在Flink中有许多函数需要我们为其指定key,比如groupBy,Join中的where等。如果我们指定的Key不对,可能会出现一些问题,正如下面的程序:[code lang="scala"]package com.iteblog.flinkimport org.apache.flink.api.scala.{ExecutionEnvironment, _}import org.apache.flink.util.Collector///////////////////////////////////////////////////////////////////// User: 过往记忆 Date: 2017 w397090770 8年前 (2017-03-13) 16845℃ 9评论15喜欢
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Tencent at Scale Usability Extension Stability Improvement》,分享者Junyi Huang 和 Pan Liu,均为腾讯软件工程师。Presto 已被腾讯采用为不同业务部门提供临时查询和交互式查询场景。在这次演讲中,作者将分享腾讯在生产中关于 Presto 的实践。关注 过往记忆大数据公众 w397090770 3年前 (2021-12-19) 724℃ 0评论0喜欢
在MapReduce作业中的数据输入和输出必须使用到相关的InputFormat和OutputFormat类,来指定输入数据的格式,InputFormat类的功能是为map任务分割输入的数据。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop InputFormat类中必须指定Map输入参数Key和Value的数据类型,以及对输入的数据如何进行分 w397090770 9年前 (2015-07-11) 5506℃ 0评论14喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第三篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 8年前 (2016-08-17) 3685℃ 0评论3喜欢
C++允许为模板类中的类型参数指定为一个迷人类型,例如:我们可以将int赋予通用类Stack中的类型参数T,作为默认类型,如下所示:[code lang="CPP"]templateclass Stack{//other operator};[/code]现在我们就可以像如下代码一样使用默认类型来声明模板类对象了:[code lang="CPP"]Stack<> stack; //store int value[/code]但是需要注意 w397090770 12年前 (2013-04-04) 4187℃ 1评论0喜欢
在 LinkedIn,我们使用 Hadoop 作为大数据分析和机器学习的基础组件。随着数据量呈指数级增长,并且公司在机器学习和数据科学方面进行了大量投资,我们的集群规模每年都在翻倍,以匹配计算工作负载的增长。我们最大的集群现在有大约 10,000 个节点,是全球最大(如果不是最大的)Hadoop 集群之一。多年来,扩展 Hadoop YARN 已成为 w397090770 3年前 (2021-09-18) 536℃ 0评论4喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-19) 7357℃ 6评论10喜欢
2017年04月25日发布的nginx 1.13.0支持了TLSv1.3,而TLSv1.3相比之前的TLSv1.2、TLSv1.1等性能大幅提升。所以我迫不及待地将nginx升级到最新版1.13.0。下面记录如何升级nginx,本文基于CentOS release 6.6,其他的操作系统略有不同。如果你不知道你的系统是啥版本,可以通过下面的几个命令查询[code lang="bash"][root@iteblog.com ~]$ cat /etc/issueCentOS w397090770 7年前 (2017-05-23) 12338℃ 2评论10喜欢
建议用Spark 1.3.0提供的写关系型数据库的方法,参见《Spark RDD写入RMDB(Mysql)方法二》。 在《Spark与Mysql(JdbcRDD)整合开发》文章中我们介绍了如何通过Spark读取Mysql中的数据,当时写那篇文章的时候,Spark还未提供通过Java来使用JdbcRDD的API,不过目前的Spark提供了Java使用JdbcRDD的API。 今天主要来谈谈如果将Spark计算的结果 w397090770 10年前 (2015-03-10) 36908℃ 5评论33喜欢
将于2016年6月5日星期天下午1:30在杭州市西湖区教工路88号立元大厦3楼沃创空间沃创咖啡进行,本次场地由挖财公司提供。分享主题1. 陈超, 七牛:《Spark 2.0介绍》(13:30 ~ 14:10)2. 雷宗雄, 花名念钧:《spark mllib大数据实践和优化》(14:10 ~ 14:50)3. 陈亮,华为:《Spark+CarbonData(New File Format For Faster Data Analysis)》(15:10 ~ 15:50)4 w397090770 8年前 (2016-05-13) 2085℃ 0评论3喜欢
桔妹导读:在滴滴SQL任务从Hive迁移到Spark后,Spark SQL任务占比提升至85%,任务运行时间节省40%,运行任务需要的计算资源节省21%,内存资源节省49%。在迁移过程中我们沉淀出一套迁移流程, 并且发现并解决了两个引擎在语法,UDF,性能和功能方面的差异。迁移背景Spark自从2010年面世,到2020年已经经过十年的发展,现在已经发展 w397090770 4年前 (2021-01-28) 2496℃ 0评论10喜欢
本文来自 submarine 团队投稿。作者: Wangda Tan & Sunil Govindan & Zhankun Tang(这篇博文由网易的刘勋和周全协助编写)。原文地址:https://hortonworks.com/blog/submarine-running-deep-learning-workloads-apache-hadoop/介绍Hadoop 是用于大型企业数据集的分布式处理的最流行的开源框架,它在本地和云端环境中都有很多重要用途。深度学习对于语 w397090770 6年前 (2019-01-01) 4027℃ 0评论4喜欢
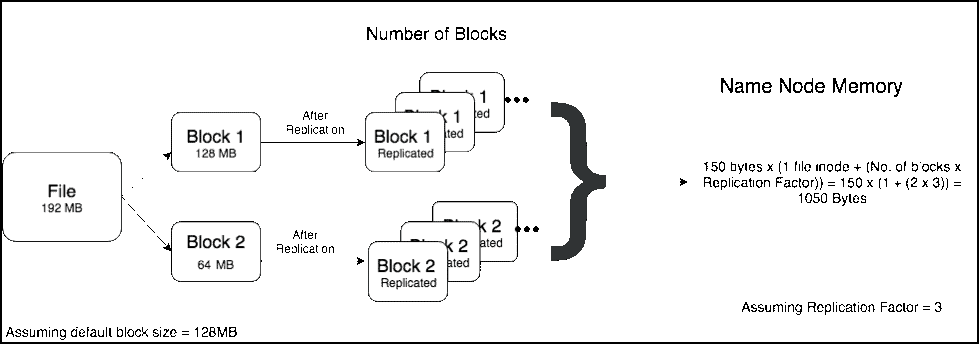
在使用Hadoop过程中,小文件是一种比较常见的挑战,如果不小心处理,可能会带来一系列的问题。HDFS是为了存储和处理大数据集(M以上)而开发的,大量小文件会导致Namenode内存利用率和RPC调用效率低下,block扫描吞吐量下降,应用层性能降低。通过本文,我们将定义小文件存储的问题,并探讨如何对小文件进行治理。什么是小 w397090770 4年前 (2021-02-24) 1042℃ 0评论6喜欢
本文仅仅是简单地介绍如何在Ubuntu/Debian系统上安装Node.js(任何版本)和npm(Node Package Manager的简写),其他类Linux系统安装步骤和这个类似。 一、更新你的系统[code lang="bash"]iteblog# sudo apt-get updateiteblog# sudo apt-get install git-core curl build-essential openssl libssl-dev[/code] 二、安装Node.js 首先我们先从github上将Node w397090770 10年前 (2015-04-11) 27759℃ 0评论22喜欢
Few months ago, I introduced a simple algorithm that allow users to implement their own short URL into their system. Today, I have some spare time so I decided to write the short URL algorithm's implementation in PHP.At first, we define a function called shorturl() that receives a URL as the input and returns an array that contains 4 hashed values (each 6 characters).[php]function shorturl($input) { ... // return array of w397090770 12年前 (2013-04-14) 3837℃ 0评论1喜欢
和Java一样,我们也可以使用Scala来创建Web工程,这里使用的是Scalatra,它是一款轻量级的Scala web框架,和Ruby Sinatra功能类似。比较推荐的创建Scalatra工程是使用Giter8,他是一款很不错的用于创建SBT工程的工具。所以我们需要在电脑上面安装好Giter8。这里以Centos系统为例进行介绍。安装giter8 在安装giter8之前需要安装Conscrip w397090770 9年前 (2015-12-18) 5785℃ 0评论10喜欢
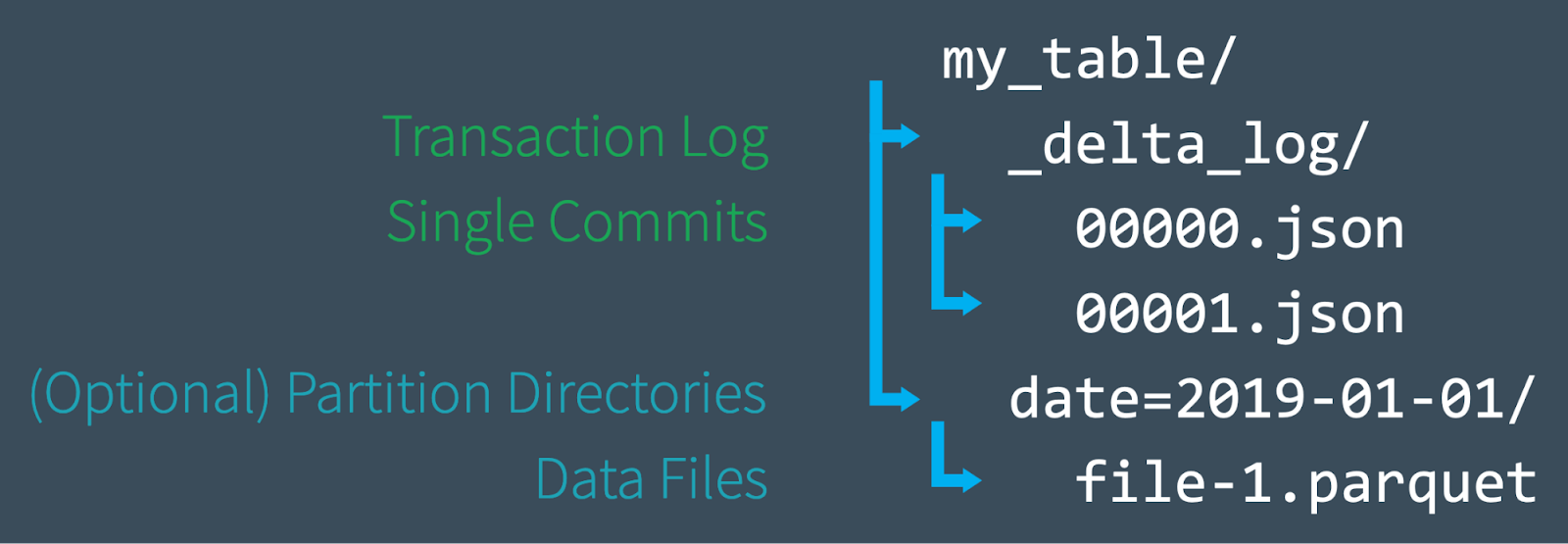
Delta Lake 支持 DML 命令,包括 DELETE, UPDATE, 以及 MERGE,这些命令简化了 CDC、审计、治理以及 GDPR/CCPA 工作流等业务场景。在这篇文章中,我们将演示如何使用这些 DML 命令,并会介绍这些命令的后背实现,同时也会介绍对应命令的一些性能调优技巧。Delta Lake: 基本原理如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 w397090770 4年前 (2020-10-12) 1438℃ 0评论0喜欢
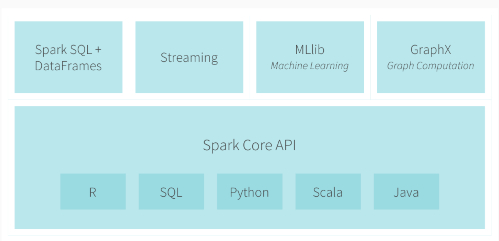
现在Apache Spark已形成一个丰富的生态系统,包括官方的和第三方开发的组件或工具。后面主要给出5个使用广泛的第三方项目。Spark官方构建了一个非常紧凑的生态系统组件,提供各种处理能力。 下面是Spark官方给出的生态系统组件 1、Spark DataFrames:列式存储的分布式数据组织,类似于关系型数据表。 2、Spark SQL:可 w397090770 9年前 (2016-03-08) 4939℃ 2评论7喜欢
Hive 设计之初,就被定位一款离线数仓产品,虽然Hortonworks喊出了Make Apache Hive 100x Faster的牛逼口号,也在上面做了大量的优化,然而性能提升依旧不大。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆而随着OPPO数据量一步步的增多,动辄运行几个小时的hive再也满足不了交互查询的需求,因此我们 w397090770 4年前 (2021-03-05) 989℃ 0评论6喜欢
Efficient processing of big data, especially with Spark, is really all about how much memory one can afford, or how efficient use one can make of the limited amount of available memory. Efficient memory utilization, however, is not what one can take for granted with default configuration shipped with Spark and Yarn. Rather, it takes very careful provisioning and tuning to get as much as possible from the bare metal. In this post I’ll w397090770 4年前 (2020-09-09) 962℃ 0评论0喜欢
以下的话是由Apache Spark committer的Reynold Xin阐述。 从很多方面来讲,Spark都是MapReduce 模式的最好实现。比如从程序抽象的角度来看: 1、他抽象出Map/Reduce两个阶段来支持tasks的任意DAG。大多数计算通过依赖将maps和reduces映射到一起(Most computation maps (no pun intended) into many maps and reduces with dependencies among them. )。而在Spark的RDD w397090770 10年前 (2015-03-09) 8073℃ 0评论9喜欢
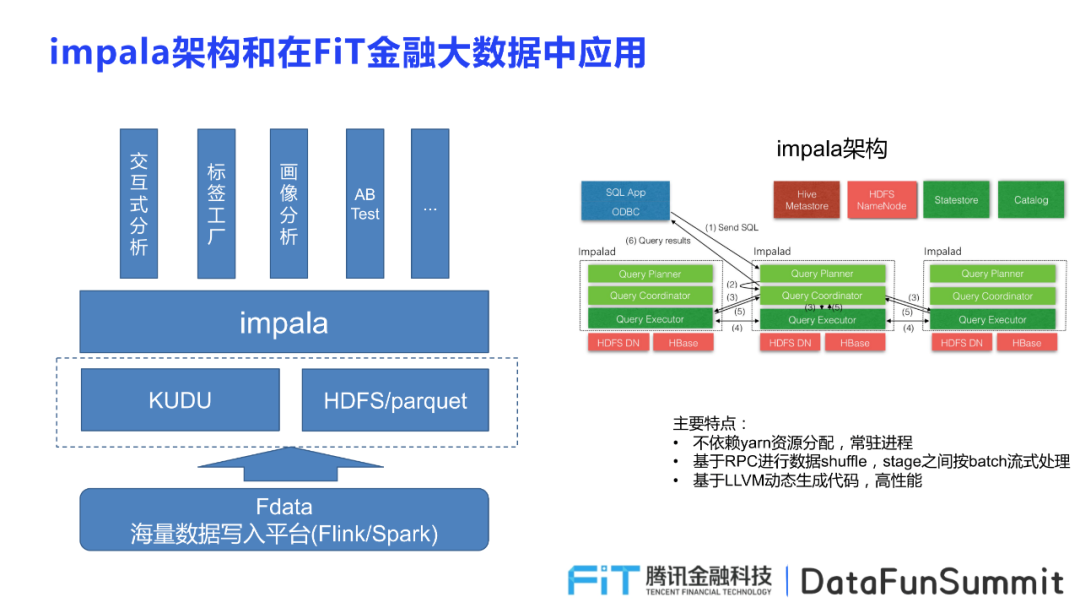
导读:在腾讯金融场景,我们每天都会产生大量的数据,为了提升分析的交互性,让决策更加敏捷,我们引入了Impala来解决我们的分析需求。所以,本文将和大家分享Impala在腾讯金融大数据场景中的应用架构,Impala的原理,落地过程的案例和优化以及总结思考。Impala的架构 首先介绍Impala的整体架构,帮助大家从宏观角度理 w397090770 3年前 (2021-10-28) 389℃ 0评论1喜欢
在前面的《Guava学习之Multimap》文章中我们谈到了Guava类库中的Multimap,其特点是存在在Multimap中的键值对可以不唯一;而我们又知道,在Java集合类库中有个Map,它的特点是存放的键(Key)是唯一的,而值(Value)可以不唯一,如果我们需要键(Key)和值(Value)都唯一,该怎么实现?这就是今天要谈的BiMap结构。 在过去,如 w397090770 11年前 (2013-07-10) 7176℃ 2评论2喜欢
根据官方文档,Spark可以用Maven进行编译,但是我试了好几个版本都编译不通过,所以没用(如果大家用Maven编译通过了Spark,求分享。)。这里是利用sbt对Spark进行编译。中间虽然也遇到了很多问题,但是经过几天的折腾,终于通过了,关于如何解决编译中间出现的问题,可以参见本博客的《Spark源码编译遇到的问题解决》进行 w397090770 11年前 (2014-04-18) 11058℃ 3评论7喜欢
将RDD转成Scala数组,并返回。函数原型[code lang="scala"]def collect(): Array[T]def collect[U: ClassTag](f: PartialFunction[T, U]): RDD[U][/code] collect函数的定义有两种,我们最常用的是第一个。第二个函数需要我们提供一个标准的偏函数,然后保存符合的元素到MappedRDD中。实例[code lang="scala"]/** * User: 过往记忆 * Date: 15-03-11 * Ti w397090770 10年前 (2015-03-11) 29834℃ 0评论22喜欢
我们在使用HDFS Shell的时候只用最频繁的命令可能就是 ls 了,其具体含义我就不介绍了。在使用 ls 的命令时,我们可能想对展示出来的文件按照修改时间排序,也就是最近修改的文件(most recent)显示在最前面。如果你使用的是Hadoop 2.8.0以下版本,内置是不支持按照时间等属性排序的。不过值得高兴的是,我们可以结合Shell命令来 w397090770 8年前 (2017-02-18) 12517℃ 0评论9喜欢
本书作者:Hari Shreedharan,由O'Reilly Media出版社于2014年09月出版,全书共238页。 如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[code lang="bash"]Chapter 1: Apache Hadoop and Apache HBase:An IntroductionChapter 2: Streaming Data Using Apache FlumeChapter 3:SourcesChapter 4: ChannelsChapter 5: SinksChapter 6: Inter w397090770 9年前 (2015-08-25) 4173℃ 0评论8喜欢
课程讲师:Cloudy 课程分类:Java 适合人群:初级 课时数量:8课时 用到技术:Zookeeper、Web界面监控 涉及项目:案例实战 此视频百度网盘免费下载。本站所有下载资源收集于网络,只做学习和交流使用,版权归原作者所有,若为付费视频,请在下载后24小时之内自觉删除,若作商业用途,请购 w397090770 10年前 (2015-04-18) 34785℃ 2评论57喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 10年前 (2015-03-30) 4843℃ 0评论4喜欢
在实践经验中,我们知道数据总是在不断演变和增长,我们对于这个世界的心智模型必须要适应新的数据,甚至要应对我们从前未知的知识维度。表的 schema 其实和这种心智模型并没什么不同,需要定义如何对新的信息进行分类和处理。这就涉及到 schema 管理的问题,随着业务问题和需求的不断演进,数据结构也会不断发生变化。 w397090770 4年前 (2020-09-12) 579℃ 0评论0喜欢