标准化是将属性域里面的数据等比例缩放,使得处理后的值落入一个小的特定区间。标准化主要有以下几点好处: (1)、可以将有单位的属性变成无单位的,这样就可以均等的对待每一个属性。比如对吞吐量量化之后的值进行标准化,不仅可以去掉单位,而且使得不同的属性值可以一起参加计算。 (2)、很好地解 w397090770 12年前 (2013-05-15) 7196℃ 0评论9喜欢
我们在开发网站的时候一般都会分header、main、side、footer。这些模块分别包含了各自公用的信息,比如header一般都是本网站所有页面需要引入的模块,里面一般都是放置菜单等信息;而footer一般是放在网站所有页面的底部。当网页的内容比较多的时候,我们可以看到footer一般都是在页面的底部。但是,当页面的内容不足以填满一 w397090770 9年前 (2015-10-28) 4584℃ 0评论8喜欢
今年的 Spark + AI Summit 2019 databricks 开源了几个重磅的项目,比如 Delta Lake,Koalas 等,Koalas 是一个新的开源项目,它增强了 PySpark 的 DataFrame API,使其与 pandas 兼容。Python 数据科学在过去几年中爆炸式增长,pandas 已成为生态系统的关键。 当数据科学家拿到一个数据集时,他们会使用 pandas 进行探索。 它是数据清洗和分析的终极工 w397090770 8年前 (2016-07-25) 216066℃ 0评论844喜欢
本文将介绍如何通过简单地几步来开始编写你的 Flink Java 程序。要求 编写你的Flink Java程序唯一的要求是需要安装Maven 3.0.4(或者更高)和Java 7.x(或者更高) 创建Flink Java工程使用下面其中一个命令来创建Flink Java工程1、使用Maven archetypes:[code lang="bash"]$ mvn archetype:generate \ -DarchetypeGrou w397090770 9年前 (2016-04-06) 13883℃ 0评论8喜欢
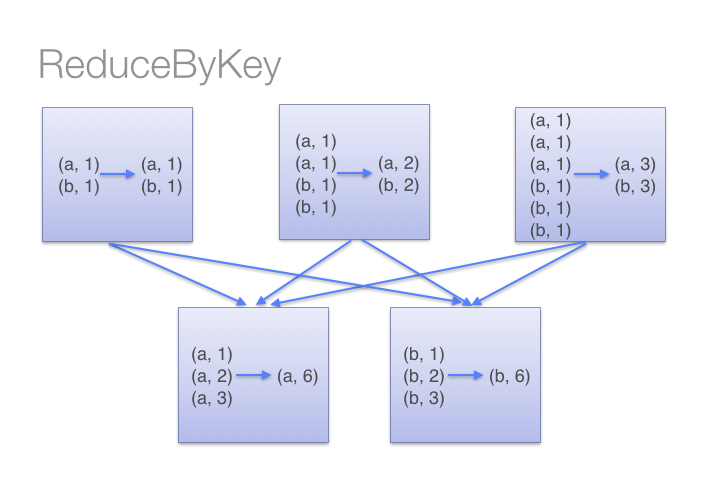
为什么建议尽量在Spark中少用GroupByKey,让我们看一下使用两种不同的方式去计算单词的个数,第一种方式使用 reduceByKey ;另外一种方式使用groupByKey,代码如下:[code lang="scala"]# User: 过往记忆# Date: 2015-05-18# Time: 下午22:26# bolg: # 本文地址:/archives/1357# 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量 w397090770 9年前 (2015-05-18) 33468℃ 0评论51喜欢
我们都知道,java中的Map结构是key->value键值对存储的,而且根据Map的特性,同一个Map中不存在两个Key相同的元素,而value不存在这个限制。换句话说,在同一个Map中Key是唯一的,而value不唯一。Map是一个接口,我们不能直接声明一个Map类型的对象,在实际开发中,比较常用的Map性数据结构是HashMap和TreeMap,它们都是Map的直接子类 w397090770 11年前 (2013-07-04) 30598℃ 2评论23喜欢
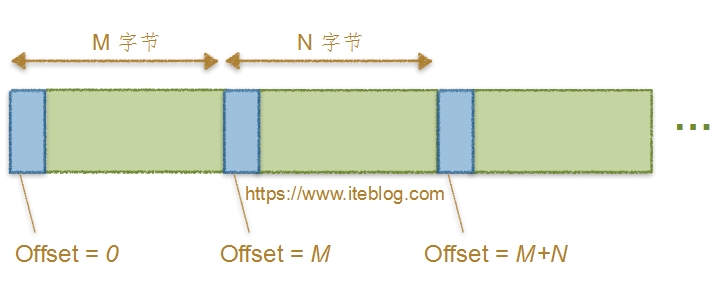
我在《Apache Kafka消息格式的演变(0.7.x~0.10.x)》文章中介绍了 Kafka 几个版本的消息格式。仔细的同学肯定看到了在 MessageSet 中的 Message 都有一个 Offset 与之一一对应,本文将探讨 Kafka 各个版本对消息中偏移量的处理。同样是从 Kafka 0.7.x 开始介绍,并依次介绍到 Kafka 0.10.x,由于 Kafka 0.11.x 正在开发中,而且消息格式已经和之前版本大不 w397090770 7年前 (2017-08-16) 5107℃ 0评论16喜欢
里氏替换法则(Liskov Substitution Principle LSP)是面向对象设计的六大基本原则之一(单一职责原则、里氏替换原则、依赖倒置原则、接口隔离原则、迪米特法则以及开闭原则)。这里说说里氏替换法则:父类的一个方法返回值是一个类型T,子类相同方法(重载或重写)返回值为S,那么里氏替换法则就要求S必须小于等于T,也就是说要么 w397090770 11年前 (2013-09-12) 4262℃ 3评论0喜欢
Apache HAWQ(incubating)的第一个版本受益于ASF(Apache software foundation)组织,通过将MPP(Massively Parallel Processing)和批处理系统(batch system)有效的结合,在性能上有了很大的提升,并且克服了一些关键的限制问题。一个新的重新设计的执行引擎在以下的几个问题在总体系统性能上有了很大的提高:硬件错误引起的短板问题(straggler)并发限制 w397090770 3年前 (2021-06-18) 1093℃ 0评论0喜欢
Apache Kafka 2.6.0 于2020年08月03日正式发布。在这个版本中,社区做了很多显著的性能改进,特别是当 Broker 有非常多的分区时。Broker 关闭性能得到了显著提高;当生产者使用压缩时,性能也得到了显著提高。ACL 使用的各个方面都有不同程度的提升,并且需要更少的内存。这个版本还增加了对 Java 14 的支持。在过去的几个版本中,社 w397090770 4年前 (2020-08-23) 882℃ 0评论0喜欢
Elasticsearch 5.0.0在2016年10月26日发布,该版本基于Lucene 6.2.0,这是最新的稳定版本,并且已经在Elastic Cloud上完成了部署。Elasticsearch 5.0.0是目前最快、最安全、最具弹性、最易用的版本,此版本带来了一系列的新功能和性能优化。ElasticSearch 5.0.0 release Note点击下载ElasticSearch 5.0.0阅读最新文档如果想及时了解Spark、Hadoop或者Hbase w397090770 8年前 (2016-11-02) 4953℃ 0评论10喜欢
在《如何快速判断正整数是2的N次幂》文章中我们谈到如何快速的判断给定的正整数是否为2的N次幂,今天来谈谈如何快速地判断一个给定的正整数是否为4的N次幂。将4的幂次方写成二进制形式后,很容易就会发现有一个特点:二进制中只有一个1(1在奇数位置),并且1后面跟了偶数个0; 因此问题可以转化为判断1后面是否跟了 w397090770 11年前 (2013-09-30) 5051℃ 0评论5喜欢
消息队列 消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。在分布式计算环境中,为了集成分布式应用,开发者需要对异构网络环 w397090770 9年前 (2015-08-11) 8104℃ 2评论17喜欢
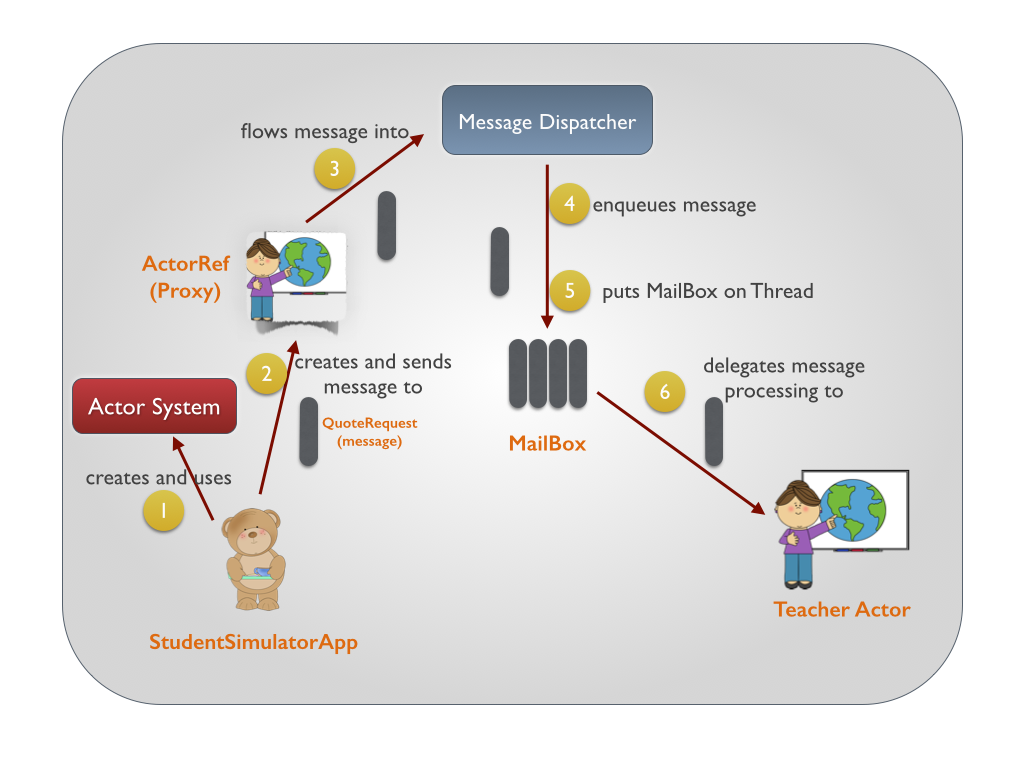
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-13) 21959℃ 5评论40喜欢
在本博客的《Spark Metrics配置详解》文章中介绍了Spark Metrics的配置,其中我们就介绍了Spark监控支持Ganglia Sink。Ganglia是UC Berkeley发起的一个开源集群监视项目,主要是用来监控系统性能,如:cpu 、mem、硬盘利用率, I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性 w397090770 10年前 (2015-05-11) 13894℃ 1评论13喜欢
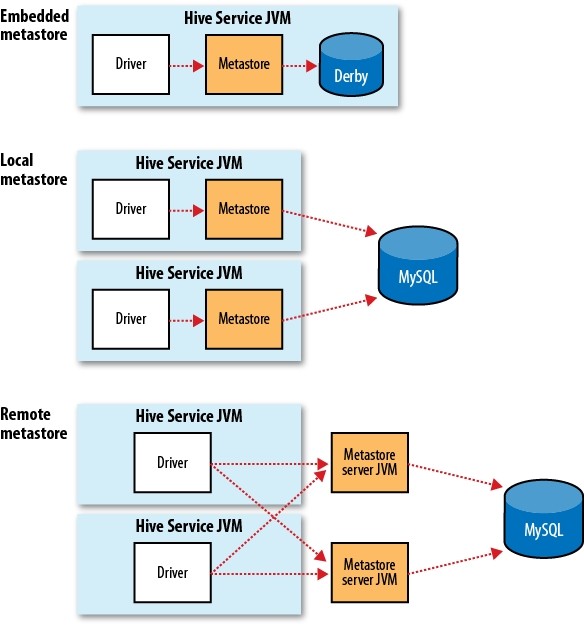
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事 Hive内部自带了许多的服务,我们可以 w397090770 11年前 (2014-02-24) 19035℃ 1评论10喜欢
本博客的《Spark与Mysql(JdbcRDD)整合开发》和《Spark RDD写入RMDB(Mysql)方法二》文章中介绍了如何通过Spark读写Mysql中的数据。 在生产环境下,很多公司都会使用PostgreSQL数据库,这篇文章将介绍如何通过Spark获取PostgreSQL中的数据。我将使用Spark 1.3中的DataFrame(也就是之前的SchemaRDD),我们可以通过SQLContext加载数据库中的数据, w397090770 9年前 (2015-05-23) 13001℃ 0评论11喜欢
Alluxio Meetup 上海站由 Alluxio、七牛主办,示说网、过往记忆协办,本次会议将于2018年10月27日 13:30-17:00 在上海市张江高科博霞路66号浦东软件园Q座举行。报名地址扫描下面二维码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动详情Alluxio:未来是数据的时代,数据的高效管理、存储 w397090770 6年前 (2018-10-17) 1308℃ 0评论1喜欢
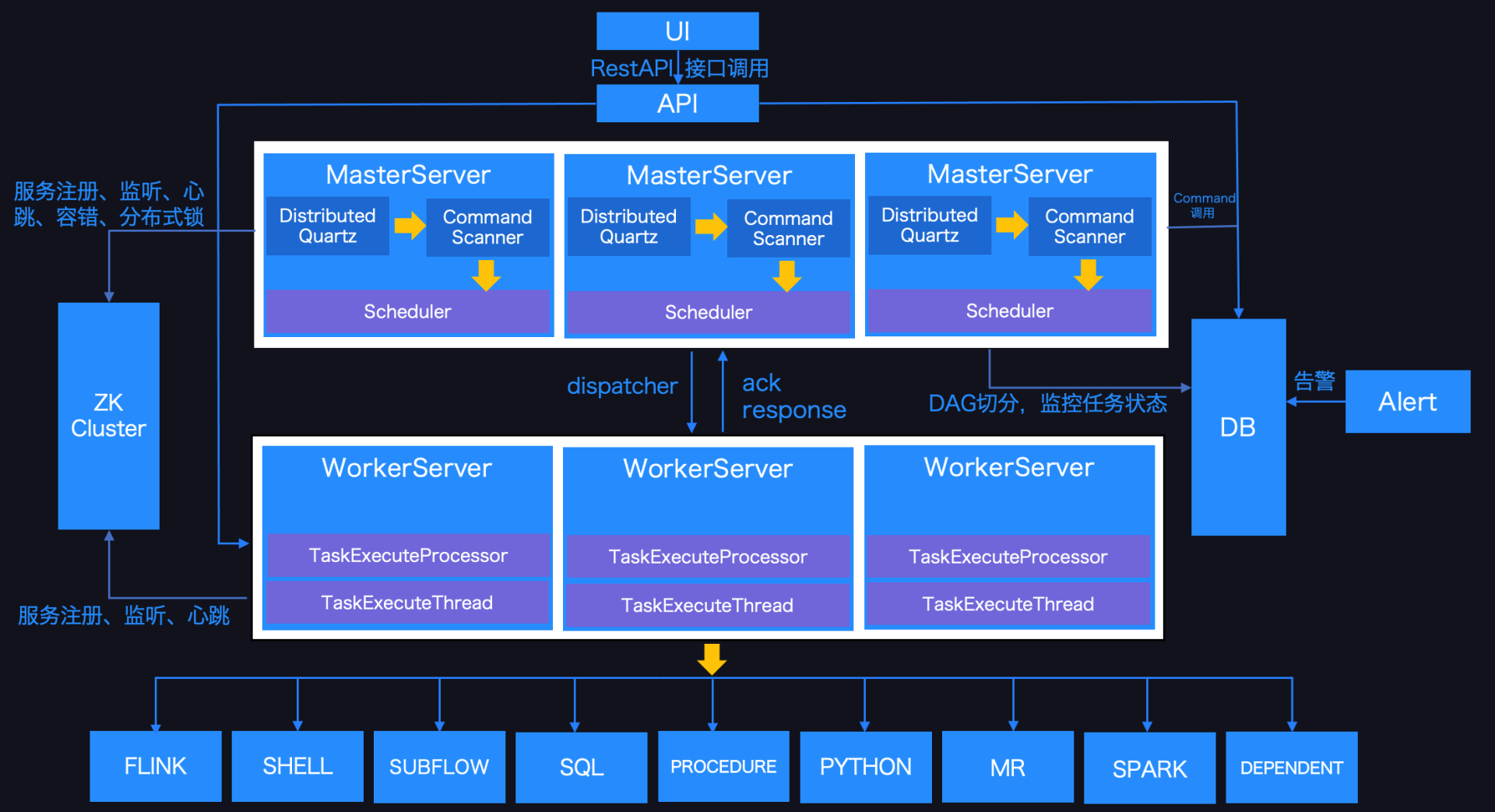
全球最大的开源软件基金会 Apache 软件基金会(以下简称 Apache)于北京时间 2021年4月9日在官方渠道宣布Apache DolphinScheduler 毕业成为Apache顶级项目。这是首个由国人主导并贡献到 Apache 的大数据工作流调度领域的顶级项目。DolphinScheduler™ 已经是联通、IDG、IBM、京东物流、联想、新东方、诺基亚、360、顺丰和腾讯等 400+ 公司在使用 w397090770 4年前 (2021-04-09) 1821℃ 0评论3喜欢
有赞数据平台从2017年上半年开始,逐步使用 SparkSQL 替代 Hive 执行离线任务,目前 SparkSQL 每天的运行作业数量5000个,占离线作业数目的55%,消耗的 cpu 资源占集群总资源的50%左右。本文介绍由 SparkSQL 替换 Hive 过程中碰到的问题以及处理经验和优化建议,包括以下方面的内容:有赞数据平台的整体架构。SparkSQL 在有赞的技术演进 w397090770 6年前 (2019-03-20) 8263℃ 5评论29喜欢
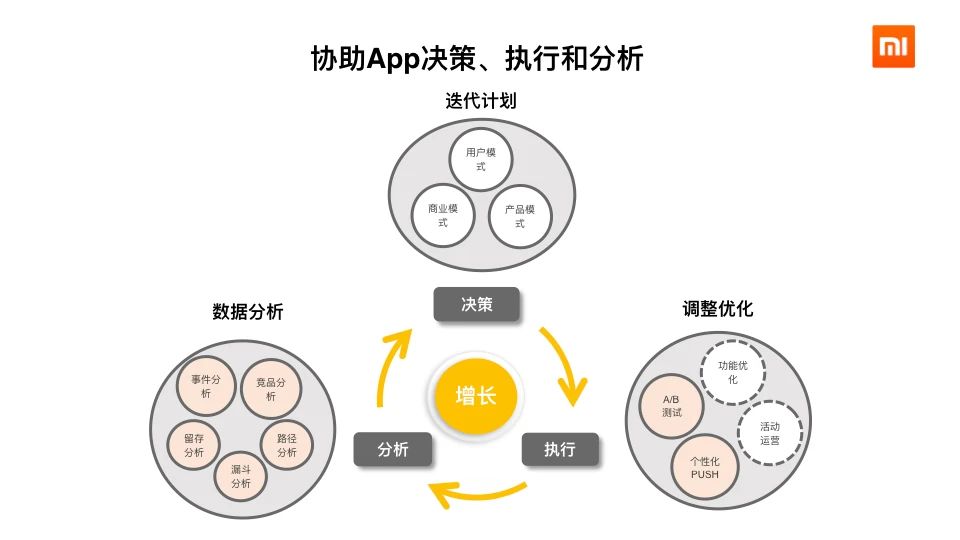
1、背景随着小米互联网业务的发展,各个产品线利用用户行为数据对业务进行增长分析的需求越来越迫切。显然,让每个业务产品线都自己搭建一套增长分析系统,不仅成本高昂,也会导致效率低下。我们希望能有一款产品能够帮助他们屏蔽底层复杂的技术细节,让相关业务人员能够专注于自己的技术领域,从而提高工作效率。 w397090770 4年前 (2020-09-13) 1243℃ 0评论2喜欢
关于如何编译Flume-ng 1.4.0可以参见本博客的《基于Hadoop-2.2.0编译flume-ng 1.4.0及错误解决》 在编译Flume-0.9.4源码的时候出现了以下的错误信息:[code lang="JAVA"][INFO] ------------------------------------------------------------------------[INFO] Reactor Summary:[INFO][INFO] Flume ............................................. SUCCESS [0.003s][INFO] Flume Core ............ w397090770 11年前 (2014-01-22) 10758℃ 2评论2喜欢
ZooKeeper使用ACL来控制访问其znode(ZooKeeper的数据树的数据节点)。ACL的实现方式非常类似于UNIX文件的访问权限:它采用访问权限位 允许/禁止 对节点的各种操作以及能进行操作的范围。不同于UNIX权限的是,ZooKeeper的节点不局限于 用户(文件的拥有者),组和其他人(其它)这三个标准范围。ZooKeeper不具有znode的拥有者的概念。 w397090770 9年前 (2015-12-02) 7265℃ 1评论4喜欢
如果你正在按照 《将 MySQL 的全量数据导入到 Apache Solr 中》 文章介绍的步骤来将 MySQL 里面的数据导入到 Solr 中,但是在创建 Core/Collection 的时候出现了以下的异常[code lang="bash"]2018-08-02 07:56:17.527 INFO (qtp817348612-15) [ x:mysql2solr] o.a.s.m.r.SolrJmxReporter Closing reporter [org.apache.solr.metrics.reporters.SolrJmxReporter@47d9861c: rootName = null, domain = solr.cor w397090770 6年前 (2018-08-07) 1049℃ 0评论2喜欢
相关图标矢量字库:《Font Awesome:图标字体》、《阿里巴巴矢量图标库:Iconfont》 Iconfont.cn是由阿里巴巴UX部门推出的矢量图标管理网站,也是国内首家推广Webfont形式图标的平台。网站涵盖了1000多个常用图标并还在持续更新中(目前加上用户上传的图标近70000个,我们可以通过搜索来找到他们。)。、 Iconfont平台为用 w397090770 10年前 (2015-02-26) 29376℃ 0评论27喜欢
物化视图作为一种预计算的优化方式,广泛应用于传统数据库中,如Oracle,MSSQL Server等。随着大数据技术的普及,各类数仓及查询引擎在业务中扮演着越来越重要的数据分析角色,而物化视图作为数据查询的加速器,将极大增强用户在数据分析工作中的使用体验。本文将基于 SparkSQL(2.4.4) + Hive (2.3.6), 介绍物化视图在SparkSQL中 w397090770 4年前 (2020-05-14) 2222℃ 0评论4喜欢
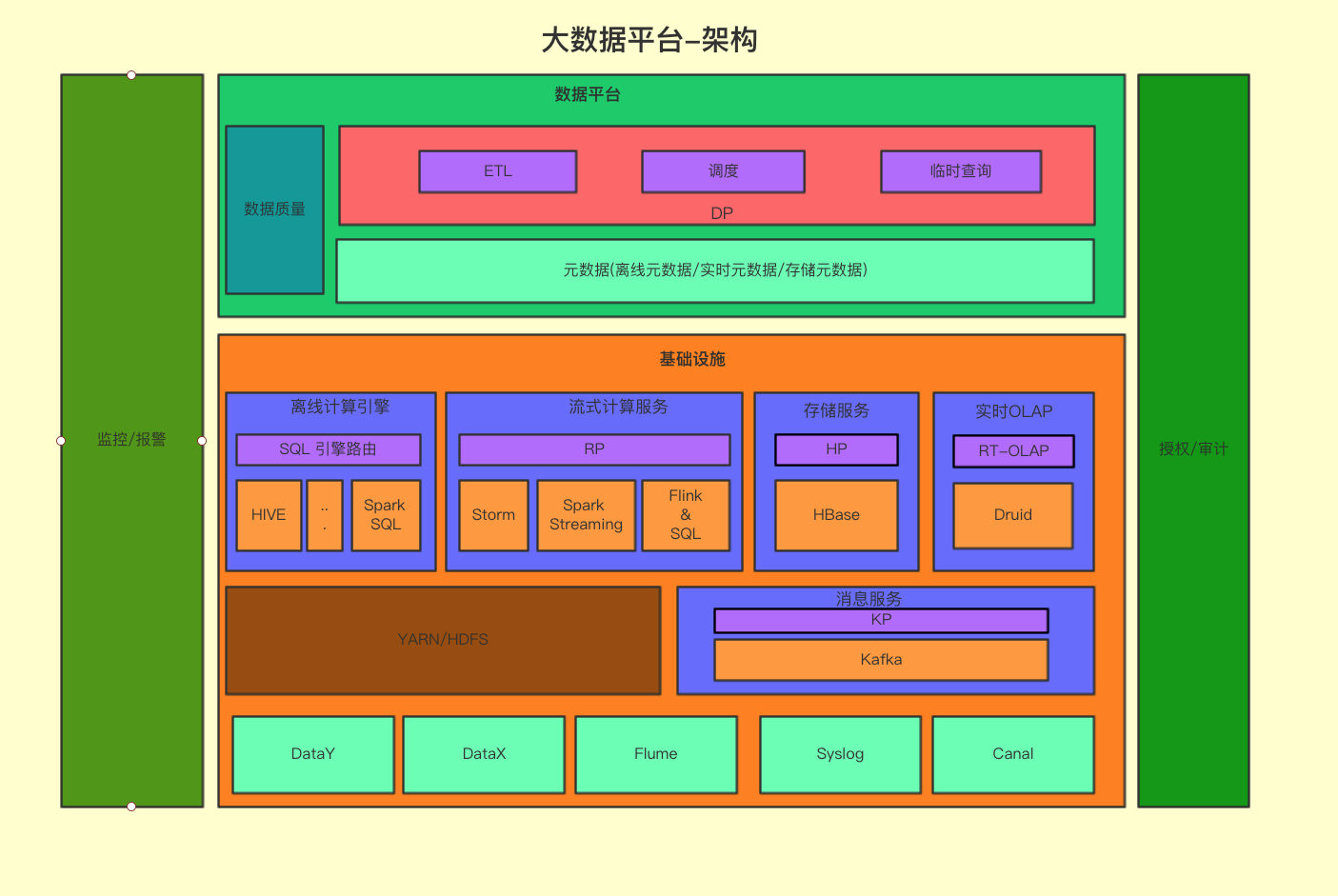
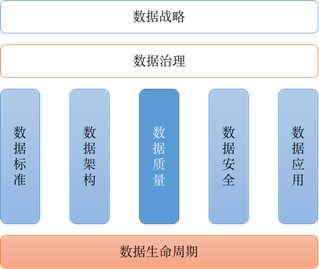
大数据平台的核心理念是构建于业务之上,用数据为业务创造价值。大数据平台的搭建之初,优先满足业务的使用需求,数据质量往往是被忽视的一环。但随着业务的逐渐稳定,数据质量越来越被人们所重视。千里之堤,溃于蚁穴,糟糕的数据质量往往就会带来低效的数据开发,不准确的数据分析,最终导致错误的业务决策。而 zz~~ 3年前 (2021-09-24) 257℃ 0评论2喜欢
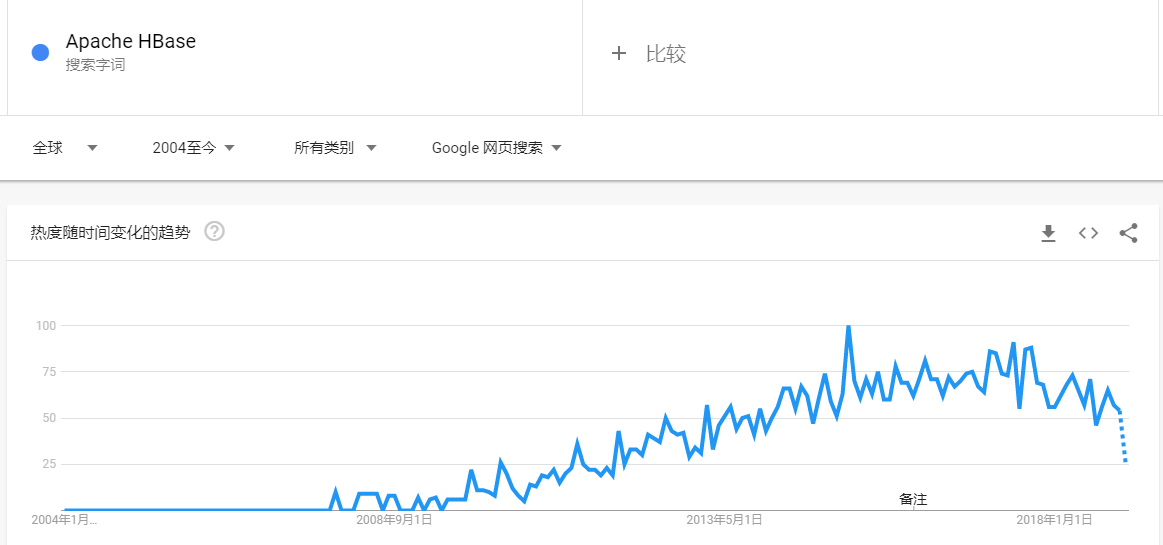
Apache HBase是基于Hadoop构建的一个分布式的、可伸缩的海量数据存储系统。随着时间的推移,HBase目前不管是在国内还是国外都受到了非常大的欢迎,以下分别是近几年 Google 和百度关于 HBase 的搜索趋势:Google如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop大家可以看到,整体趋势是越来越 w397090770 6年前 (2019-01-05) 3549℃ 4评论15喜欢
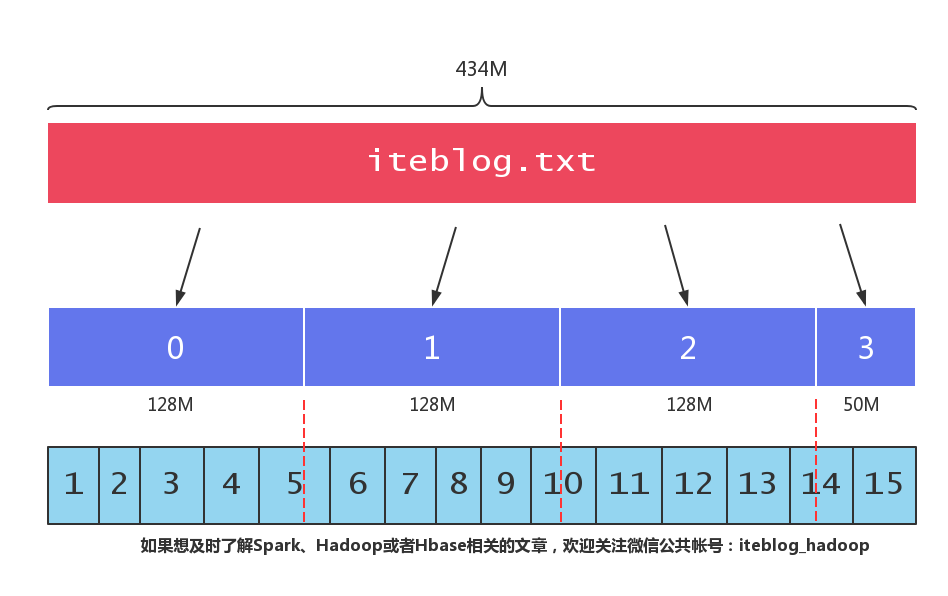
相信大家都知道,HDFS 将文件按照一定大小的块进行切割,(我们可以通过 dfs.blocksize 参数来设置 HDFS 块的大小,在 Hadoop 2.x 上,默认的块大小为 128MB。)也就是说,如果一个文件大小大于 128MB,那么这个文件会被切割成很多块,这些块分别存储在不同的机器上。当我们启动一个 MapReduce 作业去处理这些数据的时候,程序会计算出文 w397090770 6年前 (2018-05-16) 2666℃ 4评论28喜欢
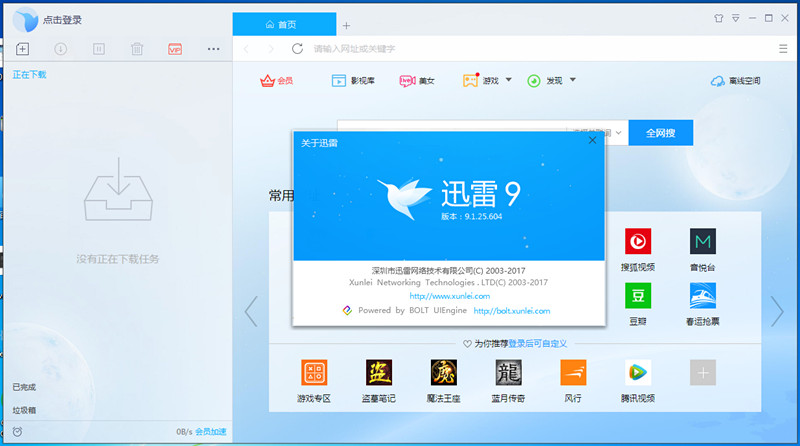
最近升级了迅雷9,新版本精简了任务列表的面积,然而增加了一个硕大的内置浏览器面板,大概占据了四分之三的窗口面积,并且不能关闭!界面如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop就个人观点而言,实在不能理解为什么需要让一个下载工具的附加功能占据主要使用区 w397090770 8年前 (2017-02-18) 6421℃ 0评论20喜欢