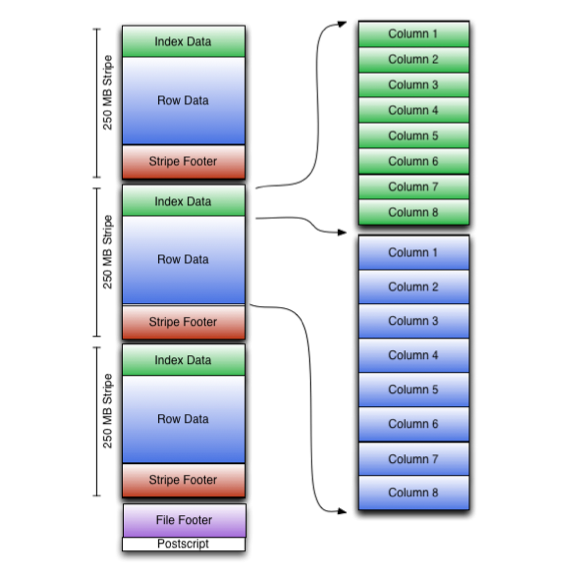
消息队列 消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。在分布式计算环境中,为了集成分布式应用,开发者需要对异构网络环 w397090770 9年前 (2015-08-11) 8104℃ 2评论17喜欢
大家肯定都知道要想在国内下载一个项目到本地速度太慢了。可以试试下面方案,把原地址:https://github.com/xxx.git 替换为:https://github.com.cnpmjs.org/xxx.git 即可。比如我们要克隆下面项目到本地,可以操作如下:[code lang="bash"][root@iteblog.com ~]$ git clone https://github.com.cnpmjs.org/397090770/web正克隆到 'web'...Username for 'https://github.com.cnpmjs.org w397090770 5年前 (2019-06-14) 922℃ 0评论1喜欢
IntelliJ IDEA 2020.2 稳定版已发布,此版本带来了不少新功能,包括支持在 IDE 中审查和合并 GitHub PR、新增加的 Inspections 小组件(Inspections Widget)支持在文件的警告和错误之间快速导航、使用 Problems 工具窗口查看当前文件中的完整问题列表,并在更改会破坏其他文件时收到通知。此外还有针对部分框架和技术的新功能,包括支持使 w397090770 4年前 (2020-07-29) 373℃ 0评论2喜欢
下面文档是今天早上翻译的,因为要上班,时间比较仓促,有些部分没有翻译,请见谅。2017年06月01日儿童节 Apache Flink 社区正式发布了 1.3.0 版本。此版本经历了四个月的开发,共解决了680个issues。Apache Flink 1.3.0 是 1.x.y 版本线上的第四个主要版本,其 API 和其他 1.x.y 使用 @Public 注释的API是兼容的。此外,Apache Flink 社区目前制 w397090770 7年前 (2017-06-01) 2590℃ 1评论10喜欢
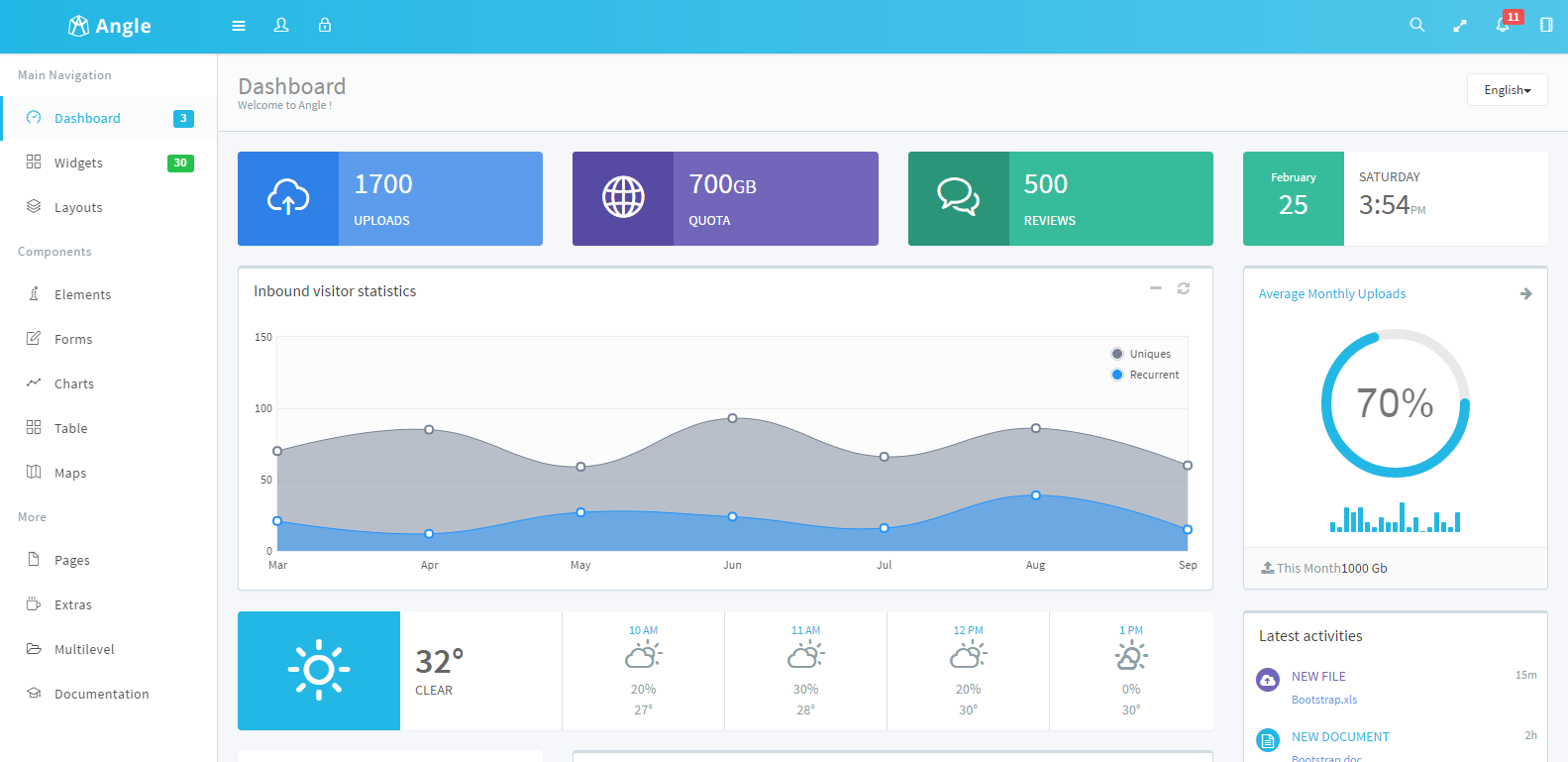
Angle Admin Template是一款后台管理模板,使用Bootstrap3.x作为界面框架,支持响应式布局。Angle包含JQuery和AngularJS两种js框架,方便SPA的使用,并且该模板提供了ASP.NET MVC、Angular、Rails等项目模板以及相应的种子模板,方便使用。点击下载Angle 3.5.4主题 该系列由于界面清爽,插件足够多、代码使用方便,文档齐全(英文), w397090770 8年前 (2017-02-25) 3222℃ 0评论16喜欢
在数据URI方面其是一个特别高效的utf-8 binary-to-text编码解决方案,可以用来替换base-64解决。对同一份数据进行编码,Base-122比Base-64小14%。Base-122当前是一个实验编码,后面可能会发生变化。基本使用Base-122编码产生utf-8字符,但每字节比base-64编码更多的位。[code lang="javascript"]let base122 = require('./base122');let inputData = require('fs'). w397090770 8年前 (2017-02-15) 917℃ 4喜欢
CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号。在本文中的CSV格式的数据就不是简单的逗号分割的),其文件以纯文本形式存储表格数据(数字和文本)。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字 w397090770 10年前 (2015-01-26) 9643℃ 0评论12喜欢
本文讲解的Hive和HBase整合意思是使用Hive读取Hbase中的数据。我们可以使用HQL语句在HBase表上进行查询、插入操作;甚至是进行Join和Union等复杂查询。此功能是从Hive 0.6.0开始引入的,详情可以参见HIVE-705。Hive与HBase整合的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive-hbase-handler-1.2.0.jar工具里面的类实现 w397090770 8年前 (2016-07-31) 17436℃ 0评论42喜欢
Hive内部提供了很多操作字符串的相关函数,本文将对其中部分常用的函数进行介绍。下表为Hive内置的字符串函数,具体的用法可以参见本文的下半部分。返回类型函数名描述intascii(string str)返回str第一个字符串的数值stringbase64(binary bin)将二进制参数转换为base64字符串 w397090770 9年前 (2016-04-24) 115959℃ 90喜欢
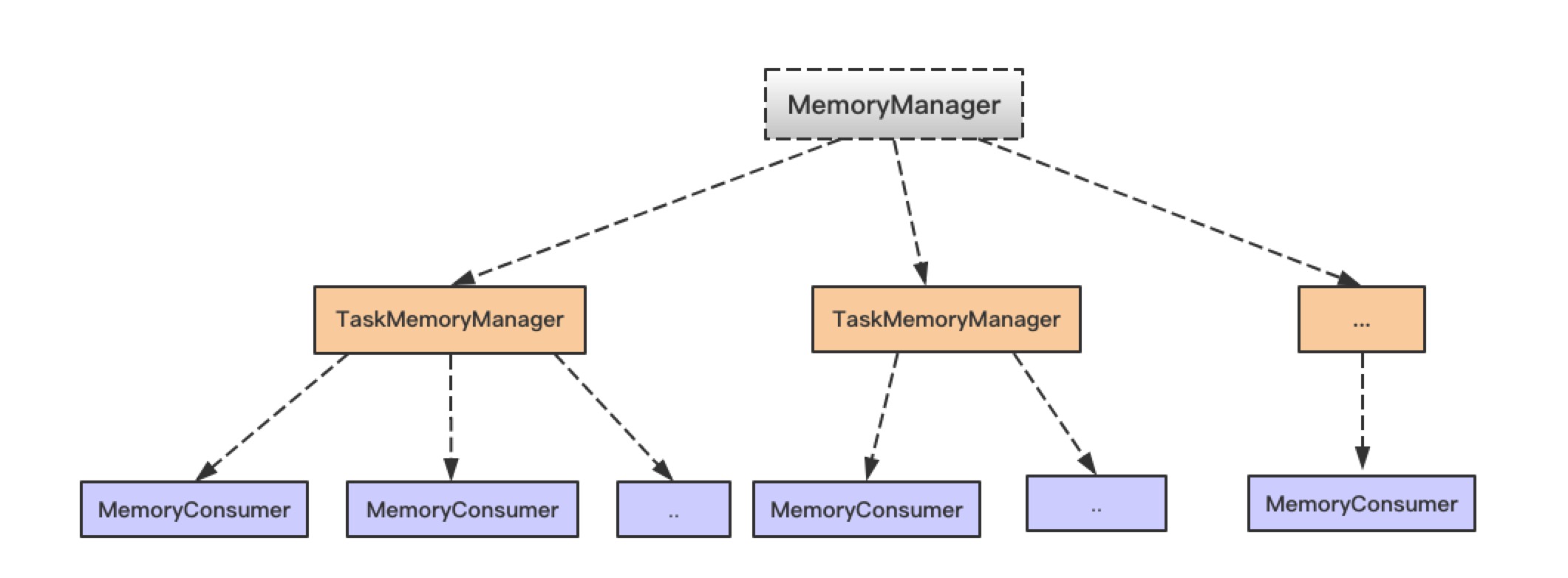
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段。那么在 Spark Shuffle 中具体是哪些地方会使用比较多的内存而有可能导致 OOM 呢? 为此,本文将围绕以上问题梳理 Spark 内存管理和 Shuffle 过程中与内存使用相关的知识;然后,简要分析下在 Spark Shuffle 中有可能导致 OOM w397090770 6年前 (2019-03-17) 5358℃ 0评论19喜欢
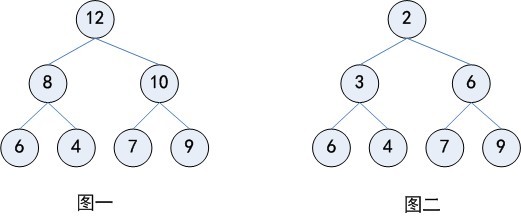
堆常用来实现优先队列,在这种队列中,待删除的元素为优先级最高(最低)的那个。在任何时候,任意优先元素都是可以插入到队列中去的,是计算机科学中一类特殊的数据结构的统称一、堆的定义最大(最小)堆是一棵每一个节点的键值都不小于(大于)其孩子(如果存在)的键值的树。大顶堆是一棵完全二叉树,同时也是 w397090770 12年前 (2013-04-01) 4864℃ 0评论3喜欢
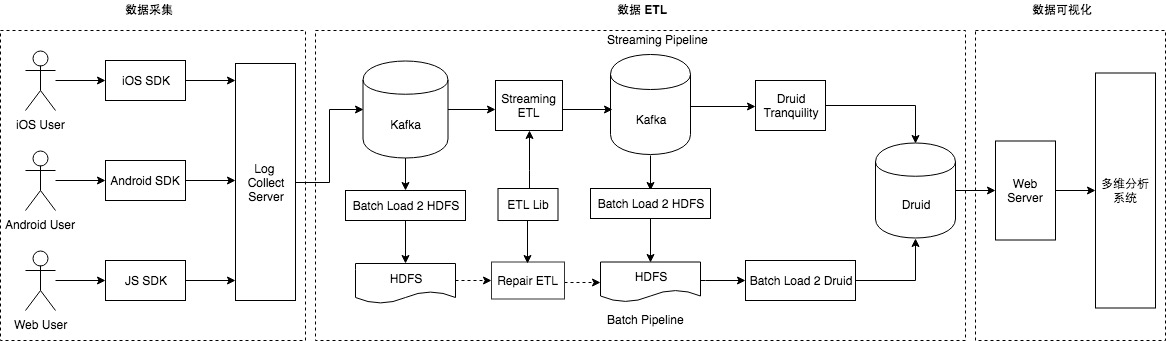
“数据智能” (Data Intelligence) 有一个必须且基础的环节,就是数据仓库的建设,同时,数据仓库也是公司数据发展到一定规模后必然会提供的一种基础服务。从智能商业的角度来讲,数据的结果代表了用户的反馈,获取结果的及时性就显得尤为重要,快速的获取数据反馈能够帮助公司更快的做出决策,更好的进行产品迭代,实时数 w397090770 6年前 (2019-02-16) 24226℃ 1评论46喜欢
今天 Apache Kafka 项目的 2.0.0 版本正式发布了!距离 1.0 版本的发布,相距还不到一年。这一年不论是社区还是 Confluent 内部对于到底 Kafka 要向哪里发展都有很多讨论:从最初的标准消息系统,到现如今成为一个完整的包括导入导出和处理的流数据平台,从 0.8.2 一直到 1.0 版本,很多新特性和新部件被不断添加。但同时更重要的,关于 w397090770 6年前 (2018-06-28) 5266℃ 0评论6喜欢
Wordpress的功能很强大,可以根据自己的需求来修改自己的网站。在Wordpress 3.5.1的中提供了默认的主题Twenty Twelve,很不错,但是首页显示的是全文信息,这不仅使得页面太长,也使得加载速度变的很慢,只有在搜索的时候才会显示摘要,那么怎么去让首页显示文章的摘要呢?到wordpress后台,依次选择 外观-->编辑-->选择右边的 w397090770 12年前 (2013-03-31) 27204℃ 9评论26喜欢
CarbonData是一种高性能大数据存储方案,支持快速过滤查找和即席OLAP分析,已在20+企业生产环境上部署应用,其中最大的单一集群数据规模达到几万亿。针对当前大数据领域分析场景需求各异而导致的存储冗余问题,业务驱动下的数据分析灵活性要求越来越高,CarbonData提供了一种新的融合数据存储方案,以一份数据同时支持多种应 w397090770 7年前 (2018-02-09) 1827℃ 0评论13喜欢
本书于2015年04月出版,共168页,这里提供的是本书的完整版. w397090770 9年前 (2015-08-24) 3178℃ 0评论5喜欢
Balloon.css文件允许用户给元素添加提示,而这些在Balloon.css中完全是由CSS来实现,不需要使用JavaScript。 button { display: inline-block; min-width: 160px; text-align: center; color: #fff; background: #ff3d2e; padding: 0.8rem 2rem; font-size: 1.2rem; margin-top: 1rem; border: none; border-radius: 5px; transition: background 0.1s linear;}.butt w397090770 9年前 (2016-03-15) 2474℃ 3评论10喜欢
TPC-H是事务处理性能委员会( Transaction ProcessingPerformance Council )制定的基准程序之一,TPC- H 主要目的是评价特定查询的决策支持能力,该基准模拟了决策支持系统中的数据库操作,测试数据库系统复杂查询的响应时间,以每小时执行的查询数(TPC-H QphH@Siz)作为度量指标。我们在很多大数据系统上线或者产品上线的时候一般都会测 w397090770 3年前 (2021-10-29) 1603℃ 0评论5喜欢
Spark的作业会通过DAGScheduler的处理生产许多的Task并构建成DAG图,而分割出的Task最终是需要经过网络分发到不同的Executor。在分发的时候,Task一般都会依赖一些文件和Jar包,这些依赖的文件和Jar会对增加分发的时间,所以Spark在分发Task的时候会将Task进行序列化,包括对依赖文件和Jar包的序列化。这个是通过spark.closure.serializer参数 w397090770 9年前 (2015-11-16) 6272℃ 0评论8喜欢
Apache Hadoop 2.5.2于2014年11月19日发布,该版本是2.5.x的分支,主要修复了2.5.0之后的一些关键bug: HADOOP-11243. SSLFactory shouldn't allow SSLv3. (Wei Yan via kasha) HADOOP-11260. Patch up Jetty to disable SSLv3. (Mike Yoder via kasha) HADOOP-11307. create-release script should run git clean first. (kasha) 下面是2.5.2中功能提升的简单概述:Common 1、 HTTP w397090770 10年前 (2014-11-24) 5402℃ 1评论5喜欢
在TCP/IP状态图中,有很多种的状态,它们之间有的是可以互相转换的,也就是说,从一种状态转到另一种状态,但是这种转换不是随便发送的,是要满足一定的条件。TCP/IP状态图看起来更像是自动机。下图即为TCP/IP状态。由上图可以看出,一共有11种不同的状态。这11种状态描述如下: CLOSED:关闭状态,没有连接活动或正在进 w397090770 12年前 (2013-04-03) 11237℃ 0评论15喜欢
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据。我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等。但是这些方式不是慢就是在导入的过程的占用Region资源导致效率低下,所以很不适合一次性导入大量数据。本文将针对这个问题介绍如何通过Hbase的BulkLoad方法来快速将海量数据导入到Hbas w397090770 8年前 (2016-11-28) 17774℃ 2评论52喜欢
我们可以通过CLI、Client、Web UI等Hive提供的用户接口来和Hive通信,但这三种方式最常用的是CLI;Client 是Hive的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出Hive Server所在节点,并且在该节点启动 Hive Server。 WUI 是通过浏览器访问 Hive。今天我们来谈谈怎么通过HiveServer来操作Hive。Hive提供了jdbc驱动,使得我们可以 w397090770 11年前 (2013-12-17) 65574℃ 6评论55喜欢
有一种非常常见的场景那就是使用其他数据库作为主要的数据存储,而Elasticsearch用来检索数据。这也意味着主数据库发生的一切变更都需要将其拷贝到Elasticsearch中。如果这时候有多个进程负责数据的同步,就会遇到《Elasticsearch乐观锁并发控制(optimistic concurrency control)》文章中提到的并发问题。 如果你的主数据库已经有 w397090770 8年前 (2016-08-12) 1653℃ 0评论0喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事 在Hive中,我们应该都听过RCFile这种格 w397090770 11年前 (2014-04-16) 83924℃ 9评论76喜欢
本文基于 A Guide To The Kafka Protocol 2017-06-14 的版本 v114 进行翻译的。简介本文档涵盖了 Kafka 0.8 及更高版本的通信协议实现。它旨在提供一个可读的,涵盖可请求的协议及其二进制格式,以及如何正确使用他们来实现一个客户端的协议指南。本文假设您已经了解了 Kafka 的基本设计以及术语。0.7 及更早的版本所使用的协议与此 w397090770 6年前 (2018-07-11) 4171℃ 1评论12喜欢
Linux安装软件依赖问题解决办法[code lang="java"][wyp@localhost Downloads]$ rpm -i --aid AdobeReader_chs-8.1.7-1.i486.rpm error: Failed dependencies: libatk-1.0.so.0 is needed by AdobeReader_chs-8.1.7-1.i486 libc.so.6 is needed by AdobeReader_chs-8.1.7-1.i486 libc.so.6(GLIBC_2.0) is needed by AdobeReader_chs-8.1.7-1.i486 libc.so.6(GLIBC_2.1) is needed by AdobeReader_chs-8.1.7-1.i486 libc.so.6(GLIBC_2.1.3) is n w397090770 10年前 (2014-10-09) 7807℃ 0评论4喜欢
相信很多网站为了方便使用了百度分享工具,但是官方提供的类库只支持HTTP方式来访问,如果你网站升级成HTTPS之后,将无法使用百度分享。不过大家别担心,本文就是来教大家解决这个问题的。 原理很简单,下载本文下面提供的包(static.tgz),然后放到你网站的根目录,这些文件其实就是从百度分享网站下载下来的,如 w397090770 8年前 (2016-12-31) 2941℃ 0评论8喜欢
本博客盘点了过去两年晋升为 Apache TLP(Apache Top-Level Project) 的大数据相关项目,具体参见《盘点2017年晋升为Apache TLP的大数据相关项目》、《盘点2018年晋升为Apache TLP的大数据相关项目》,继承这个惯例,本文将给大家盘点2019年晋升为 Apache TLP 的大数据相关项目,由于今年晋升成 TLP 的大数据项目很少,只有三个,而且其中两个好 w397090770 5年前 (2019-12-30) 2208℃ 0评论7喜欢
Learning Spark这本书链接是完整版,和之前的预览版是不一样的,我不是标题党。这里提供的Learning Spark电子书格式是mobi、pdf以及epub三种格式的文件,如果你有亚马逊Kindle电子书阅读器,是可以直接阅读mobi、pdf。但如果你用电脑,也可以下载相应的PC版阅读器 。如果你需要阅读器,可以找我。如果想及时了解Spark、Hadoop或者Hbase相 w397090770 10年前 (2015-02-11) 50864℃ 305评论70喜欢










![通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]](https://www.iteblog.com/pic/hbase_Bulkload_iteblog.png)