下: 第一步:打开终端,输入下面的命令[code lang="JAVA"]vim /etc/yum.repos.d/CentOS-Base.repo w397090770 11年前 (2013-08-07) 17696℃ 0评论5喜欢
Balloon.css文件允许用户给元素添加提示,而这些在Balloon.css中完全是由CSS来实现,不需要使用JavaScript。 button { display: inline-block; min-width: 160px; text-align: center; color: #fff; background: #ff3d2e; padding: 0.8rem 2rem; font-size: 1.2rem; margin-top: 1rem; border: none; border-radius: 5px; transition: background 0.1s linear;}.butt w397090770 9年前 (2016-03-15) 2474℃ 3评论10喜欢
Apache Flink 1.1.3仍然在Flink 1.1系列基础上修复了一些Bug,推荐所有用户升级到Flink 1.1.3,只需要在你相关工程的pom.xml文件里面加入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.1.3</version></dependency><dependency> <groupId>org.apache w397090770 8年前 (2016-10-16) 1582℃ 0评论5喜欢
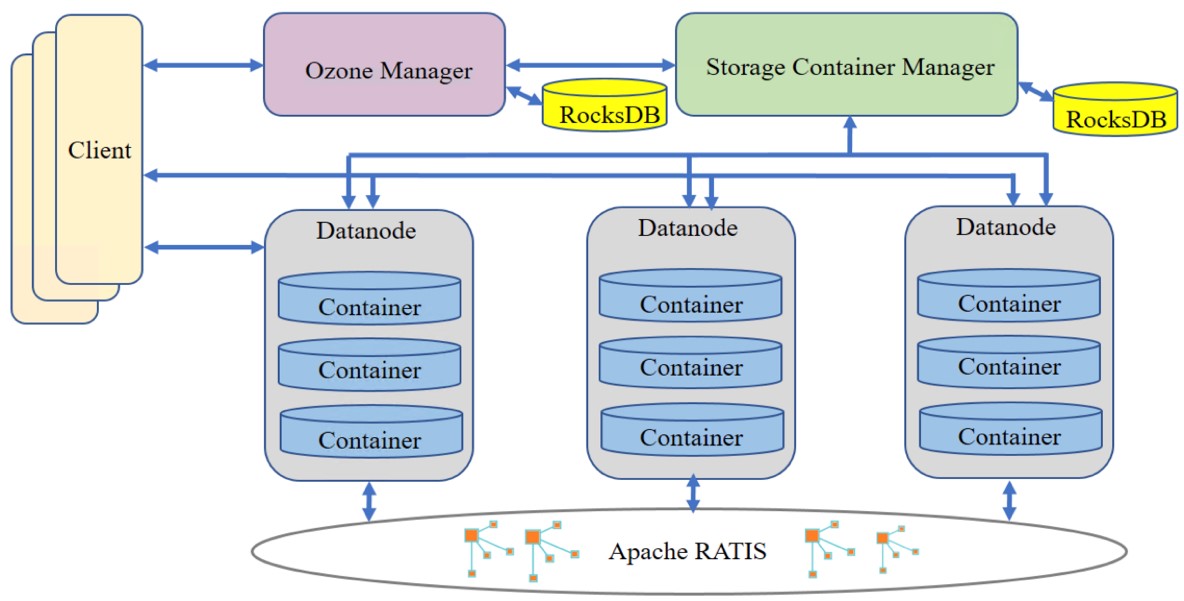
刚刚获悉,Apache基金董事会通过一致表决,正式批准分布式文件对象存储Ozone从Hadoop社区孵化成功,成为独立的Apache顶级开源项目。这意味着,作为腾讯大数据团队首个参与和主导的开源项目,Ozone已得到全球Apache技术专家的一致认可,成为世界顶级的存储开源项目之一。Ozone 是Apache Hadoop社区推出的面向大数据领域的新一代分布 w397090770 4年前 (2020-12-09) 1084℃ 0评论7喜欢
我们已经在 这篇文章详细介绍了 Apache Spark Delta Lake 的事务日志是什么、主要用途以及如何工作的。那篇文章已经可以很好地给大家介绍 Delta Lake 的内部工作原理,原子性保证,本文为了学习的目的,带领大家从源码级别来看看 Delta Lake 事务日志的实现。在看本文时,强烈建议先看一下《深入理解 Apache Spark Delta Lake 的事务日志》文 w397090770 5年前 (2019-09-02) 1743℃ 0评论4喜欢
Monarch 是 Pinterest 的批处理平台,由30多个 Hadoop YARN 集群组成,其中17k+节点完全建立在 AWS EC2 之上。2021年初,Monarch 还在使用五年前的 Hadoop 2.7.1。由于同步社区分支(特性和bug修复)的复杂性不断增加,我们决定是时候进行版本升级了。我们最终选择了Hadoop 2.10.0,这是当时 Hadoop 2 的最新版本。本文分享 Pinterest 将 Monarch 升级到 Ha w397090770 2年前 (2022-08-12) 594℃ 0评论3喜欢
直到目前,我们看到的所有Mapreduce作业都输出一组文件。但是,在一些场合下,经常要求我们将输出多组文件或者把一个数据集分为多个数据集更为方便;比如将一个log里面属于不同业务线的日志分开来输出,并交给相关的业务线。 用过旧API的人应该知道,旧API中有 org.apache.hadoop.mapred.lib.MultipleOutputFormat和org.apache.hadoop.mapr w397090770 11年前 (2013-11-26) 15122℃ 1评论10喜欢
我们在 前面的文章文章中介绍了 Docker 默认是从 https://hub.docker.com/仓库下载镜像的,由于这个网址是国外的,所以在下载镜像的时候很可能会非常慢,所以大家应该想到 Docker 是否像 Maven 仓库一样也有一些国内的 Docker 镜像库呢?答案是肯定的。截止到本文撰写的时候,下面几个国内 Docker 镜像地址是可用的:网易 Docker 镜像库:h w397090770 5年前 (2020-02-03) 11326℃ 0评论4喜欢
在Spark中分区器直接决定了RDD中分区的个数;也决定了RDD中每条数据经过Shuffle过程属于哪个分区;也决定了Reduce的个数。这三点看起来是不同的方面的,但其深层的含义是一致的。 我们需要注意的是,只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None的。 在Spark中,存在两类分区函数:HashPartitioner w397090770 9年前 (2015-11-10) 18568℃ 2评论40喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive的设计目的是为了那 w397090770 11年前 (2014-01-06) 16061℃ 2评论8喜欢
假设我们有这样的场景:我们想在 Cassandra 中使用一张表记录用户基本信息(比如 email、密码等)以及用户状态更新。我们知道,用户的基本信息一般很少会变动,但是状态会经常变化,如果每次状态更新都把用户基本信息都加进去,势必会让费大量的存储空间。为了解决这种问题,Cassandra 引入了 static column。同一个 partition key 中被 w397090770 6年前 (2019-04-12) 1367℃ 0评论2喜欢
Spark Streaming和Flink都能提供恰好一次的保证,即每条记录都仅处理一次。与其他处理系统(比如Storm)相比,它们都能提供一个非常高的吞吐量。它们的容错开销也都非常低。之前,Spark提供了可配置的内存管理,而Flink提供了自动内存管理,但从1.6版本开始,Spark也提供了自动内存管理。这两个流处理引擎确实有许多相似之处, w397090770 9年前 (2016-04-02) 4730℃ 0评论5喜欢
ResourceManager 内维护了 NodeManager 的生命周期;对于每个 NodeManager 在 ResourceManager 中都有一个 RMNode 与其对应;除了 RMNode ,ResourceManager 中还定义了 NodeManager 的状态(states)以及触发状态转移的事件(event)。具体如下:org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNode:这是一个接口,每个 NodeManager 都与 RMNode 对应,这个接口主要维 w397090770 7年前 (2017-06-07) 3568℃ 0评论21喜欢
本页面不再更新,请移步到 《2018 最新 hosts 文件持续更新》如果之前的hosts文件还有效可以不更新;由于大家使用的带宽种类,地区,被墙的程度不一样,所以有些地区使用本Hosts文件可能仍然无法使用Google;光靠修改Hosts文件是无法观看youtube里面的视频,重要的事说三遍:通过本hosts文件可以打开youtube网站,但是无法观看 w397090770 9年前 (2015-09-25) 194025℃ 376喜欢
本资料来自2021年12月09日举办的 PrestoCon 2021,标题为《Presto at Bytedance》Presto 在字节跳动中得到了广泛的应用,如数据仓库、BI工具、广告等。与此同时,字节跳动的 presto 团队也提供了许多重要的特性和优化,如 Hive UDF Wrapper、多个协调器、运行时过滤器等,扩展了 presto 的用法,增强了 presto 的稳定性。下面是字节跳动目前 Presto w397090770 3年前 (2021-12-08) 405℃ 0评论0喜欢
2016中国架构师大会大数据专场于10月27日在京进行,大数据专场有来自搜狐、优酷介绍其视频个性化推荐架构设计;也有来自饿了么的实时架构演变;有来自Qunar、宜信以及广发证券再金融中应用大数据的架构设计;也有华为CarbonData的介绍,干货十足!值得一看。主要涉及如下主题: 10月27 w397090770 8年前 (2016-11-03) 4707℃ 0评论9喜欢
Elasticsearch 6.3 于前天正式发布,其中带来了很多新特性,详情请参见:https://www.elastic.co/blog/elasticsearch-6-3-0-released。这个版本最大的亮点莫过于内置支持 SQL 模块!我在早些时间就说过 Elasticsearch 将会内置支持 SQL,参见:ElasticSearch内置也将支持SQL特性。我们可以像操作 MySQL一样使用 Elasticsearch,这样我们就可以减少 DSL 的学习成本, w397090770 6年前 (2018-06-15) 8949℃ 3评论14喜欢
如果你想配置完全分布式平台请参见本博客《Hadoop2.2.0完全分布式集群平台安装与设置》 首先,你得在电脑上面安装好jdk7,如何安装,这里就不说了,网上一大堆教程!然后安装好ssh,如何安装请参见本博客《Linux平台下安装SSH》、并设置好无密码登录(《Ubuntu和CentOS如何配置SSH使得无密码登陆》)。好了,上面的 w397090770 11年前 (2013-10-28) 9439℃ 7评论7喜欢
我们知道,编写Scala程序的时候可以使用下面两种方法之一:[code lang="scala"]object IteblogTest extends App { //ToDo}object IteblogTest{ def main(args: Array[String]): Unit = { //ToDo }}[/code] 上面的两种方法都可以运行程序,但是在Spark中,第一种方法有时可不会正确的运行(出现异常或者是数据不见了)。比如下面的代码运 w397090770 9年前 (2015-12-10) 5283℃ 0评论5喜欢
分布式计算开源框架Hadoop近日发布了今年的第一个版本Hadoop-2.3.0,新版本不仅增强了核心平台的大量功能,同时还修复了大量bug。新版本对HDFS做了两个非常重要的增强:(1)、支持异构的存储层次;(2)、通过数据节点为存储在HDFS中的数据提供了内存缓存功能。 借助于HDFS对异构存储层次的支持,我们将能够在同一个Hado w397090770 11年前 (2014-03-02) 4134℃ 0评论1喜欢
在《Hadoop 1.x中fsimage和edits合并实现》文章中,我们谈到了Hadoop 1.x上的fsimage和edits合并实现,里面也提到了Hadoop 2.x版本的fsimage和edits合并实现和Hadoop 1.x完全不一样,今天就来谈谈Hadoop 2.x中fsimage和edits合并的实现。 我们知道,在Hadoop 2.x中解决了NameNode的单点故障问题;同时SecondaryName已经不用了,而之前的Hadoop 1.x中是通过Se w397090770 11年前 (2014-03-12) 12492℃ 0评论20喜欢
AdminLTE是一个完全响应式管理并基于Bootstrap 3.x的免费高级管理控制面板主题。高度可定制的,易于使用。自适应多种屏幕分辨率,兼容PC端和手机移动端,内置了多个模板页面,包括仪表盘、邮箱、日历、锁屏、登录及注册、404错误、500错误等页面。AdminLTE是基于模块化设计,很容易在其之上定制和重制。本文撰写的时候AdminLTE w397090770 8年前 (2016-07-17) 18602℃ 0评论24喜欢
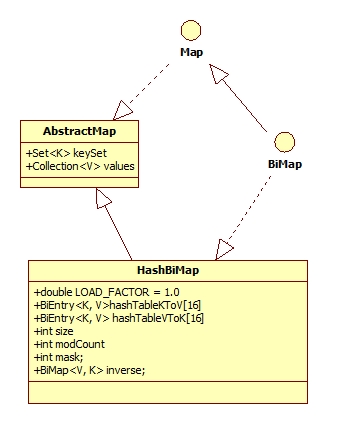
HashBiMap存储的键和值都只能唯一,不存在键与键、值与值相同的情况(详细分析见我博客:Guava学习之BiMap)。HashBiMap类继承了AbstractMap类并实现了BiMap接口,其类继承关系如下图所示:[caption id="attachment_705" align="aligncenter" width="356"] HashBiMap[/caption] AbstractMap类实现了Map接口定义的一些方法,而BiMap类定义了其子类需要实现的 w397090770 11年前 (2013-09-16) 4363℃ 0评论3喜欢
默认情况下,Flume中的PollingPropertiesFileConfigurationProvider会每隔30秒去重新加载Flume agent的配置文件,如果监听到配置文件变化了,Flume会试图重新加载变化的配置文件。判断配置文件是否变化主要是基于文件的最后修改时间来的,代码片段如下:[code lang="java"]///////////////////////////////////////////////////////////////////// User: 过往记忆 w397090770 9年前 (2015-08-20) 6667℃ 0评论13喜欢
在《Guava学习之RangeSet》中谈到了RangeSet的特点及其用法。今天要谈的的RangeMap和RangeSet有许多不一样的。 在Google Guava官方API上面可以得知:RangeMap是一种集合类型( collection type),它将不相交、且不为空的Range(key)映射给一个值(Value)。和RangeSet不一样,RangeMap不可以将相邻的区间合并,即使这个区间映射的值是一样的。 w397090770 11年前 (2013-07-18) 6909℃ 0评论5喜欢












![最新可访问Google的Hosts文件[最新更新]](https://www.iteblog.com/pic/host.jpg)