《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》如果想及时了解Spark、Hadoop或 w397090770 10年前 (2014-09-08) 18320℃ 177评论16喜欢
在即将发布的 Apache Spark™ 3.2 版本中 pandas API 将会成为其中的一部分。Pandas 是一个强大、灵活的库,并已迅速发展成为标准的数据科学库之一。现在,pandas 的用户将能够在他们现有的 Spark 集群上利用 pandas API。几年前,我们启动了 Koalas 这个开源项目,它在 Spark 之上实现了 Pandas DataFrame API,并被数据科学家广泛采用。最近,Koala w397090770 3年前 (2021-10-13) 811℃ 0评论3喜欢
Apache Flume 1.5.0 发布于5月22日正式发布(可以在http://flume.apache.org/download.html下载)。Flume是一个分布式、可靠和高可用的服务,用于收集、聚合以及移动大量日志数据,使用一个简单灵活的架构,就流数据模型。这是一个可靠、容错的服务。下面是Apache Flume-ng 1.5.0的Changelog:What's new in Apache Flume 1.5.0:May 22nd, 2014New Feature: Int w397090770 10年前 (2014-05-27) 7007℃ 1评论4喜欢
Apache HBase 是构建在 HDFS 之上的数据库,使用 HBase 我们可以随机读写存储在 HDFS 上的数据,但是我们都知道,HDFS 上的文件仅仅只支持追加(Append),其默认是不支持修改已经写好的文件。所以很多人就会问,HBase 是如何实现低延迟的读写能力呢?文本将试图介绍 HBase 写数据的过程。其实 HBase 写数据包括 put 和 delete 操作,在 HBase w397090770 6年前 (2019-01-02) 2567℃ 0评论12喜欢
Hive 1.2.1源码编译依赖的Hadoop版本必须最少是2.6.0,因为里面用到了Hadoop的org.apache.hadoop.crypto.key.KeyProvider和org.apache.hadoop.crypto.key.KeyProviderFactory两个类,而这两个类在Hadoop 2.6.0才出现,否者会出现以下编译错误:[ERROR] /home/q/spark/apache-hive-1.2.1-src/shims/0.23/src/main/java/org/apache/hadoop/hive/shims/Hadoop23Shims.java:[43,36] package org.apache.hadoop.cry w397090770 9年前 (2015-11-11) 13621℃ 11评论6喜欢
火焰图(Flame Graphs)是一种可视化技术,用于展示软件程序的运行时性能。它们可以帮助开发者快速识别程序中的热点(即执行时间最长的部分)。本文将指导您如何在 Linux 和 Mac 平台上生成火焰图。火焰图简介火焰图是由 Brendan Gregg 创建的性能分析工具,它以一种直观的方式展示了程序的调用栈信息。火焰图的每一层代表函 w397090770 5个月前 (04-10) 429℃ 0评论1喜欢
在计算机人工智能领域,距离(distance)、相似度(similarity)是经常出现的基本概念,它们在自然语言处理、计算机视觉等子领域有重要的应用,而这些概念又大多源于数学领域的度量(metric)、测度(measure)等概念。 曼哈顿距离曼哈顿距离又称计程车几何距离或方格线距离,是由十九世纪的赫尔曼·闵可夫斯基所创词汇 ,为欧几里得几 w397090770 7年前 (2018-01-14) 6711℃ 0评论27喜欢
前言 如果你尝试使用Apache Log4J中的DailyRollingFileAppender来打印每天的日志,你可能想对那些日志文件指定一个最大的保存数,就像RollingFileAppender支持maxBackupIndex参数一样。不过遗憾的是,目前版本的Log4j (Apache log4j 1.2.17)无法在使用DailyRollingFileAppender的时候指定保存文件的个数,本文将介绍如何修改DailyRollingFileAppender类,使得它 w397090770 9年前 (2016-04-12) 5646℃ 0评论3喜欢
Apache Flink开源大数据处理系统最近比较火,特别是其流处理框架的设计。本文并不打算介绍Apache Flink的相关概念,如果你感兴趣可以到本博客的Flink分类目录查看Flink的相关文章。 转入正题了,下面将一步一步教你如何提交你的代码到Flink社区。1、提交Issue 既然能够提交代码肯定是发现了什么Bug,或者有什么好 w397090770 8年前 (2016-11-21) 3417℃ 0评论4喜欢
1月15日,ElasticSearch 创始人、Elastic 公司 CEO Shay Banon 宣布,将把 Elasticsearch 和 Kibana 的 Apache 2.0-licensed 源码协议修改成 SSPL(Server Side Public License、服务器端公共许可证)和 Elastic License 双重协议!下面是 Shay Banon 修改 Elasticsearch 和 Kibana 开源协议的全文翻译。注:下面的我们是指 Elastic 公司(或 Shay Banon)我们正在将 ElasticSearch w397090770 4年前 (2021-01-17) 1162℃ 0评论4喜欢
最近修改了Spark的一些代码,然后编译Spark出现了以下的异常信息:[code lang="scala"]error file=/iteblog/spark-1.3.1/streaming/src/main/scala/org/apache/spark/streaming/StreamingContext.scalamessage=File line length exceeds 100 characters line=279error file=/iteblog/spark-1.3.1/streaming/src/main/scala/org/apache/spark/streaming/StreamingContext.scalamessage=File line length exceeds 100 characters w397090770 9年前 (2015-05-20) 6016℃ 0评论3喜欢
我们在使用Hadoop、Spark或者是Hbase,最常遇到的问题就是进行相关系统的配置,比如集群的URL地址,MapReduce临时目录、最终输出路径等。这些属性需要有一个系统(类)进行管理。然而,Hadoop没有使用 Java.util.Properties 管理配置文件,也没有使用Apache Jakarta Commons Configuration管理配置文件,而是单独开发了一个配置文件管理类,这个类就 w397090770 8年前 (2017-04-21) 7707℃ 0评论18喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 9年前 (2015-05-15) 4811℃ 0评论3喜欢
我们每天都可能会操作 HDFS 上的文件,这就很难避免误操作,比如比较严重的误操作就是删除文件。本文针对这个问题提供了三种恢复误删除文件的方法,希望对大家的日常运维有所帮助。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop通过垃圾箱恢复HDFS 为我们提供了垃圾箱的功能, w397090770 7年前 (2018-01-14) 10100℃ 2评论23喜欢
本文所列的 Hive 函数均为 Hive 内置的,共计294个,Hive 版本为 3.1.0。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop!! a - Logical not,和not逻辑操作符含义一致[code lang="sql"]hive> select !(true);OKfalse[/code]!=a != b - Returns TRUE if a is not equal to b,和操作符含义一致[code lang="sql"]hive> se w397090770 6年前 (2018-07-22) 9635℃ 0评论10喜欢
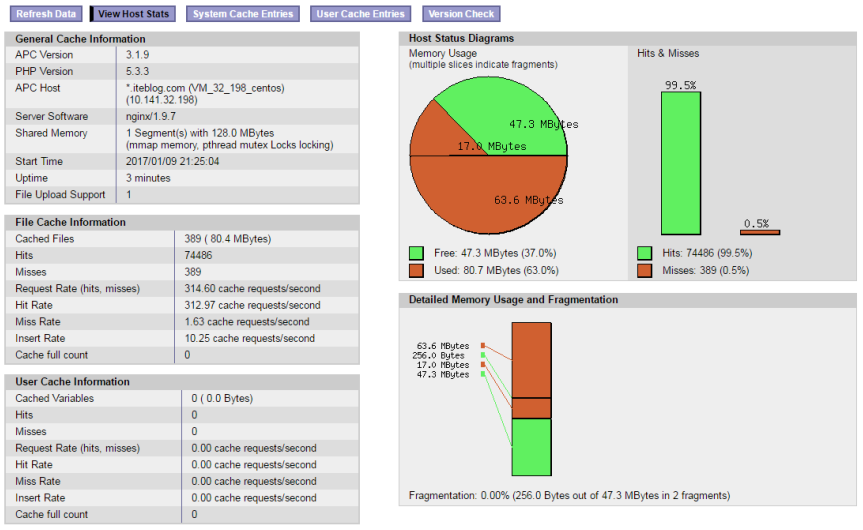
最近发现服务器php-fpm日志里面大量的Unable To Allocate Memory For Pool警告,如下:[code lang="bash"][09-Jan-2017 01:18:08] PHP Warning: require(): Unable to allocate memory for pool. in /data/web/iteblogbooks/wp-settings.php on line 220[09-Jan-2017 01:18:08] PHP Warning: require(): Unable to allocate memory for pool. in /data/web/iteblogbooks/wp-settings.php on line 221[09-Jan-2017 01:18:08] PHP Warning: re w397090770 8年前 (2017-01-09) 2174℃ 0评论4喜欢
关系运算1、等值比较: =语法:A=B操作类型:所有基本类型描述: 如果表达式A与表达式B相等,则为TRUE;否则为FALSE[code lang="sql"]hive> select 1 from iteblog where 1=1;1[/code]2、不等值比较: 语法: A B操作类型: 所有基本类型描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A与表达式B不相等,则为TRUE;否则为 zz~~ 7年前 (2017-09-14) 93483℃ 3评论183喜欢
在 《HDFS 块和 Input Splits 的区别与联系》 文章中介绍了HDFS 块和 Input Splits 的区别与联系,其中并没有涉及到源码级别的描述。为了补充这部分,这篇文章将列出相关的源码进行说明。看源码可能会比直接看文字容易理解,毕竟代码说明一切。为了简便起见,这里只描述 TextInputFormat 部分的读取逻辑,关于写 HDFS 块相关的代码请参 w397090770 6年前 (2018-05-16) 2373℃ 0评论19喜欢
此次活动参与方式:关注iteblog_hadoop公众号,并在这里评论区留言(认真写评论,增加上榜的机会)。活动截止至3月14日19:00,留言点赞数排名前5名的粉丝,各免费赠送一本《Druid实时大数据分析原理与实践》如果想及时了解Spark、Hadoop、Flink或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书简介Druid 作为一 w397090770 8年前 (2017-03-08) 1589℃ 0评论5喜欢
存储计算分离是整个行业的发展趋势,这种架构的存储和计算可以各自独立发展,它帮助云提供商降低成本。Presto 原生就支持这样的架构,数据可以从 Presto 服务器之外的远程存储节点传输过来。然而,存储计算分解也为查询延迟带来了新的挑战,因为当网络饱和时,通过网络扫描大量数据将受到 IO 限制。 此外,元数据的读取 w397090770 3年前 (2021-12-05) 765℃ 0评论2喜欢
Hadoop 社区推出了新一代分布式Key-value对象存储系统 Ozone,同时提供对象和文件访问的接口,从构架上解决了长久以来困扰HDFS的小文件问题。本文作为Ozone系列文章的第一篇,抛个砖,介绍Ozone的产生背景,主要架构和功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop背景HDFS是业界默认的 w397090770 4年前 (2020-05-26) 1905℃ 1评论1喜欢
SchemaRDD在Spark SQL中已经被我们使用到,这篇文章简单地介绍一下如果将标准的RDD(org.apache.spark.rdd.RDD)转换成SchemaRDD,并进行SQL相关的操作。[code lang="scala"]scala> val sqlContext = new org.apache.spark.sql.SQLContext(sc)sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@6edd421fscala> case class Person(name: String, age:Int)defined class Perso w397090770 10年前 (2014-12-16) 21227℃ 0评论20喜欢
由于项目需要,需要在集群中安装好Zookeeper,这里我选择最新版本的Zookeeper3.4.5。 ZooKeeper是Hadoop的正式子项目,它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统 w397090770 11年前 (2014-01-20) 9458℃ 6评论8喜欢
随着我们使用 Docker 的次数越来越多,我们电脑里面可能已经存在很多 Docker 镜像,大量的镜像会占据大量的存储空间,所有很有必要清理一些不需要的镜像。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop镜像的删除在删除镜像之前,我们可以看下系统里面都有哪些镜像:[code lang="bash"][ite w397090770 5年前 (2020-04-14) 573℃ 0评论1喜欢
本文介绍了如何使用 Presto 通过 Alluxio 查询 Iceberg 表。由于这项功能目前处于试验阶段,此处提供的信息可能会发生变化,请及时参考官方文档了解最新功能。关于如何使用 Presto 读取 Iceberg 上的数据请参考这里。我们知道,在 Hive 数据源上,Presto 支持两种形式的 Alluxio 缓存:通过 Alluxio local cache 以及 Alluxio Cluster,截止到本文章 w397090770 3年前 (2021-11-18) 1228℃ 0评论6喜欢
过去十年,存储的速度从 50MB/s(HDD)提升到 16GB/s(NvMe);网络的速度从 1Gbps 提升到 100Gbps;但是 CPU 的主频从 2010 年的 3GHz 到现在基本不变,CPU 主频是目前数据分析的重要瓶颈。为了解决这个问题,越来越多的向量化执行引擎被开发出来。比如数砖的 Photon 、ClickHouse、Apache Doris、Intel 的 Gazelle 以及 Facebook 的 Velox(参见 《Velox 介绍 w397090770 2年前 (2022-09-29) 1920℃ 0评论3喜欢
1月15日,ElasticSearch 创始人、Elastic 公司 CEO Shay Banon 宣布,将把 Elasticsearch 和 Kibana 的 Apache 2.0-licensed 源码协议修改成 SSPL(Server Side Public License、服务器端公共许可证)和 Elastic License 双重协议!并且让用户可以选择申请哪个许可。Shay Banon 说这个决策是为了限制云服务提供商提供 Elasticsearch和 Kibana 服务来保护 Elastic 公司在开发免费 w397090770 4年前 (2021-01-23) 376℃ 0评论3喜欢
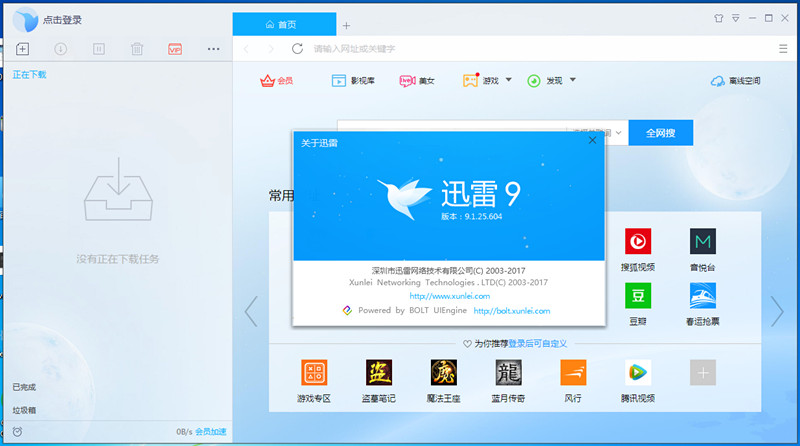
最近升级了迅雷9,新版本精简了任务列表的面积,然而增加了一个硕大的内置浏览器面板,大概占据了四分之三的窗口面积,并且不能关闭!界面如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop就个人观点而言,实在不能理解为什么需要让一个下载工具的附加功能占据主要使用区 w397090770 8年前 (2017-02-18) 6421℃ 0评论20喜欢
社区在Spark 1.3中开始引入了DataFrames,使得Apache Spark更加容易被使用。受R和Python中的data frames激发,Spark中的DataFrames提供了一些API,这些API在外部看起来像是操作单机的数据一样,而数据科学家对这些API非常地熟悉。统计是日常数据科学的一个重要组成部分。在即将发布的Spark 1.4中改进支持统计函数和数学函数(statistical and mathem w397090770 9年前 (2015-06-03) 13966℃ 2评论3喜欢
Mahout项目发展到了今天已经实现了许多的算法。下面列出Mahout项目主要的算法名称,供大家参考。一、协同过滤 Collaborative Filtering 1、基于用户的协同过滤 User-Based Collaborative Filtering 2、基于项目的协同过滤统 Item-Based Collaborative Filtering 3、交替最小二乘张量分解 Matrix Factorization with Alternating Least Squares 4、基 w397090770 10年前 (2014-09-23) 9512℃ 0评论17喜欢