本书由Vaibhav Kohli, Rajdeep Dua, John Wooten所著,全书共290页;Packt Publishing出版社于2017年03月出版。通过本书你将学习到以下的知识: 1、Install Docker ecosystem tools and services, Microservices and N-tier applications 2、Create re-usable, portable containers with help of automation tools 3、Network and inter-link containers 4、Attach volumes securely to containe zz~~ 8年前 (2017-04-05) 1875℃ 2评论7喜欢
在《Apache Solr 介绍及安装部署》 文章里面我简单地介绍了如何在 Linux 平台搭建单机版的 Solr 服务,而且我们已经创建了一个名为 iteblog 的 core,已经导入了相关的索引数据,接下来让我们来使用 Solr 检索这些数据。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop查询所有的数据可以使用 *:* w397090770 6年前 (2018-07-24) 1490℃ 0评论4喜欢
存储计算分离是整个行业的发展趋势,这种架构的存储和计算可以各自独立发展,它帮助云提供商降低成本。Presto 原生就支持这样的架构,数据可以从 Presto 服务器之外的远程存储节点传输过来。然而,存储计算分解也为查询延迟带来了新的挑战,因为当网络饱和时,通过网络扫描大量数据将受到 IO 限制。 此外,元数据的读取 w397090770 3年前 (2021-12-05) 765℃ 0评论2喜欢
第一题,基础题: 1. 数据库及线程产生死锁的原理和必要条件,如何避免死锁。 2. 列举面向对象程序设计的三个要素和五项基本原则。 3.Windows内存管理的方式有哪些?各自的优缺点。第二题,算法与程序设计: 1.公司举行羽毛球比赛,采用淘汰赛,有1001个人参加,要决出“羽毛球最高选手”,应如何组织这 w397090770 12年前 (2013-04-20) 9126℃ 0评论10喜欢
1、内存不够[code lang="JAVA"][ERROR] PermGen space -> [Help 1][ERROR] [ERROR] To see the full stack trace of the errors,re-run Maven with the -e switch.[ERROR] Re-run Maven using the -X switch to enable full debug logging.[ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles:[ERROR] [Help 1]http://cwiki.apache.org/confluence/display/MAVEN/OutOfMemoryErr w397090770 11年前 (2014-04-16) 15499℃ 4评论9喜欢
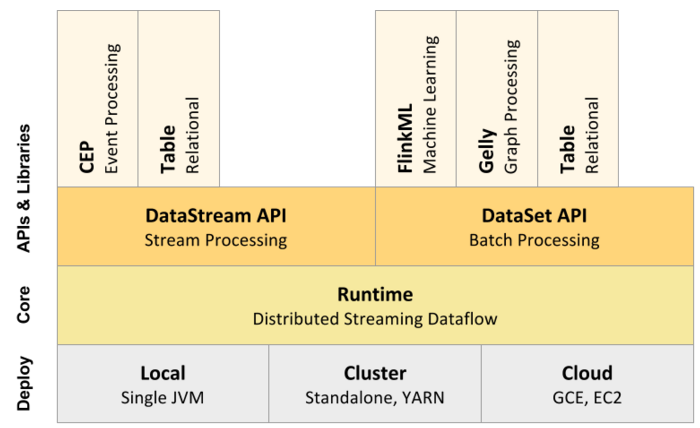
Apache Flink是一个高效、分布式、基于Java和Scala(主要是由Java实现)实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。 从Flink官方文档可以知道,目前Flink支持三大部署模式:Local、Cluster以及Cloud w397090770 9年前 (2016-03-30) 24213℃ 6评论22喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第三篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 8年前 (2016-08-17) 3685℃ 0评论3喜欢
摘要:本文整理自快手实时计算团队技术专家张静、张芒在 Flink Forward Asia 2021 的分享。主要内容包括: Flink SQL 在快手功能扩展性能优化稳定性提升未来展望 一、Flink SQL 在快手 经过一年多的推广,快手内部用户对 Flink SQL 的认可度逐渐提高,今年新增的 Flink 作业中,SQL 作业达到了 60%,与去年相比有了一倍的提升,峰值吞吐 w397090770 3年前 (2022-02-18) 1009℃ 0评论4喜欢
本文节选自《大数据之路:阿里巴巴大数据实践》,关注 iteblog_hadoop 公众号并在这篇文章里面文末评论区留言(认真写评论,增加上榜的机会)。留言点赞数排名前5名的粉丝,各免费赠送一本《大数据之路:阿里巴巴大数据实践》,活动截止至08月11日18:00。这篇文章评论区留言才有资格参加送书活动:https://mp.weixin.qq.com/s/BR7M8Rty w397090770 7年前 (2017-08-03) 1681℃ 0评论11喜欢
最近在做给博客添加上传PDF的功能,但是在测试上传文件的过程中遇到了413 Request Entity Too Large错误。不过这个无错误是很好解决的,这个错误的出现是因为上传的文件大小超过了Nginx和PHP的配置,我们可以通过以下的方法来解决:一、设置PHP上传文件大小限制 PHP默认的文件上传大小是2M,我们可以通过修改php.ini里面的 w397090770 9年前 (2015-08-17) 20759℃ 0评论6喜欢
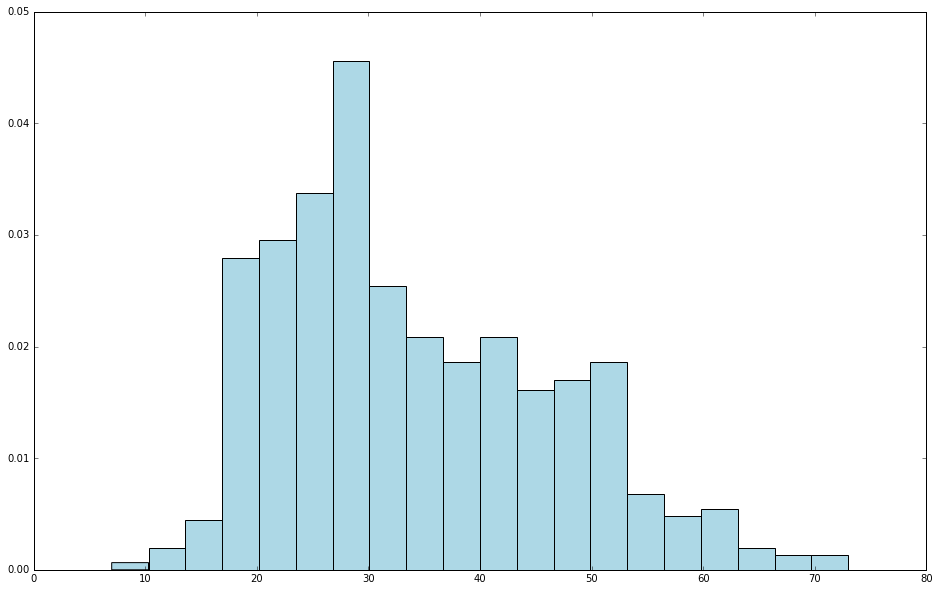
最近在使用 Python 学习 Spark,使用了 jupyter notebook,期间使用到 hist 来绘图,代码很简单如下:[code lang="python"]user_data = sc.textFile("/home/iteblog/ml-100k/u.user")user_fields = user_data.map(lambda line: line.split("|"))ages = user_fields.map(lambda x: int(x[1])).collect()hist(ages, bins=20, color='lightblue', normed=True)fig = matplotlib.pyplot.gcf()fig.set_size_inch w397090770 7年前 (2017-12-04) 4663℃ 0评论19喜欢
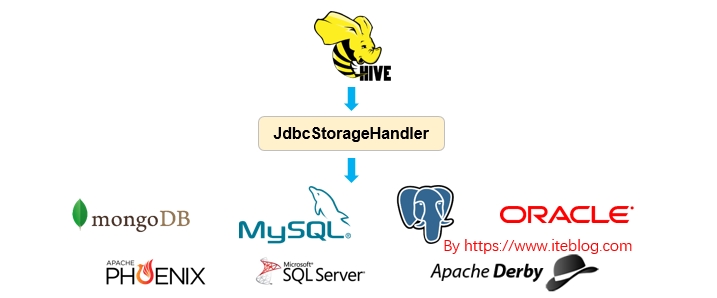
如今,很多公司可能会在内部使用多种数据存储和处理系统。这些不同的系统解决了对应的使用案例。除了传统的 RDBMS (比如 Oracle DB,Teradata或PostgreSQL) 之外,我们还会使用 Apache Kafka 来获取流和事件数据。使用 Apache Druid 处理实时系列数据(real-time series data),使用 Apache Phoenix 进行快速索引查找。 此外,我们还可能使用云存储 w397090770 6年前 (2019-03-16) 5146℃ 1评论8喜欢
Hadoop集群的监控可以通过多种方式来实现(比如REST API、jmx、内置API等等)。虽然监控方式有多种,但是我们需要根据监控的指标选择不同的监控方式,比如如果你想监控作业的情况,那么你选择jmx是不能满足的;你想监控各节点的运行情况,REST API也是不能满足的。所以在选择不同当时监控时,我们需要详细了解需要我们的需 w397090770 8年前 (2016-06-23) 21253℃ 0评论34喜欢
在2020年6月24日的 Spark AI summit Keynote 上,数砖的首席执行官 Ali Ghodsi 宣布其收购了 Redash 开源产品的背后公司 Redash!如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop通过这次收购,Redash 加入了 Apache Spark、Delta Lake 和 MLflow,创建了一个更大、更繁荣的开源系统,为数据团队提供了同类中最好的 w397090770 4年前 (2020-06-26) 943℃ 0评论3喜欢
Material-UI是实现了Google Material模式的CSS框架,其中包括了一系列的React组建。Material Design是2014年Google I/O发布的 势必将会成为统一 Android Mobile、Android Table、Desktop Chrome 等全平台设计语言规范,对从业人员意义重大。 为了更好地使用这个框架,推荐大家先了解一下React Library,然后再使用Material-UI。如果想及时了解Spark、H w397090770 10年前 (2015-05-02) 11325℃ 1评论14喜欢
我在《在Kafka中使用Avro编码消息:Producter篇》文章中简单介绍了如何发送 Avro 类型的消息到 Kafka。本文接着上文介绍如何从 Kafka 读取 Avro 格式的消息。关于 Avro 我这就不再介绍了。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop从 Kafka 中读取 Avro 格式的消息从 Kafka 中读取 Avro 格式的消 w397090770 7年前 (2017-09-25) 6363℃ 0评论16喜欢
一、前提条件 1、安装好Java JDK 1.6或以上版本; 2、安装好Apache Maven。 如果上述条件准备好之后,下面开始用Maven编译Mahout源码二、git一份Mahout源码 用下面的命令从 Mahout GitHub 仓库Git(如果你电脑没有安装Git软件,可以参照这个安装《Git安装》)一份代码到本地[code lang="JAVA"]git clone git@github.com:apache/mahout.git w397090770 10年前 (2014-09-16) 6209℃ 0评论3喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 125.117.130.174 9000 高匿名 HTTP w397090770 9年前 (2015-05-13) 46383℃ 0评论0喜欢
io.file.buffer.size hadoop访问文件的IO操作都需要通过代码库。因此,在很多情况下,io.file.buffer.size都被用来设置缓存的大小。不论是对硬盘或者是网络操作来讲,较大的缓存都可以提供更高的数据传输,但这也就意味着更大的内存消耗和延迟。这个参数要设置为系统页面大小的倍数,以byte为单位,默认值是4KB,一般情况下,可以 w397090770 11年前 (2014-04-01) 30292℃ 2评论14喜欢
SPARK SUMMIT 2015会议于美国时间2015年06月15日到2015年06月17日在San Francisco(旧金山)进行,目前PPT已经全部公布了,不过很遗憾的是这个网站被墙了,无法直接访问,本博客将这些PPT全部整理免费下载。由于源网站限制,一天只能只能下载20个PPT,所以我只能一天分享20篇。如果想获取全部的PPT,请关站本博客。会议主旨 T w397090770 9年前 (2015-06-26) 4298℃ 0评论6喜欢
随着图像分类(image classification)和对象检测(object detection)的深度学习框架的最新进展,开发者对 Apache Spark 中标准图像处理的需求变得越来越大。图像处理和预处理有其特定的挑战 - 比如,图像有不同的格式(例如,jpeg,png等),大小和颜色,并且没有简单的方法来测试正确性。图像数据源通过给我们提供可以编码的标准表 w397090770 6年前 (2018-12-13) 2438℃ 0评论4喜欢
《Apache Spark 2.0重大功能介绍》:/archives/1721 《Apache Spark作为编译器:深入介绍新的Tungsten执行引擎》:/archives/1679 《Spark 2.0技术预览:更容易、更快速、更智能》:/archives/1668 Apache Spark 2.0.0于2016-07-27正式发布。它是2.x版本线上的第一个版本。主要的更新是API可用性,SQL 2003的支持,性能提升,structured streaming w397090770 8年前 (2016-07-27) 7608℃ 4评论7喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 9年前 (2015-05-15) 4811℃ 0评论3喜欢
Elasticsearch 6.3 于前天正式发布,其中带来了很多新特性,详情请参见:https://www.elastic.co/blog/elasticsearch-6-3-0-released。这个版本最大的亮点莫过于内置支持 SQL 模块!我在早些时间就说过 Elasticsearch 将会内置支持 SQL,参见:ElasticSearch内置也将支持SQL特性。我们可以像操作 MySQL一样使用 Elasticsearch,这样我们就可以减少 DSL 的学习成本, w397090770 6年前 (2018-06-15) 8949℃ 3评论14喜欢
历时一个多月的投票和补丁修复,Apache Spark 1.6.0于今天凌晨正式发布。Spark 1.6.0是1.x线上第七个发行版.本发行版有来自248+的贡献者参与。详细邮件如下:Hi All,Spark 1.6.0 is the seventh release on the 1.x line. This release includes patches from 248+ contributors! To download Spark 1.6.0 visit the downloads page. (It may take a while for all mirrors to update.)A huge t w397090770 9年前 (2016-01-05) 2971℃ 1评论5喜欢
Scala又一强大的功能就是可以以脚本的形式运行。我们可以创建一个测试文件iteblog.sh,内容如下:[code lang="scala"]#!/bin/shexec scala "$0" "$@"!#println("Hello, Welcome to !")[/code]然后我们就可以下面之一的方式运行这个Scala脚本:[code lang="scala"][iteblog@www.iteblog.com iteblog]$ sh scala.sh Hello, Welcome to ![/code] w397090770 9年前 (2015-12-11) 5690℃ 0评论8喜欢
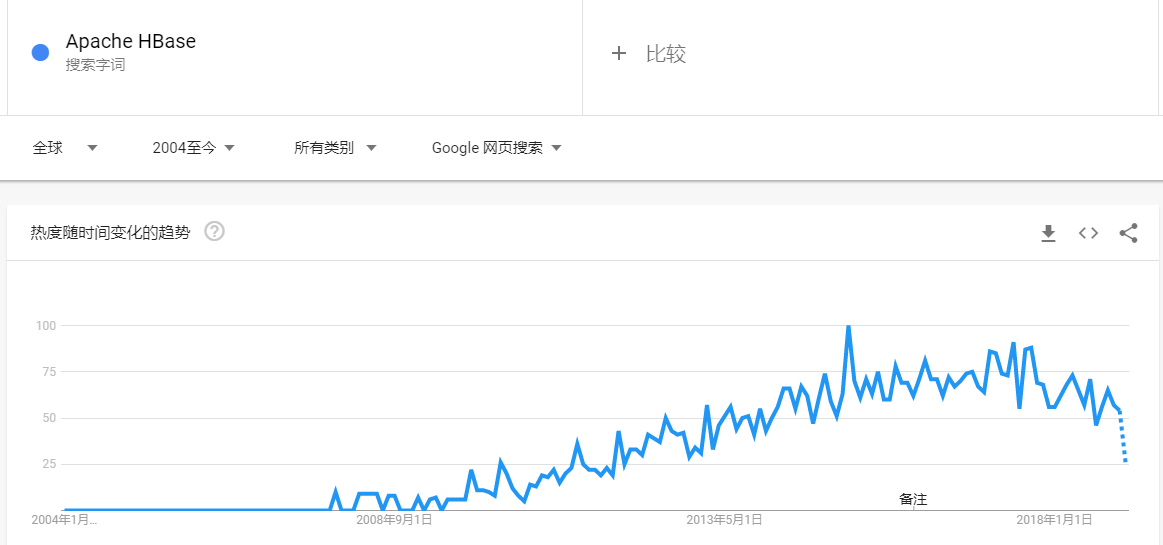
Apache HBase是基于Hadoop构建的一个分布式的、可伸缩的海量数据存储系统。随着时间的推移,HBase目前不管是在国内还是国外都受到了非常大的欢迎,以下分别是近几年 Google 和百度关于 HBase 的搜索趋势:Google如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop大家可以看到,整体趋势是越来越 w397090770 6年前 (2019-01-05) 3549℃ 4评论15喜欢
Spark 1.2.2和Spark 1.3.1于美国时间2015年4月17日同时发布。两个都是维护版本,并推荐所有1.3和1.2的Spark使用用户升级到相应的版本。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopspark 1.2.2(稳定版本) spark 1.2.2主要是维护版本,修复了许多Bug,是基于Spark 1.2的分支。并推荐所有使用1. w397090770 10年前 (2015-04-18) 5187℃ 0评论3喜欢
一. 问答题1) datanode在什么情况下不会备份?2) hdfs的体系结构?3) sqoop在导入数据到mysql时,如何让数据不重复导入?如果存在数据问题sqoop如何处理?4) 请列举曾经修改过的/etc下的配置文件,并说明修改要解决的问题?5) 描述一下hadoop中,有哪些地方使用了缓存机制,作用分别是什么?二. 计算题1、使用Hive或 w397090770 8年前 (2016-08-26) 4265℃ 1评论4喜欢
Java 8 给我们带来了一个新功能,也就是本文要介绍的 Stream API,它可以让我们以一种声明的方式处理数据。Stream 使用一种类似用 SQL 的语法来提供一种对 Java 集合运算和表达的高阶抽象。极大提高 Java 程序员的生产力,让程序员写出高效率、干净、简洁的代码。本文是 Java 8 Stream API 入门序列文章第一篇,将带领大家快速入门 Java 8 St w397090770 5年前 (2020-02-01) 513℃ 0评论3喜欢