一致性哈希算法(Consistent Hashing)最早在1997年由 David Karger 等人在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出,其设计目标是为了解决因特网中的热点(Hot spot)问题;一致性哈希最初在 P2P 网络中作为分布式哈希表( DHT)的常用数据分布算法,目前这个算法在分布式系统中成 w397090770 6年前 (2019-02-01) 3844℃ 0评论7喜欢
HDFS Federation为HDFS系统提供了NameNode横向扩容能力。然而作为一个已实现多年的解决方案,真正应用到已运行多年的大规模集群时依然存在不少的限制和问题。本文以实际应用场景出发,介绍了HDFS Federation在美团点评的实际应用经验。 背景 2015年10月,经过一段时间的优化与改进,美团点评HDFS集群稳定性和性能有显著 zz~~ 8年前 (2017-03-17) 2035℃ 0评论7喜欢
作者:李闯 郭理想 背景 随着有赞实时计算业务场景全部以Flink SQL的方式接入,对有赞现有的引擎版本—Flink 1.10的SQL能力提出了越来越多无法满足的需求以及可以优化的功能点。目前有赞的Flink SQL是在Yarn上运行,但是在公司应用容器化的背景下,可以统一使用公司K8S资源池,同时考虑到任务之间的隔离性以及任务的弹性 w397090770 3年前 (2021-12-30) 1049℃ 0评论6喜欢
在即将发布的 Apache Spark™ 3.2 版本中 pandas API 将会成为其中的一部分。Pandas 是一个强大、灵活的库,并已迅速发展成为标准的数据科学库之一。现在,pandas 的用户将能够在他们现有的 Spark 集群上利用 pandas API。几年前,我们启动了 Koalas 这个开源项目,它在 Spark 之上实现了 Pandas DataFrame API,并被数据科学家广泛采用。最近,Koala w397090770 3年前 (2021-10-13) 811℃ 0评论3喜欢
经过去年年底的一段时间,本博客已经写了好几十篇关于Hive方面的文章,今天将这些博文汇总一下,以便大家查阅方便。同时,我将会在2014年继续更新《Hive的那些事》序列博文,对Hive比较关注的人,可以关注我的博客(/archives/category/hive的那些事:hive的那些事),由于个人水平有限,如博文有什么错误还希望大家指正。 w397090770 11年前 (2014-02-12) 9197℃ 0评论11喜欢
Spark Summit East 2016:视频,PPT Spark Summit East 2016会议于2016年2月16日至2月18日在美国纽约进行。总体来说,Spark Summit一年比一年火,单看纽约的峰会中,规模已从900人增加到500个公司的1300人,更吸引到更多大型公司的分享,包括Bloomberg、Capital One、Novartis、Comcast等公司。而在这次会议上,Databricks还发布了两款产品——Commu w397090770 9年前 (2016-02-27) 5667℃ 0评论14喜欢
Few months ago, I introduced a simple algorithm that allow users to implement their own short URL into their system. Today, I have some spare time so I decided to write the short URL algorithm's implementation in PHP.At first, we define a function called shorturl() that receives a URL as the input and returns an array that contains 4 hashed values (each 6 characters).[php]function shorturl($input) { ... // return array of w397090770 12年前 (2013-04-14) 3837℃ 0评论1喜欢
问题我们都知道,Hive 内部提供了大量的内置函数用于处理各种类型的需求,参见官方文档:Hive Operators and User-Defined Functions (UDFs)。我们从这些内置的 UDF 可以看到两个用于解析 Json 的函数:get_json_object 和 json_tuple。用过这两个函数的同学肯定知道,其职能解析最普通的 Json 字符串,如下:[code lang="sql"]hive (default)> SELECT get_js w397090770 6年前 (2018-07-04) 20161℃ 0评论34喜欢
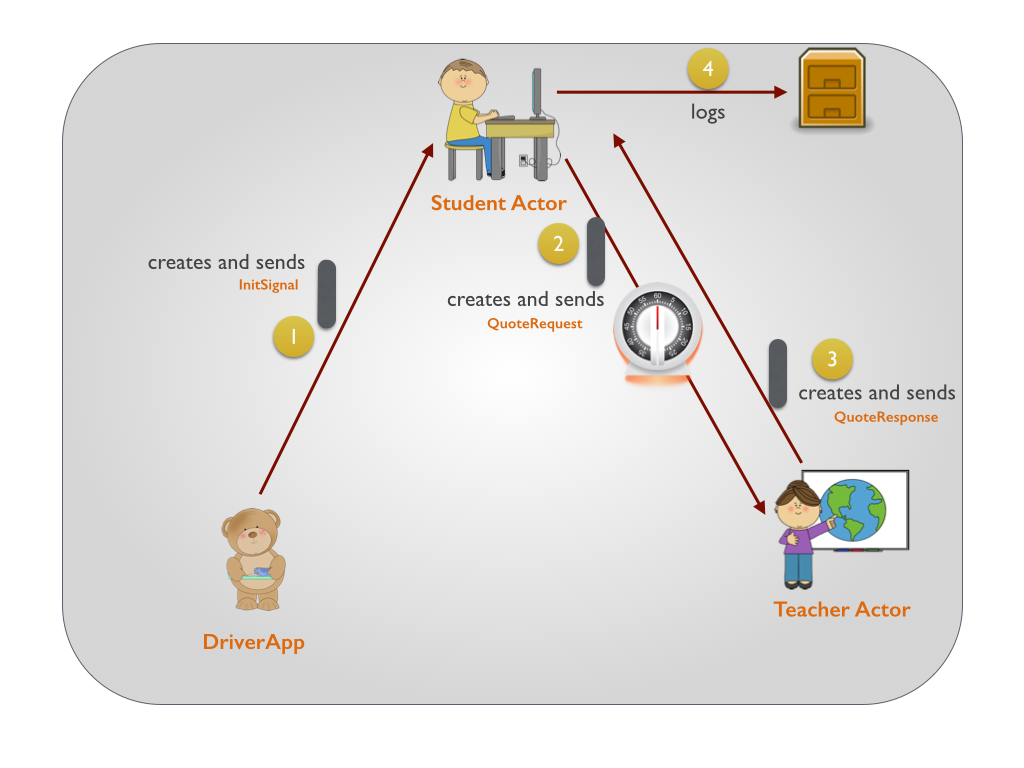
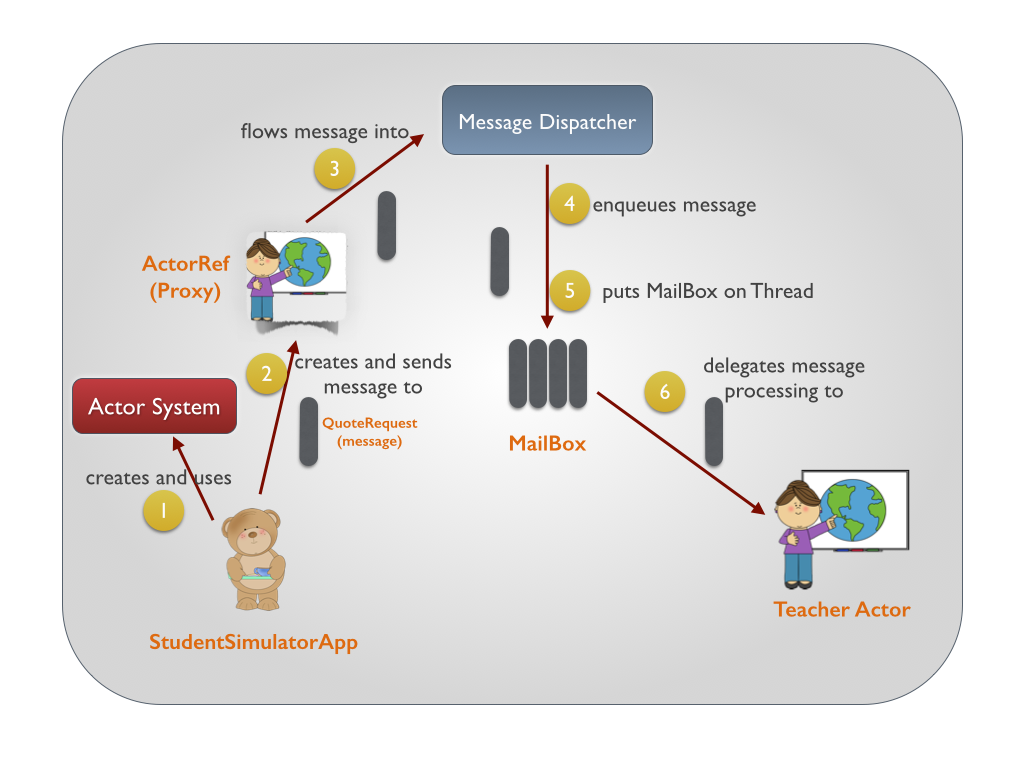
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-22) 19202℃ 3评论14喜欢
Kafka内部提供了许多管理脚本,这些脚本都放在$KAFKA_HOME/bin目录下,而这些类的实现都是放在源码的kafka/core/src/main/scala/kafka/tools/路径下。Consumer Offset Checker Consumer Offset Checker主要是运行kafka.tools.ConsumerOffsetChecker类,对应的脚本是kafka-consumer-offset-checker.sh,会显示出Consumer的Group、Topic、分区ID、分区对应已经消费的Offset、 w397090770 9年前 (2016-03-18) 16019℃ 0评论13喜欢
本文将介绍如何手动更新Kafka存在Zookeeper中的偏移量。我们有时候需要手动将某个主题的偏移量设置成某个值,这时候我们就需要更新Zookeeper中的数据了。Kafka内置为我们提供了修改偏移量的类:kafka.tools.UpdateOffsetsInZK,我们可以通过它修改Zookeeper中某个主题的偏移量,具体操作如下:[code lang="bash"][iteblog@www.iteblog.com ~]$ bin/ka w397090770 9年前 (2016-04-19) 15167℃ 0评论12喜欢
本文作者:王祥虎,原文链接:https://mp.weixin.qq.com/s/LvKaj5ytk6imEU5Dc1Sr5Q,欢迎关注 Apache Hudi 技术社区公众号:ApacheHudi。Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目。是当前最为热门的数据湖框架之一。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢 w397090770 4年前 (2020-10-09) 1841℃ 0评论2喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-13) 21959℃ 5评论40喜欢
题目以及要求:把一个字符串的大写字母放到字符串的后面,各个字符的相对位置不变,不能申请额外的空间。我的实现类似冒泡排序。[code lang="CPP"]#include <stdio.h>#include <string.h>// Author: 397090770// E-mail:wyphao.2007@163.com// Blog: // Date: 2012/09/29//题目以及要求:把一个字符串的大写字母放到字符串的后面,// w397090770 12年前 (2013-04-02) 3908℃ 0评论1喜欢
一、概述有时候我们需要设计这样一种数据结构:它能快速在要求位置插入或者删除一段数据。先考虑两种简单的数据结构:数组和链表。数组的优点是能够在O(1)的时间内找到所要执行操作的位置,但其缺点是无论是插入或删除都要移动之后的所有数据,复杂度是O(n)的。链表优点是能够在O(1)的时间内插入和删除一段数据,但缺点 w397090770 12年前 (2013-04-03) 5830℃ 0评论7喜欢
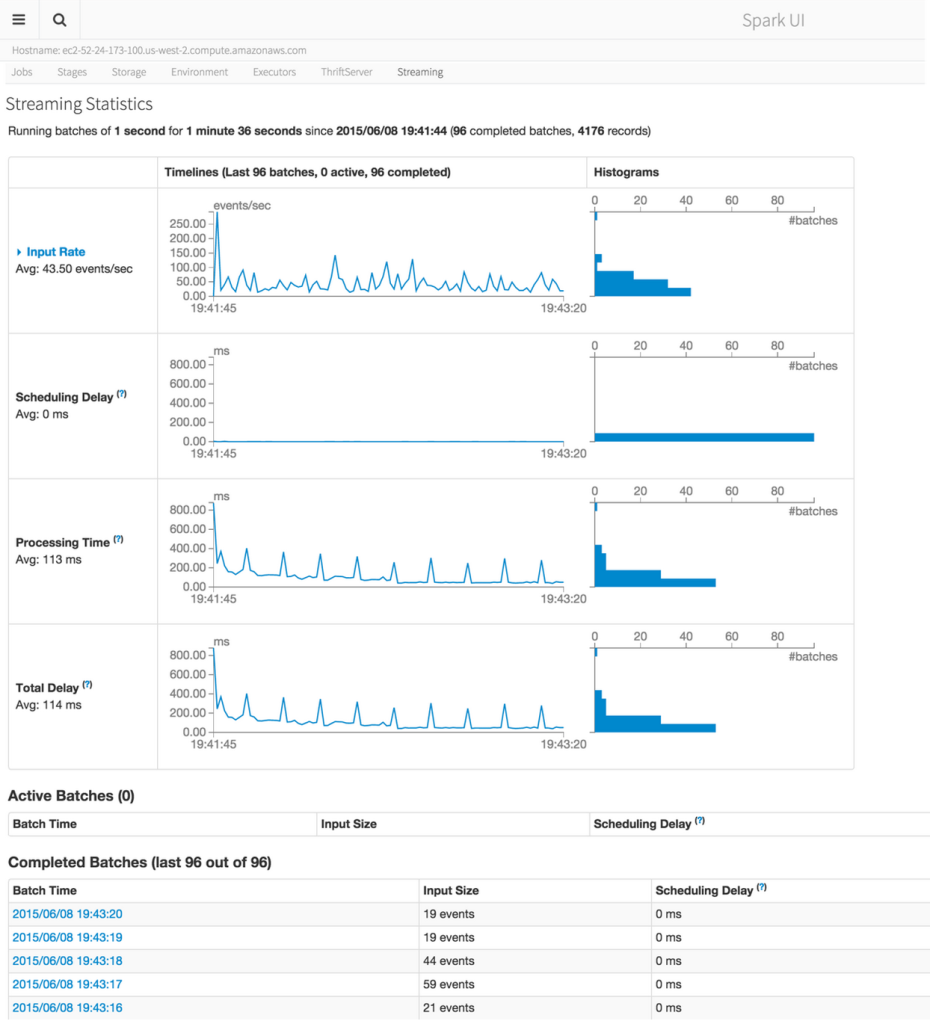
今天早上我在博文里面更新了Spark 1.4.0正式发布,由于时间比较匆忙(要上班啊),所以在那篇文章里面只是简单地介绍了一下Spark 1.4.0,本文详细将详细地介绍Spark 1.4.0特性。如果你想尽早了解Spark等相关大数据消息,请关注本博客,或者本博客微信公共帐号iteblog_hadoop。 Apache Spark 1.4.0版本于美国时间2015年06月11日正式发 w397090770 9年前 (2015-06-12) 5044℃ 1评论1喜欢
引言Join是SQL语句中的常用操作,良好的表结构能够将数据分散在不同的表中,使其符合某种范式,减少表冗余、更新容错等。而建立表和表之间关系的最佳方式就是Join操作。SparkSQL作为大数据领域的SQL实现,自然也对Join操作做了不少优化,今天主要看一下在SparkSQL中对于Join,常见的3种实现。Spark SQL中Join常用的实现Broadc zz~~ 7年前 (2017-07-09) 8319℃ 0评论16喜欢
AbstractMapBasedMultimap源码分析:AbstractMapBasedMultimap是Multimap接口的基础实现类,实现了Multimap中的绝大部分方法,其中有许多的方法还是靠实现类的具体实现,比如size()方法,其计算方法在不同实现是不一样的。同时,AbstractMapBasedMultimap类也定义了自己的一些方法,比如createCollection()。AbstractMapBasedMultimap类中主要存在以下两个成员 w397090770 11年前 (2013-09-13) 4028℃ 1喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 10年前 (2015-03-30) 4843℃ 0评论4喜欢
在 《Apache Solr 安装部署及索引创建》 文章中,我们搭建好一个单机版的 Solr 服务,并创建好一个名为 iteblog 的 core,iteblog 的索引数据是存放在 instanceDir 参数的 data 目录下。这会有以下几个问题:如果索引数据很大,可能本地的文件夹无法存储索引数据存放在本地,可能会导致索引数据丢失等幸运的是,Solr 支持将索引和事 w397090770 6年前 (2018-07-25) 1799℃ 0评论4喜欢
在过去一年有很多 Apache 孵化项目顺利毕业成顶级项目(Top-Level Project ,简称 TLP ),在这里我将给大家盘点 2020 年晋升为 Apache TLP 的大数据相关项目。在2020年一共有四个大数据相关项目顺利毕业成顶级项目,主要是 Apache® ShardingSphere™、Apache® Hudi™、Apache® Iceberg™ 以及 Apache® IoTDB™,这里以毕业的时间顺序依次介绍。关于过 w397090770 4年前 (2021-01-03) 1405℃ 0评论5喜欢
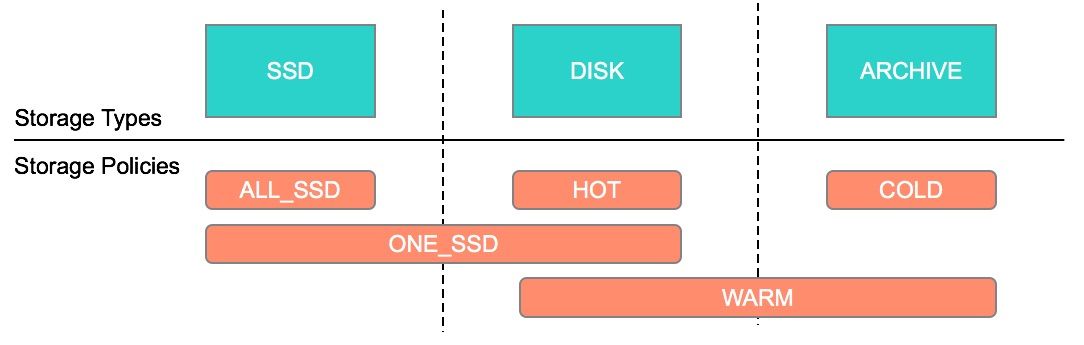
介绍HDFS 归档存储(Archival Storage)是从 Hadoop 2.6.0 开始引入的(参见 HDFS-6584)。归档存储是一种将增长的存储容量与计算容量解耦的解决方案。我们可以在集群中部署一些具有更高密度、更便宜的存储且提供更低计算能力的节点,并且可以用作集群中的冷数据存储器。根据我们的设置,可以将热数据移到冷存储介质中。通过添加更 w397090770 4年前 (2020-04-15) 1763℃ 0评论3喜欢
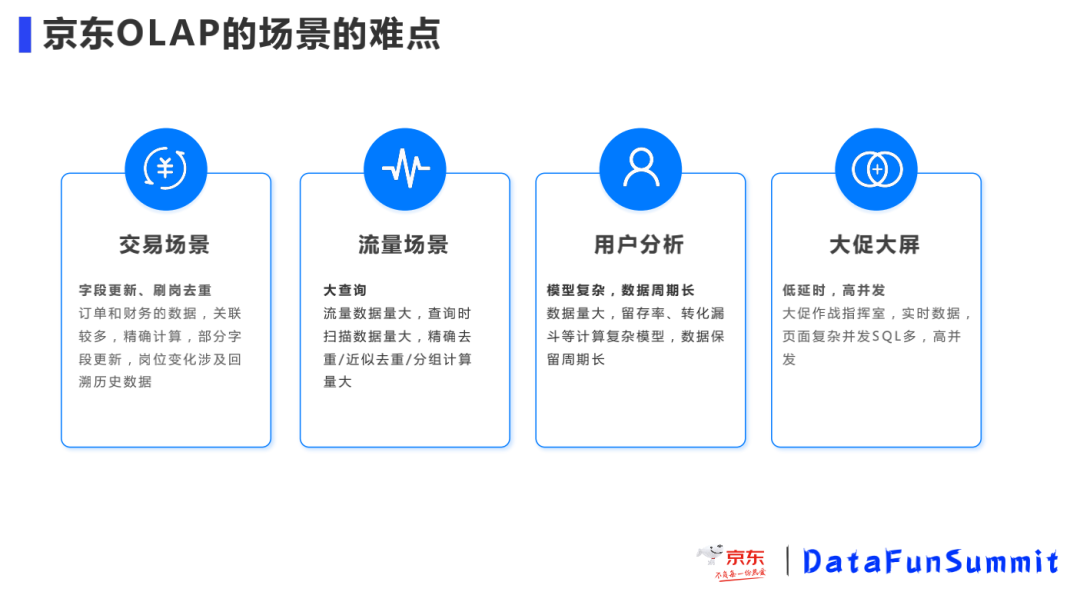
导读:京东OLAP采取ClickHouse为主Doris为辅的策略,有3000台服务器,每天亿次查询万亿条数据写入,广泛服务于各个应用场景,经过历次大促考验,提供了稳定的服务。本文介绍了ClickHouse在京东的高可用实践,包括选型过程、集群部署、高可用架构、问题和规划。01应用场景和选型京东数据分析的场景非常多,在交易、流量、大屏 zz~~ 3年前 (2021-10-08) 1140℃ 0评论3喜欢
今天由于某些原因需要卸载掉服务器上的php软件,然后我使用下面命令显示出本机安装的所有和php相关的软件,如下:[code lang="bash"]iteblog$ rpm -qa | grep phpphp-mysqlnd-5.6.25-0.1.RC1.el6.remi.x86_64php-fpm-5.6.25-0.1.RC1.el6.remi.x86_64php-pecl-jsonc-1.3.10-1.el6.remi.5.6.x86_64php-pecl-memcache-3.0.8-3.el6.remi.5.6.x86_64php-pdo-5.6.25-0.1.RC1.el6.remi.x86_64php-mbstrin w397090770 8年前 (2016-08-08) 2286℃ 0评论2喜欢
最近有个项目需要用到手机归属地信息,所有网上找到了一些免费的API。但是因为是免费的,所有很多都有限制,比如每天只能查询多少次等。本站提供的API地址: /api/mobile.php?mobile=13188888888参数:mobile ->手机号码(7位到11位)返回格式:JSON实例结果:[code lang="scala"]{ "ID": "18889", "prefix": &q w397090770 8年前 (2016-08-02) 8018℃ 4评论16喜欢
引言:十年沉淀、全球宽表排名第一、阿里云首发云Cassandra服务ApsaraDB for Cassandra是基于开源Apache Cassandra,融合阿里云数据库DBaaS能力的分布式NoSQL数据库。Cassandra已有10年+的沉淀,基于Amazon DynamoDB的分布式设计和 Google Bigtable 的数据模型。具备诸多优异特性:采用分布式架构、无中心、支持多活、弹性可扩展、高可用、容错、一 w397090770 5年前 (2019-09-05) 2153℃ 0评论4喜欢
如果你经常写MapReduce作业,你肯定看到过以下的异常信息:[code lang="bash"]Application application_1409135750325_48141 failed 2 times due to AM Container forappattempt_1409135750325_48141_000002 exited with exitCode: 143 due to: Container[pid=4733,containerID=container_1409135750325_48141_02_000001] is running beyond physical memory limits.Current usage: 2.0 GB of 2 GB physical memory used; 6.0 GB of w397090770 8年前 (2016-12-29) 4191℃ 1评论11喜欢
在今年的5月22号,Flume-ng 1.5.0版本正式发布,关于Flume-ng 1.5.0版本的新特性可以参见本博客的《Apache Flume-ng 1.5.0正式发布》进行了解。关于Apache flume-ng 1.4.0版本的编译可以参见本博客《基于Hadoop-2.2.0编译flume-ng 1.4.0及错误解决》。本文将讲述如何用Maven编译Apache flume-ng 1.5.0源码。一、到官方网站下载相应版本的flume-ng源码[code lan w397090770 10年前 (2014-06-16) 20781℃ 23评论14喜欢
为期三天的 Spark+AI Summit Europe 于 2018-10-02 ~ 04 在伦敦举行,一如往前,本次会议包含大量 AI 相关的议题,某种意义上也代表着 Spark 未来的发展方向。作为大数据领域的顶级会议,Spark+AI Summit Europe 2018 吸引了全球大量技术大咖参会,本次会议议题超过了140多个。会议的全部日程请参见:https://databricks.com/sparkaisummit/europe/schedule。注意 w397090770 6年前 (2018-10-13) 3476℃ 1评论8喜欢
Hive on Spark功能目前只增加下面九个参数,具体含义可以参见下面介绍。hive.spark.client.future.timeout Hive client请求Spark driver的超时时间,如果没有指定时间单位,默认就是秒。Expects a time value with unit (d/day, h/hour, m/min, s/sec, ms/msec, us/usec, ns/nsec), which is sec if not specified. Timeout for requests from Hive client to remote Spark driver.hive.spark.job.mo w397090770 9年前 (2015-12-07) 24550℃ 2评论11喜欢


![Spark Summit East 2016 PPT免费下载[共65个]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/5.jpg)










![Spark+AI Summit Europe 2018 PPT下载[共95个]](https://www.iteblog.com/pic/spark/Spark_ai_summit_europe_2018-iteblog.png)