2014年7月11日,Spark 1.0.1已经发布了,原文如下:We are happy to announce the availability of Spark 1.0.1! This release includes contributions from 70 developers. Spark 1.0.0 includes fixes across several areas of Spark, including the core API, PySpark, and MLlib. It also includes new features in Spark’s (alpha) SQL library, including support for JSON data and performance and stability fixes.Visit the relea w397090770 10年前 (2014-07-13) 6880℃ 0评论4喜欢
随着 Uber 业务的扩张,为其提供支持的基础数据呈指数级增长,因此处理成本也越来越高。 当大数据成为我们最大的运营开支之一时,我们开始了一项降低数据平台成本的举措,该计划将挑战分为三部分:平台效率、供应和需求。 本文将讨论我们为提高数据平台效率和降低成本所做的努力。如果想及时了解Spark、Hadoop或者HBase w397090770 3年前 (2021-09-05) 424℃ 0评论2喜欢
昨天分享了《[电子书]Apache Spark 2 for Beginners pdf下载》,这本书很适合入门学习Spark,虽然书名上写着是Apache Spark 2,但是其内容介绍几乎和Spark 2毫无关系,今天要分享的图书也是一本适合入门的Spark电子书,也是Packt出版,2016年09月开始发行的,全书共339页,其面向读者是数据科学家,本书内容涵盖了Spark编程模型、DataFrame介绍 w397090770 8年前 (2016-10-24) 5071℃ 0评论13喜欢
随着图像分类(image classification)和对象检测(object detection)的深度学习框架的最新进展,开发者对 Apache Spark 中标准图像处理的需求变得越来越大。图像处理和预处理有其特定的挑战 - 比如,图像有不同的格式(例如,jpeg,png等),大小和颜色,并且没有简单的方法来测试正确性。图像数据源通过给我们提供可以编码的标准表 w397090770 6年前 (2018-12-13) 2438℃ 0评论4喜欢
摘要:本文是来自米哈游大数据部对于Flink在米哈游应用及实践的分享。 本篇内容主要分为四个部分: 1.背景介绍 2.实时平台建设 3.实时数仓和数据湖探索 4.未来发展与展望 作者:实时计算负责人 张剑 背景介绍 米哈游成立于2011年,致力于为用户提供美好的、超出预期的产品与内容。公司陆续推出了 w397090770 3年前 (2022-03-21) 1627℃ 1评论6喜欢
我们在《Tachyon 0.7.0伪分布式集群安装与测试》文章中介绍了如何搭建伪分布式Tachyon集群。从官方文档得知,Spark 1.4.x和Tachyon 0.6.4版本兼容,而最新版的Tachyon 0.7.1和Spark 1.5.x兼容,目前最新版的Spark为1.4.1,所以下面的操作步骤全部是基于Tachyon 0.6.4平台的,Tachyon 0.6.4的搭建步骤和Tachyon 0.7.0类似。 废话不多说,开始介绍吧 w397090770 9年前 (2015-08-31) 5473℃ 0评论6喜欢
2021年2月1日, Databricks 在其博客宣布将投资10亿美元,以应对其统一数据平台(unified data platform)在全球的快速普及。 本次融资由富兰克林·邓普顿(Franklin Templeton)领投,加拿大养老金计划投资委员会(Canada Pension Plan Investment Board)、富达管理与研究有限责任公司(Fidelity Management & Research LLC)和 Whale Rock(美国的媒体和技术公 w397090770 4年前 (2021-02-02) 632℃ 0评论3喜欢
Efficient processing of big data, especially with Spark, is really all about how much memory one can afford, or how efficient use one can make of the limited amount of available memory. Efficient memory utilization, however, is not what one can take for granted with default configuration shipped with Spark and Yarn. Rather, it takes very careful provisioning and tuning to get as much as possible from the bare metal. In this post I’ll w397090770 4年前 (2020-09-09) 962℃ 0评论0喜欢
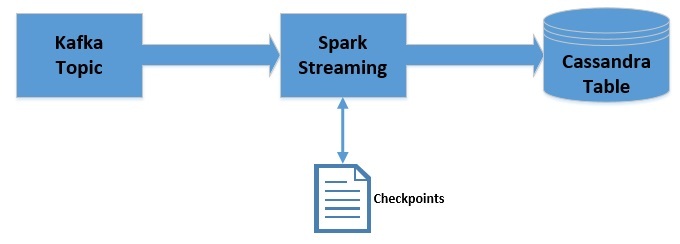
Apache Kafka 是一个可扩展,高性能,低延迟的平台,允许我们像消息系统一样读取和写入数据。我们可以很容易地在 Java 中使用 Kafka。Spark Streaming 是 Apache Spark 的一部分,是一个可扩展、高吞吐、容错的实时流处理引擎。虽然是使用 Scala 开发的,但是支持 Java API。Apache Cassandra 是分布式的 NoSQL 数据库。在这篇文章中,我们将 w397090770 5年前 (2019-09-08) 4041℃ 0评论8喜欢
《Apache Spark快速入门:基本概念和例子(1)》 《Apache Spark快速入门:基本概念和例子(2)》 本文聚焦Apache Spark入门,了解其在大数据领域的地位,覆盖Apache Spark的安装及应用程序的建立,并解释一些常见的行为和操作。一、 为什么要选择Apache Spark 当前,我们正处在一个“大数据"的时代,每时每刻,都有各 w397090770 9年前 (2015-07-13) 6131℃ 1评论24喜欢
我们在用Maven编译项目的时候有时老是出现无法下载某些jar依赖从而导致整个工程编译失败,这时候我们可以修改jar下载的源(也就是repositorie)即可,下面是Maven的用法,你可以在你项目的pom文件里面加入这些代码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="JAVA"]<!-- **** w397090770 10年前 (2014-07-25) 12988℃ 1评论14喜欢
一、概述有时候我们需要设计这样一种数据结构:它能快速在要求位置插入或者删除一段数据。先考虑两种简单的数据结构:数组和链表。数组的优点是能够在O(1)的时间内找到所要执行操作的位置,但其缺点是无论是插入或删除都要移动之后的所有数据,复杂度是O(n)的。链表优点是能够在O(1)的时间内插入和删除一段数据,但缺点 w397090770 12年前 (2013-04-03) 5830℃ 0评论7喜欢
概论 SparkR是一个R语言包,它提供了轻量级的方式使得可以在R语言中使用Apache Spark。在Spark 1.4中,SparkR实现了分布式的data frame,支持类似查询、过滤以及聚合的操作(类似于R中的data frames:dplyr),但是这个可以操作大规模的数据集。SparkR DataFrames DataFrame是数据组织成一个带有列名称的分布式数据集。在概念上和关系 w397090770 9年前 (2015-06-09) 36577℃ 1评论50喜欢
Elasticsearch 6.3 于前天正式发布,其中带来了很多新特性,详情请参见:https://www.elastic.co/blog/elasticsearch-6-3-0-released。这个版本最大的亮点莫过于内置支持 SQL 模块!我在早些时间就说过 Elasticsearch 将会内置支持 SQL,参见:ElasticSearch内置也将支持SQL特性。我们可以像操作 MySQL一样使用 Elasticsearch,这样我们就可以减少 DSL 的学习成本, w397090770 6年前 (2018-06-15) 8949℃ 3评论14喜欢
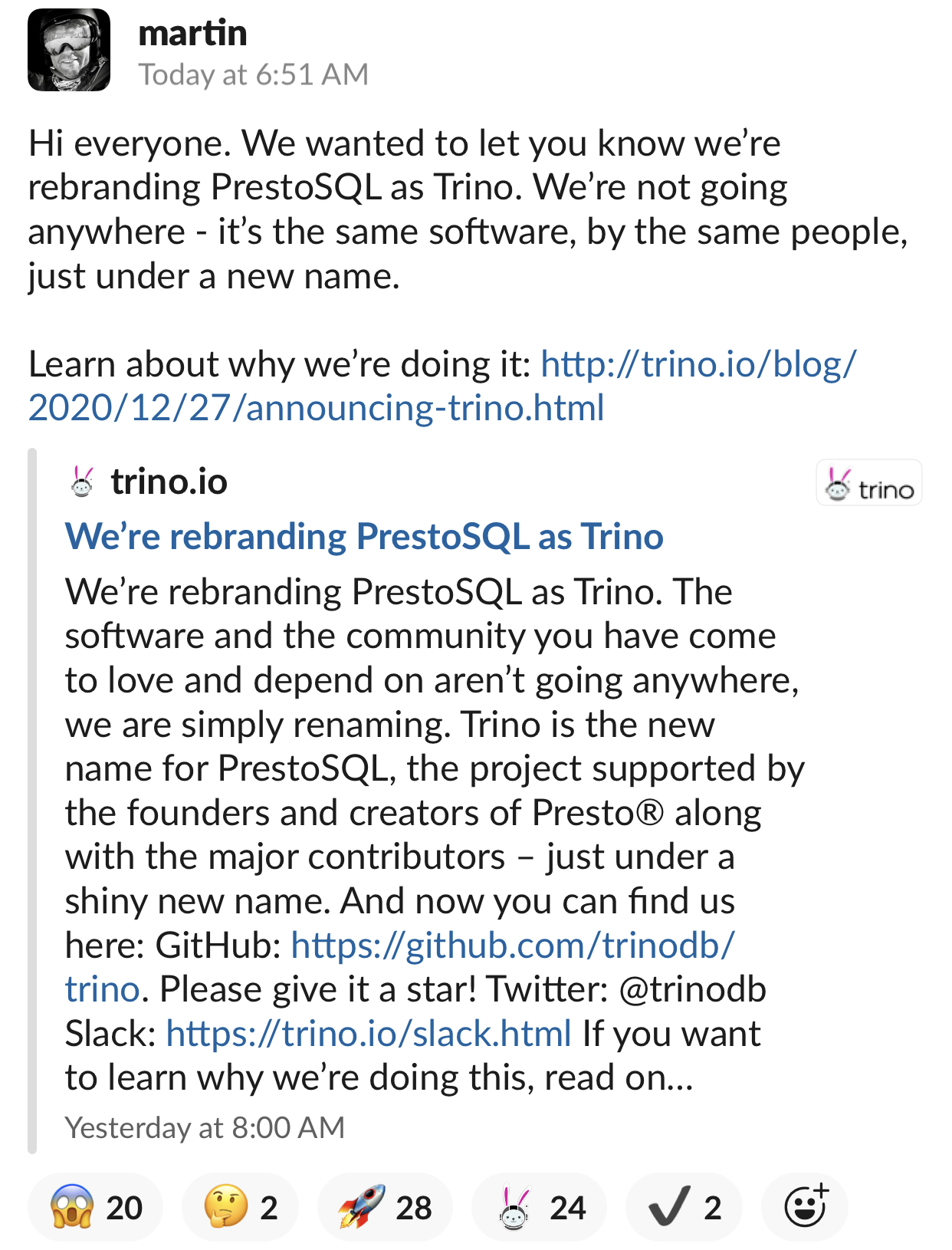
2020年12月27日,Martin Traverso、 Dain Sundstrom 以及 David Phillips 大佬们宣布将 PrestoSQL 项目的名字更名为 Trino。新的项目地址为 https://trino.io/。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop正如上图的描述,这个仅仅是更改名字,之前的社区和软件都还在那的,这个项目还是由 Presto 的创始人和创 w397090770 4年前 (2020-12-28) 1999℃ 0评论1喜欢
新世纪以来,互联网及个人终端的普及,传统行业的信息化及物联网的发展等产业变化产生了大量的数据,远远超出了单台机器能够处理的范围,分布式存储与处理成为唯一的选项。从2005年开始,Hadoop从最初Nutch项目的一部分,逐步发展成为目前最流行的大数据处理平台。Hadoop生态圈的各个项目,围绕着大数据的存储,计算, w397090770 9年前 (2015-11-06) 7963℃ 0评论9喜欢
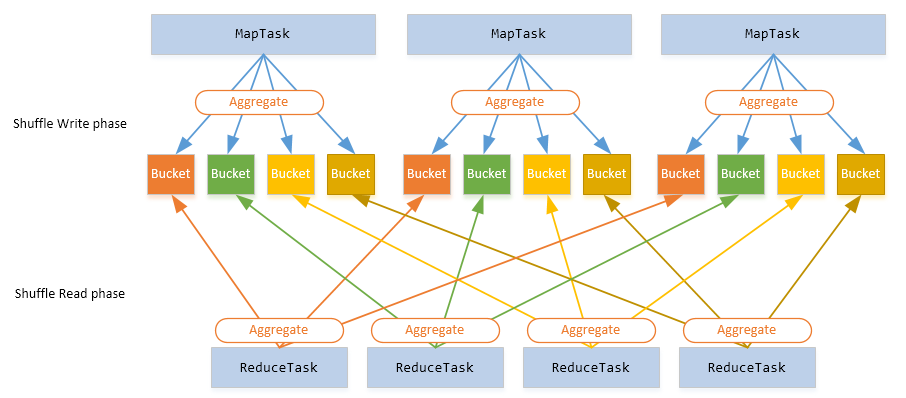
Spark Shuffle 基础在 MapReduce 框架中,Shuffle 是连接 Map 和 Reduce 之间的桥梁,Reduce 要读取到 Map 的输出必须要经过 Shuffle 这个环节;而 Reduce 和 Map 过程通常不在一台节点,这意味着 Shuffle 阶段通常需要跨网络以及一些磁盘的读写操作,因此 Shuffle 的性能高低直接影响了整个程序的性能和吞吐量。与 MapReduce 计算框架一样,Spark 作 w397090770 7年前 (2017-11-15) 7464℃ 3评论30喜欢
本课程内容全面涵盖了Spark生态系统的概述及其编程模型,深入内核的研究,Spark on Yarn,Spark Streaming流式计算原理与实践,Spark SQL,基于Spark的机器学习,图计算,Techyon,Spark的多语言编程以及SparkR的原理和运行。面向研究Spark的学员,它是一门非常有学习指引意义的课程。 本文的视频是录制版本的,所以是画面有些不清楚。 w397090770 10年前 (2015-03-23) 43789℃ 19评论69喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop假设我们有以下表:[code lang="scala"]scala> spark.sql("""CREATE TABLE iteblog_test (name STRING, id int) using orc PARTITIONED BY (id)""").show(100)[/code]我们往里面插入一些数据:[code lang="sql"]scala> spark.sql("insert into table iteblog_test select w397090770 4年前 (2020-08-03) 3256℃ 0评论4喜欢
Vim是一个高级文本编辑器,它提供了Unix下编辑器 'Vi' 的功能并对其进行了完善。Vim经常被认为是 "程序员的编辑器",它在程序编写时非常有用,很多人认为它是一个完整的集成开发环境(IDE)。仅管如此,Vim并不只是程序员使用的。Vim可以用于多种文档编辑,从email排版到配置文件编写。 在Ubuntu下安装一个Vim编辑器可以用下面 w397090770 11年前 (2013-07-19) 4976℃ 2评论2喜欢
《Get Programming with Scala》于2021年7月由 Manning 出版,ISBN 为 9781617295270 全书共 560 页。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop图书介绍The perfect starting point for your journey into Scala and functional programming.In Get Programming in Scala you will learn:Object-oriented principles in ScalaExpress program designs in fun w397090770 3年前 (2021-08-30) 341℃ 0评论4喜欢
在本博客的《Spark 0.9.1 Standalone模式分布式部署》详细的介绍了如何部署Spark Standalone的分布式,在那篇文章中并没有介绍如何来如何来测试,今天我就来介绍如何用Java来编写简单的程序,并在Standalone模式下运行。 程序的名称为SimpleApp.java,通过调用Spark提供的API进行的,在程序编写前现在pom引入相应的jar依赖:[code lang="JA w397090770 11年前 (2014-04-24) 7632℃ 0评论2喜欢
我下载的Apache Zeppelin和Apache Spark版本分别为:0.6.0-incubating-SNAPSHOT和1.5.2,在Zeppelin中使用SQLContext读取Json文件创建DataFrame的过程中出现了以下的异常:[code lanh="scala"]val profilesJsonRdd =sqlc.jsonFile("hdfs://www.iteblog.com/tmp/json")val profileDF=profilesJsonRdd.toDF()profileDF.printSchema()profileDF.show()profileDF.registerTempTable("profiles") w397090770 9年前 (2016-01-21) 6845℃ 2评论11喜欢
Wordpress的功能很强大,可以根据自己的需求来修改自己的网站。在Wordpress 3.5.1的中提供了默认的主题Twenty Twelve,很不错,但是首页显示的是全文信息,这不仅使得页面太长,也使得加载速度变的很慢,只有在搜索的时候才会显示摘要,那么怎么去让首页显示文章的摘要呢?到wordpress后台,依次选择 外观-->编辑-->选择右边的 w397090770 12年前 (2013-03-31) 27204℃ 9评论26喜欢
随着网站的文章越来越多,网站的图片也不知不觉的多了起来,图片多起来带来的问题就是访问的人多的时候会导致页面加载速度越来越慢,这严重影响了网站的用户体验,所以网站图片异步加载势在必行。 图片异步加载就是图片只有在视野范围内才加载,没出现在范围内的图片就暂不加载,等用户滑动滚动条时再逐步 w397090770 8年前 (2016-07-08) 3443℃ 0评论7喜欢
在Debian平台,请输入以下的命令[code lang="JAVA"]$ sudo vi /etc/apt/sources.list[/code]在里面加入下面的一行[code lang="JAVA"]deb http://ftp.us.debian.org/debian/ squeeze main non-free[/code]然后保存退出(:wq)之后,执行下面的命令[code lang="JAVA"]$ sudo apt-get update[/code]安装Java执行环境运行下面命令[code lang="JAVA"]$ sudo apt-get install sun-java6-jre[/ w397090770 11年前 (2013-10-21) 6163℃ 2评论3喜欢
一、相关概念 在默认情况下,Hadoop相关的WEB页面(JobTracker, NameNode, TaskTrackers and DataNodes)是不需要什么权限验证就可以直接进入的,谁都可以查看到当前集群上有哪些作业在运行,这对安全来说是很不合理的。我们应该限定用户来访问Hadoop相关的WEB页面,只有授权的用户才能看到自己授权的作业等信息,而不应该看到他不 w397090770 11年前 (2014-03-25) 12916℃ 2评论8喜欢
Web服务描述语言(WSDL)是一种用于描述Web服务或者网络端点的基于XML的语言。WSDL协议描述了Web服务之间的额消息处理机制、Web服务的位置,以及Web服务之间的通信协议。 WSDL与SOAP和UDDI一起工作,支持Web服务与Internet上的其他WEb服务、应用程序和设备交互作用。从本质上讲,UDDI提供了发布和定位Web服务的功能,WSDL描述了W w397090770 12年前 (2013-04-24) 3421℃ 0评论3喜欢
当一个broker停止或者crashes时,所有本来将它作为leader的分区将会把leader转移到其它broker上去。这意味着当这个broker重启时,它将不再担任何分区的leader,kafka的client也不会从这个broker来读取消息,从而导致资源的浪费。比如下面的broker 7是挂掉重启的,我们可以发现Partition 1虽然在broker 7上有数据,但是由于它挂了,所以Kafka重新 w397090770 9年前 (2016-03-24) 8331℃ 0评论5喜欢
1、自动向 WordPress 编辑器插入文本 编辑当前主题目录的 functions.php 文件,并粘贴以下代码: [code lang="php"]< ?php add_filter( 'default_content', 'my_editor_content' ); function my_editor_content( $content ) { $content = "过往记忆,专注于Hadoop、Spark等"; return $content; } ?> [/code]2、获取 WordPress 注册用户数量 通过简单的 SQL 语句, w397090770 10年前 (2014-10-12) 2638℃ 0评论3喜欢

![[电子书]Spark for Data Science PDF下载](https://www.iteblog.com/pic/books/spark_for_data_science_iteblog.JPG)







![Spark 1.X 大数据平台V2百度网盘下载[完整版]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/4.jpg)





