本文是面向Spark初学者,有Spark有比较深入的理解同学可以忽略。前言很多初学者其实对Spark的编程模式还是RDD这个概念理解不到位,就会产生一些误解。比如,很多时候我们常常以为一个文件是会被完整读入到内存,然后做各种变换,这很可能是受两个概念的误导:1、RDD的定义,RDD是一个分布式的不可变数据集合; w397090770 9年前 (2016-04-20) 8435℃ 0评论33喜欢
本书是2013年09月出版,全书共298页,这里提供的本书完整英文版电子书。 w397090770 9年前 (2015-08-16) 2649℃ 0评论7喜欢
这里说明一点:本文提到的解决Spark insertIntoJDBC找不到Mysql驱动的方法是针对单机模式(也就是local模式)。在集群环境下,下面的方法是不行的。这是因为在分布式环境下,加载mysql驱动包存在一个Bug,1.3及以前的版本 --jars 分发的jar在executor端是通过Spark自身特化的classloader加载的。而JDBC driver manager使用的则是系统默认的classloader w397090770 10年前 (2015-04-03) 19109℃ 3评论15喜欢
为了更好的使用 Apache Iceberg,理解其时间旅行是很有必要的,这个其实也会对 Iceberg 表的读取过程有个大致了解。不过在介绍 Apache Iceberg 的时间旅行(Time travel)之前,我们需要了解 Apache Iceberg 的底层数据组织结构。Apache Iceberg 的底层数据组织我们在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中详细地介绍了 Apache I w397090770 4年前 (2020-11-29) 3611℃ 0评论4喜欢
Apache Hive 1.2.0于美国时间2015年05月18日正式发布,其中修复了大量大Bug,完整邮件内容如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopThe Apache Hive team is proud to announce the the release of Apache Hive version 1.2.0.The Apache Hive (TM) data warehouse software facilitates querying and managing large datasets residin w397090770 9年前 (2015-05-19) 5403℃ 0评论4喜欢
相信很多网站为了方便使用了百度分享工具,但是官方提供的类库只支持HTTP方式来访问,如果你网站升级成HTTPS之后,将无法使用百度分享。不过大家别担心,本文就是来教大家解决这个问题的。 原理很简单,下载本文下面提供的包(static.tgz),然后放到你网站的根目录,这些文件其实就是从百度分享网站下载下来的,如 w397090770 8年前 (2016-12-31) 2941℃ 0评论8喜欢
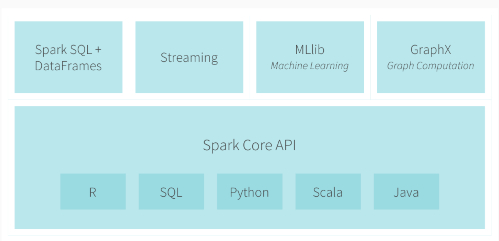
现在Apache Spark已形成一个丰富的生态系统,包括官方的和第三方开发的组件或工具。后面主要给出5个使用广泛的第三方项目。Spark官方构建了一个非常紧凑的生态系统组件,提供各种处理能力。 下面是Spark官方给出的生态系统组件 1、Spark DataFrames:列式存储的分布式数据组织,类似于关系型数据表。 2、Spark SQL:可 w397090770 9年前 (2016-03-08) 4939℃ 2评论7喜欢
一个功能健全的kafka集群可以处理相当大的数据量,由于消息系统是很多大型应用的基石,因此broker集群在性能上的缺陷,都会引起整个应用栈的各种问题。Kafka的度量指标主要有以下三类:1.Kafka服务器(Kafka)指标2.生产者指标3.消费者指标另外,由于Kafka的状态靠Zookeeper来维护,对于Zookeeper性能的监控也成为了整个Ka zz~~ 2年前 (2022-05-01) 1293℃ 0评论0喜欢
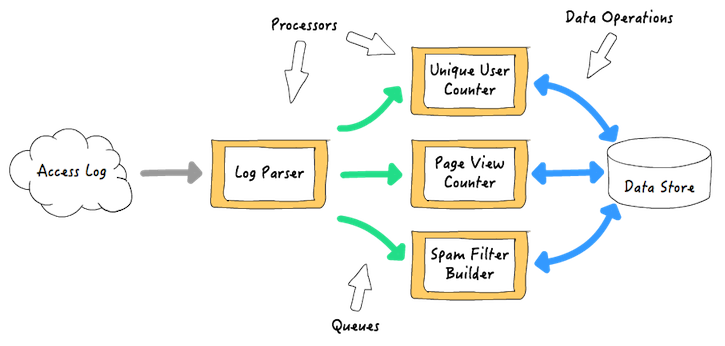
一个实时流处理框架通常需要两个基础架构:处理器和队列。处理器从队列中读取事件,执行用户的处理代码,如果要继续对结果进行处理,处理器还会把事件写到另外一个队列。队列由框架提供并管理。队列做为处理器之间的缓冲,传输数据和事件,这样处理器可以单独操作和扩展。例如,一个web 服务访问日志处理应用,可能是 w397090770 7年前 (2017-07-12) 584℃ 0评论0喜欢
点击试试使用Github登录我博客。 随着使用Github的人越来越多,为自己的网站添加Github登录功能也越来越有必要了。Github开放了登录API,第三方网站可以通过调用Github的OAuth相关API读取到登录用户的基本信息,从而使得用户可以通过Github登录到我们的网站。今天来介绍一下如何使用Github的OAuth相关API登录到Wordpress。 w397090770 10年前 (2015-04-12) 11934℃ 9评论12喜欢
一. 问答题1) datanode在什么情况下不会备份?2) hdfs的体系结构?3) sqoop在导入数据到mysql时,如何让数据不重复导入?如果存在数据问题sqoop如何处理?4) 请列举曾经修改过的/etc下的配置文件,并说明修改要解决的问题?5) 描述一下hadoop中,有哪些地方使用了缓存机制,作用分别是什么?二. 计算题1、使用Hive或 w397090770 8年前 (2016-08-26) 4265℃ 1评论4喜欢
经常使用 Apache Spark 从 Kafka 读数的同学肯定会遇到这样的问题:某些 Spark 分区已经处理完数据了,另一部分分区还在处理数据,从而导致这个批次的作业总消耗时间变长;甚至导致 Spark 作业无法及时消费 Kafka 中的数据。为了简便起见,本文讨论的 Spark Direct 方式读取 Kafka 中的数据,这种情况下 Spark RDD 中分区和 Kafka 分区是一一对 w397090770 6年前 (2018-09-08) 6616℃ 0评论25喜欢
!! expr :逻辑非。%expr1 % expr2 - 返回 expr1/expr2 的余数.例子:[code lang="sql"]> SELECT 2 % 1.8; 0.2> SELECT MOD(2, 1.8); 0.2[/code]&expr1 & expr2 - 返回 expr1 和 expr2 的按位AND的结果。例子:[code lang="sql"]> SELECT 3 & 5; 1[/code]*expr1 * expr2 - 返回 expr1*expr2.例子:[code lang="sql"]> SELECT 2 * 3; 6[/code]+ w397090770 6年前 (2018-07-13) 16562℃ 0评论2喜欢
2020年12月01日,IntelliJ IDEA 2020.3 正式发布,这是2020年的第三个里程碑版本。2020年其他两个版本可以参见IntelliJ IDEA 2020.2 稳定版发布 和 IntelliJ IDEA 2020.1 稳定版发布。本文主要介绍 IntelliJ IDEA 2020.3 的新功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop用户体验重新设置欢迎界面这个 w397090770 4年前 (2020-12-10) 1035℃ 0评论0喜欢
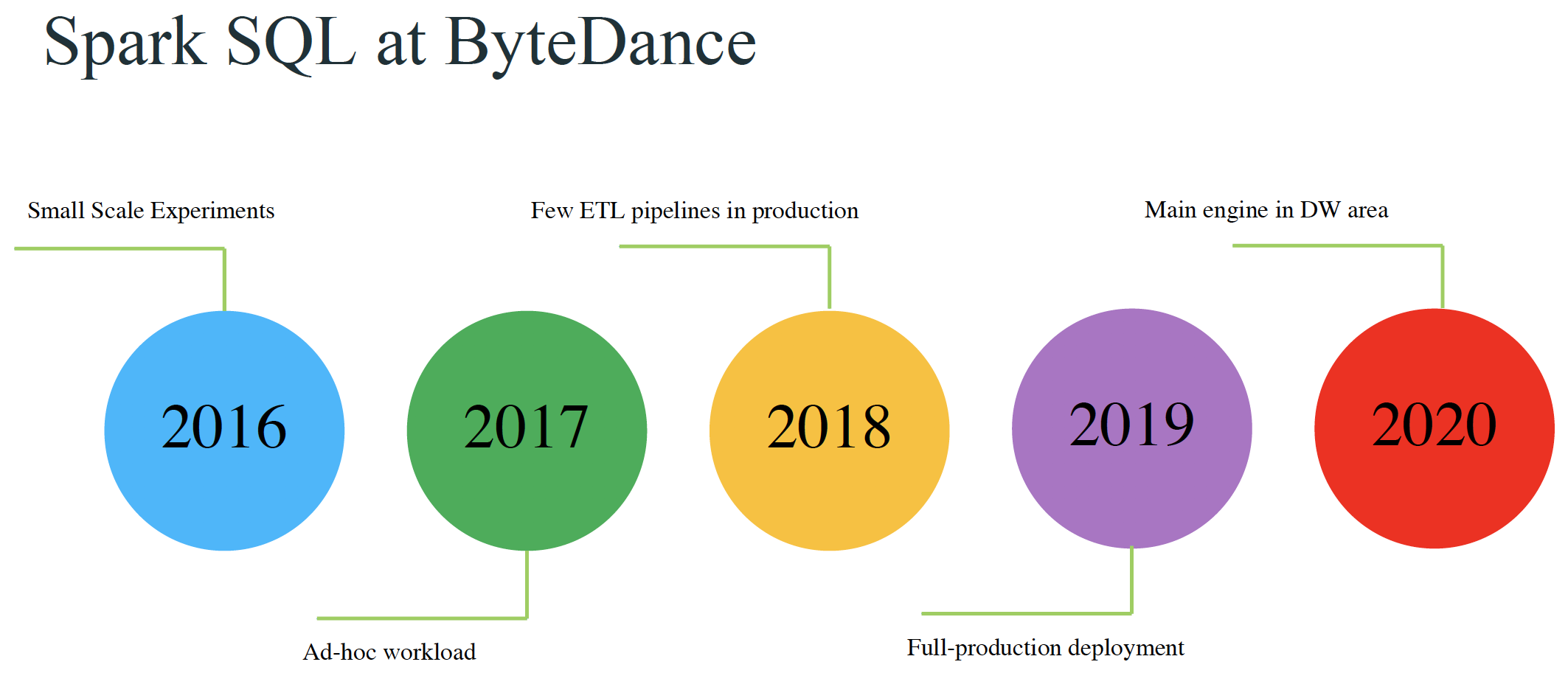
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Improving Spark SQL Performance by 30%: How We Optimize Parquet Filter Pushdown and Parquet Reader》的分享,作者为字节跳动的孙科和郭俊。相关 PPT 可以关注 Java与大数据架构 公众号并回复 9912 获取。Parquet 是一种非常流行的列式存储格式。Spark 的算子下推(pushdown filters)可以利用 P w397090770 4年前 (2020-12-14) 2410℃ 2评论4喜欢
最近在一个项目中使用到Play的Json相关的类库,看名字就知道这是和Json打交道的类库。其可以很方面地将class转换成Json字符串;也可以将Json字符串转换成一个类。一般的转换直接看Play的相关文档即可很容易的搞定,将class转换成Json字符串直接写个Writes即可;而将Json字符串转换成一个类直接写个Reads即可。所有的操作只需要引入 w397090770 8年前 (2016-08-27) 3225℃ 0评论14喜欢
2014年7月11日,Spark 1.0.1已经发布了,原文如下:We are happy to announce the availability of Spark 1.0.1! This release includes contributions from 70 developers. Spark 1.0.0 includes fixes across several areas of Spark, including the core API, PySpark, and MLlib. It also includes new features in Spark’s (alpha) SQL library, including support for JSON data and performance and stability fixes.Visit the relea w397090770 10年前 (2014-07-13) 6880℃ 0评论4喜欢
《Spark Streaming和Kafka整合开发指南(一)》 《Spark Streaming和Kafka整合开发指南(二)》 Apache Kafka是一个分布式的消息发布-订阅系统。可以说,任何实时大数据处理工具缺少与Kafka整合都是不完整的。本文将介绍如何使用Spark Streaming从Kafka中接收数据,这里将会介绍两种方法:(1)、使用Receivers和Kafka高层次的API;(2) w397090770 10年前 (2015-04-19) 33696℃ 0评论33喜欢
在 《一条 SQL 在 Apache Spark 之旅(上)》 文章中我们介绍了一条 SQL 在 Apache Spark 之旅的 Parser 和 Analyzer 两个过程,本文接上文继续介绍。优化逻辑计划阶段 - Optimizer在前文的绑定逻辑计划阶段对 Unresolved LogicalPlan 进行相关 transform 操作得到了 Analyzed Logical Plan,这个 Analyzed Logical Plan 是可以直接转换成 Physical Plan 然后在 Spark 中执 w397090770 5年前 (2019-06-18) 5650℃ 4评论21喜欢
课程讲师:Cloudy 课程分类:Java 适合人群:初级 课时数量:8课时 用到技术:Zookeeper、Web界面监控 涉及项目:案例实战 此视频百度网盘免费下载。本站所有下载资源收集于网络,只做学习和交流使用,版权归原作者所有,若为付费视频,请在下载后24小时之内自觉删除,若作商业用途,请购 w397090770 10年前 (2015-04-18) 34785℃ 2评论57喜欢
FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:下载(Download)和上传(Up w397090770 6年前 (2018-05-23) 5212℃ 0评论7喜欢
在本文中,我将分享一些关于如何编写可伸缩的 Apache Spark 代码的技巧。本文提供的示例代码实际上是基于我在现实世界中遇到的。因此,通过分享这些技巧,我希望能够帮助新手在不增加集群资源的情况下编写高性能 Spark 代码。背景我最近接手了一个 notebook ,它主要用来跟踪我们的 AB 测试结果,以评估我们的推荐引擎的性能 w397090770 5年前 (2019-11-26) 1575℃ 0评论4喜欢
最近突然收到线上服务器发出来的磁盘满了的报警,然后到服务器上发现 Apache Spark 的历史服务器(HistoryServer)日志居然占了近 500GB,如下所示:[code lang="bash"][root@iteblog.com spark]# ll -htotal 328-rw-rw-r-- 1 spark spark 15.4G Jul 11 13:09 spark-spark-org.apache.spark.deploy.history.HistoryServer-1-iteblog.com.out-rw-rw-r-- 1 spark spark 369M May 30 09:07 spark-spark-org.a w397090770 6年前 (2018-10-29) 2196℃ 0评论2喜欢
CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号。在本文中的CSV格式的数据就不是简单的逗号分割的),其文件以纯文本形式存储表格数据(数字和文本)。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字 w397090770 10年前 (2015-01-26) 9643℃ 0评论12喜欢
1、内存不够[code lang="JAVA"][ERROR] PermGen space -> [Help 1][ERROR] [ERROR] To see the full stack trace of the errors,re-run Maven with the -e switch.[ERROR] Re-run Maven using the -X switch to enable full debug logging.[ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles:[ERROR] [Help 1]http://cwiki.apache.org/confluence/display/MAVEN/OutOfMemoryErr w397090770 11年前 (2014-04-16) 15499℃ 4评论9喜欢
Finatra Finatra是一款基于TwitterServer和Finagle的快速、可测试的Scala异步框架。Finatra is a fast, testable, Scala services built on TwitterServer and Finagle.Play Play是一款轻量级、无状态的WEB友好框架。使用Java和Scala可以很方便地创建web应用程序。Play is based on a lightweight, stateless, web-friendly architecture.Play Framework makes it easy to build web application w397090770 9年前 (2015-12-25) 12562℃ 0评论15喜欢
XML(可扩展标记语言,英语:eXtensible Markup Language,简称: XML)是一种标记语言,也是行业标准数据交换交换格式,它很适合在系统之间进行数据存储和交换(话说Hadoop、Hive等的配置文件就是XML格式的)。本文将介绍如何使用MapReduce来读取XML文件。但是Hadoop内部是无法直接解析XML文件;而且XML格式中没有同步标记,所以并行地处 w397090770 9年前 (2016-03-07) 5812℃ 1评论7喜欢
商业敏感数据虽然难以获取,但好在仍有相当多有用数据可公开访问。它们中的不少常用来作为特定机器学习问题的基准测试数据。常见的有以下几个:UCL机器学习知识库包括近300个不同大小和类型的数据集,可用于分类、回归、聚类和推荐系统任务。数据集列表位于:http://archive.ics.uci.edu/ml/Amazon AWS公开数据集包含的 w397090770 9年前 (2016-03-22) 8290℃ 0评论9喜欢
Git 的代码回滚主要有 reset 和 revert,本文介绍其用法如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopreset一般用法是 [code lang="bash"]git reset --hard commit_id[/code]其中 commit_id 是使用 git log 查看的 id,如下:[code lang="bash"]$ git logcommit 26721c73c6bb82c8a49aa94ce06024f592032d0cAuthor: iteblog <iteblog@iteb w397090770 4年前 (2020-10-12) 1269℃ 0评论0喜欢
Databricks官网昨天发布了一篇关于Spark用206个节点打破了原来MapReduce 100TB和1PB排序的世界记录。先前的世界记录是Yahoo在2100个Hadoop节点上运行MapReduce 对102.5 TB数据进行排序,他的运行时间是72分钟;而此次的Spark采用了206 个EC2节点,并部署了Spark,对100 TB的数据进行排序,一共用了23分钟!并且所有的排序都是基于磁盘的。也就是 w397090770 10年前 (2014-10-11) 12271℃ 2评论15喜欢










![Play JSON类库将List[(String, String)]转换成Json字符串](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/4.jpg)