导读:OPPO是一家智能终端制造公司,有着数亿的终端用户,手机 、IoT设备产生的数据源源不断,设备的智能化服务需要我们对这些数据做更深层次的挖掘。海量的数据如何低成本存储、高效利用是大数据部门必须要解决的问题。目前业界流行的解决方案是数据湖,本次Xiaochun He老师介绍的OPPO自研数据湖存储系统CBFS在很大程度上可 zz~~ 3年前 (2021-09-24) 420℃ 0评论2喜欢
和Java一样,我们也可以使用Scala来创建Web工程,这里使用的是Scalatra,它是一款轻量级的Scala web框架,和Ruby Sinatra功能类似。比较推荐的创建Scalatra工程是使用Giter8,他是一款很不错的用于创建SBT工程的工具。所以我们需要在电脑上面安装好Giter8。这里以Centos系统为例进行介绍。安装giter8 在安装giter8之前需要安装Conscrip w397090770 9年前 (2015-12-18) 5785℃ 0评论10喜欢
Spark Summit 2016 Europe会议于2016年10月25日至10月27日在布鲁塞尔进行。本次会议有上百位Speaker,来自业界顶级的公司。官方日程:https://spark-summit.org/eu-2016/schedule/。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料 w397090770 8年前 (2016-11-06) 3065℃ 0评论1喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-10-10) 163679℃ 11评论384喜欢
这本书2015年06月出版,完整版共340页,这里提供的只是预览版,只有第一章【19页】 w397090770 9年前 (2015-08-15) 4019℃ 2评论6喜欢
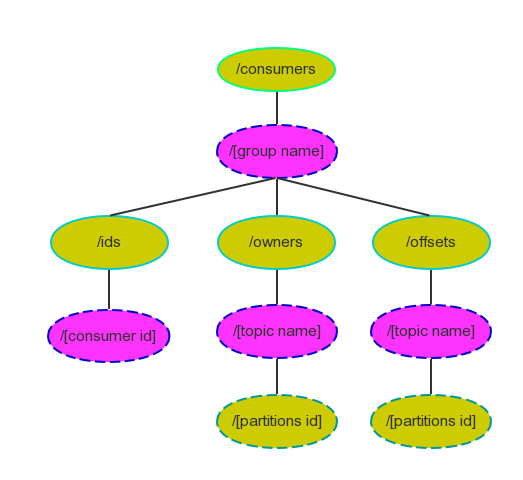
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》High Level Consumer 很多时候,客户程序只是希望从Kafka读取数据,不太关心消息offset的处理。同时也希望提供一些语义,例如同 w397090770 9年前 (2015-09-08) 9635℃ 0评论22喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-07-15) 92406℃ 0评论164喜欢
在 Apache Iceberg 中有很多种方式可以来创建表,其中就包括使用 Catalog 方式或者实现 org.apache.iceberg.Tables 接口。下面我们来简单介绍如何使用。.如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop使用 Hive catalog从名字就可以看出,Hive catalog 是通过连接 Hive 的 MetaStore,把 Iceberg 的表存储到其中,它 w397090770 4年前 (2020-11-08) 2301℃ 0评论5喜欢
我在前面的文章介绍了MapReduce中两种全排序的方法及其实现。但是上面的两种方法都是有很大的局限性:方法一在数据量很大的时候会出现OOM问题;方法二虽然能够将数据分散到多个Reduce中,但是问题也很明显:我们必须手动地找到各个Reduce的分界点,尽量使得分散到每个Reduce的数据量均衡。而且每次修改Reduce的个数时,都得 w397090770 7年前 (2017-05-12) 7269℃ 14评论20喜欢
为帮助开发者更深入的了解这三个大数据开源技术及其实际应用场景,9月8日,InfoQ联合华为云举办了一场实时大数据Meetup,集结了来自Databricks、华为及美团点评的大咖级嘉宾前来分享。作为Spark Structured Streaming最核心的开发人员、Databricks工程师,Tathagata Das(以下简称“TD”)在开场演讲中介绍了Structured Streaming的基本概念 w397090770 6年前 (2018-09-21) 4802℃ 0评论10喜欢
求解问题如下:在本地磁盘里面有file1和file2两个文件,每一个文件包含500万条随机整数(可以重复),最大不超过2147483648也就是一个int表示范围。要求写程序将两个文件中都含有的整数输出到一个新文件中。要求: 程序的运行时间不超过5秒钟。 没有内存泄漏。 代码规范,能要考虑到出错情况。 代码具有高度可重用性 w397090770 12年前 (2013-04-03) 6912℃ 3评论5喜欢
下面的操作会影响到Spark输出RDD分区(partitioner)的: cogroup, groupWith, join, leftOuterJoin, rightOuterJoin, groupByKey, reduceByKey, combineByKey, partitionBy, sort, mapValues (如果父RDD存在partitioner), flatMapValues(如果父RDD存在partitioner), 和 filter (如果父RDD存在partitioner)。其他的transform操作不会影响到输出RDD的partitioner,一般来说是None,也就是没 w397090770 10年前 (2014-12-29) 16575℃ 0评论5喜欢
Apache HBase 1.3.0于美国时间2017年01月17日正式发布。本版本是Hbase 1.x版本线的第三次小版本,大约解决了1700个issues,主要包括了大量的Bug修复和性能提升;其中以下的新特性值得关注:Date-based tiered compactions (HBASE-15181, HBASE-15339)Maven archetypes for HBase client applications (HBASE-14877)Throughput controller for flushes (HBASE-14969)Controlled delay (CoD w397090770 8年前 (2017-01-18) 3427℃ 0评论3喜欢
Apache Hadoop 2.5.2于2014年11月19日发布,该版本是2.5.x的分支,主要修复了2.5.0之后的一些关键bug: HADOOP-11243. SSLFactory shouldn't allow SSLv3. (Wei Yan via kasha) HADOOP-11260. Patch up Jetty to disable SSLv3. (Mike Yoder via kasha) HADOOP-11307. create-release script should run git clean first. (kasha) 下面是2.5.2中功能提升的简单概述:Common 1、 HTTP w397090770 10年前 (2014-11-24) 5402℃ 1评论5喜欢
Git 的代码回滚主要有 reset 和 revert,本文介绍其用法如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopreset一般用法是 [code lang="bash"]git reset --hard commit_id[/code]其中 commit_id 是使用 git log 查看的 id,如下:[code lang="bash"]$ git logcommit 26721c73c6bb82c8a49aa94ce06024f592032d0cAuthor: iteblog <iteblog@iteb w397090770 4年前 (2020-10-12) 1269℃ 0评论0喜欢
PrestoCon 2021 于2021年12月09日通过在线的形式举办完了。在 PrestoCon,来自行业领先公司的用户分享了一些用例和最佳实践,Presto 开发人员讨论项目的特性;用户和开发人员将合作推进 Presto 的使用,将其作为一种高质量、高性能和可靠的软件,用于支持全球组织的分析平台,无论是在本地还是在云端。本次会议大概有20多个议题,干货 w397090770 3年前 (2021-12-19) 314℃ 0评论2喜欢
本文将介绍如何通过Flink读取Kafka中Topic的数据。 和Spark一样,Flink内置提供了读/写Kafka Topic的Kafka连接器(Kafka Connectors)。Flink Kafka Consumer和Flink的Checkpint机制进行了整合,以此提供了exactly-once处理语义。为了实现这个语义,Flink不仅仅依赖于追踪Kafka的消费者group偏移量,而且将这些偏移量存储在其内部用于追踪。 和Sp w397090770 9年前 (2016-05-03) 23935℃ 1评论23喜欢
在Linux C网络编程中,一共有两种方法来关闭一个已经连接好的网络通信,它们就是close函数和shutdown函数,它们的函数原型分别为:[code lang="CPP"]#include<unistd.h>int close(int sockfd)//返回:0——成功, 1——失败#include<sys/socket.h>int shutdown(int sockfd, int howto)//返回:0——成功, 1——失败[/code]close函数和shutdown函数 w397090770 12年前 (2013-04-04) 5562℃ 0评论2喜欢
静态分区裁剪(Static Partition Pruning)用过 Spark 的同学都知道,Spark SQL 在查询的时候支持分区裁剪,比如我们如果有以下的查询:[code lang="sql"]SELECT * FROM Sales_iteblog WHERE day_of_week = 'Mon'[/code]Spark 会自动进行以下的优化:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop从上图可以看到,S w397090770 5年前 (2019-11-04) 2629℃ 0评论6喜欢
在Flink中有许多函数需要我们为其指定key,比如groupBy,Join中的where等。如果我们指定的Key不对,可能会出现一些问题,正如下面的程序:[code lang="scala"]package com.iteblog.flinkimport org.apache.flink.api.scala.{ExecutionEnvironment, _}import org.apache.flink.util.Collector///////////////////////////////////////////////////////////////////// User: 过往记忆 Date: 2017 w397090770 8年前 (2017-03-13) 16845℃ 9评论15喜欢
在Scala中存在case class,它其实就是一个普通的class。但是它又和普通的class略有区别,如下:1、初始化的时候可以不用new,当然你也可以加上,普通类一定需要加new;[code lang="scala"]scala> case class Iteblog(name:String)defined class Iteblogscala> val iteblog = Iteblog("iteblog_hadoop")iteblog: Iteblog = Iteblog(iteblog_hadoop)scala> val iteblog w397090770 9年前 (2015-09-18) 38514℃ 1评论71喜欢
Spark Release 1.0.2于2014年8月5日发布,Spark 1.0.2 is a maintenance release with bug fixes. This release is based on the branch-1.0 maintenance branch of Spark. We recommend all 1.0.x users to upgrade to this stable release. Contributions to this release came from 30 developers.如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopYou can download Spark 1.0.2 as w397090770 10年前 (2014-08-06) 5817℃ 2评论4喜欢
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》shuffle调优调优概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。因此,如果要让作业的性能更上一层楼,就有必要对sh w397090770 8年前 (2016-05-15) 22506℃ 2评论52喜欢
第十四次Shanghai Apache Spark Meetup聚会,由中国平安银行大力支持。活动将于2017年12月23日12:30~17:00在上海浦东新区上海海神诺富特酒店三楼麦哲伦厅举行。举办地点交通方便,靠近地铁4号线浦东大道站。座位有限,先到先得。大会主题《Spark在金融领域的算法实践》(13:20 – 14:05)演讲嘉宾:潘鹏举,平安银行大数据平台架构师 zz~~ 7年前 (2017-12-06) 2020℃ 0评论11喜欢
历时一个多月的投票和补丁修复,Apache Spark 1.6.0于今天凌晨正式发布。Spark 1.6.0是1.x线上第七个发行版.本发行版有来自248+的贡献者参与。详细邮件如下:Hi All,Spark 1.6.0 is the seventh release on the 1.x line. This release includes patches from 248+ contributors! To download Spark 1.6.0 visit the downloads page. (It may take a while for all mirrors to update.)A huge t w397090770 9年前 (2016-01-05) 2971℃ 1评论5喜欢
今天我将介绍如何在Java工程使用Scala代码。对于那些想在真实场景中尝试使用Scala的开发人员来说,会非常有意思。这和你项目中有什么类型的东西毫无关系:不管是Spring还是Spark还是别的。我们废话少说,开始吧。抽象Java Maven项工程 这里我们使用Maven来管理我们的Java项目,项目的结果如下所示:如果想及时了解Spa w397090770 8年前 (2017-01-01) 9841℃ 0评论24喜欢
我们在《Tachyon 0.7.0伪分布式集群安装与测试》文章中介绍了如何搭建伪分布式Tachyon集群。从官方文档得知,Spark 1.4.x和Tachyon 0.6.4版本兼容,而最新版的Tachyon 0.7.1和Spark 1.5.x兼容,目前最新版的Spark为1.4.1,所以下面的操作步骤全部是基于Tachyon 0.6.4平台的,Tachyon 0.6.4的搭建步骤和Tachyon 0.7.0类似。 废话不多说,开始介绍吧 w397090770 9年前 (2015-08-31) 5473℃ 0评论6喜欢
1、新增"Explain dependency"语法,以json格式输出执行语句会读取的input table和input partition信息,这样debug语句会读取哪些表就很方便了[code lang="JAVA"]hive> explain dependency select count(1) from p;OK{"input_partitions":[{"partitionName":"default@p@stat_date=20110728/province=bj"},{"partitionName":"default@p@stat_date=20110728/provinc w397090770 11年前 (2013-11-04) 7532℃ 2评论4喜欢
我目前使用的Hive版本是apache-hive-1.2.0-bin,每次在使用 show create table 语句的时候如果你字段中有中文注释,那么Hive得出来的结果如下:hive> show create table iteblog;OKCREATE TABLE `iteblog`( `id` bigint COMMENT '�id', `uid` bigint COMMENT '(7id', `name` string COMMENT '(7�')ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTF w397090770 8年前 (2016-06-08) 11284℃ 0评论13喜欢
继续介绍如何在脚本中运行Scala,在前面的文章中我们只是简单地介绍了如何在脚本中使用Scala,本文将进一步地介绍。 在脚本中使用Scala最大的好处就是可以在脚本中使用Scala的所有高级特性,比如我们可以在脚本中定义和使用Scala class,如下:[code lang="scala"]#!/bin/shexec scala -savecompiled "$0" "$@"!#case c w397090770 9年前 (2015-12-15) 2659℃ 0评论5喜欢

![Spark Summit 2016 Europe全部PPT下载[共75个]](https://www.iteblog.com/pic/iteblog.png)
![Hadoop Security Protecting Your Big Data Platform[PDF]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/1.jpg)