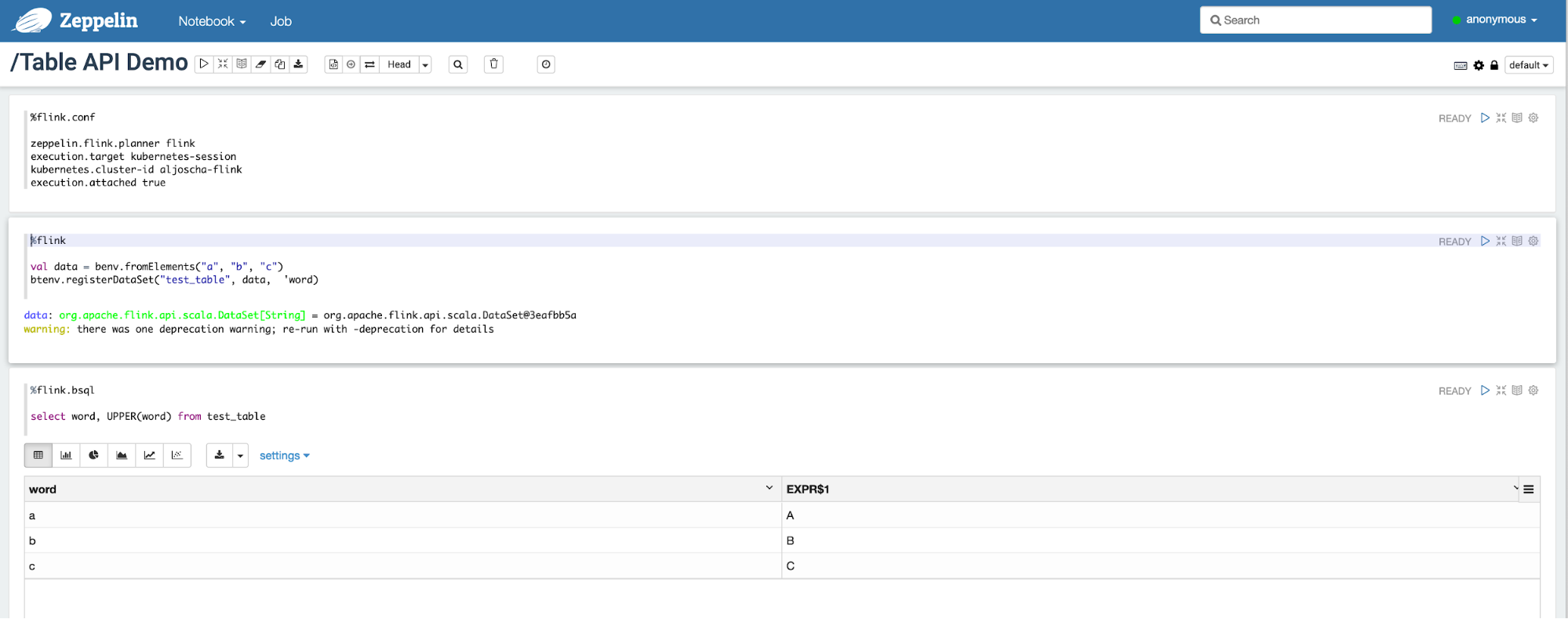
Hive 设计之初,就被定位一款离线数仓产品,虽然Hortonworks喊出了Make Apache Hive 100x Faster的牛逼口号,也在上面做了大量的优化,然而性能提升依旧不大。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆而随着OPPO数据量一步步的增多,动辄运行几个小时的hive再也满足不了交互查询的需求,因此我们 w397090770 4年前 (2021-03-05) 989℃ 0评论6喜欢
Apache Kafka 3.0 于2021年9月21日正式发布。本文将介绍这个版本的新功能。以下文章翻译自 《What's New in Apache Kafka 3.0.0》。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据我很高兴地代表 Apache Kafka® 社区宣布 Apache Kafka 3.0 的发布。 Apache Kafka 3.0 是一个大版本,其引入了各种新功能、API 发生重 w397090770 3年前 (2021-09-24) 569℃ 0评论2喜欢
Apache Hudi 是一种数据湖平台技术,它提供了构建和管理数据湖所需的几个功能。hudi 提供的一个关键特性是自我管理文件大小,这样用户就不需要担心手动维护表。拥有大量的小文件将使计算更难获得良好的查询性能,因为查询引擎不得不多次打开/读取/关闭文件以执行查询。但是对于流数据湖用例来说,可能每次都只会写入很少的 w397090770 3年前 (2021-08-03) 1067℃ 0评论1喜欢
在Wordpress后台里面有个选项是 多媒体->媒体库 里面显示的是所有文章的附件,包括了图片、视频、文件等。我们在开发Wordpress的时候,有时候需要列出文章中相应的附件,可以通过下面的方式来解决:[code lang="php"]$args = array( 'caller_get_posts' => 1, 'paged' => $paged);query_posts($args);if ( have_posts() ) : while ( have_posts w397090770 10年前 (2014-11-10) 6644℃ 1评论6喜欢
我们在开发过程中,难免会进行一些误操作,比如下面我们提交 723cc1e commit 的时候把 2b27deb 和 0ff665e 不小心也提交到这个分支了。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据0ff665e 是属于其他还没有合并到 master 分支的 MR,所以我们这里肯定不能把它带上来。我们需要把它删了。值得 w397090770 3年前 (2021-07-09) 581℃ 0评论1喜欢
如果你想搭建伪分布式Hadoop平台,请参见本博客《在Fedora上部署Hadoop2.2.0伪分布式平台》 经过好多天的各种折腾,终于在几台电脑里面配置好了Hadoop2.2.0分布式系统,现在总结一下如何配置。 前提条件: (1)、首先在每台Linux电脑上面安装好JDK6或其以上版本,并设置好JAVA_HOME等,测试一下java、javac、jps等命令 w397090770 11年前 (2013-11-06) 21278℃ 6评论27喜欢
在大规模数据量的数据分析及建模任务中,往往针对全量数据进行挖掘分析时会十分耗时和占用集群资源,因此一般情况下只需要抽取一小部分数据进行分析及建模操作。本文就介绍 Hive 中三种数据抽样的方法块抽样(Block Sampling)Hive 本身提供了抽样函数,使用 TABLESAMPLE 抽取指定的 行数/比例/大小,举例:[code lang="sql"]CREA w397090770 8年前 (2017-02-10) 6183℃ 0评论7喜欢
本章节我们提供一些 Java 8 中的 IntStream、LongStream 和 DoubleStream 使用范例。IntStream、LongStream 和 DoubleStream 分别表示原始 int 流、 原始 long 流 和 原始 double 流。这三个原始流类提供了大量的方法用于操作流中的数据,同时提供了相应的静态方法来初始化它们自己。这三个原始流类都在 java.util.stream 命名空间下。java.util.stream.Int w397090770 3年前 (2022-03-31) 194℃ 0评论1喜欢
Spark 1.1.0马上就要发布了(估计就是明天),其中更新了很多功能。其中对Spark SQL进行了增强: 1、Spark 1.0是第一个预览版本( 1.0 was the first “preview” release); 2、Spark 1.1 将支持Shark更新(1.1 provides upgrade path for Shark), (1)、Replaced Shark in our benchmarks with 2-3X perfgains; (2)、Can perform optimizations with 10- w397090770 10年前 (2014-09-11) 7778℃ 2评论5喜欢
现象大家在使用 Apache Spark 2.x 的时候可能会遇到这种现象:虽然我们的 Spark Jobs 已经全部完成了,但是我们的程序却还在执行。比如我们使用 Spark SQL 去执行一些 SQL,这个 SQL 在最后生成了大量的文件。然后我们可以看到,这个 SQL 所有的 Spark Jobs 其实已经运行完成了,但是这个查询语句还在运行。通过日志,我们可以看到 driver w397090770 6年前 (2019-01-14) 4219℃ 0评论18喜欢
前言 OPPO的大数据离线计算发展,经历了哪些阶段?在生产中遇到哪些经典的大数据问题?我们是怎么解决的,从中有哪些架构上的升级演进?未来的OPPO离线平台有哪些方向规划?今天会给大家一一揭秘。OPPO大数据离线计算发展历史大数据行业发展阶段 一家公司的技术发展,离不开整个行业的发展背景。我们简短回归 w397090770 3年前 (2021-10-29) 735℃ 0评论2喜欢
Apache Spark 3.3.0 从2021年07月03日正式开发,历时近一年,终于在2022年06月16日正式发布,在 Databricks Runtime 11.0 也同步发布。这个版本一共解决了 1600 个 ISSUE,感谢 Apache Spark 社区为 Spark 3.3 版本做出的宝贵贡献。根据经验,这个版本应该不是稳定版,想在线上环境使用的小伙伴们可以再等等。如果想及时了解Spark、Hadoop或者HBase相关 w397090770 2年前 (2022-06-18) 1952℃ 0评论2喜欢
gossip 是什么gossip 协议(gossip protocol)又称 epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议,在分布式系统中被广泛使用,比如我们可以使用 gossip 协议来确保网络中所有节点的数据一样。gossip protocol 最初是由施乐公司帕洛阿尔托研究中心(Palo Alto Research Center)的研究员艾伦·德默斯(Al w397090770 6年前 (2019-01-24) 19689℃ 1评论15喜欢
Apache Flink 1.10.0 于 2020年02月11日正式发布。Flink 1.10 是一个历时非常长、代码变动非常大的版本,也是 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。 w397090770 5年前 (2020-02-12) 3459℃ 0评论3喜欢
摘要:本文整理自 58 同城实时计算平台负责人冯海涛在 Flink Forward Asia 2020 分享的议题《Flink 在 58 同城应用与实践》,内容包括: 实时计算平台架实时 SQL 建设Storm 迁移 Flink 实践一站式实时计算平台后续规划如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据实时计算平台架构 w397090770 3年前 (2021-08-17) 286℃ 0评论2喜欢
搜索API允许开发者执行搜索查询,返回匹配查询的搜索结果。这既可以通过查询字符串也可以通过查询体实现。多索引多类型所有的搜索API都可以跨多个类型使用,也可以通过多索引语法跨索引使用。例如,我们可以搜索twitter索引的跨类型的所有文档。[code lang="java"]$ curl -XGET 'http://localhost:9200/twitter/_search?q=user:kimchy'[/ zz~~ 8年前 (2016-09-22) 1667℃ 0评论2喜欢
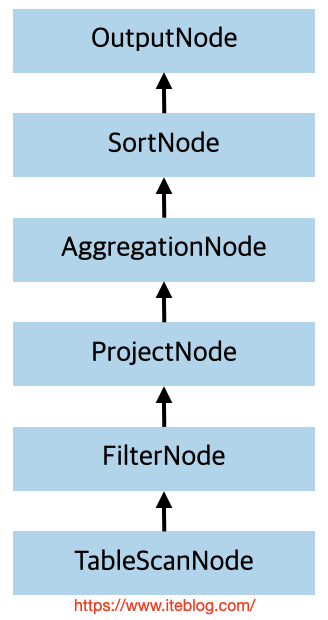
和其他计算引擎一样,一条 SQL 从客户的提交到 Coordinator 端经过 SqlParser 进行词法和语法解析形成 AST 树,然后经过 Analyzer 进行语义分析,生成了逻辑计划(LogicalPlan);接着经过优化器处理(优化规则都是在 PlanOptimizers 里面定义好的,然后在 LogicalPlanner 里面循环遍历每个规则)生成物理计划(PhysicalPlan);最后使用 PlanFragmenter 并 w397090770 3年前 (2021-08-08) 1187℃ 0评论3喜欢
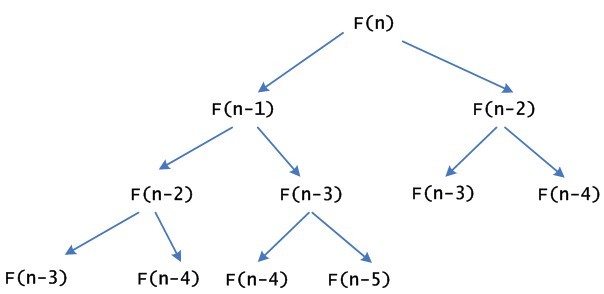
斐波那契数列又译费波拿契数、斐波那契数列、费氏数列、黄金分割数列。根据高德纳(Donald Ervin Knuth)的《计算机程序设计艺术》(The Art of Computer Programming),1150年印度数学家Gopala和金月在研究箱子包装物件长阔刚好为 1 和 2 的可行方法数目时,首先描述这个数列。 在西方,最先研究这个数列的人是比萨的列奥那多(又名费波 w397090770 12年前 (2013-04-16) 5892℃ 0评论6喜欢
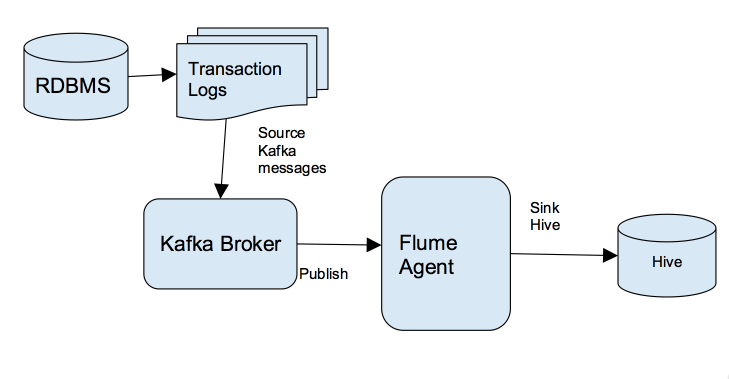
对那些想快速把数据传输到其Hadoop集群的企业来说,Kafka是一个非常合适的选择。关于什么是Kafka我就不介绍了,大家可以参见我之前的博客:《Apache kafka入门篇:工作原理简介》 本文是面向技术人员编写的。阅读本文你将了解到我是如何通过Kafka把关系数据库管理系统(RDBMS)中的数据实时写入到Hive中,这将使得实时分析的 w397090770 8年前 (2016-08-30) 11454℃ 6评论26喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 139.226.113.238 8090 高匿名 HTTP w397090770 9年前 (2015-05-12) 13684℃ 0评论1喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/好久没写Hive的那些事了,今 w397090770 11年前 (2014-02-19) 92554℃ 5评论132喜欢
经常使用 Apache Spark 从 Kafka 读数的同学肯定会遇到这样的问题:某些 Spark 分区已经处理完数据了,另一部分分区还在处理数据,从而导致这个批次的作业总消耗时间变长;甚至导致 Spark 作业无法及时消费 Kafka 中的数据。为了简便起见,本文讨论的 Spark Direct 方式读取 Kafka 中的数据,这种情况下 Spark RDD 中分区和 Kafka 分区是一一对 w397090770 6年前 (2018-09-08) 6616℃ 0评论25喜欢
highlight.js是一款轻量级的Web代码语法高亮库,它主要有以下几个特点: (1)、支持118种语言(看这里https://github.com/isagalaev/highlight.js/tree/master/src/languages)和54中样式(看这里https://github.com/isagalaev/highlight.js/tree/master/src/styles); (2)、可以自动检测编程语言; (3)、同时为多种编程语言代码高亮; (4) w397090770 10年前 (2015-04-16) 14217℃ 0评论13喜欢
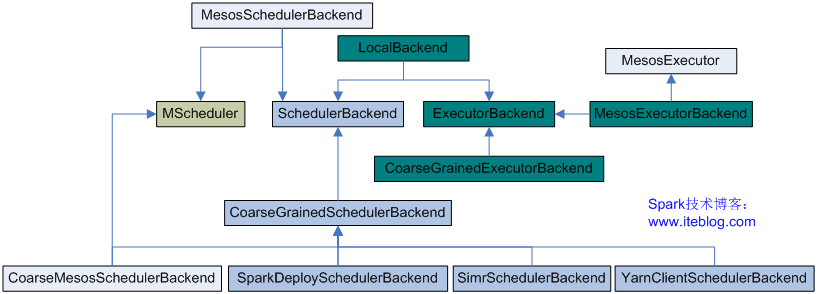
《Spark源码分析:多种部署方式之间的区别与联系(1)》《Spark源码分析:多种部署方式之间的区别与联系(2)》 在《Spark源码分析:多种部署方式之间的区别与联系(1)》我们谈到了SparkContext的初始化过程会做好几件事情(这里就不再列出,可以去《Spark源码分析:多种部署方式之间的区别与联系(1)》查看),其中做了一件重要 w397090770 10年前 (2014-10-28) 7689℃ 6评论8喜欢
《Kafka: The Definitive Guide, 2nd Edition》于 2021年11月由 O'Reilly Media 出版, ISBN 为 9781492043089 ,全书 486 页。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop图书介绍Every enterprise application creates data, whether it consists of log messages, metrics, user activity, or outgoing messages. Moving all this data is just as important as the w397090770 3年前 (2022-03-22) 1176℃ 0评论4喜欢
Apache Hive 1.2.0于美国时间2015年05月18日正式发布,其中修复了大量大Bug,完整邮件内容如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopThe Apache Hive team is proud to announce the the release of Apache Hive version 1.2.0.The Apache Hive (TM) data warehouse software facilitates querying and managing large datasets residin w397090770 9年前 (2015-05-19) 5403℃ 0评论4喜欢
到这个页面(https://hub.docker.com/_/centos?tab=tags)查看自己要下载的 Centos 版本:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop将指定版本的 CentOS 镜像拉到本地在本地使用下面命令进行拉取:[code lang="bash"][iteblog@iteblog.com]$ docker pull centos:centos7centos7: Pulling from library/centos6717b8ec66cd: Pull comp w397090770 3年前 (2021-10-17) 140℃ 0评论1喜欢
Git 的代码回滚主要有 reset 和 revert,本文介绍其用法如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopreset一般用法是 [code lang="bash"]git reset --hard commit_id[/code]其中 commit_id 是使用 git log 查看的 id,如下:[code lang="bash"]$ git logcommit 26721c73c6bb82c8a49aa94ce06024f592032d0cAuthor: iteblog <iteblog@iteb w397090770 4年前 (2020-10-12) 1269℃ 0评论0喜欢
这是一份迟来的年终报告,本来昨天就要发出来的,实在是没忙开,今天我就把它当作新年礼物送给各位看官,以下文章都是我结合日常工作、学习,每当“夜深人静"的时候写出来的一些小总结,希望能给大家一些技术上的帮助。关注我的朋友都知道,我在今年八月份发了一篇文章,里面整理了我五年来写在这个公众号上面的原 w397090770 5年前 (2020-01-04) 1367℃ 0评论1喜欢
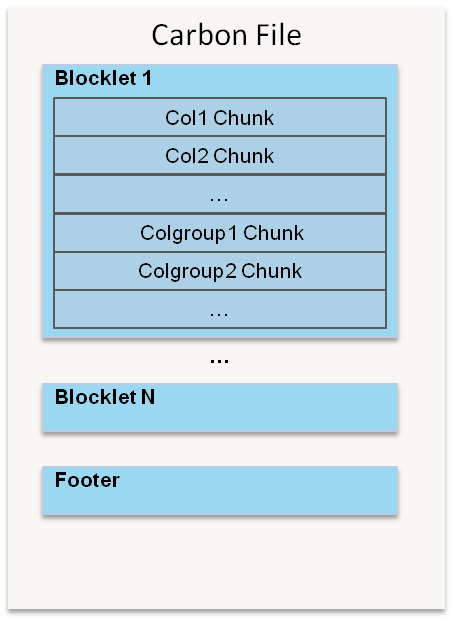
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。为什么重新设计一种文件格式目前华为针对数据的需求分析主要有以下5点要求: 1、支持海量数据扫描并 w397090770 8年前 (2016-06-13) 5484℃ 0评论7喜欢