《Spark Python API函数学习:pyspark API(1)》 《Spark Python API函数学习:pyspark API(2)》 《Spark Python API函数学习:pyspark API(3)》 《Spark Python API函数学习:pyspark API(4)》 Spark支持Scala、Java以及Python语言,本文将通过图片和简单例子来学习pyspark API。.wp-caption img{ max-width: 100%; height: auto;}如果想 w397090770 9年前 (2015-06-28) 36645℃ 0评论78喜欢
对RDD中的分区重新进行合并。函数原型[code lang="scala"]def coalesce(numPartitions: Int, shuffle: Boolean = false) (implicit ord: Ordering[T] = null): RDD[T][/code] 返回一个新的RDD,且该RDD的分区个数等于numPartitions个数。如果shuffle设置为true,则会进行shuffle。实例[code lang="scala"]/** * User: 过往记忆 * Date: 15-03-09 * Time: 上午0 w397090770 10年前 (2015-03-09) 14239℃ 1评论5喜欢
我们在《Tachyon 0.7.0伪分布式集群安装与测试》文章中介绍了如何搭建伪分布式Tachyon集群。从官方文档得知,Spark 1.4.x和Tachyon 0.6.4版本兼容,而最新版的Tachyon 0.7.1和Spark 1.5.x兼容,目前最新版的Spark为1.4.1,所以下面的操作步骤全部是基于Tachyon 0.6.4平台的,Tachyon 0.6.4的搭建步骤和Tachyon 0.7.0类似。 废话不多说,开始介绍吧 w397090770 9年前 (2015-08-31) 5473℃ 0评论6喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Best Practice in Accelerating Data Applications with Spark+Alluxio》的分享,作者来自 Alluxio 的 David Zhu。本次演讲将分享 Alluxio 和 Spark 集成解决方案的设计和用例,以及在设计和实现 Alluxio分 布式系统时的最佳实践以及不要做什么。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 w397090770 3年前 (2021-10-28) 551℃ 0评论1喜欢
rest 接口 现在我们已经有一个正常运行的节点(和集群),下一步就是要去理解怎样与其通信。幸运的是,Elasticsearch提供了非常全面和强大的REST API,利用这个REST API你可以同你的集群交互。下面是利用这个API,可以做的几件事情: 1、查你的集群、节点和索引的健康状态和各种统计信息 2、管理你的集群、节点、 zz~~ 8年前 (2016-08-31) 1427℃ 0评论2喜欢
本博客的《Spark与Mysql(JdbcRDD)整合开发》和《Spark RDD写入RMDB(Mysql)方法二》文章中介绍了如何通过Spark读写Mysql中的数据。 在生产环境下,很多公司都会使用PostgreSQL数据库,这篇文章将介绍如何通过Spark获取PostgreSQL中的数据。我将使用Spark 1.3中的DataFrame(也就是之前的SchemaRDD),我们可以通过SQLContext加载数据库中的数据, w397090770 9年前 (2015-05-23) 13001℃ 0评论11喜欢
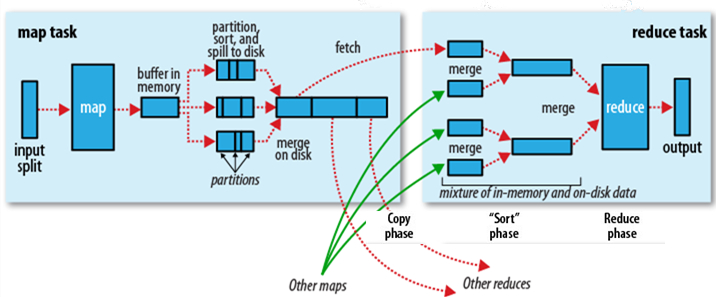
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方。要想理解MapReduce, Shuffle是必须要了解的。我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑,反而越搅越混。前段时间在做MapReduce job 性能调优的工作,需要深入代码研究MapReduce的运行机制,这才对Shuffle探了个究竟。考虑到之前我在看相关资料 w397090770 10年前 (2014-09-15) 16368℃ 7评论59喜欢
就在前几天,Apache Hadoop 3.0.0-beta1 正式发布了,这是3.0.0的第一个 beta 版本。本版本基于 3.0.0-alpha4 版本进行了Bug修复、性能提升以及其他一些加强。好消息是,这个版本之后会正式发行 Apache Hadoop 3.3.0 GA(General Availability,正式发布的版本)版本,这意味着我们就可以正式在线上使用 Hadoop 3.0.0 了!目前预计 Apache Hadoop 3.3.0 GA 将会在 201 w397090770 7年前 (2017-10-11) 2235℃ 0评论15喜欢
经过几天的折腾,终于配置好了Hadoop2.2.0(如何配置在Linux平台部署Hadoop请参见本博客《在Fedora上部署Hadoop2.2.0伪分布式平台》),今天主要来说说怎么在Hadoop2.2.0伪分布式上面运行我们写好的Mapreduce程序。先给出这个程序所依赖的Maven包:[code lang="JAVA"]<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> w397090770 11年前 (2013-10-29) 20357℃ 6评论10喜欢
谁说网站首次备案一定要关站?特别是网站运行了一段时间,搜索引擎等已经收录了网站内容,这时候如果关站一段时间(备案期间最长需要20个工作日,也就是一个月时间)会对网站产生很大的影响,比如网站被搜索引擎加黑,权重变低。这样的影响我们肯定不想要。 今天我想告诉大家的是其实在备案期间我们网站是可 w397090770 10年前 (2014-12-24) 4343℃ 3评论5喜欢
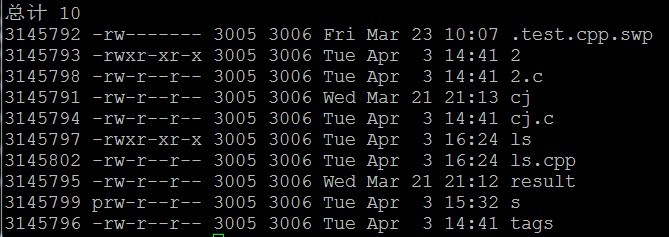
本程序用来仿照linux中的ls -l命令来实现的,主要运用的函数有opendir,readdir, lstat等。代码如下:[code lang="CPP"]#include <iostream>#include <vector>#include <cstdlib>#include <dirent.h>#include <sys/types.h>#include <sys/stat.h>#include <unistd.h>#include <cstring>#include <algorithm>using namespace std;void getFileAndDir(vector w397090770 12年前 (2013-04-04) 2649℃ 0评论0喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop回望过去10年,数据技术发展迅速,数据也在呈现爆炸式的增长,这也伴随着如下两个现象。一、数据更加分散:企业的数据是散落在不同的数据存储之中,如对象存储OSS,OLTP的MySQL,NoSQL的Mongo及HBase,以及数据仓库ADB之中,甚至是以服务的形式 w397090770 5年前 (2020-01-07) 1187℃ 0评论3喜欢
Hive内部提供了很多操作字符串的相关函数,本文将对其中部分常用的函数进行介绍。下表为Hive内置的字符串函数,具体的用法可以参见本文的下半部分。返回类型函数名描述intascii(string str)返回str第一个字符串的数值stringbase64(binary bin)将二进制参数转换为base64字符串 w397090770 9年前 (2016-04-24) 115959℃ 90喜欢
Thrift 最初由Facebook开发,目前已经开源到Apache,已广泛应用于业界。Thrift 正如其官方主页介绍的,“是一种可扩展、跨语言的服务开发框架”。简而言之,它主要用于各个服务之间的RPC通信,其服务端和客户端可以用不同的语言来开发。只需要依照IDL(Interface Description Language)定义一次接口,Thrift工具就能自动生成 C++, Java, Python, PH w397090770 8年前 (2016-06-30) 3698℃ 0评论7喜欢
我们在使用Hive的时候经常会使用到order by、Sort by、Distribute by和Cluster By,本文对其含义进行介绍。order by Hive中的order by和数据库中的order by 功能一致,按照某一项或者几项排序输出,可以指定是升序或者是降序排序。它保证全局有序,但是进行order by的时候是将所有的数据全部发送到一个Reduce中,所以在大数据量的情 w397090770 9年前 (2015-11-19) 14147℃ 0评论16喜欢
在这篇文章中,我将介绍如何在Spark中使用Akka-http并结合Cassandra实现REST服务,在这个系统中Cassandra用于数据的存储。 我们已经见识到Spark的威力,如果和Cassandra正确地结合可以实现更强大的系统。我们先创建一个build.sbt文件,内容如下:[code lang="scala"]name := "cassandra-spark-akka-http-starter-kit"version := "1.0" w397090770 8年前 (2016-10-17) 3867℃ 1评论5喜欢
Spark Data Source API是从Spark 1.2开始提供的,它提供了可插拔的机制来和各种结构化数据进行整合。Spark用户可以从多种数据源读取数据,比如Hive table、JSON文件、Parquet文件等等。我们也可以到http://spark-packages.org/(这个网站貌似现在不可以访问了)网站查看Spark支持的第三方数据源工具包。本文将介绍新的Spark数据源包,通过它我们 w397090770 9年前 (2015-10-21) 3870℃ 0评论4喜欢
大家对加州大学伯克利分校的AMPLab可能不太熟悉,但是它的项目我们都有所耳闻——没错,它就是Spark和Mesos的诞生之地。AMPLab是加州大学伯克利分校一个为期五年的计算机研究计划,其初衷是为了理解机器和人如何合作处理和解决数据中的问题——使用数据去训练更加丰富的模型,有效的数据清理,以及进行可衡量的数据扩展。 w397090770 8年前 (2017-02-09) 1320℃ 0评论3喜欢
本书由Vaibhav Kohli, Rajdeep Dua, John Wooten所著,全书共290页;Packt Publishing出版社于2017年03月出版。通过本书你将学习到以下的知识: 1、Install Docker ecosystem tools and services, Microservices and N-tier applications 2、Create re-usable, portable containers with help of automation tools 3、Network and inter-link containers 4、Attach volumes securely to containe zz~~ 8年前 (2017-04-05) 1875℃ 2评论7喜欢
在使用Spark streaming消费kafka数据时,程序异常中断的情况下发现会有数据丢失的风险,本文简单介绍如何解决这些问题。 在问题开始之前先解释下流处理中的几种可靠性语义: 1、At most once - 每条数据最多被处理一次(0次或1次),这种语义下会出现数据丢失的问题; 2、At least once - 每条数据最少被处理一次 (1 w397090770 8年前 (2016-07-26) 10905℃ 3评论17喜欢
PrestoCon 2021 于2021年12月09日通过在线的形式举办完了。在 PrestoCon,来自行业领先公司的用户分享了一些用例和最佳实践,Presto 开发人员讨论项目的特性;用户和开发人员将合作推进 Presto 的使用,将其作为一种高质量、高性能和可靠的软件,用于支持全球组织的分析平台,无论是在本地还是在云端。本次会议大概有20多个议题,干货 w397090770 3年前 (2021-12-19) 314℃ 0评论2喜欢
世界上大多数事物的发展规律是相似的,在最开始往往都会出现相对通用的方案解决绝大多数的问题,随后会出现为某一场景专门设计的解决方案,这些解决方案不能解决通用的问题,但是在某些具体的领域会有极其出色的表现。而在计算领域中,CPU(Central Processing Unit)和 GPU(Graphics Processing Unit)分别是通用的和特定的方案,前 zz~~ 3年前 (2021-09-24) 166℃ 0评论3喜欢
HDFS 架构介绍 HDFS离线存储平台是Hadoop大数据计算的底层架构,在B站应用已经超过5年的时间。经过多年的发展,HDFS存储平台目前已经发展成为总存储数据量近EB级,元数据总量近百亿级,NameSpace 数量近20组,节点数量近万台,日均吞吐几十PB数据量的大型分布式文件存储系统。 首先我们来介绍一下B站的HDFS离线存储平台的总体架 w397090770 3年前 (2022-04-01) 1088℃ 0评论4喜欢
本文来自上周(2020-11-17至2020-11-19)举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Spark SQL Beyond Official Documentation》的分享,作者 David Vrba,是 Socialbakers 的高级机器学习工程师。实现高效的 Spark 应用程序并获得最大的性能为目标,通常需要官方文档之外的知识。理解 Spark 的内部流程和特性有助于根据内部优化设计查询 w397090770 4年前 (2020-11-24) 1154℃ 0评论4喜欢
在《ASM 与 Presto 动态代码生成简介》这篇文章中,我们简单介绍了 Presto 动态代码生成的原理以及 Presto 在计算表达式的地方会使用到动态代码生成技术。为了加深理解,本文将以两个例子介绍 Presto 里面动态代码生成的使用。EmbedVersion我们往 Presto 提交 SQL 查询以及 TaskExecutor 启动 TaskRunner 执行 Task 的时候都会使用到 EmbedVersion 类 w397090770 3年前 (2021-10-12) 686℃ 0评论1喜欢
auto_ptr是这样一种指针:它是“它所指向的对象”的拥有者。这种拥有具有唯一性,即一个对象只能有一个拥有者,严禁一物二主。当auto_ptr指针被摧毁时,它所指向的对象也将被隐式销毁,即使程序中有异常发生,auto_ptr所指向的对象也将被销毁。设计动机在函数中通常要获得一些资源,执行完动作后,然后释放所获得的资源 w397090770 12年前 (2013-03-30) 2722℃ 0评论4喜欢
Apache Spark是目前非常强大的分布式计算框架。其简单易懂的计算框架使得我们很容易理解。虽然Spark是在操作大数据集上很有优势,但是它仍然需要将数据持久化存储,HDFS是最通用的选择,和Spark结合使用,因为它基于磁盘的特点,导致在实时应用程序中会影响性能(比如在Spark Streaming计算中)。而且Spark内置就不支持事务提交( w397090770 10年前 (2015-04-22) 10189℃ 0评论8喜欢
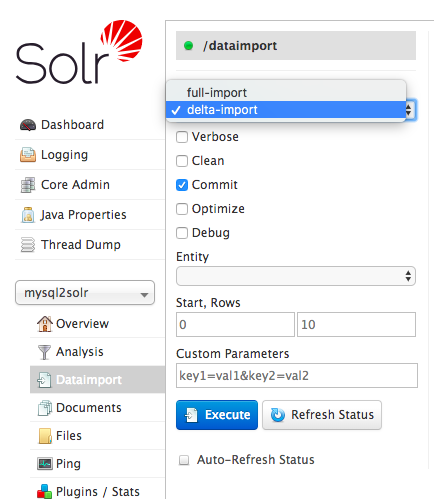
在 这篇 和 这篇 文章中我分别介绍了如何将 MySQL 的全量数据导入到 Apache Solr 中以及如何分页导入等,本篇文章将继续介绍如何将 MySQL 的增量数据导入到 Solr 中。增量导数接口为 deltaimport,对应的页面如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop如果我们使用 《将 MySQL 的全量 w397090770 6年前 (2018-08-18) 1625℃ 0评论3喜欢
将多个RDD中同一个Key对应的Value组合到一起。函数原型[code lang="scala"]def cogroup[W1, W2, W3](other1: RDD[(K, W1)], other2: RDD[(K, W2)], other3: RDD[(K, W3)], partitioner: Partitioner) : RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2], Iterable[W3]))] def cogroup[W1, W2, W3](other1: RDD[(K, W1)], other2: RDD[(K, W2)], other3: RDD[(K, W3)], numPartitions: Int) : RDD[(K w397090770 10年前 (2015-03-10) 17532℃ 0评论17喜欢
引言:十年沉淀、全球宽表排名第一、阿里云首发云Cassandra服务ApsaraDB for Cassandra是基于开源Apache Cassandra,融合阿里云数据库DBaaS能力的分布式NoSQL数据库。Cassandra已有10年+的沉淀,基于Amazon DynamoDB的分布式设计和 Google Bigtable 的数据模型。具备诸多优异特性:采用分布式架构、无中心、支持多活、弹性可扩展、高可用、容错、一 w397090770 5年前 (2019-09-05) 2153℃ 0评论4喜欢









![[电子书]Troubleshooting Docker PDF下载](https://www.iteblog.com/pic/books/Troubleshooting_Docker_iteblog.png)