本文来自 submarine 团队投稿。作者: Wangda Tan & Sunil Govindan & Zhankun Tang(这篇博文由网易的刘勋和周全协助编写)。原文地址:https://hortonworks.com/blog/submarine-running-deep-learning-workloads-apache-hadoop/介绍Hadoop 是用于大型企业数据集的分布式处理的最流行的开源框架,它在本地和云端环境中都有很多重要用途。深度学习对于语 w397090770 6年前 (2019-01-01) 4027℃ 0评论4喜欢
由于Hadoop自身的一些特点,它只适合用于将Linux作为操作系统的生产环境。在实际应用场景中,管理员适当对Linux内核参数进行调优,可在一定程度上提高作业的运行效率,比较有用的调整选项如下。一、增大同时打开的文件描述符和网络连接上限 在Hadoop集群中,由于涉及的作业和任务数目非常多,对于某个节点,由于 w397090770 11年前 (2014-04-02) 13057℃ 1评论7喜欢
Spark Streaming是近实时(near real time)的小批处理系统。对给定的时间间隔(interval),Spark Streaming生成新的batch并对它进行一些处理。每个batch中的数据都代表一个RDD,但是如果一些batch中没有数据会发生什么事情呢?Spark Streaming将会产生EmptyRDD的RDD,它的定义如下:[code lang="scala"]package org.apache.spark.rddimport scala.reflect.ClassTagimport w397090770 10年前 (2015-04-08) 10132℃ 1评论11喜欢
Java 8 流的新类 java.util.stream.Collectors 实现了 java.util.stream.Collector 接口,同时又提供了大量的方法对流 ( stream ) 的元素执行 map and reduce 操作,或者统计操作。本章节,我们就来看看那些常用的方法,顺便写几个示例练练手。Collectors.averagingDouble()Collectors.averagingDouble() 方法将流中的所有元素视为 double 类型并计算他们的平均值 w397090770 3年前 (2022-03-31) 175℃ 0评论1喜欢
导读:Flink 从 1.9.0 开始提供与 Hive 集成的功能,随着几个版本的迭代,在最新的 Flink 1.11 中,与 Hive 集成的功能进一步深化,并且开始尝试将流计算场景与Hive 进行整合。本文主要分享在 Flink 1.11 中对接 Hive 的新特性,以及如何利用 Flink 对 Hive 数仓进行实时化改造,从而实现批流一体的目标。主要内容包括: Flink 与 Hive 集成的 w397090770 4年前 (2020-11-26) 2349℃ 0评论11喜欢
在使用Hadoop的时候,一般配置SSH使得我们可以无密码登录到主机,下面分别以Ubuntu和CentOS两个平台来举例说明如何配置SSH使得我们可以无密码登录到主机,当然,你得先安装好SSH服务器,并开启(关于如何在Linux平台下安装好SSH请参加本博客的《Linux平台下安装SSH》)在 Ubuntu 平台设置 SSH 无秘钥登录Ubuntu配置步骤如下所示:[c w397090770 11年前 (2013-10-24) 7786℃ 4评论3喜欢
SBT默认的日志级别是Info,我们可以根据自己的需要去设置它的默认日志级别,比如我们在开发过程中,就可以打开Debug日志级别,这样可以看出SBT是如何工作的。SBT的日志级别在sbt.Level类里面定义:[code lang="scala"]object Level extends Enumeration{ val Debug = Value(1, "debug") val Info = Value(2, "info") val Warn = Value(3, "warn&q w397090770 9年前 (2015-12-24) 3447℃ 0评论8喜欢
本文将介绍如何在Local模式下安装和使用Flink集群。要求(Requirements) Flink可以在Linux, Mac OS X 以及Windows等平台上运行。Local模式安装的唯一要求是安装Java 1.7.x或者更高版本。下面的操作假定是类UNIX环境,对于Windows可以参见本文的Flink on Windows章节。我们可以使用下面的命令来查看Java的版本:[code lang="bash"]java -versio w397090770 9年前 (2016-04-19) 5368℃ 0评论3喜欢
前言本文讨论了京东搜索在实时流量数据分析方面,利用Apache Flink和Apache Doris进行的探索和实践。流式计算在近些年的热度与日俱增,从Google Dataflow论文的发表,到Apache Flink计算引擎逐渐站到舞台中央,再到Apache Druid等实时分析型数据库的广泛应用,流式计算引擎百花齐放。但不同的业务场景,面临着不同的问题,没有哪一种引 w397090770 4年前 (2020-12-25) 1285℃ 0评论4喜欢
经过几个星期的开发,本博客微信小程序(过往记忆大数据技术博客)正式上线了!至此大家可以通过微信公众号、微信小程序等方式访问本博客了。下面来看看本博客微信公众号的一些预览:微信小程序首页在首页可以查看本博客最新的文章,热门文章以及搜索等。文章页文章页可以文章的详情,功 w397090770 7年前 (2018-01-28) 1948℃ 0评论7喜欢
每次当你在Yarn上以Cluster模式提交Spark应用程序的时候,通过日志我们总可以看到下面的信息:[code lang="java"]21 Oct 2014 14:23:22,006 INFO [main] (org.apache.spark.Logging$class.logInfo:59) - Uploading file:/home/spark-1.1.0-bin-2.2.0/lib/spark-assembly-1.1.0-hadoop2.2.0.jar to hdfs://my/user/iteblog/...../spark-assembly-1.1.0-hadoop2.2.0.jar21 Oct 2014 14:23:23,465 INFO [main] (org.ap w397090770 10年前 (2014-11-10) 10900℃ 2评论12喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 10年前 (2015-03-30) 4843℃ 0评论4喜欢
7.1 TF-IDF TF-IDF是一种特征向量化方法,这种方法多用于文本挖掘,通过算法可以反应出词在语料库中某个文档中的重要性。文档中词记为t,文档记为d , 语料库记为D . 词频TF(t,d) 是词t 在文档d 中出现的次数。文档频次DF(t,D) 是语料库中包括词t的文档数。如果使用词在文档中出现的频次表示词的重要程度,那么很容易取出反例, w397090770 9年前 (2016-03-27) 6041℃ 0评论6喜欢
Delta Lake 写数据是其最基本的功能,而且其使用和现有的 Spark 写 Parquet 文件基本一致,在介绍 Delta Lake 实现原理之前先来看看如何使用它,具体使用如下:[code lang="scala"]df.write.format("delta").save("/data/iteblog/delta/test/")//数据按照 dt 分区df.write.format("delta").partitionBy("dt").save("/data/iteblog/delta/test/" w397090770 5年前 (2019-09-10) 2186℃ 0评论2喜欢
在Spark中分区器直接决定了RDD中分区的个数;也决定了RDD中每条数据经过Shuffle过程属于哪个分区;也决定了Reduce的个数。这三点看起来是不同的方面的,但其深层的含义是一致的。 我们需要注意的是,只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None的。 在Spark中,存在两类分区函数:HashPartitioner w397090770 9年前 (2015-11-10) 18568℃ 2评论40喜欢
Balloon.css文件允许用户给元素添加提示,而这些在Balloon.css中完全是由CSS来实现,不需要使用JavaScript。 button { display: inline-block; min-width: 160px; text-align: center; color: #fff; background: #ff3d2e; padding: 0.8rem 2rem; font-size: 1.2rem; margin-top: 1rem; border: none; border-radius: 5px; transition: background 0.1s linear;}.butt w397090770 9年前 (2016-03-15) 2474℃ 3评论10喜欢
如果你使用Nginx web server,你可能在访问你网站的时候出现了504 Gateway Time-out错误,这个错误代码很常见,这可能是因为超过了PHP的最大执行时间的限制或者是FastCGI读超时。这篇文章将向大家展示如何解决Nginx的504 gateway timeout的问题。一、修改php.ini文件 下面都是以CentOS服务器为例进行介绍,如果你是CentOS,那么可以直 w397090770 9年前 (2015-08-18) 19791℃ 2评论16喜欢
双重检查锁定模式(也被称为"双重检查加锁优化","锁暗示"(Lock hint)) 是一种软件设计模式用来减少并发系统中竞争和同步的开销。双重检查锁定模式首先验证锁定条件(第一次检查),只有通过锁定条件验证才真正的进行加锁逻辑并再次验证条件(第二次检查)。该模式在某些语言在某些硬件平台的实现可能是不安全的。有 w397090770 4年前 (2020-06-19) 849℃ 0评论4喜欢
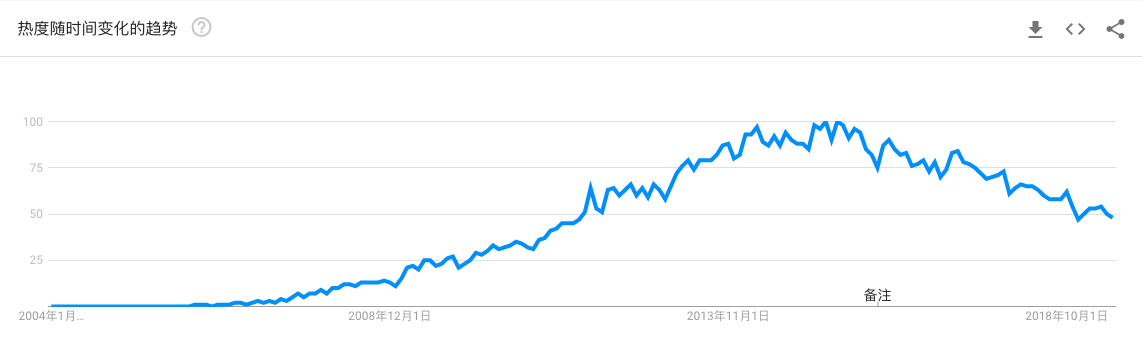
Hadoop我先从一个悲观的观点说起:Hadoop 正在迅速失去市场,我们可以从 Google 趋势走向看出这个现象:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop下面的炒作生命周期表也上面的趋势很类似:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop看起来 Hadoo w397090770 5年前 (2019-06-23) 3683℃ 0评论32喜欢
在Hive0.8开始支持Insert into语句,它的作用是在一个表格里面追加数据。标准语法语法如下:[code lang="sql"]用法一:INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;用法二:INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;[/code w397090770 11年前 (2013-10-30) 102119℃ 2评论69喜欢
为期三天的 SPARK + AI SUMMIT Europe 2019 于 2019年10月15日-17日荷兰首都阿姆斯特丹举行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。Spark+AI Summit Europe 2019 是欧洲最大的数据和机器学习会议,大约有1700多名数据科学家、工程师和分析师参加此次会议。本次会议的提议包括了A w397090770 5年前 (2019-11-01) 1034℃ 0评论1喜欢
ZooKeeper使用ACL来控制访问其znode(ZooKeeper的数据树的数据节点)。ACL的实现方式非常类似于UNIX文件的访问权限:它采用访问权限位 允许/禁止 对节点的各种操作以及能进行操作的范围。不同于UNIX权限的是,ZooKeeper的节点不局限于 用户(文件的拥有者),组和其他人(其它)这三个标准范围。ZooKeeper不具有znode的拥有者的概念。 w397090770 9年前 (2015-12-02) 7265℃ 1评论4喜欢
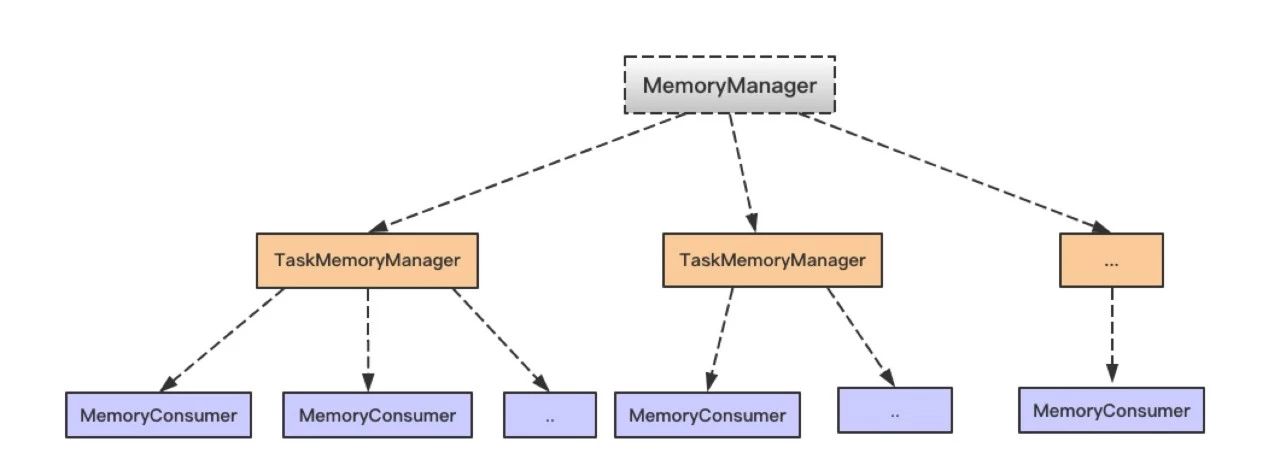
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段。那么在 Spark Shuffle 中具体是哪些地方会使用比较多的内存而有可能导致 OOM 呢? 为此,本文将围绕以上问题梳理 Spark 内存管理和 Shuffle 过程中与内存使用相关的知识;然后,简要分析下在 Spark Shuffle 中有可能导致 OOM w397090770 8年前 (2017-01-17) 807℃ 0评论1喜欢
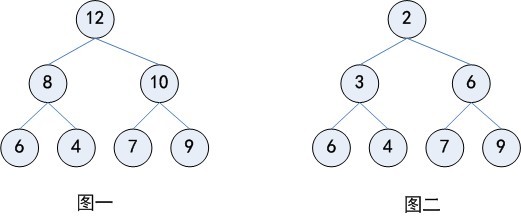
堆常用来实现优先队列,在这种队列中,待删除的元素为优先级最高(最低)的那个。在任何时候,任意优先元素都是可以插入到队列中去的,是计算机科学中一类特殊的数据结构的统称一、堆的定义最大(最小)堆是一棵每一个节点的键值都不小于(大于)其孩子(如果存在)的键值的树。大顶堆是一棵完全二叉树,同时也是 w397090770 12年前 (2013-04-01) 4864℃ 0评论3喜欢
一、百度(武汉地区)第一部分:1、描述数据库的简单操作。2、描述TCP\IP四层模型,并简述之。3、描述MVC的内容。第二部分:1、给出a-z0-9,在其中选择三个字符组成一个密码,输出全部的情况,程序实现。2、字符串的反转,比如abcde,输出edcba.3、许多程序会大量使用字符串。对于不同的字符串,我们希望能够 w397090770 12年前 (2013-04-15) 13371℃ 0评论9喜欢
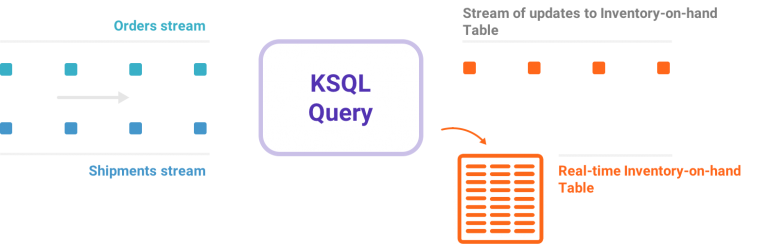
我非常高兴地宣布KSQL,这是面向Apache Kafka的一种数据流SQL引擎。KSQL降低了数据流处理这个领域的准入门槛,为使用Kafka处理数据提供了一种简单的、完全交互的SQL界面。你不再需要用Java或Python之类的编程语言编写代码了!KSQL具有这些特点:开源(采用Apache 2.0许可证)、分布式、可扩展、可靠、实时。它支持众多功能强大的数据流 w397090770 7年前 (2017-08-30) 7900℃ 0评论22喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第二篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 8年前 (2016-08-16) 5568℃ 0评论6喜欢
本文来自本人于2018年12月25日在 HBase生态+Spark社区钉钉大群直播,本群每周二下午18点-19点之间进行 HBase+Spark技术分享。加群地址:https://dwz.cn/Fvqv066s。本文 PPT 下载:关注 iteblog_hadoop 微信公众号,并回复 HBase_Rowkey 关键字获取。为什么Rowkey这么重要RowKey 到底是什么如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微 w397090770 6年前 (2018-12-25) 7431℃ 0评论29喜欢
相关文章:《Apache Flink 1.1.0和1.1.1发布,支持SQL》 Apache Flink 1.1.2于2016年09月05日正式发布,此版本主要是修复一些小bug,推荐所有使用Apache Flink 1.1.0以及Apache Flink 1.1.1的用户升级到此版本,我们可以在pom.xml文件引入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</a zz~~ 8年前 (2016-09-06) 1350℃ 0评论1喜欢
Monarch 是 Pinterest 的批处理平台,由30多个 Hadoop YARN 集群组成,其中17k+节点完全建立在 AWS EC2 之上。2021年初,Monarch 还在使用五年前的 Hadoop 2.7.1。由于同步社区分支(特性和bug修复)的复杂性不断增加,我们决定是时候进行版本升级了。我们最终选择了Hadoop 2.10.0,这是当时 Hadoop 2 的最新版本。本文分享 Pinterest 将 Monarch 升级到 Ha w397090770 2年前 (2022-08-12) 594℃ 0评论3喜欢













![Spark+AI Summit Europe 2019 高清视频下载[共135个]](https://www.iteblog.com/pic/spark/spark+ai_summit_europe_2019-iteblog.jpg)