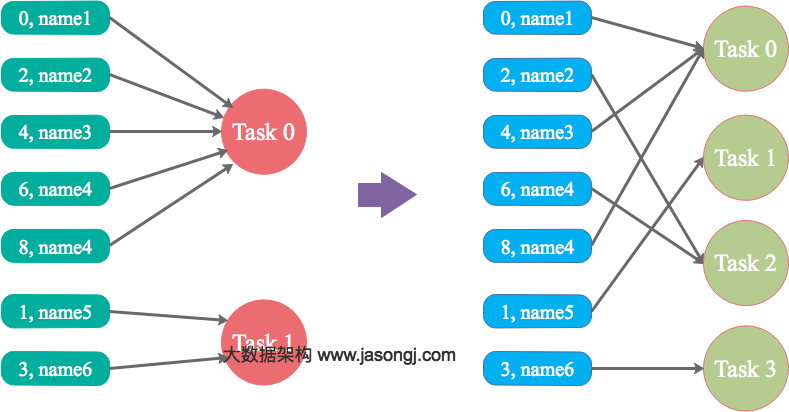
在《Kafka集群扩展以及重新分布分区》文章中我们介绍了如何重新分布分区,在那里面我们基本上把所有的分区全部移动了,其实我们完全没必要移动所有的分区,而移动其中部分的分区。比如我们想把Broker 1与Broker 7上面的分区数据互换,如下图所示:可以看出,只有Broker 1与Broker 7上面的分区做了移动。来看看移动分区之 w397090770 9年前 (2016-03-31) 3338℃ 0评论4喜欢
本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitioner,使用Map侧Join代替Reduce侧Join,给倾斜Key加上随机前缀等。为何要处理数据倾斜(Data Skew)什么是数据倾斜对Spark/Hadoop这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。何谓数据倾 w397090770 8年前 (2017-03-07) 13305℃ 2评论27喜欢
Shanghai Apache Spark Meetup第九次聚会在6月18日下午13:00-17:00由Intel联手饿了么在上海市普陀区金沙江路1518弄2号近铁城市广场饿了么公司5楼会议室(榴莲酥+螺狮粉)举行。分享主题演讲者1: 史鸣飞, 英特尔大数据工程师演讲者2: 史栋杰, 英特尔大数据工程师演讲者3: 毕洪宇,饿了么数据运营部副总监演讲者4: 张家劲, w397090770 8年前 (2016-06-25) 2129℃ 0评论4喜欢
在 Zookeeper 中限制 transaction log 总大小主要有两种方法。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop限制 Zookeeper Transaction Log 里面的事务条数默认情况下,在写入 snapCount(100000) 事务后,Zookeeper 事务日志将会切换。如果 Zookeeper 的数据目录的空间不足与存储三个版本的 Zookeeper Transaction Lo w397090770 4年前 (2020-10-28) 737℃ 0评论1喜欢
历时一个多月的投票和补丁修复,Apache Spark 1.6.0于今天凌晨正式发布。Spark 1.6.0是1.x线上第七个发行版.本发行版有来自248+的贡献者参与。详细邮件如下:Hi All,Spark 1.6.0 is the seventh release on the 1.x line. This release includes patches from 248+ contributors! To download Spark 1.6.0 visit the downloads page. (It may take a while for all mirrors to update.)A huge t w397090770 9年前 (2016-01-05) 2971℃ 1评论5喜欢
Apache Flink 1.5.0 于昨天晚上正式发布了。在过去五个月的时间里,Flink 社区共解决了超过 780 个 issues。完整的 changelog 看这里: https://issues.apache.org/jira/secure/ReleaseNote.jspa?version=12341764&projectId=12315522。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopFlink 1.5.0 是 1.x.y 版本线上的第六个主要发行版。 w397090770 6年前 (2018-05-26) 3099℃ 0评论12喜欢
我下载的Apache Zeppelin和Apache Spark版本分别为:0.6.0-incubating-SNAPSHOT和1.5.2,在Zeppelin中使用SQLContext读取Json文件创建DataFrame的过程中出现了以下的异常:[code lanh="scala"]val profilesJsonRdd =sqlc.jsonFile("hdfs://www.iteblog.com/tmp/json")val profileDF=profilesJsonRdd.toDF()profileDF.printSchema()profileDF.show()profileDF.registerTempTable("profiles") w397090770 9年前 (2016-01-21) 6845℃ 2评论11喜欢
本文主要讲解 Kafka 是什么、Kafka 的架构包括工作流程和存储机制,以及生产者和消费者,最终大家会掌握 Kafka 中最重要的概念,分别是 broker、producer、consumer、consumer group、topic、partition、replica、leader、follower,这是学会和理解 Kafka 的基础和必备内容。1. 定义Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主 w397090770 5年前 (2020-03-14) 1613℃ 0评论10喜欢
我们都知道,目前 Apache Beam 仅仅提供了 Java 和 Python 两种语言的 API,尚不支持 Scala 相关的 API。基于此全球最大的流音乐服务商 Spotify 开发了 Scio ,其为 Apache Beam 和 Google Cloud Dataflow 提供了Scala API,使得我们可以直接使用 Scala 来编写 Beam 应用程序。Scio 开发受 Apache Spark 和 Scalding 的启发,目前最新版本是 Scio 0.3.0,0.3.0版本之前依赖 w397090770 7年前 (2017-07-25) 1269℃ 0评论7喜欢
在 Apache 软件基金会近期发布的年度报告中,Apache Flink 再次跻身最活跃项目前 5 名!该项目最新发布的 1.14.0 版本同样体现了其非凡的活跃力,囊括了来自超过 200 名贡献者的 1000 余项贡献。整个社区为项目的推进付出了持之以恒的努力,我们引以为傲。新版本在 SQL API、更多连接器支持、Checkpoint 机制、PyFlink 等多个方面带来了大 zz~~ 3年前 (2021-10-09) 908℃ 0评论4喜欢
大数据处理技术现今已广泛应用于各个行业,为业务解决海量存储和海量分析的需求。但数据量的爆发式增长,对数据处理能力提出了更大的挑战,同时对时效性也提出了更高的要求。业务通常已不再满足滞后的分析结果,希望看到更实时的数据,从而在第一时间做出判断和决策。典型的场景如电商大促和金融风控等,基于延迟数 w397090770 4年前 (2020-06-08) 3904℃ 0评论3喜欢
最近在做给博客添加上传PDF的功能,但是在测试上传文件的过程中遇到了413 Request Entity Too Large错误。不过这个无错误是很好解决的,这个错误的出现是因为上传的文件大小超过了Nginx和PHP的配置,我们可以通过以下的方法来解决:一、设置PHP上传文件大小限制 PHP默认的文件上传大小是2M,我们可以通过修改php.ini里面的 w397090770 9年前 (2015-08-17) 20759℃ 0评论6喜欢
Delta Lake 的 Delete 功能是由 0.3.0 版本引入的,参见这里,对应的 Patch 参见这里。在介绍 Apache Spark Delta Lake 实现逻辑之前,我们先来看看如何使用 delete 这个功能。Delta Lake 删除使用Delta Lake 的官方文档为我们提供如何使用 Delete 的几个例子,参见这里,如下:[code lang="scala"]import io.delta.tables._val iteblogDeltaTable = DeltaTable.forPath(spa w397090770 5年前 (2019-09-27) 1517℃ 0评论2喜欢
在HDFS中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的 dfs.datanode.data.dir 参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。 w397090770 8年前 (2016-12-13) 5858℃ 0评论13喜欢
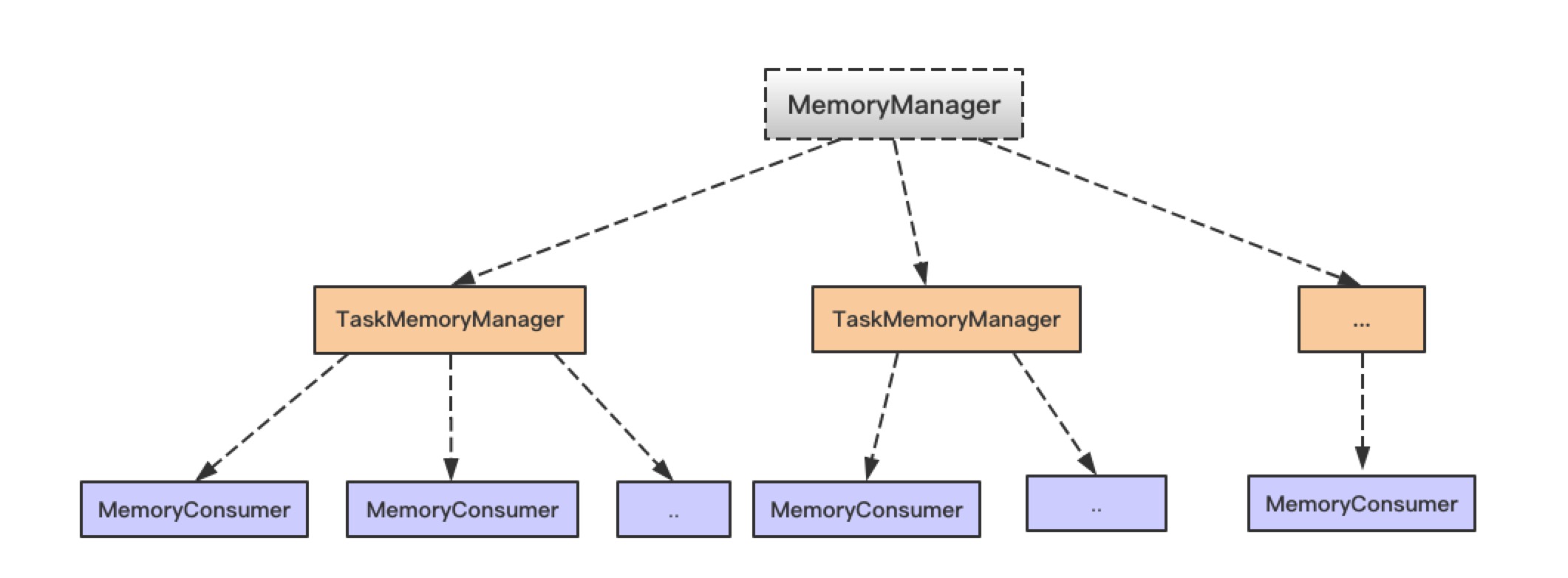
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段。那么在 Spark Shuffle 中具体是哪些地方会使用比较多的内存而有可能导致 OOM 呢? 为此,本文将围绕以上问题梳理 Spark 内存管理和 Shuffle 过程中与内存使用相关的知识;然后,简要分析下在 Spark Shuffle 中有可能导致 OOM w397090770 6年前 (2019-03-17) 5358℃ 0评论19喜欢
Apache Flume 1.5.0 发布于5月22日正式发布(可以在http://flume.apache.org/download.html下载)。Flume是一个分布式、可靠和高可用的服务,用于收集、聚合以及移动大量日志数据,使用一个简单灵活的架构,就流数据模型。这是一个可靠、容错的服务。下面是Apache Flume-ng 1.5.0的Changelog:What's new in Apache Flume 1.5.0:May 22nd, 2014New Feature: Int w397090770 10年前 (2014-05-27) 7007℃ 1评论4喜欢
Linux(vi/vim)一般模式语法功能描述yy复制光标当前一行y数字y复制一段(从第几行到第几行)p箭头移动到目的行粘贴u撤销上一步dd删除光标当前行d数字d删除光标(含)后多少行x删除一个字母,相当于delX删除一个字母,相当于Backspaceyw复制一个词dw删除一个词 zz~~ 3年前 (2021-12-01) 168℃ 0评论0喜欢
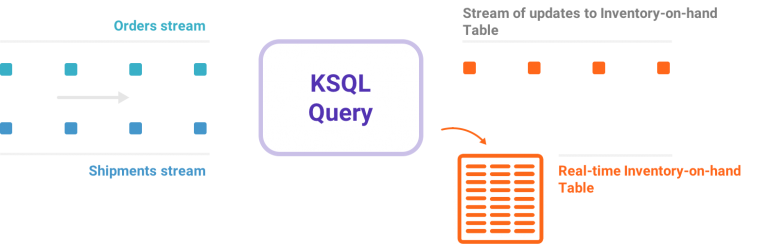
我非常高兴地宣布KSQL,这是面向Apache Kafka的一种数据流SQL引擎。KSQL降低了数据流处理这个领域的准入门槛,为使用Kafka处理数据提供了一种简单的、完全交互的SQL界面。你不再需要用Java或Python之类的编程语言编写代码了!KSQL具有这些特点:开源(采用Apache 2.0许可证)、分布式、可扩展、可靠、实时。它支持众多功能强大的数据流 w397090770 7年前 (2017-08-30) 7900℃ 0评论22喜欢
今天将临时表里面的数据按照天分区插入到线上的表中去,出现了Hive创建的文件数大于100000个的情况,我的SQL如下:[code lang="sql"]///////////////////////////////////////////////////////////////////// User: 过往记忆 Date: 2015-11-18 Time: 23:24 bolg: 本文地址:/archives/1533 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量 w397090770 9年前 (2015-11-18) 22941℃ 3评论53喜欢
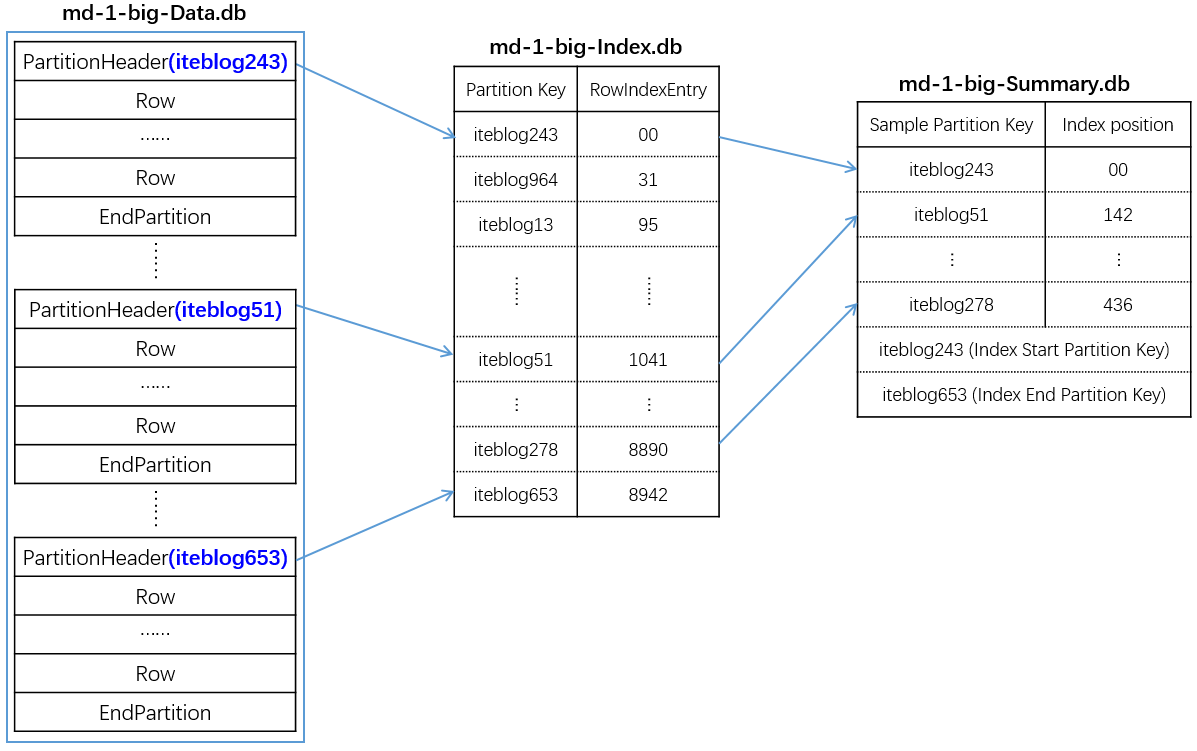
在 Cassandra 中,当达到一定条件触发 flush 的时候,表对应的 Memtable 中的数据会被写入到这张表对应的数据目录(通过 data_file_directories 参数配置)中,并生成一个新的 SSTable(Sorted Strings Table,这个概念是从 Google 的 BigTable 借用的)。每个 SSTable 是由一系列的不可修改的文件组成,这些文件在 Cassandra 中被称为 Component。本文是基于 Cas w397090770 5年前 (2019-05-05) 2172℃ 1评论4喜欢
本文原文:Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop Deep dive into the new Tungsten execution engine:https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html本文已经投稿自:http://geek.csdn.net/news/detail/77005 《Spark 2.0技术预览:更容易、更快速、更智能》文中简单地介绍了Spark 2.0相关 w397090770 8年前 (2016-05-27) 6003℃ 1评论16喜欢
This topic describes tips for tuning parallelism and memory in Presto. The tips are categorized as follows:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopTuning Parallelism at a Task LevelThe number of splits in a cluster = node-scheduler.max-splits-per-node * number of worker nodes.The node-scheduler.max-splits-per-node denotes the target value for the total num w397090770 4年前 (2021-02-20) 1152℃ 0评论4喜欢
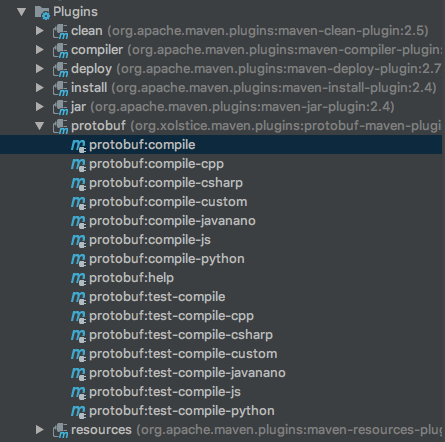
Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准,目前已经正在使用的有超过 48,162 种报文格式定义和超过 12,183 个 .proto 文件。他们用于 RPC 系统和持续数据存储系统。Protocol Buffers 是一种序列化数据结构的方法。对于通过管线(pipeline)或存储数据进行通信的程序开发上是很有用的。这个方法包含一个接口描述 w397090770 6年前 (2019-02-01) 6822℃ 0评论8喜欢
使用 MAC 写移动硬盘的时候会出现 Read-only file system,我们可以使用下面方法来解决。[code code="bash"]iteblog: iteblog $ diskutil info /Volumes/Seagate\ Backup\ Plus\ Drive/ Device Identifier: disk2s1 Device Node: /dev/disk2s1[/code]记下上面的 Device Node。然后使用下面命令弹出我们插入的移动硬盘:[code code="bash"]iteblog: iteblog $ hdiutil eje w397090770 4年前 (2021-01-05) 2238℃ 0评论2喜欢
概论 SparkR是一个R语言包,它提供了轻量级的方式使得可以在R语言中使用Apache Spark。在Spark 1.4中,SparkR实现了分布式的data frame,支持类似查询、过滤以及聚合的操作(类似于R中的data frames:dplyr),但是这个可以操作大规模的数据集。SparkR DataFrames DataFrame是数据组织成一个带有列名称的分布式数据集。在概念上和关系 w397090770 9年前 (2015-06-09) 36577℃ 1评论50喜欢
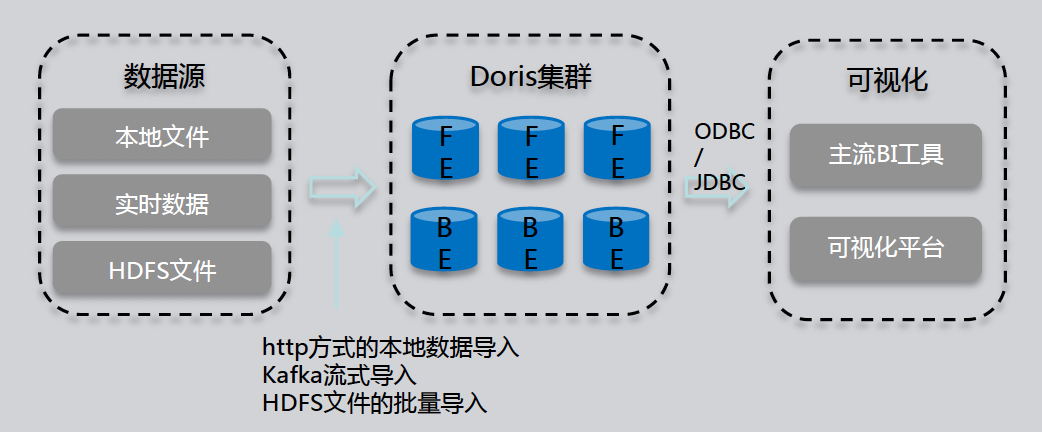
Apache Doris 简介Doris(原百度 Palo)是一款基于大规模并行处理技术的分布式 SQL 数据库,由百度在 2017 年开源,2018 年 8 月进入 Apache 孵化器。本次将主要从以下三部分介绍 Apache Doris.Doris 定位:即 Doris 所要面临的业务场景及解决的问题Doris 关键技术Doris 案例介绍01 Doris 定位实时数据仓库 Doris产品定位我们首先看一下 w397090770 5年前 (2019-12-11) 2942℃ 0评论4喜欢
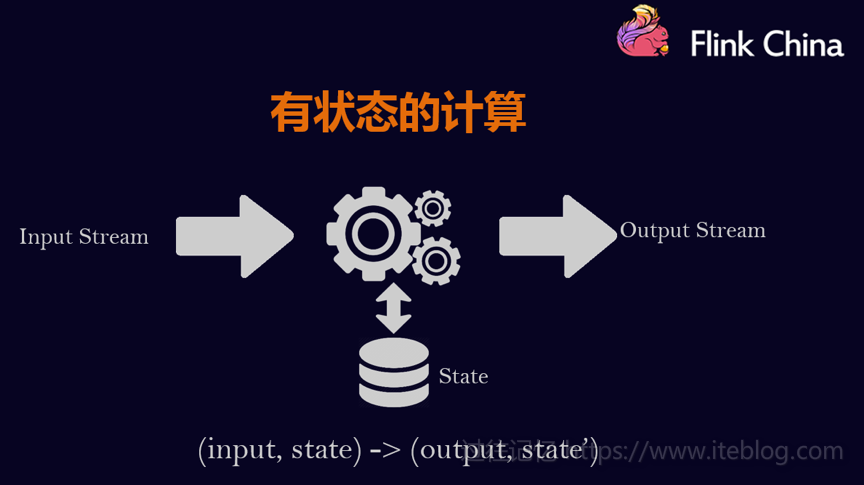
本文整理自8月11日在北京举行的 Flink Meetup 会议,分享嘉宾施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发。本文由韩非(Flink China社区志愿者)整理一、有状态的流数据处理1、什么是有状态的计算计算任务的结果不仅仅依赖于输入,还依赖于它的当前状态,其实大 w397090770 6年前 (2018-08-24) 9091℃ 0评论21喜欢
Shanghai Apache Spark Meetup第十次聚会活动将于2016年09月10日12:30 至 17:20在四星级的上海通茂大酒店 (浦东新区陆家嘴金融区松林路357号)。分享主题1、中国电信在大数据领域上的创新与探索2、函数式编程与RDD3、社交网络中的信息传播4、大数据分析和机器学习5、分布式流式数据处理框架:功能对比以及性能评估详细主 zz~~ 8年前 (2016-09-20) 1793℃ 0评论2喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 第四次北京Spark meeting会议 w397090770 10年前 (2014-12-16) 10337℃ 73评论8喜欢
功能和collect函数类似。该函数用于Pair RDD,最终返回Map类型的结果。官方文档说明:Return the key-value pairs in this RDD to the master as a Map.Warning: this doesn't return a multimap (so if you have multiple values to the same key, only one value per key is preserved in the map returned)函数原型[code lang="scala"]def collectAsMap(): Map[K, V][/code]实例[code lang="scala w397090770 10年前 (2015-03-16) 16521℃ 0评论18喜欢