本文转载至 http://www.ibm.com/developerworks/cn/java/j-dcl.html 单例创建模式是一个通用的编程习语。和多线程一起使用时,必需使用某种类型的同步。在努力创建更有效的代码时,Java 程序员们创建了双重检查锁定习语,将其和单例创建模式一起使用,从而限制同步代码量。然而,由于一些不太常见的 Java 内存模型细节的原因,并不能 w397090770 11年前 (2013-10-18) 4653℃ 4评论6喜欢
C的结构体内不允许有函数存在,C++允许有内部成员函数,且允许该函数是虚函数。所以C的结构体是没有构造函数、析构函数、和this指针的。 C的结构体对内部成员变量的访问权限只能是public,而C++允许public,protected,private三种。 C语言的结构体是不可以继承的,C++的结构体是可以从其他的结构体或者类继承过来的。在C中定义一 w397090770 12年前 (2013-04-05) 5133℃ 0评论0喜欢
《Spark Streaming作业提交源码分析接收数据篇》、《Spark Streaming作业提交源码分析数据处理篇》 最近一段时间在使用Spark Streaming,里面遇到很多问题,只知道参照官方文档写,不理解其中的原理,于是抽了一点时间研究了一下Spark Streaming作业提交的全过程,包括从外部数据源接收数据,分块,拆分Job,提交作业全过程。 w397090770 10年前 (2015-04-28) 9194℃ 2评论9喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive提供三种可以改变环境 w397090770 11年前 (2013-12-24) 25303℃ 2评论10喜欢
为了方便集群的部署,一般我们都会构建出一个 dokcer 镜像,然后部署到 k8s 里面。Presto、Prestissimo 以及 Velox 也不例外,本文将介绍如果构建 presto 以及 Prestissimo 的镜像。构建 Presto 镜像Presto 官方代码里面其实已经包含了构建 Presto 镜像的相关文件,具体参见 $PRESTO_HOME/docker 目录:[code lang="bash"]➜ target git:(velox_docker) ✗ ll ~/ w397090770 1年前 (2023-06-21) 423℃ 0评论8喜欢
Iterators类提供了返回Iterator类型的对象或者对Iterator类型对象操作的方法。除了特别的说明,Iterators类中所有的方法都在Iterables类中有相应的基于Iterable方法对应。 性能说明:除非特别说明,所有在这个类中的迭代器都是懒惰的,这意味着在觉得必要的时候,需要提前得到迭代功能。Iterators类可以通过emptyIterator()方法得到 w397090770 11年前 (2013-09-11) 3957℃ 3评论0喜欢
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计 w397090770 9年前 (2016-05-04) 16820℃ 3评论45喜欢
如果你经常写MapReduce作业,你肯定看到过以下的异常信息:[code lang="bash"]Application application_1409135750325_48141 failed 2 times due to AM Container forappattempt_1409135750325_48141_000002 exited with exitCode: 143 due to: Container[pid=4733,containerID=container_1409135750325_48141_02_000001] is running beyond physical memory limits.Current usage: 2.0 GB of 2 GB physical memory used; 6.0 GB of w397090770 8年前 (2016-12-29) 4191℃ 1评论11喜欢
这几天由于项目的需要,需要将Flume收集到的日志插入到Hbase中,有人说,这不很简单么?Flume里面自带了Hbase sink,可以直接调用啊,还用说么?是的,我在本博客的《Flume-1.4.0和Hbase-0.96.0整合》文章中就提到如何用Flume和Hbase整合,从文章中就看出整个过程不太复杂,直接做相应的配置就行了。那么为什么今天还要特意提一下Flum w397090770 11年前 (2014-01-28) 7296℃ 2评论2喜欢
我们知道,Flume可以和许多的系统进行整合,包括了Hadoop、Spark、Kafka、Hbase等等;当然,强悍的Flume也是可以和Mysql进行整合,将分析好的日志存储到Mysql(当然,你也可以存放到pg、oracle等等关系型数据库)。 不过我这里想多说一些:Flume是分布式收集日志的系统;既然都分布式了,数据量应该很大,为什么你要将Flume分 w397090770 10年前 (2014-09-04) 25722℃ 21评论40喜欢
从名字就可以看出这是笛卡儿的意思,就是对给的两个RDD进行笛卡儿计算。官方文档说明:Return the Cartesian product of this RDD and another one, that is, the RDD of all pairs of elements (a, b) where a is in `this` and b is in `other`.函数原型[code lang="scala"]def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)][/code] 该函数返回的是Pair类型的RDD,计算结果 w397090770 10年前 (2015-03-07) 11253℃ 0评论5喜欢
2015年中国大数据技术大会已经圆满落幕,本届大会历时三天(2015-12-10~2015-12-12),以更加国际化的视野,从政策法规、技术实践和产业应用等角度深入探讨大数据落地后的挑战,作为大数据产业界、科技界与政府部门密切合作的重要平台,吸引了数千名大数据技术爱好者到场参会。 本届大会邀请了近百余位国内外顶尖的 w397090770 9年前 (2015-12-18) 5513℃ 0评论11喜欢
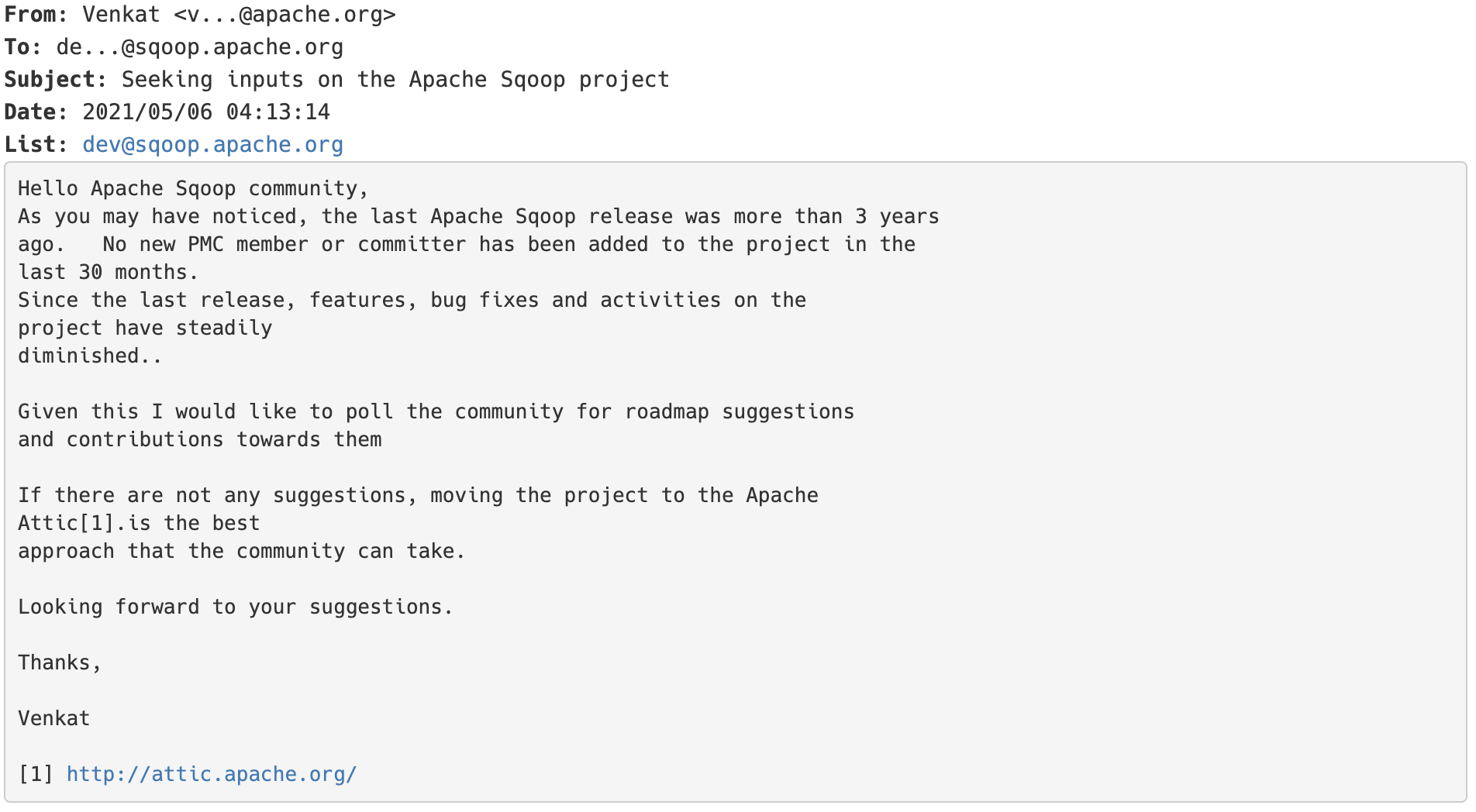
2021年05月06日,Apache Sqoop 的 PMC venkatrangan 给 Sqoop 项目的 dev 邮件列表发送了一篇名为《Seeking inputs on the Apache Sqoop project》的邮件:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据从邮件内容可以看出,Apache Sqoop 最后一次 release 的时间是三年前,最近30个月没有任何新的 PMC 和 committer 加入到 w397090770 3年前 (2021-06-27) 746℃ 0评论2喜欢
本文所列的所有API在ElasticSearch文档是有详尽的说明,但它的结构组织的不太好。 这篇文章把ElasticSearch API用表格的形式供大家参考。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopCategoryDescriptionCall examplesDocument APISingle Document APIAdds a new document[code lang="bash"]PUT / w397090770 8年前 (2017-02-20) 2428℃ 0评论9喜欢
大家对加州大学伯克利分校的AMPLab可能不太熟悉,但是它的项目我们都有所耳闻——没错,它就是Spark和Mesos的诞生之地。AMPLab是加州大学伯克利分校一个为期五年的计算机研究计划,其初衷是为了理解机器和人如何合作处理和解决数据中的问题——使用数据去训练更加丰富的模型,有效的数据清理,以及进行可衡量的数据扩展。 w397090770 8年前 (2017-02-09) 1320℃ 0评论3喜欢
在《Apache Solr 介绍及安装部署》 文章里面我简单地介绍了如何在 Linux 平台搭建单机版的 Solr 服务,而且我们已经创建了一个名为 iteblog 的 core,已经导入了相关的索引数据,接下来让我们来使用 Solr 检索这些数据。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop查询所有的数据可以使用 *:* w397090770 6年前 (2018-07-24) 1490℃ 0评论4喜欢
Hive 设计之初,就被定位一款离线数仓产品,虽然Hortonworks喊出了Make Apache Hive 100x Faster的牛逼口号,也在上面做了大量的优化,然而性能提升依旧不大。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆而随着OPPO数据量一步步的增多,动辄运行几个小时的hive再也满足不了交互查询的需求,因此我们 w397090770 4年前 (2021-03-05) 989℃ 0评论6喜欢
本文作者:李寅威,从事大数据、机器学习方面的工作,目前就职于CVTE联系方式:微信(coridc),邮箱(251469031@qq.com)原文链接: Spark2.1.0 + CarbonData1.0.0集群模式部署及使用入门1 引言 Apache CarbonData是一个面向大数据平台的基于索引的列式数据格式,由华为大数据团队贡献给Apache社区,目前最新版本是1.0.0版。介于 zz~~ 8年前 (2017-03-13) 3441℃ 0评论11喜欢
rest 接口 现在我们已经有一个正常运行的节点(和集群),下一步就是要去理解怎样与其通信。幸运的是,Elasticsearch提供了非常全面和强大的REST API,利用这个REST API你可以同你的集群交互。下面是利用这个API,可以做的几件事情: 1、查你的集群、节点和索引的健康状态和各种统计信息 2、管理你的集群、节点、 zz~~ 8年前 (2016-08-31) 1427℃ 0评论2喜欢
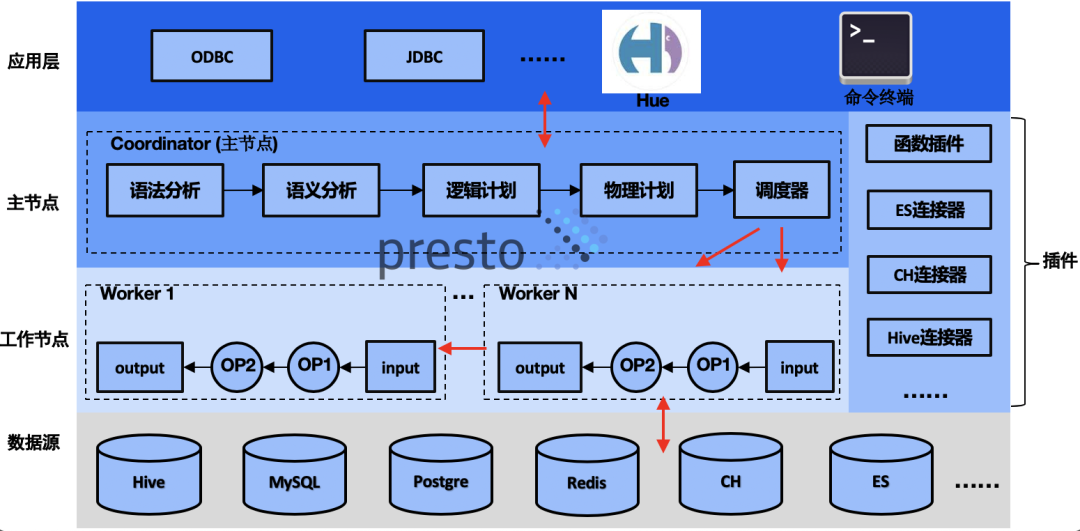
文章来源团队:腾讯医疗资讯与服务部-技术研发中心 前言:随着产品矩阵和团队规模的扩张,跨业务、APP的数据处理、分析总是不可避免。一个显而易见的问题就是异构数据源的连通。我们基于PrestoDB构建了业务线内适应腾讯生态的联邦查询引擎,连通了部门内部20+数据源实例,涵盖了90%的查询场景。同时,我们参与公司级的Pre w397090770 3年前 (2021-09-08) 536℃ 0评论1喜欢
Vim是一个高级文本编辑器,它提供了Unix下编辑器 'Vi' 的功能并对其进行了完善。Vim经常被认为是 "程序员的编辑器",它在程序编写时非常有用,很多人认为它是一个完整的集成开发环境(IDE)。仅管如此,Vim并不只是程序员使用的。Vim可以用于多种文档编辑,从email排版到配置文件编写。 在Ubuntu下安装一个Vim编辑器可以用下面 w397090770 11年前 (2013-07-19) 4976℃ 2评论2喜欢
Apache Spark 2.4 是在11月08日正式发布的,其带来了很多新的特性具体可以参见这里,本文主要介绍这次为复杂数据类型新引入的内置函数和高阶函数。本次 Spark 发布共引入了29个新的内置函数来处理复杂类型(例如,数组类型),包括高阶函数。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop w397090770 6年前 (2018-11-21) 2477℃ 0评论2喜欢
在昨天我谈到了WSDL的一些概念,今天打算谈谈为什么理解WSDL非常重要。 许多用户可能会提到的一个问题是,既然WSDL文件可以在各种主要的平台上使用工具创建,为什么还要花时间学习WSDL呢?这是因为WSDL文档非常新,学习其内容和工作原理是明智的。由于Web服务正在变得无所不在,所以,理解和掌握WSDL文档的必要性越来 w397090770 12年前 (2013-04-25) 3098℃ 1评论2喜欢
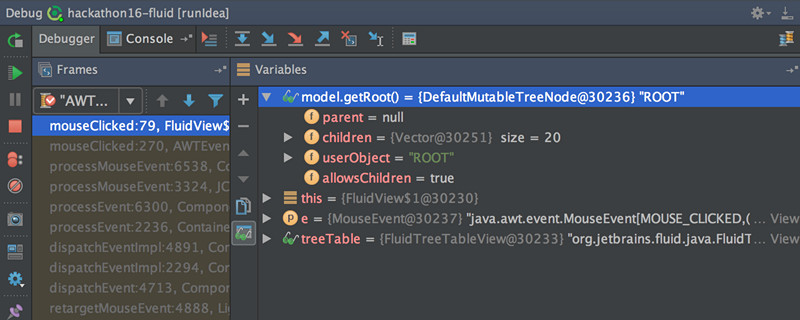
近日,被誉为最好的Java开发工具IntelliJ IDEA发布了IntelliJ IDEA 2016.2版本,这是本年度第二个发行版本。此版本带来了许多新功能,本文将列举部分比较好的功能。调试器Debugger新版本的Idea将Watches和Variables面板合在一起。此外多行表达式(multiline expressions)功能现在在断点设置中支持Condition、Evaluate和log fields,并且在Data Type w397090770 8年前 (2016-07-16) 6197℃ 0评论17喜欢
在使用Hadoop过程中,小文件是一种比较常见的挑战,如果不小心处理,可能会带来一系列的问题。HDFS是为了存储和处理大数据集(M以上)而开发的,大量小文件会导致Namenode内存利用率和RPC调用效率低下,block扫描吞吐量下降,应用层性能降低。通过本文,我们将定义小文件存储的问题,并探讨如何对小文件进行治理。什么是小 w397090770 4年前 (2021-02-24) 1042℃ 0评论6喜欢
本书于2017-08由Packt Publishing出版,作者David Blomquist, Tomasz Janiszewski,全书546页。通过本书你将学到以下知识Set up Mesos on different operating systemsUse the Marathon and Chronos frameworks to manage multiple applicationsWork with Mesos and DockerIntegrate Mesos with Spark and other big data frameworksUse networking features in Mesos for effective communication between containersConfig zz~~ 7年前 (2017-08-17) 2419℃ 0评论8喜欢
《Apache Spark快速入门:基本概念和例子(1)》 《Apache Spark快速入门:基本概念和例子(2)》 本文聚焦Apache Spark入门,了解其在大数据领域的地位,覆盖Apache Spark的安装及应用程序的建立,并解释一些常见的行为和操作。一、 为什么要选择Apache Spark 当前,我们正处在一个“大数据"的时代,每时每刻,都有各 w397090770 9年前 (2015-07-13) 6131℃ 1评论24喜欢
Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领域对开源社区的又一个非常大的贡献。Apache Beam的主要目标是统一批处理和流处理的编程范式,为无限,乱序,web-scale的数据集处理提供简单灵活,功能丰富以及表达能力十分强大的SDK。此项 w397090770 8年前 (2017-04-14) 2582℃ 0评论6喜欢
摘要:本文是来自米哈游大数据部对于Flink在米哈游应用及实践的分享。 本篇内容主要分为四个部分: 1.背景介绍 2.实时平台建设 3.实时数仓和数据湖探索 4.未来发展与展望 作者:实时计算负责人 张剑 背景介绍 米哈游成立于2011年,致力于为用户提供美好的、超出预期的产品与内容。公司陆续推出了 w397090770 3年前 (2022-03-21) 1627℃ 1评论6喜欢
根据官方文档,Spark可以用Maven进行编译,但是我试了好几个版本都编译不通过,所以没用(如果大家用Maven编译通过了Spark,求分享。)。这里是利用sbt对Spark进行编译。中间虽然也遇到了很多问题,但是经过几天的折腾,终于通过了,关于如何解决编译中间出现的问题,可以参见本博客的《Spark源码编译遇到的问题解决》进行 w397090770 11年前 (2014-04-18) 11058℃ 3评论7喜欢













![[电子书]Apache Mesos Cookbook PDF下载](https://www.iteblog.com/pic/books/Apache_Mesos_Cookbook_iteblog.png)