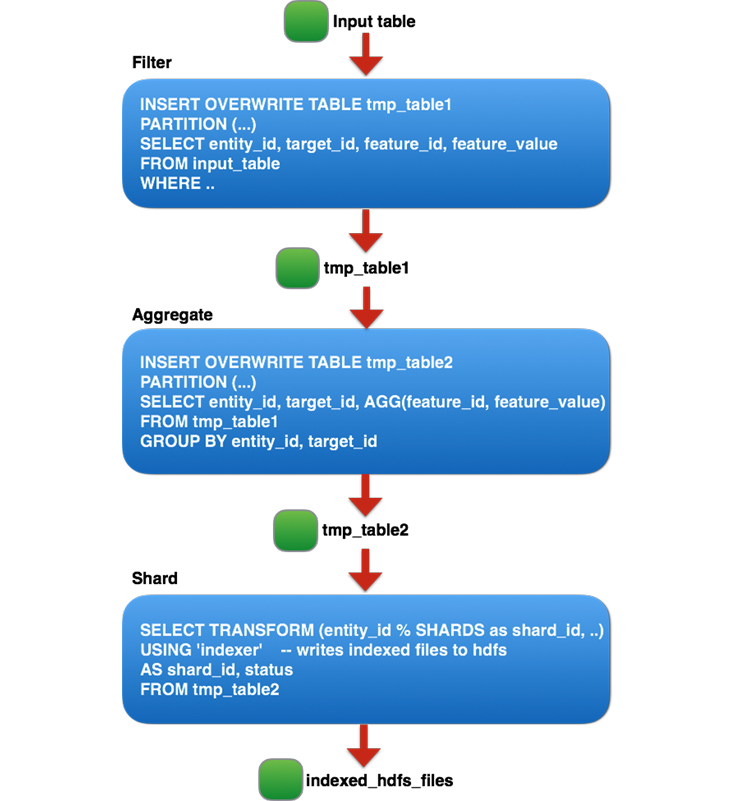
继续介绍如何在脚本中运行Scala,在前面的文章中我们只是简单地介绍了如何在脚本中使用Scala,本文将进一步地介绍。 在脚本中使用Scala最大的好处就是可以在脚本中使用Scala的所有高级特性,比如我们可以在脚本中定义和使用Scala class,如下:[code lang="scala"]#!/bin/shexec scala -savecompiled "$0" "$@"!#case c w397090770 9年前 (2015-12-15) 2659℃ 0评论5喜欢
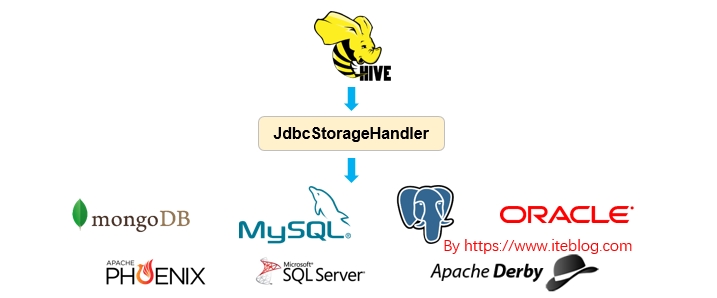
如今,很多公司可能会在内部使用多种数据存储和处理系统。这些不同的系统解决了对应的使用案例。除了传统的 RDBMS (比如 Oracle DB,Teradata或PostgreSQL) 之外,我们还会使用 Apache Kafka 来获取流和事件数据。使用 Apache Druid 处理实时系列数据(real-time series data),使用 Apache Phoenix 进行快速索引查找。 此外,我们还可能使用云存储 w397090770 6年前 (2019-03-16) 5146℃ 1评论8喜欢
4月16日在http://mirror.bit.edu.cn/apache/hive/hive-0.13.0/网址就可以下载Hive 0.13,这个版本在Hive执行速度、扩展性、SQL以及其他方面做了相当多的修改:一、执行速度 用户可以选择基于Tez的查询,基于Tez的查询可以大大提高Hive的查询速度(官网上上可以提升100倍)。下面一些技术对查询速度的提升: (1)、Broadcast Joins:和M w397090770 11年前 (2014-04-25) 8307℃ 1评论1喜欢
auto_ptr是这样一种指针:它是“它所指向的对象”的拥有者。这种拥有具有唯一性,即一个对象只能有一个拥有者,严禁一物二主。当auto_ptr指针被摧毁时,它所指向的对象也将被隐式销毁,即使程序中有异常发生,auto_ptr所指向的对象也将被销毁。设计动机在函数中通常要获得一些资源,执行完动作后,然后释放所获得的资源 w397090770 12年前 (2013-03-30) 2722℃ 0评论4喜欢
Thrift 最初由Facebook开发,目前已经开源到Apache,已广泛应用于业界。Thrift 正如其官方主页介绍的,“是一种可扩展、跨语言的服务开发框架”。简而言之,它主要用于各个服务之间的RPC通信,其服务端和客户端可以用不同的语言来开发。只需要依照IDL(Interface Description Language)定义一次接口,Thrift工具就能自动生成 C++, Java, Python, PH w397090770 3年前 (2022-03-29) 1761℃ 0评论1喜欢
Apache Spark 2.2.0 于今年7月份正式发布,这个版本是 Structured Streaming 的一个重要里程碑,因为其可以正式在生产环境中使用,实验标签(experimental tag)已经被移除; CBO (Cost-Based Optimizer)有了进一步的优化;SQL完全支持 SQL-2003 标准;R 中引入了新的分布式机器学习算法;MLlib 和 GraphX 中添加了新的算法更多详情请参见:Apa w397090770 7年前 (2017-12-13) 2664℃ 0评论19喜欢
近日,Intel开源了基于Apache Spark的分布式深度学习框架BigDL。有了BigDL之后,用户可以像编写标准的Spark程序一样来编写深度学习(deep learning)应用程序,编写完的程序还可以直接运行在现有的Spark或者Hadoop集群之上。BigDL主要有以下三大特点:[gt href="https://github.com/intel-analytics/BigDL " rel="nofollow"]BigDL GitHub地址[/gt]丰富的深度学习算法支 w397090770 8年前 (2017-01-19) 4428℃ 0评论14喜欢
在《Spark读取Hbase中的数据》文章中我介绍了如何在Spark中读取Hbase中的数据,并提供了Java和Scala两个版本的实现,本文将接着上文介绍如何通过Spark将计算好的数据存储到Hbase中。 Spark中内置提供了两个方法可以将数据写入到Hbase:(1)、saveAsHadoopDataset;(2)、saveAsNewAPIHadoopDataset,它们的官方介绍分别如下: saveAsHad w397090770 8年前 (2016-11-29) 17881℃ 1评论29喜欢
本书作者Venkat Ankam,由Packt Publishing出版社在2016年09月发行,全书供326页。本书基于Spark 2.0和Hadoop 2.7版本介绍,是适合数据分析师和数据科学家的参考手册,当然也适合那些想入门的人。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[code lang="bash"]Chapter 1: Big Data Analytics at a 10 zz~~ 8年前 (2016-11-21) 4677℃ 0评论6喜欢
《Kafka in Action》于 2022年01月由 Manning 出版, ISBN 为 9781617295232 ,全书 272 页。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop图书介绍作者有多年使用 Kafka 的真实世界的经验,这本书的实地感觉真的让它与众不同。---- From the foreword by Jun Rao, Confluent CofounderMaster the wicked-fast Apache Kafka streaming w397090770 3年前 (2022-03-02) 589℃ 0评论3喜欢
目前,Apache Kafka 使用 Apache ZooKeeper 来存储它的元数据,比如分区的位置和主题的配置等数据就是存储在 ZooKeeper 集群中。在 2019 年社区提出了一个计划,以打破这种依赖关系,并将元数据管理引入 Kafka 本身。所以 Apache Kafka 为什么要移除 Zookeeper 的依赖?Zookeeper 有什么问题?实际上,问题不在于 ZooKeeper 本身,而在于外部元数据 w397090770 4年前 (2020-05-19) 1384℃ 0评论1喜欢
本文原文:Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop Deep dive into the new Tungsten execution engine:https://databricks.com/blog/2016/05/23/apache-spark-as-a-compiler-joining-a-billion-rows-per-second-on-a-laptop.html本文已经投稿自:http://geek.csdn.net/news/detail/77005 《Spark 2.0技术预览:更容易、更快速、更智能》文中简单地介绍了Spark 2.0相关 w397090770 8年前 (2016-05-27) 6003℃ 1评论16喜欢
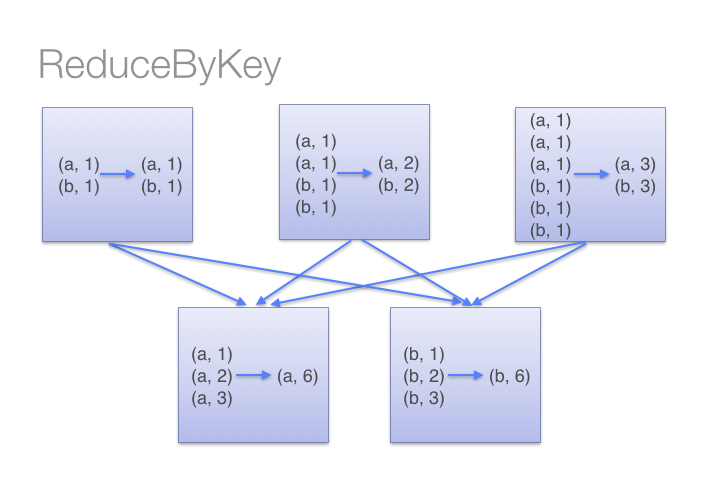
为什么建议尽量在Spark中少用GroupByKey,让我们看一下使用两种不同的方式去计算单词的个数,第一种方式使用 reduceByKey ;另外一种方式使用groupByKey,代码如下:[code lang="scala"]# User: 过往记忆# Date: 2015-05-18# Time: 下午22:26# bolg: # 本文地址:/archives/1357# 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量 w397090770 9年前 (2015-05-18) 33468℃ 0评论51喜欢
下面文档是今天早上翻译的,因为要上班,时间比较仓促,有些部分没有翻译,请见谅。2017年06月01日儿童节 Apache Flink 社区正式发布了 1.3.0 版本。此版本经历了四个月的开发,共解决了680个issues。Apache Flink 1.3.0 是 1.x.y 版本线上的第四个主要版本,其 API 和其他 1.x.y 使用 @Public 注释的API是兼容的。此外,Apache Flink 社区目前制 w397090770 7年前 (2017-06-01) 2590℃ 1评论10喜欢
一直运行的Spark Streaming程序如何关闭呢?是直接使用kill命令强制关闭吗?这种手段是可以达到关闭的目的,但是带来的后果就是可能会导致数据的丢失,因为这时候如果程序正在处理接收到的数据,但是由于接收到kill命令,那它只能停止整个程序,而那些正在处理或者还没有处理的数据可能就会被丢失。那我们咋办?这里有两 w397090770 8年前 (2017-03-01) 8857℃ 1评论11喜欢
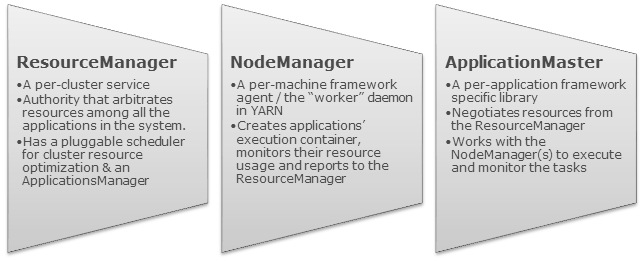
Apache YARN是将之前Hadoop 1.x的 JobTracker 功能分别拆到不同的组件里面了,每个组件分别负责不同的功能。在Hadoop 1.x中, JobTracker 负责管理集群的资源,作业调度以及作业监控;YARN把这些功能分别拆到ResourceManager 和 ApplicationMaster 中了。而之前的TaskTracker被NodeManager替代。下面分别介绍YAEN的各个组件的作用。如果想及时了解Spark、Had w397090770 7年前 (2017-06-01) 3985℃ 0评论31喜欢
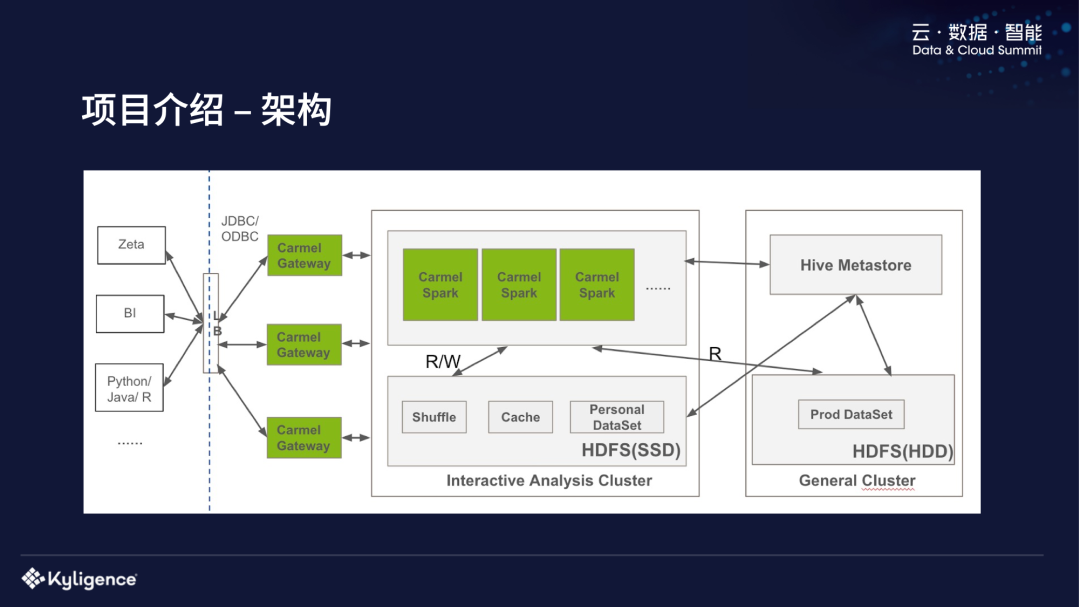
系统介绍我们这个系统的名字叫 Carmel,它是基于开源的 Hadoop 和 Spark 来替换传统的数据仓库,我们是 2019 年开始做我们这个项目的,当时是基于 Spark 2.3.1,最近刚刚升到 Spark 3.0。面临的主要技术挑战,第一个是功能方面的缺失,包括访问控制,还有一些 Update 和 Delete 的支持;在性能方面跟传统数仓,特别是交互式的分析查询中性 zz~~ 3年前 (2021-09-24) 647℃ 0评论2喜欢
本书于2017-08由Packt Publishing出版,作者Ankit Jain, 全书341页。通过本书你将学到以下知识Understand the core concepts of Apache Storm and real-time processingFollow the steps to deploy multiple nodes of Storm ClusterCreate Trident topologies to support various message-processing semanticsMake your cluster sharing effective using Storm schedulingIntegrate Apache Storm with other Big Data technolo zz~~ 7年前 (2017-08-30) 3724℃ 4评论16喜欢
Apache Gobblin 是一个用于流数据和批处理数据生态系统的分布式大数据集成框架。可以简化大数据集成里面的常见问题,比如数据摄取、复制、组织以及生命周期管理等。该项目2014年起源于 LinkedIn,2015年开源,2017年2月进入 Apache 孵化器,2021年02月16日正式毕业成为 Apache 顶级项目。如果想及时了解Spark、Hadoop或者HBase相关的文章, w397090770 3年前 (2022-01-01) 1187℃ 0评论4喜欢
MapReduce和Spark比较 目前的大数据处理可以分为以下三个类型: 1、复杂的批量数据处理(batch data processing),通常的时间跨度在数十分钟到数小时之间; 2、基于历史数据的交互式查询(interactive query),通常的时间跨度在数十秒到数分钟之间; 3、基于实时数据流的数据处理(streaming data processing),通常的时间 w397090770 9年前 (2015-05-28) 4901℃ 0评论7喜欢
Facebook 经常使用分析来进行数据驱动的决策。在过去的几年里,用户和产品都得到了增长,使得我们分析引擎中单个查询的数据量达到了数十TB。我们的一些批处理分析都是基于 Hive 平台(Apache Hive 是 Facebook 在2009年贡献给社区的)和 Corona( Facebook 内部的 MapReduce 实现)进行的。Facebook 还针对包括 Hive 在内的多个内部数据存储,继续 w397090770 5年前 (2019-12-19) 1750℃ 0评论10喜欢
Apache HBase 1.3.0于美国时间2017年01月17日正式发布。本版本是Hbase 1.x版本线的第三次小版本,大约解决了1700个issues,主要包括了大量的Bug修复和性能提升;其中以下的新特性值得关注:Date-based tiered compactions (HBASE-15181, HBASE-15339)Maven archetypes for HBase client applications (HBASE-14877)Throughput controller for flushes (HBASE-14969)Controlled delay (CoD w397090770 8年前 (2017-01-18) 3427℃ 0评论3喜欢
Apache Hadoop 3.0.0-alpha1相对于hadoop-2.x来说包含了许多重要的改进。这里介绍的是Hadoop 3.0.0的alpha版本,主要是便于检测和收集应用开发人员和其他用户的使用反馈。因为是alpha版本,所以本版本的API稳定性和质量没有保证,如果需要在正式开发中使用,请耐心等待稳定版的发布吧。本文将对Hadoop 3.0.0重要的改进进行介绍。Java最低 zz~~ 8年前 (2016-09-22) 3363℃ 0评论7喜欢
Spark 1.6.1于2016年3月11日正式发布,此版本主要是维护版本,主要涉及稳定性修复,并不涉及到大的修改。推荐所有使用1.6.0的用户升级到此版本。 Spark 1.6.1主要修复的bug包括: 1、当写入数据到含有大量分区表时出现的OOM:SPARK-12546 2、实验性Dataset API的许多bug修复:SPARK-12478, SPARK-12696, SPARK-13101, SPARK-12932 w397090770 9年前 (2016-03-11) 3892℃ 0评论5喜欢
有时候我们想对来自不同平台对同一页面的访问进行处理。比如访问 https://www.iteblog.com/test.html 页面,如果是电脑的浏览器访问,直接不处理;但是如果是手机的浏览器访问这个页面我们想跳转到其他页面去。这时候有几种方法可以实现:直接通过 JavaScript 进行处理;通过 Nginx 配置来处理如果想及时了解Spark、Hadoop或者Hbase w397090770 7年前 (2017-12-16) 1791℃ 0评论13喜欢
在介绍 HBase 是不是列式存储数据库之前,我们先来了解一下什么是行式数据库和列式数据库。行式数据库和列式数据库在维基百科里面,对行式数据库和列式数据库的定义为:列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理(OLAP)和即时查询。相对应的是行式数据库,数据以行相关的存储体 w397090770 6年前 (2019-01-08) 6332℃ 0评论31喜欢
本课程是Scala语言的入门课程,面向没有或仅有少量编程语言基础的同学,当然,具有一定的Java或C、C++语言基础将有助于本课程的学习。在本课程内,将更注重scala的各种语言规则与简单直接的应用,而不在于其是如何具体实现,通过学习本课程能具备初步的Scala语言实际编程能力。 此视频保证可以全部浏览,百度网盘 w397090770 10年前 (2015-03-21) 21924℃ 6评论46喜欢
这次整理的 PPT 来自于2018年09月03日至05日在 Berlin 进行的 flink forward 会议,这种性质的会议和大家熟知的Spark summit类似。本次会议的官方日程参见:https://berlin-2018.flink-forward.org/。本次会议共有超过350个 Flink 社区会员的人参与,因为原始的 PPT 是在 http://www.slideshare.net/ 网站,这个网站需要翻墙;为了学习交流的方便,本博客将这些 P w397090770 6年前 (2018-09-19) 2589℃ 2评论5喜欢
本文所列的 Hive 函数均为 Hive 内置的,共计294个,Hive 版本为 3.1.0。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop!! a - Logical not,和not逻辑操作符含义一致[code lang="sql"]hive> select !(true);OKfalse[/code]!=a != b - Returns TRUE if a is not equal to b,和操作符含义一致[code lang="sql"]hive> se w397090770 6年前 (2018-07-22) 9635℃ 0评论10喜欢
重庆博尼施科技有限公司是一家商用车全周期方案服务商,利用车联网、云计算、移动互联网技术,在物流领域 为商用车的生产、销售、使用、售后、回收各个环节提供一站式解决方案,其中的新能源车辆监控系统就是由该公司提供的,本文是阿里云客户重庆博尼施科技有限公司介绍如何使用阿里云 HBase 来实现新能源车辆监控系统 w397090770 6年前 (2018-11-29) 4287℃ 2评论16喜欢




![[电子书]Big Data Analytics pdf下载](https://www.iteblog.com/pic/big-data-analytics-iteblog.jpg)





![[电子书]Mastering Apache Storm PDF下载](https://www.iteblog.com/pic/books/Mastering_Apache_Storm_iteblog.png)