我目前使用的Hive版本是apache-hive-1.2.0-bin,每次在使用 show create table 语句的时候如果你字段中有中文注释,那么Hive得出来的结果如下:hive> show create table iteblog;OKCREATE TABLE `iteblog`( `id` bigint COMMENT '�id', `uid` bigint COMMENT '(7id', `name` string COMMENT '(7�')ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTF w397090770 8年前 (2016-06-08) 11284℃ 0评论13喜欢
在《Apache Solr 介绍及安装部署》 文章里面我简单地介绍了如何在 Linux 平台搭建单机版的 Solr 服务,而且我们已经创建了一个名为 iteblog 的 core,已经导入了相关的索引数据,接下来让我们来使用 Solr 检索这些数据。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop查询所有的数据可以使用 *:* w397090770 6年前 (2018-07-24) 1490℃ 0评论4喜欢
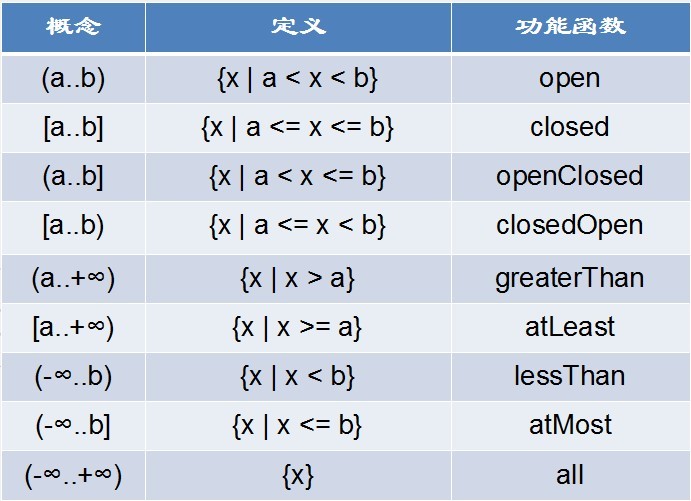
在Guava中新增了一个新的类型Range,从名字就可以了解到,这个是和区间有关的数据结构。从Google官方文档可以得到定义:Range定义了连续跨度的范围边界,这个连续跨度是一个可以比较的类型(Comparable type)。比如1到100之间的整型数据。不过我们无法遍历出这个区间里面的值。如果需要达到这个目的,我们可以将这个范围传给Conti w397090770 11年前 (2013-07-15) 5346℃ 0评论4喜欢
一.问答题1、map方法是如何调用reduce方法的?2、fsimage和edit的区别?3、hadoop1和hadoop2的区别?4、列举几个配置文件优化?5、写出你对zookeeper的理解6、datanode首次加入cluster的时候,如果log报告不兼容文件版本,那需要namenode执行格式化操作,这样处理的原因是?7、hbase 集群安装注意事项二. 思考题1. linux w397090770 8年前 (2016-08-26) 3163℃ 0评论1喜欢
随着网站的文章越来越多,网站的图片也不知不觉的多了起来,图片多起来带来的问题就是访问的人多的时候会导致页面加载速度越来越慢,这严重影响了网站的用户体验,所以网站图片异步加载势在必行。 图片异步加载就是图片只有在视野范围内才加载,没出现在范围内的图片就暂不加载,等用户滑动滚动条时再逐步 w397090770 8年前 (2016-07-08) 3443℃ 0评论7喜欢
我们通过分析从2015年1月至5月下载次数最多的R包,列出了前20名流行的机器学习R包。 大多数R包都深受Kagglers大神的最爱,也被资深的笔者所赞美,而这些包的使用率或评价高低不仅仅取决于其它的包对于这个 这个包的依赖程度。还也取决于Crantastic.org并使用其众包能解决方案的用户。但是,用户评价太低以至于不 w397090770 8年前 (2016-07-17) 3830℃ 0评论5喜欢
MMLSpark为Apache Spark提供了大量深度学习和数据科学工具,包括将Spark Machine Learning管道与Microsoft Cognitive Toolkit(CNTK)和OpenCV进行无缝集成,使您能够快速创建功能强大,高度可扩展的大型图像和文本数据集分析预测模型。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopMMLSpark需要Scala 2.11,Spark 2 w397090770 7年前 (2017-10-24) 4188℃ 0评论9喜欢
Zomato 是一家食品订购、外卖及餐馆发现平台,被称为印度版的“大众点评”。目前,该公司的业务覆盖全球24个国家(主要是印度,东南亚和中东市场)。本文将介绍该公司的 Food Feed 业务是如何从 Redis 迁移到 Cassandra 的。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoopFood Feed 是 Zomato 社交场景 w397090770 5年前 (2019-09-08) 1128℃ 0评论2喜欢
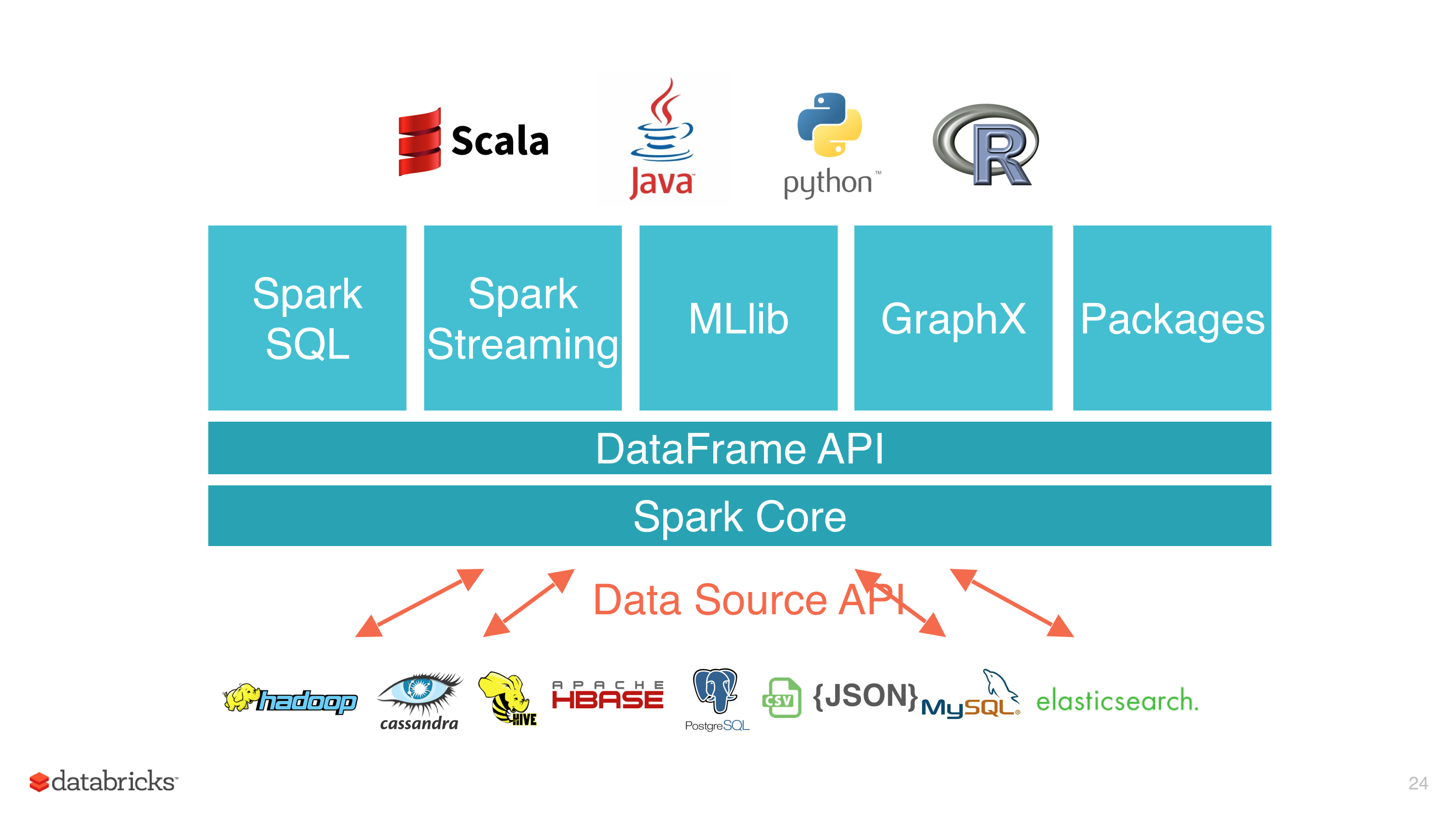
Data Source API 定义如何从存储系统进行读写的相关 API 接口,比如 Hadoop 的 InputFormat/OutputFormat,Hive 的 Serde 等。这些 API 非常适合用户在 Spark 中使用 RDD 编程的时候使用。使用这些 API 进行编程虽然能够解决我们的问题,但是对用户来说使用成本还是挺高的,而且 Spark 也不能对其进行优化。为了解决这些问题,Spark 1.3 版本开始引入了 D w397090770 5年前 (2019-08-13) 3503℃ 0评论3喜欢
《Kafka: The Definitive Guide, 2nd Edition》于 2021年11月由 O'Reilly Media 出版, ISBN 为 9781492043089 ,全书 486 页。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop图书介绍Every enterprise application creates data, whether it consists of log messages, metrics, user activity, or outgoing messages. Moving all this data is just as important as the w397090770 3年前 (2022-03-22) 1176℃ 0评论4喜欢
相关文章:《Apache Flink 1.1.0和1.1.1发布,支持SQL》 Apache Flink 1.1.2于2016年09月05日正式发布,此版本主要是修复一些小bug,推荐所有使用Apache Flink 1.1.0以及Apache Flink 1.1.1的用户升级到此版本,我们可以在pom.xml文件引入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</a zz~~ 8年前 (2016-09-06) 1350℃ 0评论1喜欢
一、简介1.14 新版本原本规划有 35 个比较重要的新特性以及优化工作,目前已经有 26 个工作完成;5 个任务不确定是否能准时完成;另外 4 个特性由于时间或者本身设计上的原因,会放到后续版本完成。[1]如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据1.14 相对于历届版本来说,囊 w397090770 3年前 (2021-09-02) 693℃ 0评论4喜欢
导读:本文主要介绍Flink实时计算在bilibili的优化,将从以下四个方面展开: 1、Flink-connector稳定性优化 2、Flink sql优化 3、Flink-runtime优化 4、对未来的展望 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据 概述首先介绍下Flink实时计算在b站的应用场景。在b站,Flink on yarn w397090770 3年前 (2021-09-23) 851℃ 0评论4喜欢
Apache Kafka 2.6.0 于2020年08月03日正式发布。在这个版本中,社区做了很多显著的性能改进,特别是当 Broker 有非常多的分区时。Broker 关闭性能得到了显著提高;当生产者使用压缩时,性能也得到了显著提高。ACL 使用的各个方面都有不同程度的提升,并且需要更少的内存。这个版本还增加了对 Java 14 的支持。在过去的几个版本中,社 w397090770 4年前 (2020-08-23) 882℃ 0评论0喜欢
我在 这篇 文章中介绍了 Apache Spark 3.0 动态分区裁剪(Dynamic Partition Pruning),里面涉及到动态分区的优化思路等,但是并没有涉及到如何使用,本文将介绍在什么情况下会启用动态分区裁剪。并不是什么查询都会启用动态裁剪优化的,必须满足以下几个条件:spark.sql.optimizer.dynamicPartitionPruning.enabled 参数必须设置为 true,不过这 w397090770 5年前 (2019-11-08) 2304℃ 0评论3喜欢
最近在做给博客添加上传PDF的功能,但是在测试上传文件的过程中遇到了413 Request Entity Too Large错误。不过这个无错误是很好解决的,这个错误的出现是因为上传的文件大小超过了Nginx和PHP的配置,我们可以通过以下的方法来解决:一、设置PHP上传文件大小限制 PHP默认的文件上传大小是2M,我们可以通过修改php.ini里面的 w397090770 9年前 (2015-08-17) 20759℃ 0评论6喜欢
[caption id="attachment_762" align="aligncenter" width="442"] Guava学习之AbstractSortedSetMultimap[/caption] AbstractSortedSetMultimap是一个抽象类,其继承关系如上所示,关于AbstractSetMultimap和SortedSetMultimap的介绍分别在《Guava学习之AbstractSetMultimap》和《Gauva学习之SortedSetMultimap》,这里就不再介绍了。AbstractSortedSetMultimap类是SortedSetMultimap的基本实现,不过A w397090770 11年前 (2013-09-29) 3172℃ 0评论4喜欢
ScalikeJDBC是一款给Scala开发者使用的简洁DB访问类库,它是基于SQL的,使用者只需要关注SQL逻辑的编写,所有的数据库操作都交给ScalikeJDBC。这个类库内置包含了JDBC API,并且给用户提供了简单易用并且非常灵活的API。并且,QueryDSL使你的代码类型安全的并且可重复使用。我们可以在生产环境大胆地使用这款DB访问类库。工作 w397090770 9年前 (2016-03-10) 4291℃ 0评论4喜欢
当前数据湖方向非常热门,市面上也出现了三款开源的数据湖产品:Delta Lake、Apache Hudi 以及 Apache Iceberg。这段时间抽了点时间看了下使用 Apache Spark 读写 Apache Iceberg 的代码。完全看代码肯定有些吃力,所以使用了代码调试功能。由于 Apache Iceberg 支持 Apache Spark 2.x 以及 3.x,并在创建了不同的模块。其相当于 Spark 的 Connect。Apache Spa w397090770 4年前 (2020-10-04) 1798℃ 0评论3喜欢
AdminLTE是一个完全响应式管理并基于Bootstrap 3.x的免费高级管理控制面板主题。高度可定制的,易于使用。自适应多种屏幕分辨率,兼容PC端和手机移动端,内置了多个模板页面,包括仪表盘、邮箱、日历、锁屏、登录及注册、404错误、500错误等页面。AdminLTE是基于模块化设计,很容易在其之上定制和重制。本文撰写的时候AdminLTE w397090770 8年前 (2016-07-17) 18602℃ 0评论24喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-17) 9609℃ 6评论6喜欢
Apache Hadoop 2.7.0发布。一共修复了来自社区的535个JIRAs,其中:Hadoop Common有160个;HDFS有192个;YARN有148个;MapReduce有35个。Hadoop 2.7.0是2015年第一个Hadoop release版本,不过需要注意的是 (1)、不要将Hadoop 2.7.0用于生产环境,因为一些关键Bug还在测试中,如果需要在生产环境使用,需要等Hadoop 2.7.1/2.7.2,这些版本很快会发布。 w397090770 10年前 (2015-04-24) 8837℃ 0评论14喜欢
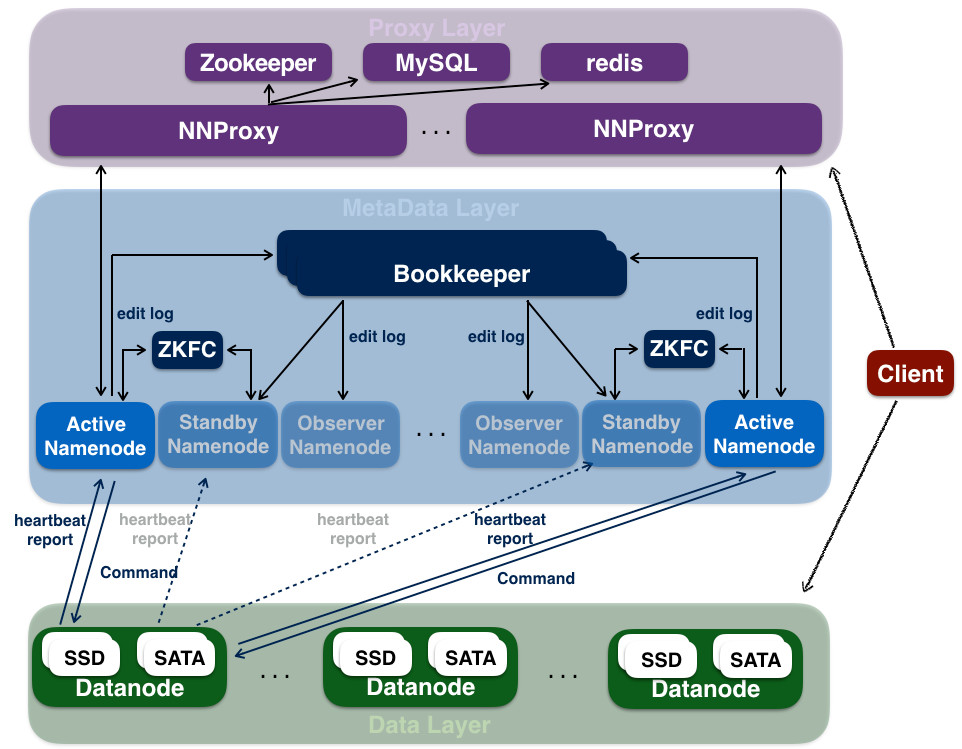
HDFS 简介因为 HDFS 这样一个系统已经存在了非常长的时间,应用的场景已经非常成熟了,所以这部分我们会比较简单地介绍。HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:和本地文件系统一样的目录树视图Append Only 的写入(不支持 w397090770 5年前 (2020-01-10) 2382℃ 0评论4喜欢
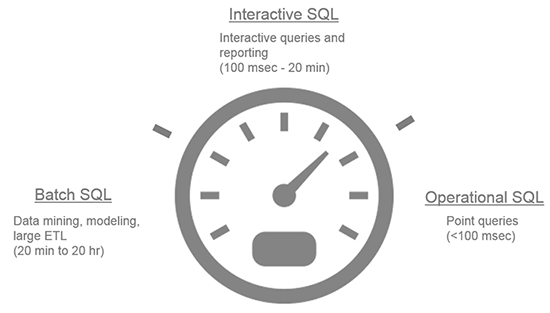
以下文章是转载自国外网站,介绍了Hadoop生态系统上面的几种SQL:Hive、Drill、Impala、Presto以及Spark\Shark等应用场景、对比以及一些结论Within the big data landscape there are multiple approaches to accessing, analyzing, and manipulating data in Hadoop. Each depends on key considerations such as latency, ANSI SQL completeness (and the ability to tolerate machine-generated SQL), developer and a w397090770 10年前 (2014-08-11) 9892℃ 0评论14喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop假设我们有以下表:[code lang="scala"]scala> spark.sql("""CREATE TABLE iteblog_test (name STRING, id int) using orc PARTITIONED BY (id)""").show(100)[/code]我们往里面插入一些数据:[code lang="sql"]scala> spark.sql("insert into table iteblog_test select w397090770 4年前 (2020-08-03) 3256℃ 0评论4喜欢
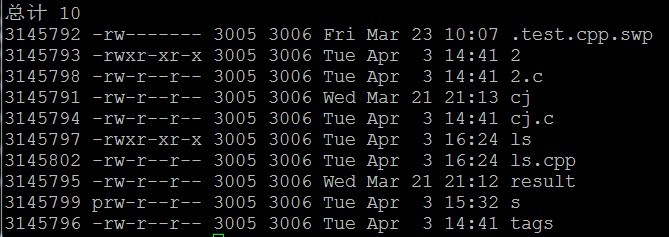
本程序用来仿照linux中的ls -l命令来实现的,主要运用的函数有opendir,readdir, lstat等。代码如下:[code lang="CPP"]#include <iostream>#include <vector>#include <cstdlib>#include <dirent.h>#include <sys/types.h>#include <sys/stat.h>#include <unistd.h>#include <cstring>#include <algorithm>using namespace std;void getFileAndDir(vector w397090770 12年前 (2013-04-04) 2649℃ 0评论0喜欢
我下载的Apache Zeppelin和Apache Spark版本分别为:0.6.0-incubating-SNAPSHOT和1.5.2,在Zeppelin中使用SQLContext读取Json文件创建DataFrame的过程中出现了以下的异常:[code lanh="scala"]val profilesJsonRdd =sqlc.jsonFile("hdfs://www.iteblog.com/tmp/json")val profileDF=profilesJsonRdd.toDF()profileDF.printSchema()profileDF.show()profileDF.registerTempTable("profiles") w397090770 9年前 (2016-01-21) 6845℃ 2评论11喜欢
我们在开发过程中,难免会进行一些误操作,比如下面我们提交 723cc1e commit 的时候把 2b27deb 和 0ff665e 不小心也提交到这个分支了。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据0ff665e 是属于其他还没有合并到 master 分支的 MR,所以我们这里肯定不能把它带上来。我们需要把它删了。值得 w397090770 3年前 (2021-07-09) 581℃ 0评论1喜欢
本系列文章翻译自:《scala data analysis cookbook》第二章:Getting Started with Apache Spark DataFrames。原书是基于Spark 1.4.1编写的,我这里使用的是Spark 1.6.0,丢弃了一些已经标记为遗弃的函数。并且修正了其中的错误。 一、从csv文件创建DataFrame 如何做? 如何工作的 附录 二、操作DataFrame w397090770 9年前 (2016-01-16) 6559℃ 0评论16喜欢
在昨天我谈到了WSDL的一些概念,今天打算谈谈为什么理解WSDL非常重要。 许多用户可能会提到的一个问题是,既然WSDL文件可以在各种主要的平台上使用工具创建,为什么还要花时间学习WSDL呢?这是因为WSDL文档非常新,学习其内容和工作原理是明智的。由于Web服务正在变得无所不在,所以,理解和掌握WSDL文档的必要性越来 w397090770 12年前 (2013-04-25) 3098℃ 1评论2喜欢