Apache Flink开源大数据处理系统最近比较火,特别是其流处理框架的设计。本文并不打算介绍Apache Flink的相关概念,如果你感兴趣可以到本博客的Flink分类目录查看Flink的相关文章。 转入正题了,下面将一步一步教你如何提交你的代码到Flink社区。1、提交Issue 既然能够提交代码肯定是发现了什么Bug,或者有什么好 w397090770 8年前 (2016-11-21) 3417℃ 0评论4喜欢
我们期待已久的Spark 1.1.0在美国时间的9月11日正式发布了,官方发布的声明如下:We are happy to announce the availability of Spark 1.1.0! Spark 1.1.0 is the second release on the API-compatible 1.X line. It is Spark’s largest release ever, with contributions from 171 developers!This release brings operational and performance improvements in Spark core including a new implementation of the Spark w397090770 10年前 (2014-09-12) 3799℃ 0评论2喜欢
2015年中国大数据技术大会已经圆满落幕,本届大会历时三天(2015-12-10~2015-12-12),以更加国际化的视野,从政策法规、技术实践和产业应用等角度深入探讨大数据落地后的挑战,作为大数据产业界、科技界与政府部门密切合作的重要平台,吸引了数千名大数据技术爱好者到场参会。 本届大会邀请了近百余位国内外顶尖的 w397090770 9年前 (2015-12-18) 5513℃ 0评论11喜欢
我使用的是Spark 1.5.2和HDP 2.2.4.8,在启动spark-shell的时候出现了以下的异常:[code lang="bash"][itebog@www.iteblog.com ~]$ bin/spark-shell --master yarn-client...at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala):10: error: not found: value sqlContext import sqlContext.implicits._:10: error: not found: value sqlContext import sqlContext.sql[/code]你打开Application w397090770 9年前 (2016-01-15) 4655℃ 0评论2喜欢
在使用Hadoop的时候,一般配置SSH使得我们可以无密码登录到主机,下面分别以Ubuntu和CentOS两个平台来举例说明如何配置SSH使得我们可以无密码登录到主机,当然,你得先安装好SSH服务器,并开启(关于如何在Linux平台下安装好SSH请参加本博客的《Linux平台下安装SSH》)在 Ubuntu 平台设置 SSH 无秘钥登录Ubuntu配置步骤如下所示:[c w397090770 11年前 (2013-10-24) 7786℃ 4评论3喜欢
前言本文讨论了京东搜索在实时流量数据分析方面,利用Apache Flink和Apache Doris进行的探索和实践。流式计算在近些年的热度与日俱增,从Google Dataflow论文的发表,到Apache Flink计算引擎逐渐站到舞台中央,再到Apache Druid等实时分析型数据库的广泛应用,流式计算引擎百花齐放。但不同的业务场景,面临着不同的问题,没有哪一种引 w397090770 4年前 (2020-12-25) 1285℃ 0评论4喜欢
我们都知道,HDFS设计是用来存储海量数据的,特别适合存储TB、PB量级别的数据。但是随着时间的推移,HDFS上可能会存在大量的小文件,这里说的小文件指的是文件大小远远小于一个HDFS块(128MB)的大小;HDFS上存在大量的小文件至少会产生以下影响:消耗NameNode大量的内存延长MapReduce作业的总运行时间如果想及时了解Spar w397090770 8年前 (2017-04-25) 6765℃ 1评论18喜欢
Spark SQL从2.0开始已经不再支持ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...)这种语法了(下文简称add columns语法)。如果你的Spark项目中用到了SparkSQL+Hive这种模式,从Spark1.x升级到2.x很有可能遇到这个问题。为了解决这个问题,我们一般有3种方案可以选择: 1、启动一个hiveserver2服务,通过jdbc直接调用hive w397090770 8年前 (2017-02-27) 3033℃ 0评论5喜欢
Apache Hadoop 2.7.0发布。一共修复了来自社区的535个JIRAs,其中:Hadoop Common有160个;HDFS有192个;YARN有148个;MapReduce有35个。Hadoop 2.7.0是2015年第一个Hadoop release版本,不过需要注意的是 (1)、不要将Hadoop 2.7.0用于生产环境,因为一些关键Bug还在测试中,如果需要在生产环境使用,需要等Hadoop 2.7.1/2.7.2,这些版本很快会发布。 w397090770 10年前 (2015-04-24) 8837℃ 0评论14喜欢
Shanghai Apache Spark Meetup第九次聚会在6月18日下午13:00-17:00由Intel联手饿了么在上海市普陀区金沙江路1518弄2号近铁城市广场饿了么公司5楼会议室(榴莲酥+螺狮粉)举行。分享主题演讲者1: 史鸣飞, 英特尔大数据工程师演讲者2: 史栋杰, 英特尔大数据工程师演讲者3: 毕洪宇,饿了么数据运营部副总监演讲者4: 张家劲, w397090770 8年前 (2016-06-25) 2129℃ 0评论4喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章介绍了Spark的三大新特性,本文是Reynold Xin在2016年5月5日的演讲,视频可以到这里看:http://go.databricks.com/apache-spark-2.0-presented-by-databricks-co-founder-reynold-xinPPT下载地址见下面。 w397090770 8年前 (2016-05-24) 3267℃ 0评论4喜欢
在互联网网络中,当网络发生拥塞(congestion)时,交换机将开始丢弃数据包。这可能导致数据重发(retransmissions)、数据包查询(query packets),这些操作将进一步导致网络的拥塞。为了防止网络拥塞(network congestion),需限制流出网络的流量,使流量以比较均匀的速度向外发送。主要有两种限流算法:漏桶算法(Leaky Bucket)和 w397090770 6年前 (2018-06-04) 3334℃ 0评论4喜欢
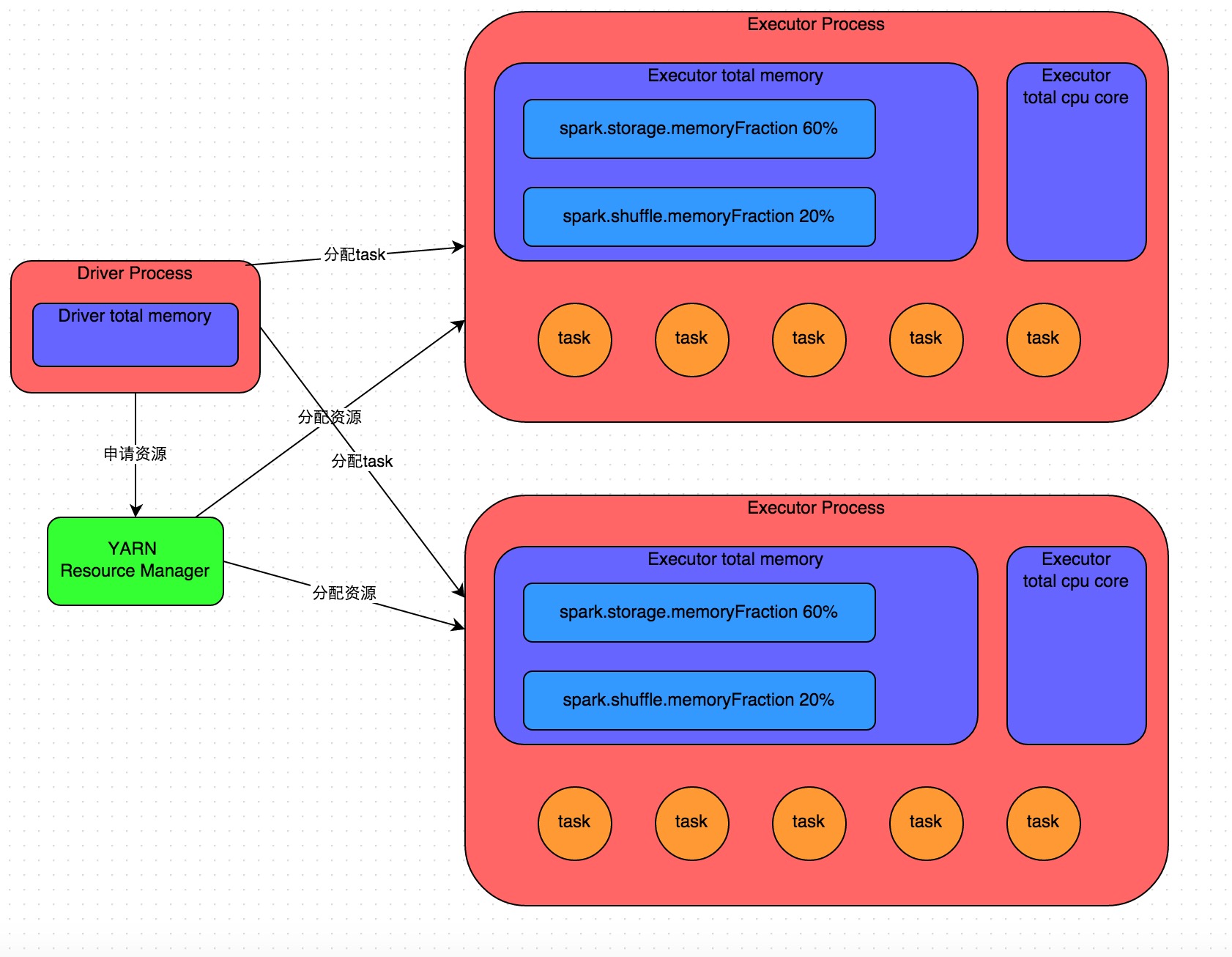
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在开发完Spark作业之后,就该为作业配置合适的资源了。Spark的资源参数,基本都可以在spark-submit命令中作为参数设置。很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置这些参 w397090770 9年前 (2016-05-04) 30886℃ 8评论38喜欢
这几天在集群上部署了Shark 0.9.1,我下载的是已经编译好的,Hadoop版本是2.2.0,下面就总结一下我在安装Shark的过程中遇到的问题及其解决方案。一、YARN mode not available ?[code lang="JAVA"]Exception in thread "main" org.apache.spark.SparkException: YARN mode not available ? at org.apache.spark.SparkContext$.org$apache$spark$SparkContext$$createTaskScheduler(SparkContext. w397090770 11年前 (2014-05-05) 16048℃ 3评论4喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive的内置数据类型可以分 w397090770 11年前 (2013-12-23) 15493℃ 1评论14喜欢
本文根据2016年4月北京Apache Kylin Meetup上的分享讲稿整理,略有删节。美团各业务线存在大量的OLAP分析场景,需要基于Hadoop数十亿级别的数据进行分析,直接响应分析师和城市BD等数千人的交互式访问请求,对OLAP服务的扩展性、稳定性、数据精确性和性能均有很高要求。本文主要介绍美团的具体OLAP需求,如何将Kylin应用到实际场景 w397090770 8年前 (2016-07-17) 9681℃ 0评论9喜欢
Apache Spark Delta Lake 的更新(update)和删除都是在 0.3.0 版本发布的,参见这里,对应的 Patch 参见这里。和前面几篇源码分析文章一样,我们也是先来看看在 Delta Lake 里面如何使用更新这个功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopDelta Lake 更新使用Delta Lake 的官方文档为我们提供如何 w397090770 5年前 (2019-10-19) 2047℃ 0评论3喜欢
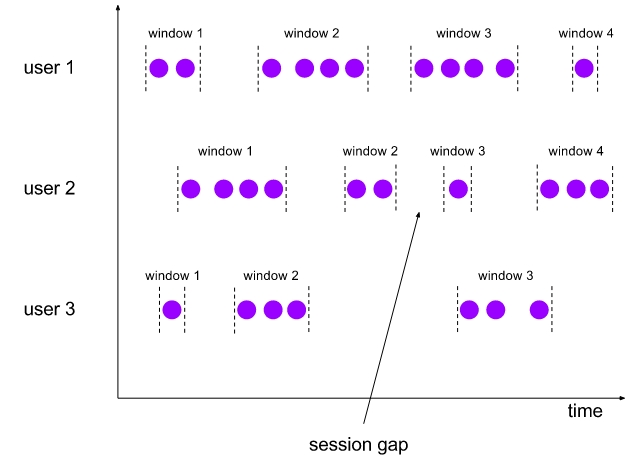
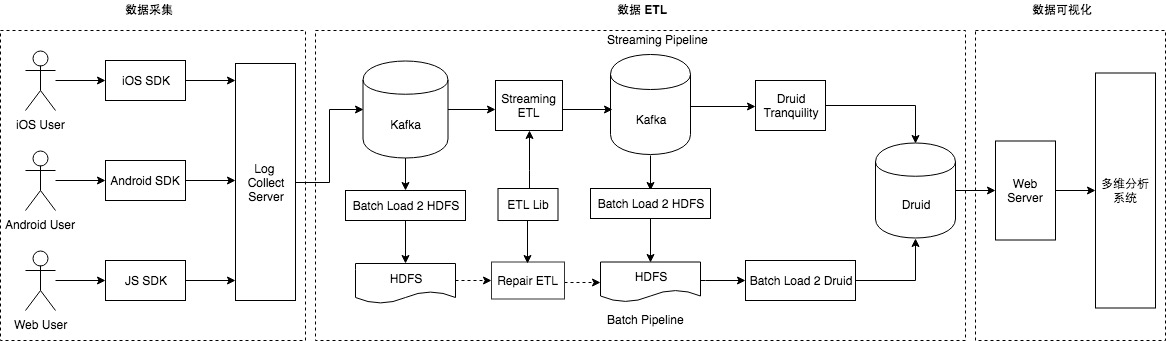
Airbnb 日志事件获取日志事件从客户端(例如移动应用程序和 Web 浏览器)和在线服务发出,其中包含行为或操作的关键信息。每个事件都有一个特定的信息。例如,当客人在 Airbnb.com 上搜索马里布的海滨别墅时,将生成包含位置,登记和结账日期等的搜索事件。在 Airbnb,事件记录对于我们理解客人和房东,然后为他们提供更 w397090770 5年前 (2019-05-19) 2860℃ 0评论8喜欢
Spark SQL也是可以直接部署在当前的Hive wareHouse。 Spark SQL 1.1.0的 Thrift JDBC server 被设计成兼容当前的Hive数据仓库。你不需要修改你的Hive元数据,或者是改变表的数据存放目录以及分区。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 以下列出来的是当前Spark SQL(1.1.0)对Hive特性的 w397090770 10年前 (2014-09-11) 9410℃ 1评论8喜欢
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个广泛应用于统计计算和统计制图的优秀编程语言,但是其交互式使用通常局限于一台机器。为了能够使用R语言分析大规模分布式的数据,UC Berkeley给我们带来了SparkR,SparkR就是用R语言编写Spark程序,它允许数据科学家分析 w397090770 10年前 (2015-04-14) 12909℃ 0评论17喜欢
Apache Flink 1.1.0于2016年08月08日正式发布,虽然发布了好多天了,我觉得还是有必要说说该版本的一些重大更新。Apache Flink 1.1.0是1.x.x系列版本的第一个主要版本,其API与1.0.0版本保持兼容。这就意味着你之前使用Flink 1.0.0稳定API编写的应用程序可以直接运行在Flink 1.1.0上面。本次发布共有95位贡献者参与,包括对Bug进行修复、新特 w397090770 8年前 (2016-08-18) 2081℃ 0评论0喜欢
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。 本文并不打算介绍ElasticSearch的概 w397090770 8年前 (2016-08-10) 36792℃ 2评论73喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 第四次北京Spark meeting会议 w397090770 10年前 (2014-12-16) 10337℃ 73评论8喜欢
Apache Hudi 是一种数据湖平台技术,它提供了构建和管理数据湖所需的几个功能。hudi 提供的一个关键特性是自我管理文件大小,这样用户就不需要担心手动维护表。拥有大量的小文件将使计算更难获得良好的查询性能,因为查询引擎不得不多次打开/读取/关闭文件以执行查询。但是对于流数据湖用例来说,可能每次都只会写入很少的 w397090770 3年前 (2021-08-03) 1067℃ 0评论1喜欢
我们在《Kafka创建Topic时如何将分区放置到不同的Broker中》文章中已经学习到创建 Topic 的时候分区是如何分配到各个 Broker 中的。今天我们来介绍分区分配到 Broker 中之后,会再哪个目录下创建文件夹。我们知道,在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录 w397090770 7年前 (2017-08-09) 5068℃ 0评论15喜欢
JMX(Java Management Extensions,即Java管理扩展)是一个为应用程序、设备、系统等植入管理功能的框架。JMX可以跨越一系列异构操作系统平台、系统体系结构和网络传输协议,灵活的开发无缝集成的系统、网络和服务管理应用。启动JMX监控,在启动java程序的时候最少需要在环境变量里面配置以下的选项:[code lang="bash"]-Dcom.sun.m w397090770 9年前 (2016-03-25) 6185℃ 0评论10喜欢
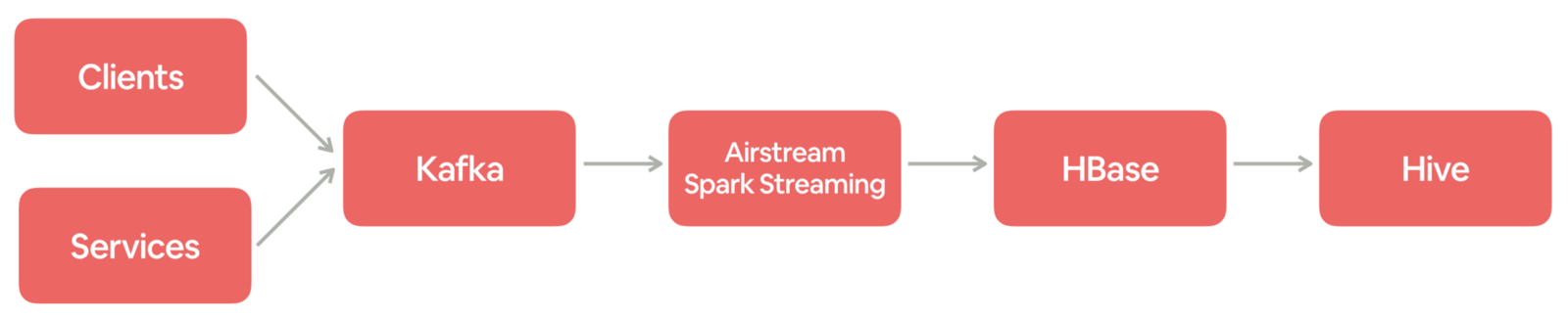
“数据智能” (Data Intelligence) 有一个必须且基础的环节,就是数据仓库的建设,同时,数据仓库也是公司数据发展到一定规模后必然会提供的一种基础服务。从智能商业的角度来讲,数据的结果代表了用户的反馈,获取结果的及时性就显得尤为重要,快速的获取数据反馈能够帮助公司更快的做出决策,更好的进行产品迭代,实时数 w397090770 6年前 (2019-02-16) 24226℃ 1评论46喜欢
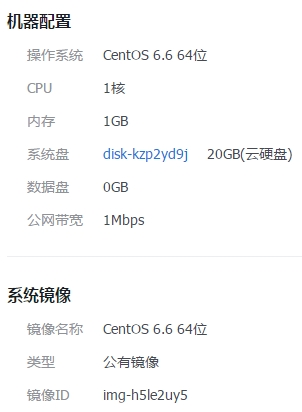
随着过往记忆大数据技术博客的浏览量逐渐增多(目前日IP达到5k+,PV达到1.5W+),博客的访问速度越来越慢,在高峰时期打开一个页面需要近10s的时间,这样的情况非常的糟糕,没多少人愿意等待近10s,所以优化网站的访问速度迫在眉睫! 先来介绍一下本博客的相关配置信息:博客购买的是腾讯云主机,CentOS 6.6 64位、1 w397090770 8年前 (2016-07-19) 1708℃ 0评论4喜欢
引言Join是SQL语句中的常用操作,良好的表结构能够将数据分散在不同的表中,使其符合某种范式,减少表冗余、更新容错等。而建立表和表之间关系的最佳方式就是Join操作。SparkSQL作为大数据领域的SQL实现,自然也对Join操作做了不少优化,今天主要看一下在SparkSQL中对于Join,常见的3种实现。Spark SQL中Join常用的实现Broadc zz~~ 7年前 (2017-07-09) 8319℃ 0评论16喜欢
这里说明一点:本文提到的解决Spark insertIntoJDBC找不到Mysql驱动的方法是针对单机模式(也就是local模式)。在集群环境下,下面的方法是不行的。这是因为在分布式环境下,加载mysql驱动包存在一个Bug,1.3及以前的版本 --jars 分发的jar在executor端是通过Spark自身特化的classloader加载的。而JDBC driver manager使用的则是系统默认的classloader w397090770 10年前 (2015-04-03) 19109℃ 3评论15喜欢