本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-09-16) 119806℃ 4评论290喜欢
本程序实际上是构建了一颗二叉排序树,程序最后输出构建数的中序遍历。代码实现:[code lang="CPP"]#include <stdio.h>#include <stdlib.h>// Author: 过往记忆// Email: wyphao.2007@163.com// Blog: typedef int DataType; typedef struct BTree{ DataType data; struct BTree *Tleft; struct BTree *Tright; }*BTree;BTree CreateTree(); BTree insert(BTree root, DataTy w397090770 12年前 (2013-04-04) 3076℃ 0评论1喜欢
由于本文比较长,考虑到篇幅问题,所以将本文拆分为二,请阅读本文之前先阅读本文的第一部分《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(一)》。为你带来的不变,敬请谅解。 与MultipleOutputFormat类不一样的是,MultipleOutputs可以为不同的输出产生不同类型,到这里所说的MultipleOutputs类还是旧版本的功能,后 w397090770 11年前 (2013-11-27) 21509℃ 0评论17喜欢
该函数和aggregate类似,但操作的RDD是Pair类型的。Spark 1.1.0版本才正式引入该函数。官方文档定义:Aggregate the values of each key, using given combine functions and a neutral "zero value". This function can return a different result type, U, than the type of the values in this RDD, V. Thus, we need one operation for merging a V into a U and one operation for merging two U's, as in scala.Traversabl w397090770 10年前 (2015-03-02) 39606℃ 2评论35喜欢
我们在前面的 《Docker 入门教程:快速开始 》文章了解到镜像和容器的概念。本文将了解一下 Docker 的镜像分层(Layer)的概念,在 Docker 的官方文档对 Layer 的定义如下(参见这里):In an image, a layer is modification to the image, represented by an instruction in the Dockerfile. Layers are applied in sequence to the base image to create the final image. When an image is up w397090770 5年前 (2020-02-05) 1912℃ 0评论6喜欢
Apache Kafka在LinkedIn和其他公司中是作为各种数据管道和异步消息的后端。Netflix和Microsoft公司作为Kafka的重量级使用者(Four Comma Club,每天万亿级别的消息量),他们在Kafka Summit的分享也让人受益良多。 虽然Kafka有着极其稳定的架构,但是在每天万亿级别消息量的大规模下也会偶尔出现有趣的bug。在本篇文章以及以后的几篇 w397090770 8年前 (2016-07-20) 5305℃ 1评论6喜欢
今天谈谈Guava类库中的Multisets数据结构,虽然它不怎么经常用,但是还是有必要对它进行探讨。我们知道Java类库中的Set不能存放相同的元素,且里面的元素是无顺序的;而List是能存放相同的元素,而且是有顺序的。而今天要谈的Multisets是能存放相同的元素,但是元素之间的顺序是无序的。从这里也可以看出,Multisets肯定不是实 w397090770 11年前 (2013-07-11) 4670℃ 0评论1喜欢
背景 随着公司这两年业务的迅速扩增,业务数据量和数据处理需求也是呈几何式增长,这对底层的存储和计算等基础设施建设提出了较高的要求。本文围绕计算集群资源使用和资源调度展开,将带大家了解集群资源调度的整体过程、面临的问题,以及我们在底层所做的一系列开发优化工作。资源调度框架---YarnYarn的总体结 zz~~ 3年前 (2021-11-16) 550℃ 0评论0喜欢
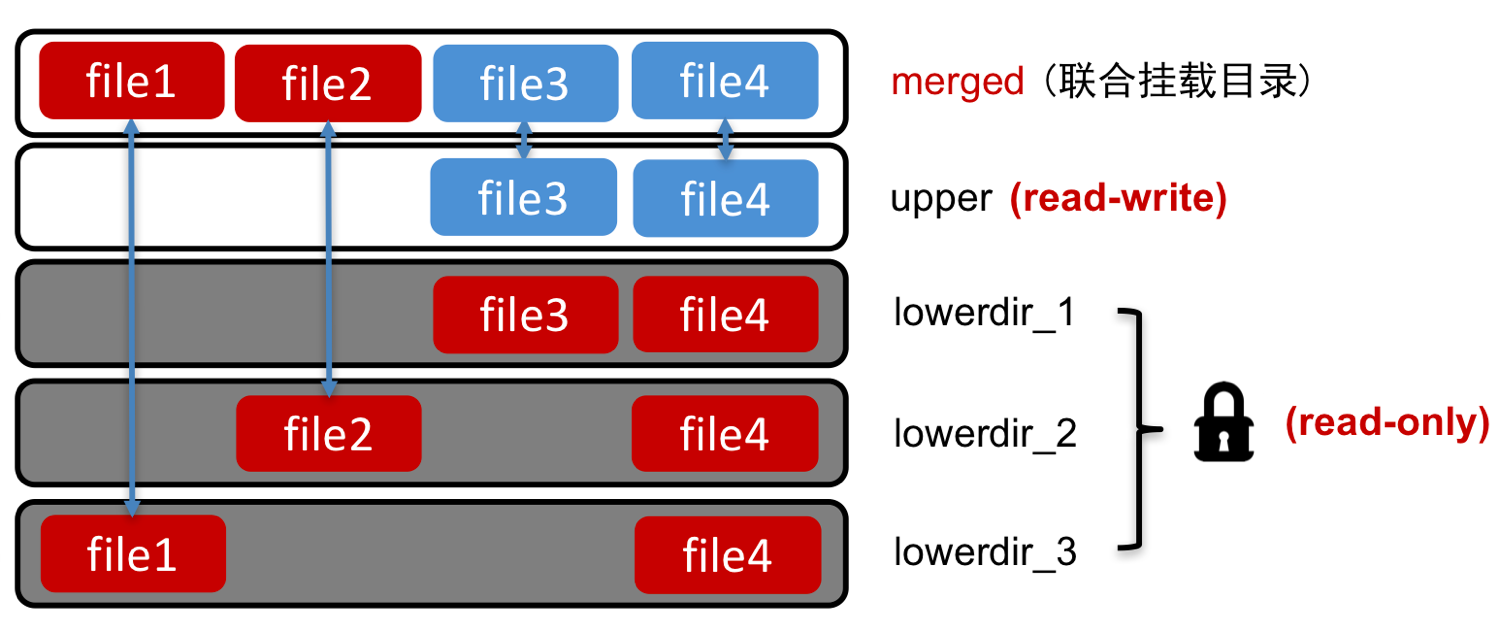
我们在前面 《Docker 入门教程:镜像分层》 文章中介绍了 Docker 为什么构建速度非常快,其原因就是采用了镜像分层,镜像分层底层采用的技术就是本文要介绍的 Union File System。Linux 支持多种 Union File System,比如 aufs、OverlayFS、ZFS 等。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众帐号:iteblog_hadoopaufs & OverlayF w397090770 5年前 (2020-02-09) 1255℃ 0评论4喜欢
原计划在2019年年底发布的 Apache Spark 3.0.0 今天终于赶在下周二举办的 Spark Summit AI 会议之前正式发布了! Apache Spark 3.0.0 自2018年10月02日开发到目前已经经历了近21个月!这个版本的发布经历了两个预览版以及三次投票:2019年11月06日第一次预览版,参见 https://spark.apache.org/news/spark-3.0.0-preview.html2019年12月23日第二次预览版,参见 https w397090770 4年前 (2020-06-18) 1832℃ 0评论4喜欢
随着Spark项目的逐渐成熟, 越来越多的可配置参数被添加到Spark中来。在Spark中提供了三个地方用于配置:Spark properties:这个可以控制应用程序的绝大部分属性。并且可以通过 SparkConf 对象或者Java 系统属性进行设置;环境变量(Environment variables):这个可以分别对每台机器进行相应的设置,比如IP。这个可以在每台机器的 $SPARK_HOME/co w397090770 10年前 (2014-09-24) 57160℃ 1评论22喜欢
一、 问答题1、简单描述如何安装配置一个apache开源版hadoop,只描述即可,无需列出完整步骤,能列出步骤更好。1) 安装JDK并配置环境变量(/etc/profile)2) 关闭防火墙3) 配置hosts文件,方便hadoop通过主机名访问(/etc/hosts)4) 设置ssh免密码登录5) 解压缩hadoop安装包,并配置环境变量6) 修改配置文件($HADOOP_HOME/conf)hadoop-e w397090770 8年前 (2016-08-26) 7946℃ 0评论14喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/好久没写Hive的那些事了,今 w397090770 11年前 (2014-02-19) 92554℃ 5评论132喜欢
Hive on Spark功能目前只增加下面九个参数,具体含义可以参见下面介绍。hive.spark.client.future.timeout Hive client请求Spark driver的超时时间,如果没有指定时间单位,默认就是秒。Expects a time value with unit (d/day, h/hour, m/min, s/sec, ms/msec, us/usec, ns/nsec), which is sec if not specified. Timeout for requests from Hive client to remote Spark driver.hive.spark.job.mo w397090770 9年前 (2015-12-07) 24550℃ 2评论11喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive最初是应Facebook每天 w397090770 11年前 (2013-12-18) 16844℃ 2评论31喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-15) 19376℃ 5评论10喜欢
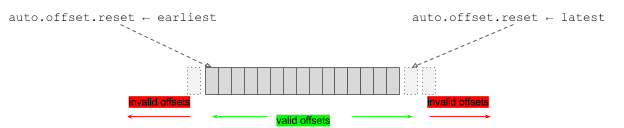
什么是数据迁移Apache Kafka 对于数据迁移的官方说法是分区重分配。即重新分配分区在集群的分布情况。官方提供了kafka-reassign-partitions.sh脚本来执行分区重分配操作。其底层实现主要有如下三步: 通过副本复制的机制将老节点上的分区搬迁到新的节点上。 然后再将Leader切换到新的节点。 最后删除老节点上的分区。重分 zz~~ 3年前 (2021-09-24) 847℃ 0评论5喜欢
这几天由于项目的需要,需要将Flume收集到的日志插入到Hbase中,有人说,这不很简单么?Flume里面自带了Hbase sink,可以直接调用啊,还用说么?是的,我在本博客的《Flume-1.4.0和Hbase-0.96.0整合》文章中就提到如何用Flume和Hbase整合,从文章中就看出整个过程不太复杂,直接做相应的配置就行了。那么为什么今天还要特意提一下Flum w397090770 11年前 (2014-01-27) 5145℃ 1评论1喜欢
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》 本文在上篇文章(《Kafka设计解析:Kafka High Availability(上)》)基础上,更加深入讲解了Kafka的HA机制,主要阐述了HA相关各种 w397090770 9年前 (2015-06-04) 4498℃ 0评论6喜欢
本书书名全名:Learning Spark Streaming:Best Practices for Scaling and Optimizing Apache Spark,于2017-06由 O'Reilly Media出版,作者 Francois Garillot, Gerard Maas,全书300页。本文提供的是本书的预览版。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Understand how Spark Streaming fits in the big pictureLearn c zz~~ 7年前 (2017-10-18) 6450℃ 0评论21喜欢
Apache Flink 1.1.4于2016年12月21日正式发布,本版本是Flink的最新稳定版本,主要以修复Bug为主;强烈推荐所有的用户升级到Flink 1.1.4版本,替换pom中的以为如下:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.1.4</version></dependency><dependency> & w397090770 8年前 (2016-12-27) 2339℃ 0评论3喜欢
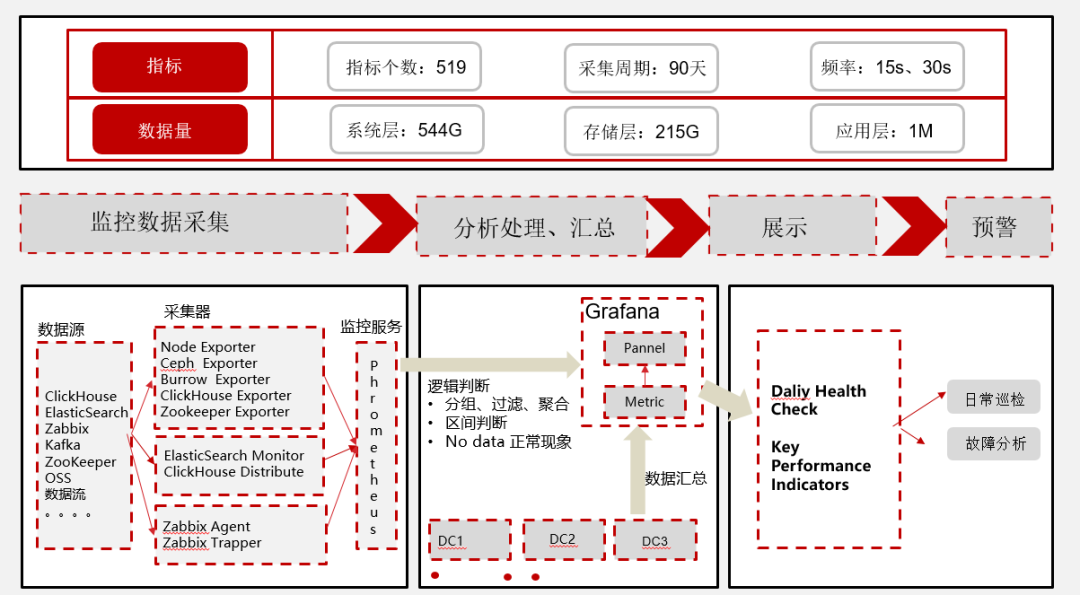
导语:随着互联网业务的迅速发展,用户对系统的要求也越来越高,而做好监控为系统保驾护航,能有效提高系统的可靠性、可用性及用户体验。监控系统是整个运维环节乃至整个项目及产品生命周期中最重要的一环。百分点大数据技术团队基于大数据平台项目,完成了百亿流量、约3000+台服务器集群规模的大数据平台服务的监控, zz~~ 3年前 (2021-09-24) 566℃ 0评论4喜欢
近日,红杏官方为了方便开发人员,公布了红杏公益版代理,该代理地址和端口为hx.gy:1080,可以在浏览器、IDE里面进行设置,并且访问很多常用的网站。目前支持的域名如下:[code lang="scala"]android.combitbucket.orgbintray.comchromium.orgclojars.orgregistry.cordova.iodartlang.orgdownload.eclipse.orggithub.comgithubusercontent.comgolang.orggoogl w397090770 10年前 (2015-04-15) 18250℃ 0评论22喜欢
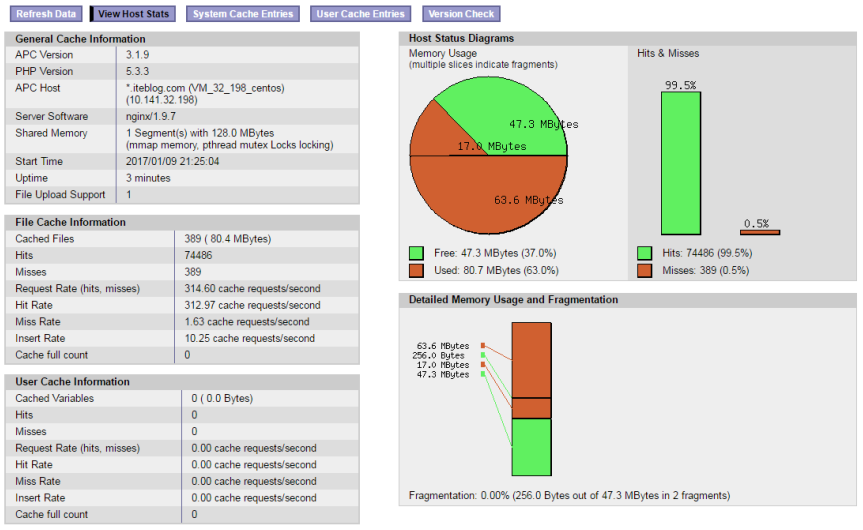
最近发现服务器php-fpm日志里面大量的Unable To Allocate Memory For Pool警告,如下:[code lang="bash"][09-Jan-2017 01:18:08] PHP Warning: require(): Unable to allocate memory for pool. in /data/web/iteblogbooks/wp-settings.php on line 220[09-Jan-2017 01:18:08] PHP Warning: require(): Unable to allocate memory for pool. in /data/web/iteblogbooks/wp-settings.php on line 221[09-Jan-2017 01:18:08] PHP Warning: re w397090770 8年前 (2017-01-09) 2174℃ 0评论4喜欢
这篇文章本来19年5月份就想写的,最终拖到今天才整理出来😂。Spark 内置给我们带来了非常丰富的各种优化,这些优化基本可以满足我们日常的需求。但是我们知道,现实场景中会有各种各样的需求,总有一些场景在 Spark 得到的执行计划不是最优的,社区的大佬肯定也知道这个问题,所以从 Spark 1.3.0 开始,Spark 为我们提供 w397090770 4年前 (2020-08-05) 1103℃ 2评论3喜欢
使用用户设置好的聚合函数对每个Key中的Value进行组合(combine)。可以将输入类型为RDD[(K, V)]转成成RDD[(K, C)]。函数原型[code lang="scala"]def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C) : RDD[(K, C)]def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitio w397090770 10年前 (2015-03-19) 22566℃ 0评论23喜欢
PhantomJS是一个基于WebKit的服务器端JavaScript API,它基于BSD开源协议发布。PhantomJS无需浏览器即可实现对Web的支持,且原生支持各种Web标准,如DOM处理、JavaScript、CSS选择器、JSON、Canvas和可缩放矢量图形SVG。PhantomJS主要是通过JavaScript和CoffeeScript控制WebKit的CSS选择器、可缩放矢量图形SVG和HTTP网络等各个模块。PhantomJS主要支持Windows、M w397090770 9年前 (2016-04-29) 4204℃ 0评论5喜欢
Apache Flink 1.10.0 于 2020年02月11日正式发布。Flink 1.10 是一个历时非常长、代码变动非常大的版本,也是 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。 w397090770 5年前 (2020-02-12) 3459℃ 0评论3喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 第四次北京Spark meeting会议 w397090770 10年前 (2014-12-16) 10337℃ 73评论8喜欢
spark.cleaner.ttl参数的原意是清除超过这个时间的所有RDD数据,以便腾出空间给后来的RDD使用。周期性清除保证在这个时间之前的元数据会被遗忘,对于那些运行了几小时或者几天的Spark作业(特别是Spark Streaming)设置这个是很有用的。注意:任何内存中的RDD只要过了这个时间就会被清除掉。官方文档是这么介绍的:Duration (secon w397090770 9年前 (2015-05-20) 8113℃ 0评论7喜欢













![[电子书]Learning Spark Streaming PDF下载](https://www.iteblog.com/pic/books/Learning_Spark_Streaming_iteblog.jpg)