《Spark Python API函数学习:pyspark API(1)》 《Spark Python API函数学习:pyspark API(2)》 《Spark Python API函数学习:pyspark API(3)》 《Spark Python API函数学习:pyspark API(4)》 Spark支持Scala、Java以及Python语言,本文将通过图片和简单例子来学习pyspark API。.wp-caption img{ max-width: 100%; height: auto;}如果想 w397090770 9年前 (2015-06-28) 18894℃ 1评论16喜欢
如果你在Spark SQL中运行的SQL语句过长的话,会出现 java.lang.StackOverflowError 异常:[code lang="java"]java.lang.StackOverflowError at org.apache.spark.sql.hive.HiveQl$$anonfun$22.apply(HiveQl.scala:924) at org.apache.spark.sql.hive.HiveQl$$anonfun$22.apply(HiveQl.scala:924) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244) at scala.collection.TraversableLike$$anonfun w397090770 7年前 (2017-05-17) 6266℃ 0评论7喜欢
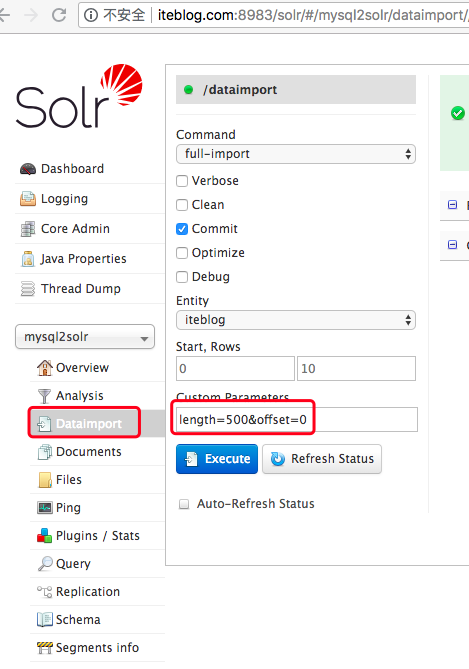
在 《将 MySQL 的全量数据导入到 Apache Solr 中》 文章中介绍了如何将 MySQL 中的全量数据导入到 Solr 中。里面提到一个问题,那就是如果数据量很大的时候,一次性导入数据可能会影响 MySQL ,这种情况下能不能分页导入呢?答案是肯定的,本文将介绍如何通过分页的方式将 MySQL 里面的数据导入到 Solr。分页导数的方法和全量导大部 w397090770 6年前 (2018-08-07) 1452℃ 0评论1喜欢
关系运算1、等值比较: =语法:A=B操作类型:所有基本类型描述: 如果表达式A与表达式B相等,则为TRUE;否则为FALSE[code lang="sql"]hive> select 1 from iteblog where 1=1;1[/code]2、不等值比较: 语法: A B操作类型: 所有基本类型描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A与表达式B不相等,则为TRUE;否则为 zz~~ 7年前 (2017-09-14) 93483℃ 3评论183喜欢
前提条件: 1、安装好jdk1.6或以上版本 2、部署好Hadoop 2.2.0(可以参见本博客《Hadoop2.2.0完全分布式集群平台安装与设置》) 3、安装好ant,这很简单:[code lang="JAVA"]$ wget http://mirrors.cnnic.cn/apache/ant/binaries/apache-ant-1.9.3-bin.tar.gz$ tar -zxvf apache-ant-1.9.3-bin.tar.gz[/code]然后设置好ANT_HOME和PATH就行 4、安装好相 w397090770 11年前 (2014-03-26) 23786℃ 1评论35喜欢
HDFS 架构介绍 HDFS离线存储平台是Hadoop大数据计算的底层架构,在B站应用已经超过5年的时间。经过多年的发展,HDFS存储平台目前已经发展成为总存储数据量近EB级,元数据总量近百亿级,NameSpace 数量近20组,节点数量近万台,日均吞吐几十PB数据量的大型分布式文件存储系统。 首先我们来介绍一下B站的HDFS离线存储平台的总体架 w397090770 3年前 (2022-04-01) 1088℃ 0评论4喜欢
当用户未定义一个默认的构造函数,编译器并不是在任何时候都给自动给我们定义一个默认的构造函数,它只会在编译器需要的时候才会生成,并且只有class类型的变量会被初始化,其他的诸如内置类型变量或者指针都不会被初始化,这些变量的初始化工作是程序员的责任。同样,一个类的默认复制构造函数也不是什么时候都会 w397090770 12年前 (2013-04-04) 32005℃ 0评论1喜欢
Snappy是用C++开发的压缩和解压缩开发包,旨在提供高速压缩速度和合理的压缩率。Snappy比zlib更快,但文件相对要大20%到100%。在64位模式的Core i7处理器上,可达每秒250~500兆的压缩速度。 Snappy的前身是Zippy。虽然只是一个数据压缩库,它却被Google用于许多内部项目程,其中就包括BigTable,MapReduce和RPC。Google宣称它在这个库本 w397090770 11年前 (2014-03-03) 13575℃ 1评论2喜欢
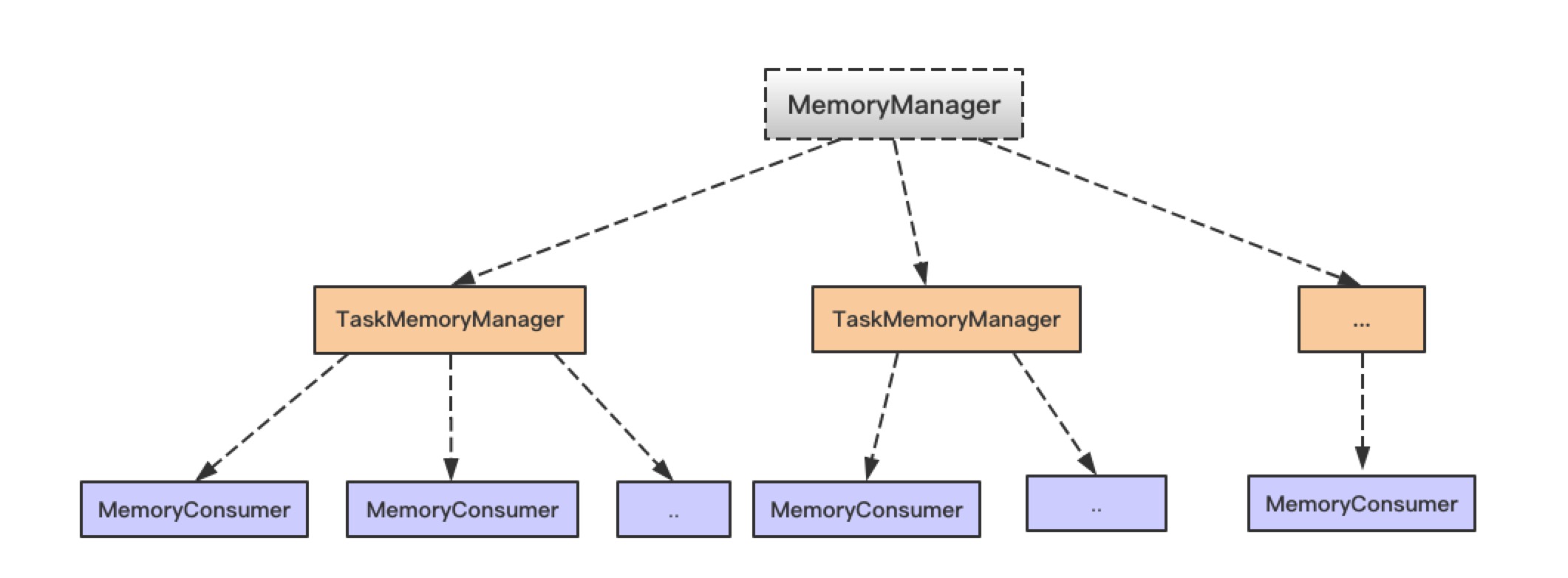
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段。那么在 Spark Shuffle 中具体是哪些地方会使用比较多的内存而有可能导致 OOM 呢? 为此,本文将围绕以上问题梳理 Spark 内存管理和 Shuffle 过程中与内存使用相关的知识;然后,简要分析下在 Spark Shuffle 中有可能导致 OOM w397090770 6年前 (2019-03-17) 5358℃ 0评论19喜欢
Spark已经成为数据科学专业人士最有前途的大数据分析引擎。Apache Spark真正的力量和价值在于它能够以高速和准确的方式执行数据科学任务;Spark的卖点是它结合ETL,批处理分析,实时流分析,机器学习,图形处理和可视化;它允许您轻松处理非结构化的原始数据集。 本书将让您舒适和自信地使用Spark完成数据科学任务。 w397090770 8年前 (2017-02-10) 2205℃ 0评论6喜欢
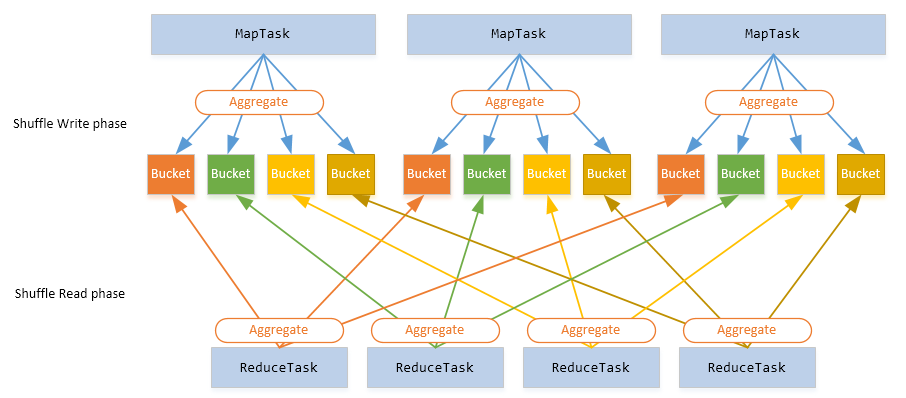
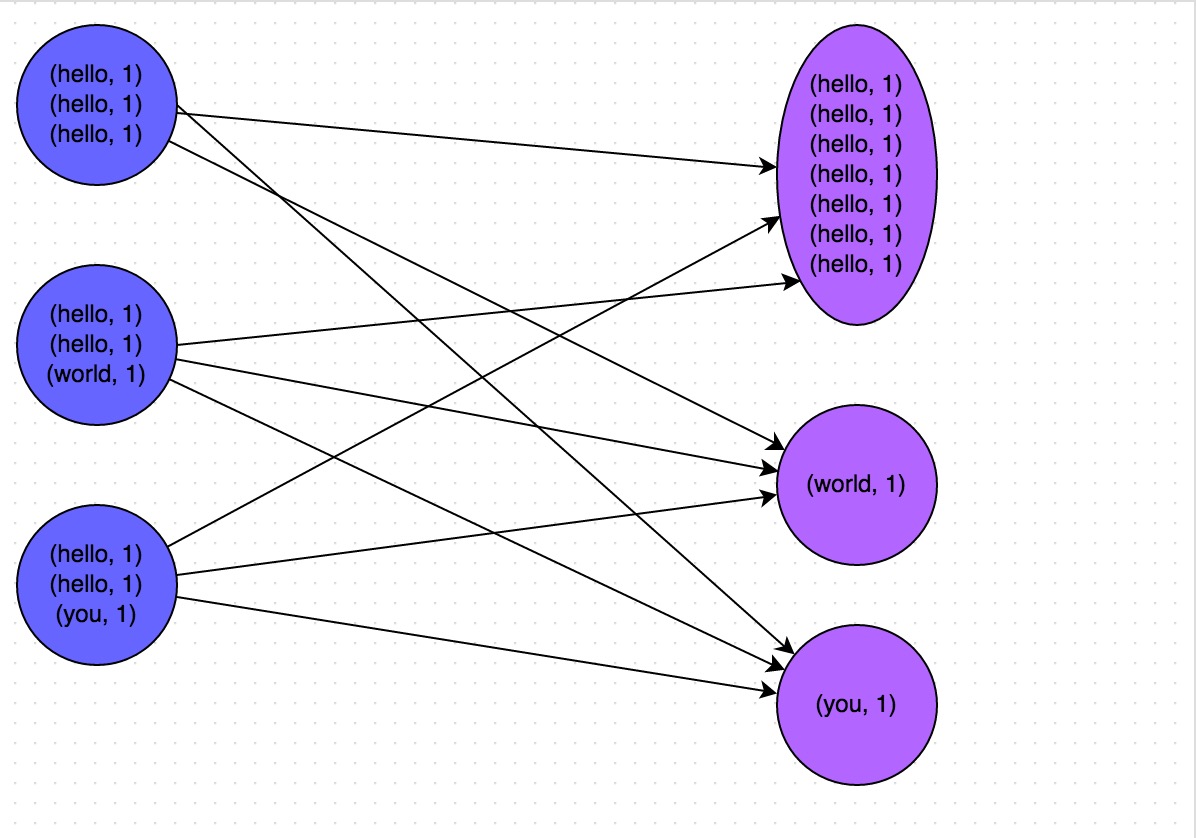
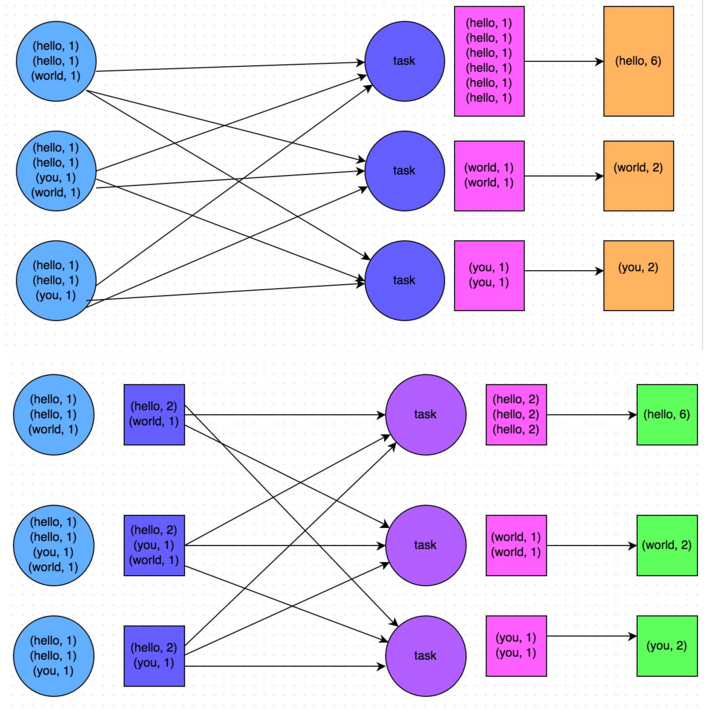
Spark Shuffle 基础在 MapReduce 框架中,Shuffle 是连接 Map 和 Reduce 之间的桥梁,Reduce 要读取到 Map 的输出必须要经过 Shuffle 这个环节;而 Reduce 和 Map 过程通常不在一台节点,这意味着 Shuffle 阶段通常需要跨网络以及一些磁盘的读写操作,因此 Shuffle 的性能高低直接影响了整个程序的性能和吞吐量。与 MapReduce 计算框架一样,Spark 作 w397090770 7年前 (2017-11-15) 7464℃ 3评论30喜欢
本文将介绍如何通过简单地几步来开始编写你的 Flink Java 程序。要求 编写你的Flink Java程序唯一的要求是需要安装Maven 3.0.4(或者更高)和Java 7.x(或者更高) 创建Flink Java工程使用下面其中一个命令来创建Flink Java工程1、使用Maven archetypes:[code lang="bash"]$ mvn archetype:generate \ -DarchetypeGrou w397090770 9年前 (2016-04-06) 13883℃ 0评论8喜欢
bsie是使得IE6可以支持Bootstrap的补丁,Bootstrap是 twitter.com 推出的非常棒web UI工具库。目前,bsie使得IE6能支持bootstrap大部分特性,可惜,还有一些实在无法支持...下面的这个表格就是当前已经被支持的bootstrap的组件和特性:[code lang="bash"]组件 特性-----------------------------------------------------------grid fixed, fluidnavbar w397090770 9年前 (2015-12-26) 2317℃ 7评论3喜欢
近几年来,人工智能逐渐火热起来,特别是和大数据一起结合使用。人工智能的主要场景又包括图像能力、语音能力、自然语言处理能力和用户画像能力等等。这些场景我们都需要处理海量的数据,处理完的数据一般都需要存储起来,这些数据的特点主要有如下几点:大:数据量越大,对我们后面建模越会有好处;稀疏:每行 w397090770 6年前 (2018-11-22) 3296℃ 1评论10喜欢
今天早上 06:53(2019年11月08日 06:53) 数砖的 Xingbo Jiang 大佬给社区发了一封邮件,宣布 Apache Spark 3.0 预览版正式发布,这个版本主要是为了对即将发布的 Apache Spark 3.0 版本进行大规模社区测试。无论是从 API 还是从功能上来说,这个预览版都不是一个稳定的版本,它的主要目的是为了让社区提前尝试 Apache Spark 3.0 的新特性。如果大家想 w397090770 5年前 (2019-11-08) 2064℃ 0评论6喜欢
搜索API允许开发者执行搜索查询,返回匹配查询的搜索结果。这既可以通过查询字符串也可以通过查询体实现。多索引多类型所有的搜索API都可以跨多个类型使用,也可以通过多索引语法跨索引使用。例如,我们可以搜索twitter索引的跨类型的所有文档。[code lang="java"]$ curl -XGET 'http://localhost:9200/twitter/_search?q=user:kimchy'[/ zz~~ 8年前 (2016-09-22) 1667℃ 0评论2喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Apache Hudi : The Path Forward》的分享,作者来自Apache Hudi 项目的原始创建者和副总裁 Vinoth Chandar 和 Zendesk 的 Raymond Xu。Raymond Xu leads the Data Lake team at Zendesk. He is also a PMC member and committer for Apache Hudi.Vinoth Chandar is the original creator & VP of the Apache Hudi project, which has changed the face of data lake archi w397090770 3年前 (2021-11-16) 463℃ 0评论1喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 今天我很激动地宣布Spark 1.1.0发布了,Spark 1.1.0引入了许多新特征(new features)包括了可扩展性和稳定性方面的提升。这篇文章主要是介绍了Spark 1.1.0主要的特性,下面的介绍主要是根据各个特征重要性的优先级进行说明的。在接下来的两个星 w397090770 10年前 (2014-09-12) 4691℃ 2评论8喜欢
杭州第六次 Spark & Flink Meetup 于2018年05月12日在华为杭研所1号楼1楼报告厅进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop议题本次会议的议题如下:冯叶磊 - 华为云 《Time GeoSpatial on Flink SQL》范文臣 - Spark PMC 《deep dive into structural streaming》梁永峰 - 阿里《基于Flink的流计算平台 w397090770 6年前 (2018-05-13) 3926℃ 1评论8喜欢
尽量不要把数据 collect 到 Driver 端如果你的 RDD/DataFrame 非常大,drive 端的内存无法放下所有的数据时,千万别这么做[code lang="scala"]data = df.collect()[/code]Collect 函数会尝试将 RDD/DataFrame 中所有的数据复制到 driver 端,这时候肯定会导致 driver 端的内存溢出,然后进程出现 crash。如果想及时了解Spark、Hadoop或者HBase相关的文章, w397090770 4年前 (2020-06-23) 749℃ 0评论3喜欢
Spark的其中一个目标就是使得大数据应用程序的编写更简单。Spark的Scala和Python的API接口很简洁;但由于Java缺少函数表达式(function expressions), 使得Java API有些冗长。Java 8里面增加了lambda表达式,Spark开发者们更新了Spark的API来支持Java8的lambda表达式,而且与旧版本的Java保持兼容。这些支持将会在Spark 1.0可用。如果想及时了解 w397090770 10年前 (2014-07-10) 13193℃ 0评论18喜欢
相关文章:《Apache Flink 1.1.0和1.1.1发布,支持SQL》 Apache Flink 1.1.2于2016年09月05日正式发布,此版本主要是修复一些小bug,推荐所有使用Apache Flink 1.1.0以及Apache Flink 1.1.1的用户升级到此版本,我们可以在pom.xml文件引入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</a zz~~ 8年前 (2016-09-06) 1350℃ 0评论1喜欢
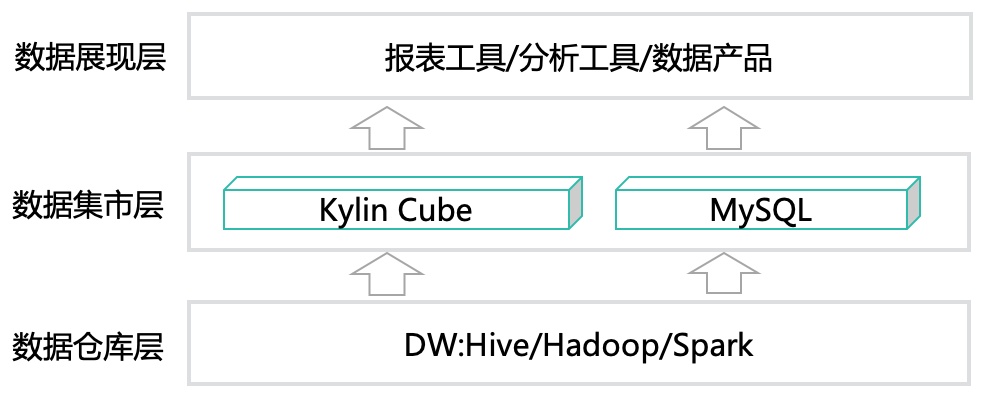
序言美团外卖数据仓库技术团队负责支撑日常业务运营及分析师的日常分析,由于外卖业务特点带来的数据生产成本较高和查询效率偏低的问题,他们通过引入Apache Doris引擎优化生产方案,实现了低成本生产与高效查询的平衡。并以此分析不同业务场景下,基于Kylin的MOLAP模式与基于Doris引擎的ROLAP模式的适用性问题。希望能对大家有 w397090770 4年前 (2020-04-17) 2371℃ 0评论3喜欢
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》前言 继《Spark性能优化:开发调优篇》和《Spark性能优化:资源调优篇》讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为《Spark性能优化指南》的高级篇,将深入分析 w397090770 8年前 (2016-05-14) 15577℃ 0评论30喜欢
如果我们需要通过编程的方式来获取到Kafka中某个Topic的所有分区、副本、每个分区的Leader(所在机器及其端口等信息),所有分区副本所在机器的信息和ISR机器的信息等(特别是在使用Kafka的Simple API来编写SimpleConsumer的情况)。这一切可以通过发送TopicMetadataRequest请求到Kafka Server中获取。代码片段如下所示:[code lang="scala"]de w397090770 8年前 (2016-05-09) 8251℃ 0评论4喜欢
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计 w397090770 9年前 (2016-05-04) 16820℃ 3评论45喜欢
题目:一个数组里,除了三个数是唯一出现的,其余的都出现偶数个,找出这三个数中的任一个。比如数组元素为【1, 2,4,5,6,4,2】,只有1,5,6这三个数字是唯一出现的,我们只需要输出1,5,6中的一个就行。下面是我的思路:这个数组元素个数一定为奇数,而且那要求的三个数一定不可能每一bit位都相同,所以我们可以找到其中一个b w397090770 12年前 (2013-03-31) 4066℃ 1评论4喜欢
在Debian平台,请输入以下的命令[code lang="JAVA"]$ sudo vi /etc/apt/sources.list[/code]在里面加入下面的一行[code lang="JAVA"]deb http://ftp.us.debian.org/debian/ squeeze main non-free[/code]然后保存退出(:wq)之后,执行下面的命令[code lang="JAVA"]$ sudo apt-get update[/code]安装Java执行环境运行下面命令[code lang="JAVA"]$ sudo apt-get install sun-java6-jre[/ w397090770 11年前 (2013-10-21) 6163℃ 2评论3喜欢
美国时间2015年2月09日Spark 1.2.1正式发布了,邮件如下:Hi All,I've just posted the 1.2.1 maintenance release of Apache Spark. We recommend all 1.2.0 users upgrade to this release, as this release includes stability fixes across all components of Spark.- Download this release: http://spark.apache.org/downloads.html- View the release notes: http://spark.apache.org/releases/spark-release-1-2-1.html- w397090770 10年前 (2015-02-10) 3480℃ 0评论2喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》、《Hadoop从入门到上手企业开发视 w397090770 10年前 (2015-02-28) 96467℃ 381评论279喜欢






![[电子书]Apache Spark for Data Science Cookbook PDF下载](https://www.iteblog.com/pic/books/Spark_for_Data_Science_Cookbook_iteblog.jpg)