在 《使用Python编写Hive UDF》 文章中,我简单的谈到了如何使用 Python 编写 Hive UDF 解决实际的问题。我们那个例子里面仅仅是一个很简单的示例,里面仅仅引入了 Python 的 sys 包,而这个包是 Python 内置的,所有我们不需要担心 Hadoop 集群中的 Python 没有这个包;但是问题来了,如果我们现在需要使用到 numpy 中的一些函数呢?假设我们 w397090770 7年前 (2018-01-25) 6514℃ 3评论23喜欢
默认情况下,Flume中的PollingPropertiesFileConfigurationProvider会每隔30秒去重新加载Flume agent的配置文件,如果监听到配置文件变化了,Flume会试图重新加载变化的配置文件。判断配置文件是否变化主要是基于文件的最后修改时间来的,代码片段如下:[code lang="java"]///////////////////////////////////////////////////////////////////// User: 过往记忆 w397090770 9年前 (2015-08-20) 6667℃ 0评论13喜欢
今天将临时表里面的数据按照天分区插入到线上的表中去,出现了Hive创建的文件数大于100000个的情况,我的SQL如下:[code lang="sql"]///////////////////////////////////////////////////////////////////// User: 过往记忆 Date: 2015-11-18 Time: 23:24 bolg: 本文地址:/archives/1533 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量 w397090770 9年前 (2015-11-18) 22941℃ 3评论53喜欢
Delta Lake 是一个存储层,为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构建在 HDFS 和云存储上的数据湖(data lakes)带来可靠性。Delta Lake 还提供内置数据版本控制,以便轻松回滚。为了更好的学习 Delta Lake ,本文 w397090770 5年前 (2019-09-09) 3968℃ 0评论4喜欢
在今年的5月22号,Flume-ng 1.5.0版本正式发布,关于Flume-ng 1.5.0版本的新特性可以参见本博客的《Apache Flume-ng 1.5.0正式发布》进行了解。关于Apache flume-ng 1.4.0版本的编译可以参见本博客《基于Hadoop-2.2.0编译flume-ng 1.4.0及错误解决》。本文将讲述如何用Maven编译Apache flume-ng 1.5.0源码。一、到官方网站下载相应版本的flume-ng源码[code lan w397090770 10年前 (2014-06-16) 20781℃ 23评论14喜欢
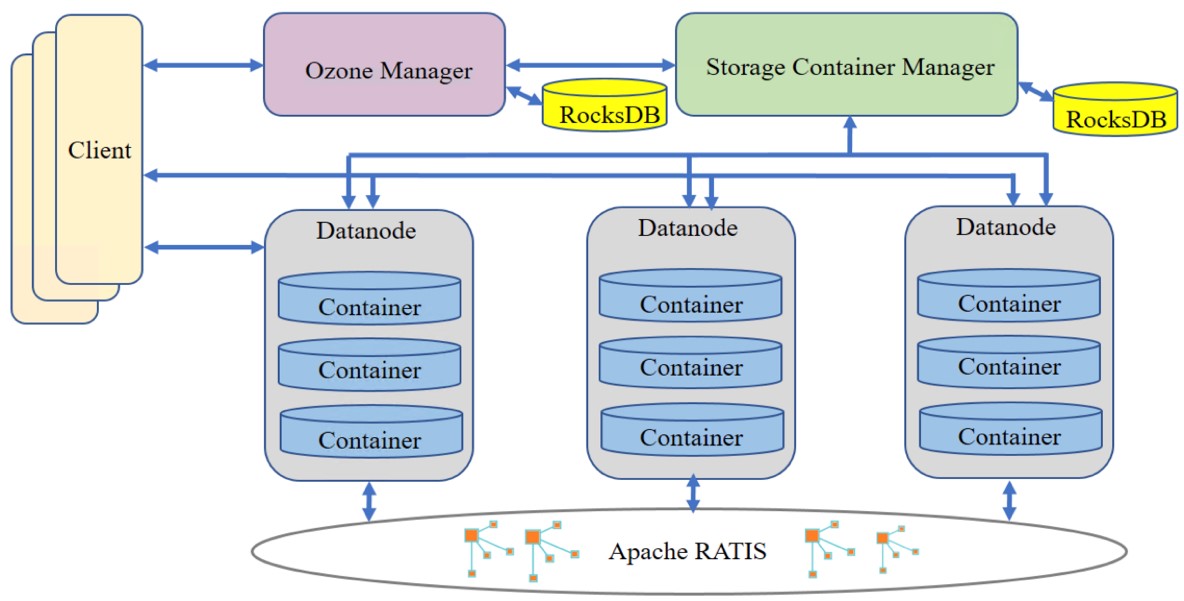
刚刚获悉,Apache基金董事会通过一致表决,正式批准分布式文件对象存储Ozone从Hadoop社区孵化成功,成为独立的Apache顶级开源项目。这意味着,作为腾讯大数据团队首个参与和主导的开源项目,Ozone已得到全球Apache技术专家的一致认可,成为世界顶级的存储开源项目之一。Ozone 是Apache Hadoop社区推出的面向大数据领域的新一代分布 w397090770 4年前 (2020-12-09) 1084℃ 0评论7喜欢
安装:下载并启动 Flink可以在Linux、Mac OS X以及Windows上运行。为了能够运行Flink,唯一的要求是必须安装Java 7.x或者更高版本。对于Windows用户来说,请参考 Flink on Windows 文档,里面介绍了如何在Window本地运行Flink。下载 从下载页面(http://flink.apache.org/downloads.html)下载所需的二进制包。你可以选择任何与 Hadoop/Scala 结 w397090770 9年前 (2016-04-05) 17696℃ 0评论23喜欢
在即将发布的 Apache Spark™ 3.2 版本中 pandas API 将会成为其中的一部分。Pandas 是一个强大、灵活的库,并已迅速发展成为标准的数据科学库之一。现在,pandas 的用户将能够在他们现有的 Spark 集群上利用 pandas API。几年前,我们启动了 Koalas 这个开源项目,它在 Spark 之上实现了 Pandas DataFrame API,并被数据科学家广泛采用。最近,Koala w397090770 3年前 (2021-10-13) 811℃ 0评论3喜欢
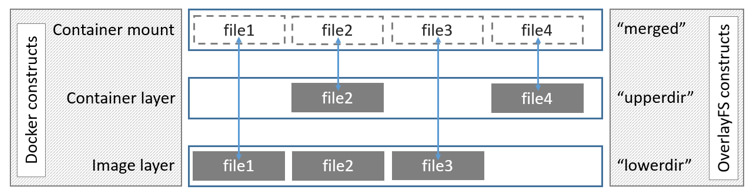
我们在 Docker 入门教程:镜像分层 和 Docker 入门教程:Docker 基础技术 Union File System 已经介绍了一些前提基础知识,本文我们来介绍 Union File System 在 Docker 的应用。为了使 Docker 能够在 container 的 writable layer 写一些比较小的数据(如果需要写大量的数据可以通过挂载盘去写),Docker 为我们实现了存储驱动(storage drivers)。Docker 使 w397090770 5年前 (2020-02-16) 756℃ 0评论5喜欢
本书由Andrew Morgan所著,全书共560页;Packt Publishing出版社于2017年03月出版。通过本书你将学习到以下的知识: 1、Learn the design patterns that integrate Spark into industrialized data science pipelines 2、See how commercial data scientists design scalable code and reusable code for data science services 3、Explore cutting edge data science methods so that you can study tre zz~~ 8年前 (2017-04-17) 3515℃ 2评论8喜欢
Wordpress的功能很强大,可以根据自己的需求来修改自己的网站。在Wordpress 3.5.1的中提供了默认的主题Twenty Twelve,很不错,但是首页显示的是全文信息,这不仅使得页面太长,也使得加载速度变的很慢,只有在搜索的时候才会显示摘要,那么怎么去让首页显示文章的摘要呢?到wordpress后台,依次选择 外观-->编辑-->选择右边的 w397090770 12年前 (2013-03-31) 27204℃ 9评论26喜欢
Apache Spark 发布了 Delta Lake 0.4.0,主要支持 DML 的 Python API、将 Parquet 表转换成 Delta Lake 表 以及部分 SQL 功能。 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop下面详细地介绍这些功能部分功能的 SQL 支持SQL 的支持能够为用户提供极大的便利,如果大家去看数砖的 Delta Lake 产品,你肯定已 w397090770 5年前 (2019-10-01) 1292℃ 0评论4喜欢
Learning Apache Flink又名Mastering Apache Flink,是由Tanmay Deshpande所著,2017年02月在Packt出版,全书共280页。这本书是学习Apache Flink进行批处理和流数据处理的入门指南。本书首先介绍Apache Flink生态系统,然后介绍如何设置Apache Flink,并使用DataSet和DataStream API分别处理静态数据和流数据。本书将探讨如何在数据集上使用Table API。在本书的 zz~~ 8年前 (2017-02-24) 16260℃ 0评论19喜欢
IntelliJ IDEA 2020.2 稳定版已发布,此版本带来了不少新功能,包括支持在 IDE 中审查和合并 GitHub PR、新增加的 Inspections 小组件(Inspections Widget)支持在文件的警告和错误之间快速导航、使用 Problems 工具窗口查看当前文件中的完整问题列表,并在更改会破坏其他文件时收到通知。此外还有针对部分框架和技术的新功能,包括支持使 w397090770 4年前 (2020-07-29) 373℃ 0评论2喜欢
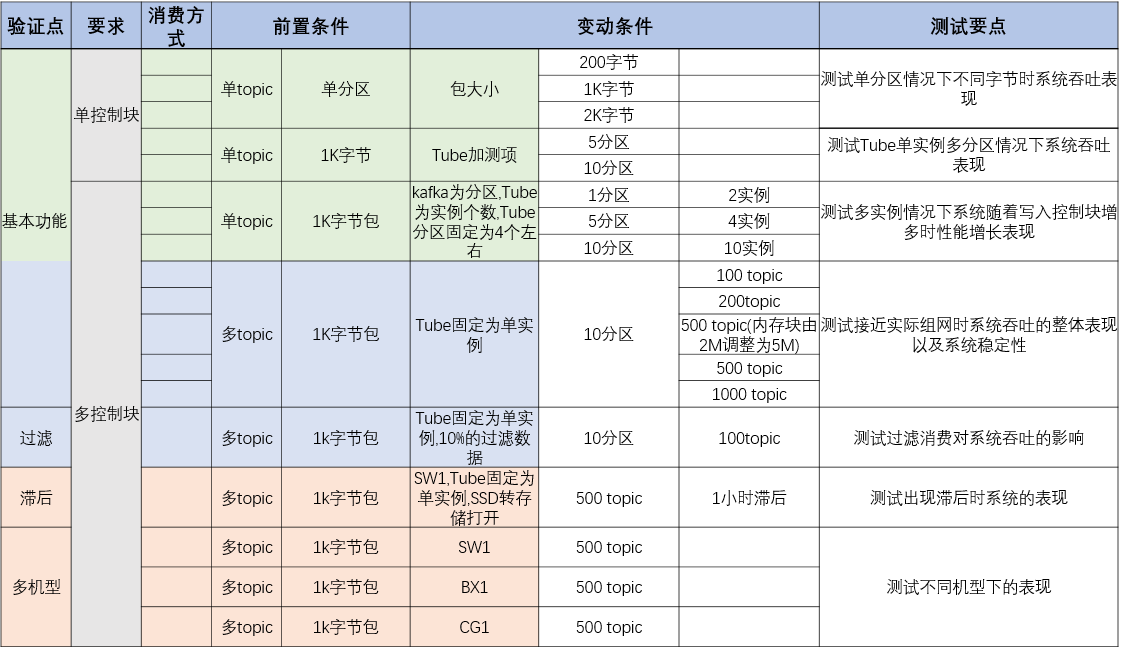
TubeMQ 是腾讯在 2013 年自研的分布式消息中间件系统,专注服务大数据场景下海量数据的高性能存储和传输,经过近7年上万亿的海量数据沉淀,目前日均接入量超过25万亿条。较之于众多明星的开源MQ组件,TubeMQ 在海量实践(稳定性+性能)和低成本方面有着比较好的核心优势。该项目于 2019年11月03日正式进入 Apache 孵化器。TubeMQ的 w397090770 5年前 (2019-09-18) 629℃ 0评论2喜欢
在这篇文章中,我将介绍如何在Spark中使用Akka-http并结合Cassandra实现REST服务,在这个系统中Cassandra用于数据的存储。 我们已经见识到Spark的威力,如果和Cassandra正确地结合可以实现更强大的系统。我们先创建一个build.sbt文件,内容如下:[code lang="scala"]name := "cassandra-spark-akka-http-starter-kit"version := "1.0" w397090770 8年前 (2016-10-17) 3867℃ 1评论5喜欢
如何下载整个网站用来离线浏览?怎样将一个网站上的所有 MP3 文件保存到本地的一个目录中?怎么才能将需要登陆的网页后面的文件下载下来?怎样构建一个迷你版的Google?wget 是一个自由的工具,可在包括 Mac,Window 和 Linux 在内的多个平台上使用,它可帮助你实现所有上述任务,而且还有更多的功能。与大多数下载管理器不同 w397090770 9年前 (2016-02-19) 1737℃ 0评论1喜欢
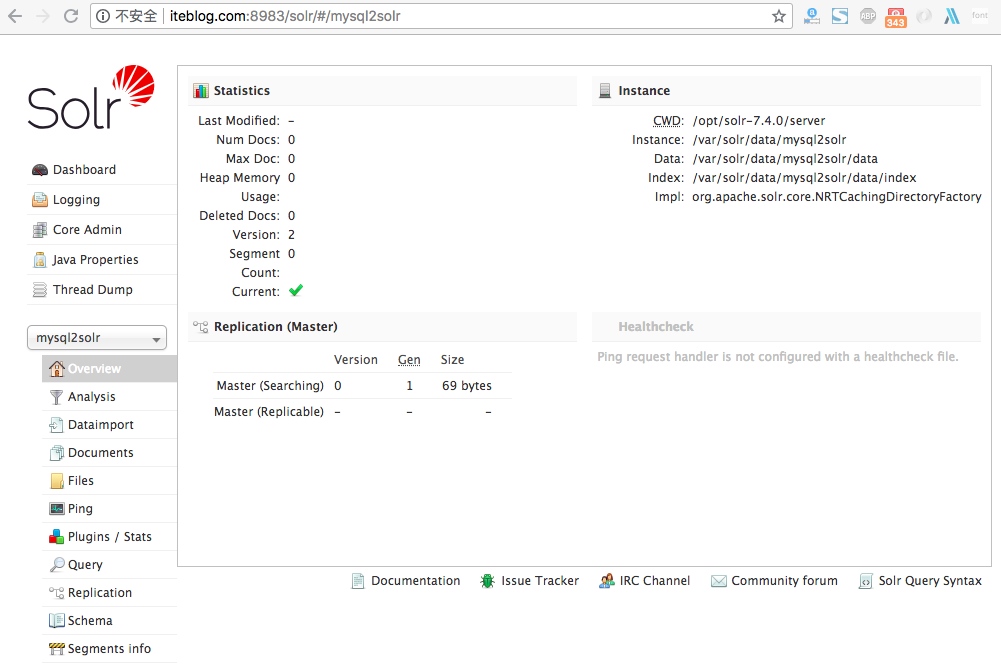
关于分页方式导入全量数据请参照《将 MySQL 的全量数据以分页的形式导入到 Apache Solr 中》。在前面几篇文章中我们介绍了如何通过 Solr 的 post 命令将各种各样的文件导入到已经创建好的 Core 或 Collection 中。但有时候我们需要的数据并不在文件里面,而是在别的系统中,比如 MySql 里面。不过高兴的是,Solr 针对这些数据也提供了 w397090770 6年前 (2018-08-06) 1938℃ 0评论2喜欢
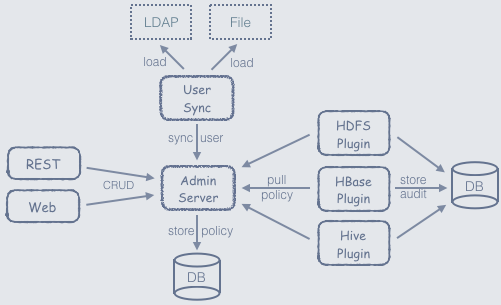
Apache Ranger 是一个用在 Hadoop 平台上并提供操作、监控、管理综合数据安全的框架。Ranger 的愿景是在 Apache Hadoop 生态系统中提供全面的安全性。 目前,Apache Ranger 支持以下 Apache 项目的细粒度授权和审计:Apache HadoopApache HiveApache HBaseApache StormApache KnoxApache SolrApache KafkaYARN对于上面那些受支持的 Hadoop 组件,Ranger 通过访 w397090770 7年前 (2018-01-07) 9197℃ 2评论16喜欢
最近有个项目需要用到手机归属地信息,所有网上找到了一些免费的API。但是因为是免费的,所有很多都有限制,比如每天只能查询多少次等。本站提供的API地址: /api/mobile.php?mobile=13188888888参数:mobile ->手机号码(7位到11位)返回格式:JSON实例结果:[code lang="scala"]{ "ID": "18889", "prefix": &q w397090770 8年前 (2016-08-02) 8018℃ 4评论16喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-09-16) 119806℃ 4评论290喜欢
Apache Spark 2.0发布信息可以参见《Apache Spark 2.0.0正式发布及其功能介绍》 我们很荣幸地宣布,自7月26日起Databricks开始提供Apache Spark 2.0的下载,这个版本是基于社区在过去两年的经验总结而成,不但加入了用户喜爱的功能,也修复了之前的痛点。 本文总结了Spark 2.0的三大主题:更简单、更快速、更智能,另有Spark w397090770 8年前 (2016-07-28) 14380℃ 0评论28喜欢
为帮助开发者更深入的了解这三个大数据开源技术及其实际应用场景,9月8日,InfoQ联合华为云举办了一场实时大数据Meetup,集结了来自Databricks、华为及美团点评的大咖级嘉宾前来分享。作为Spark Structured Streaming最核心的开发人员、Databricks工程师,Tathagata Das(以下简称“TD”)在开场演讲中介绍了Structured Streaming的基本概念 w397090770 6年前 (2018-09-21) 4802℃ 0评论10喜欢
如果你想搭建伪分布式Hadoop平台,请参见本博客《在Fedora上部署Hadoop2.2.0伪分布式平台》 经过好多天的各种折腾,终于在几台电脑里面配置好了Hadoop2.2.0分布式系统,现在总结一下如何配置。 前提条件: (1)、首先在每台Linux电脑上面安装好JDK6或其以上版本,并设置好JAVA_HOME等,测试一下java、javac、jps等命令 w397090770 11年前 (2013-11-06) 21278℃ 6评论27喜欢
本书作者:Steve Hoffman,由Packt 出版社于2015年02月出版,全书共178页。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[code lang="bash"]Chapter 1: Overview and ArchitectureChapter 2: A Quick Start Guide to FlumeChapter 3:ChannelsChapter 4:Sinks and Sink ProcessorsChapter 5: Sources and Channel SelectorsChapter 6: w397090770 9年前 (2015-08-25) 3920℃ 10评论3喜欢
题目以及要求:把一个字符串的大写字母放到字符串的后面,各个字符的相对位置不变,不能申请额外的空间。我的实现类似冒泡排序。[code lang="CPP"]#include <stdio.h>#include <string.h>// Author: 397090770// E-mail:wyphao.2007@163.com// Blog: // Date: 2012/09/29//题目以及要求:把一个字符串的大写字母放到字符串的后面,// w397090770 12年前 (2013-04-02) 3908℃ 0评论1喜欢
为了方便集群的部署,一般我们都会构建出一个 dokcer 镜像,然后部署到 k8s 里面。Presto、Prestissimo 以及 Velox 也不例外,本文将介绍如果构建 presto 以及 Prestissimo 的镜像。构建 Presto 镜像Presto 官方代码里面其实已经包含了构建 Presto 镜像的相关文件,具体参见 $PRESTO_HOME/docker 目录:[code lang="bash"]➜ target git:(velox_docker) ✗ ll ~/ w397090770 1年前 (2023-06-21) 423℃ 0评论8喜欢
在过去Spark社区创建了Spark 2.0的技术预览版,经过几天的投票,目前该技术预览版今天正式公布。《Spark 2.0技术预览:更容易、更快速、更智能》文章中详细介绍了Spark 2.0给我们带来的新功能,总体上Spark 2.0提升了下面三点: 1. 对标准的SQL支持,统一DataFrame和Dataset API。现在已经可以运行TPC-DS所有的99个查询,这99个查 w397090770 8年前 (2016-05-25) 2620℃ 0评论3喜欢
Apache CarbonData 1.4.0 于 2018年06月06日正式发布。更新内容请参见 Apache CarbonData 1.4.0 正式发布,多项新功能及性能提升。Apache CarbonData 是一种新的融合存储解决方案,利用先进的列式存储,索引,压缩和编码技术提高计算效率,从而加快查询速度,其查询速度比 PetaBytes 数据快一个数量级。 鉴于目前使用 Apache CarbonData 用户越来越 w397090770 6年前 (2018-06-12) 4286℃ 0评论18喜欢
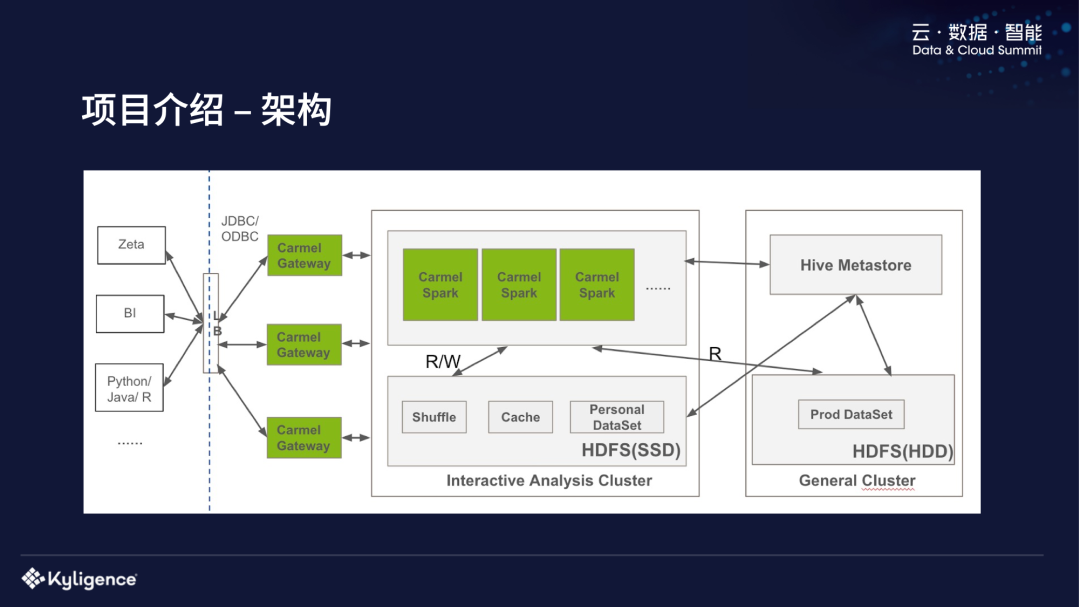
系统介绍我们这个系统的名字叫 Carmel,它是基于开源的 Hadoop 和 Spark 来替换传统的数据仓库,我们是 2019 年开始做我们这个项目的,当时是基于 Spark 2.3.1,最近刚刚升到 Spark 3.0。面临的主要技术挑战,第一个是功能方面的缺失,包括访问控制,还有一些 Update 和 Delete 的支持;在性能方面跟传统数仓,特别是交互式的分析查询中性 zz~~ 3年前 (2021-09-24) 647℃ 0评论2喜欢



![[电子书]Mastering Spark for Data Science PDF下载](https://www.iteblog.com/pic/books/mastering-spark-data-science_iteblog.jpg)


![[电子书]Learning Apache Flink PDF下载](https://www.iteblog.com/pic/flink/Mastering_Apache_Flink_iteblog.png)