Flink China社区线下 Meetup·北京站会议于 2018年8月11日 在朝阳区酒仙桥北路恒通国际创新园进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动议程13:40-13:50 莫问 出品人开场发言13:50-14:30 Flink Committer星罡《Flink状态管理和恢复技术介绍》,详细请见这里14:30-15:10 滴滴 余海琳《Flink在 zz~~ 6年前 (2018-08-14) 2953℃ 0评论4喜欢
2020年6月4日,马萨诸塞州韦克菲尔德(Wakefield, MA)—— Apache 软件基金会(ASF),超过350个开源项目和计划的全志愿者开发人员、管理人员和孵化器,正式宣布 Apache Hudi 成为顶级项目(Top-Level Project 、TLP)。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Hudi (Hadoop Upserts delete and Incrementa w397090770 4年前 (2020-06-04) 1217℃ 0评论5喜欢
本文来自 submarine 团队投稿。作者: Wangda Tan & Sunil Govindan & Zhankun Tang(这篇博文由网易的刘勋和周全协助编写)。原文地址:https://hortonworks.com/blog/submarine-running-deep-learning-workloads-apache-hadoop/介绍Hadoop 是用于大型企业数据集的分布式处理的最流行的开源框架,它在本地和云端环境中都有很多重要用途。深度学习对于语 w397090770 6年前 (2019-01-01) 4027℃ 0评论4喜欢
在Spark 1.x版本,我们收到了很多询问SparkContext, SQLContext和HiveContext之间关系的问题。当人们想使用DataFrame API的时候把HiveContext当做切入点的确有点奇怪。在Spark 2.0,引入了SparkSession,作为一个新的切入点并且包含了SQLContext和HiveContext的功能。为了向后兼容,SQLContext和HiveContext被保存下来。SparkSession拥有许多特性,下面将展示SparkS w397090770 8年前 (2016-05-26) 14024℃ 0评论13喜欢
今天谈谈Guava类库中的Multisets数据结构,虽然它不怎么经常用,但是还是有必要对它进行探讨。我们知道Java类库中的Set不能存放相同的元素,且里面的元素是无顺序的;而List是能存放相同的元素,而且是有顺序的。而今天要谈的Multisets是能存放相同的元素,但是元素之间的顺序是无序的。从这里也可以看出,Multisets肯定不是实 w397090770 11年前 (2013-07-11) 4670℃ 0评论1喜欢
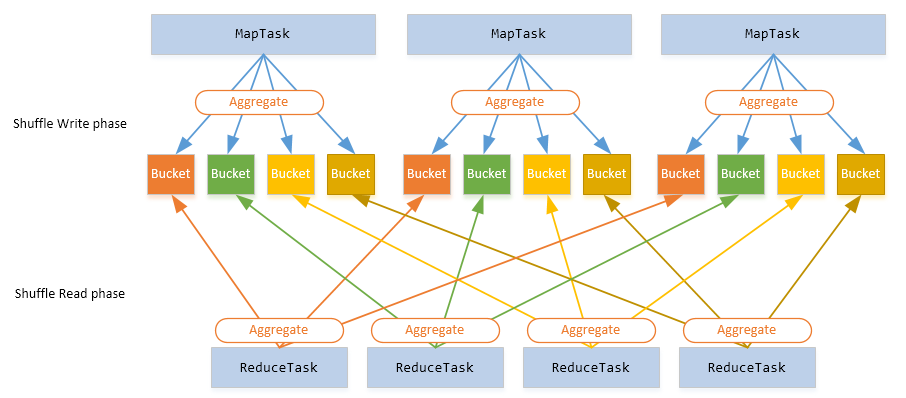
Spark Shuffle 基础在 MapReduce 框架中,Shuffle 是连接 Map 和 Reduce 之间的桥梁,Reduce 要读取到 Map 的输出必须要经过 Shuffle 这个环节;而 Reduce 和 Map 过程通常不在一台节点,这意味着 Shuffle 阶段通常需要跨网络以及一些磁盘的读写操作,因此 Shuffle 的性能高低直接影响了整个程序的性能和吞吐量。与 MapReduce 计算框架一样,Spark 作 w397090770 7年前 (2017-11-15) 7464℃ 3评论30喜欢
这是Spark北京Meetup第四次活动,主要是SparkSQL专题。可以在这里报名,活动免费。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动时间 12月13日下午14:00活动地点 地址:淀区中关村软件园二期,西北旺东路10号院东区,亚信大厦 一层会议室 时间:13:20-13:40活动内容: w397090770 10年前 (2014-12-02) 4979℃ 0评论3喜欢
对RDD中的分区重新进行合并。函数原型[code lang="scala"]def coalesce(numPartitions: Int, shuffle: Boolean = false) (implicit ord: Ordering[T] = null): RDD[T][/code] 返回一个新的RDD,且该RDD的分区个数等于numPartitions个数。如果shuffle设置为true,则会进行shuffle。实例[code lang="scala"]/** * User: 过往记忆 * Date: 15-03-09 * Time: 上午0 w397090770 10年前 (2015-03-09) 14239℃ 1评论5喜欢
本文已经不再更新,谢谢支持。本页面长期更新最新 Google、谷歌学术、维基百科、ccFox.info、ProjectH、3DM、Battle.NET 、WordPress、Microsoft Live、GitHub、Box.com、SoundCloud、inoreader、Feedly、FlipBoard、Twitter、Facebook、Flickr、imgur、DuckDuckGo、Ixquick、Google Services、Google apis、Android、Youtube、Google Drive、UpLoad、Appspot、Googl eusercontent、Gstatic、Google othe w397090770 5年前 (2019-11-19) 1090℃ 0评论3喜欢
本书是《Hadoop权威指南》第三版,新版新特色,内容更详细。本书是为程序员写的,可帮助他们分析任何大小的数据集。本书同时也是为管理员写的,帮助他们了解如何设置和运行Hadoop集群。 本书通过丰富的案例学习来解释Hadoop的幕后机理,阐述了Hadoop如何解决现实生活中的具体问题。第3版覆盖Hadoop的新动态,包括新增 zz~~ 8年前 (2016-12-16) 17234℃ 0评论43喜欢
最近在Yarn上使用Spark,不管是yarn-cluster模式还是yarn-client模式,都出现了以下的异常:[code lang="java"]Application application_1434099279301_123706 failed 2 times due to AM Container for appattempt_1434099279301_123706_000002 exited with exitCode: 127 due to: Exception from container-launch:org.apache.hadoop.util.Shell$ExitCodeException:at org.apache.hadoop.util.Shell.runCommand(Shell.java:464) w397090770 9年前 (2015-06-19) 7858℃ 0评论3喜欢
Spark支持读取很多格式的文件,其中包括了所有继承了Hadoop的InputFormat类的输入文件,以及平时我们常用的Text、Json、CSV (Comma Separated Values) 以及TSV (Tab Separated Values)文件。本文主要介绍如何通过Spark来读取Json文件。很多人会说,直接用Spark SQL模块的jsonFile方法不就可以读取解析Json文件吗?是的,没错,我们是可以通过那个读取Json w397090770 10年前 (2015-01-06) 26936℃ 10评论15喜欢
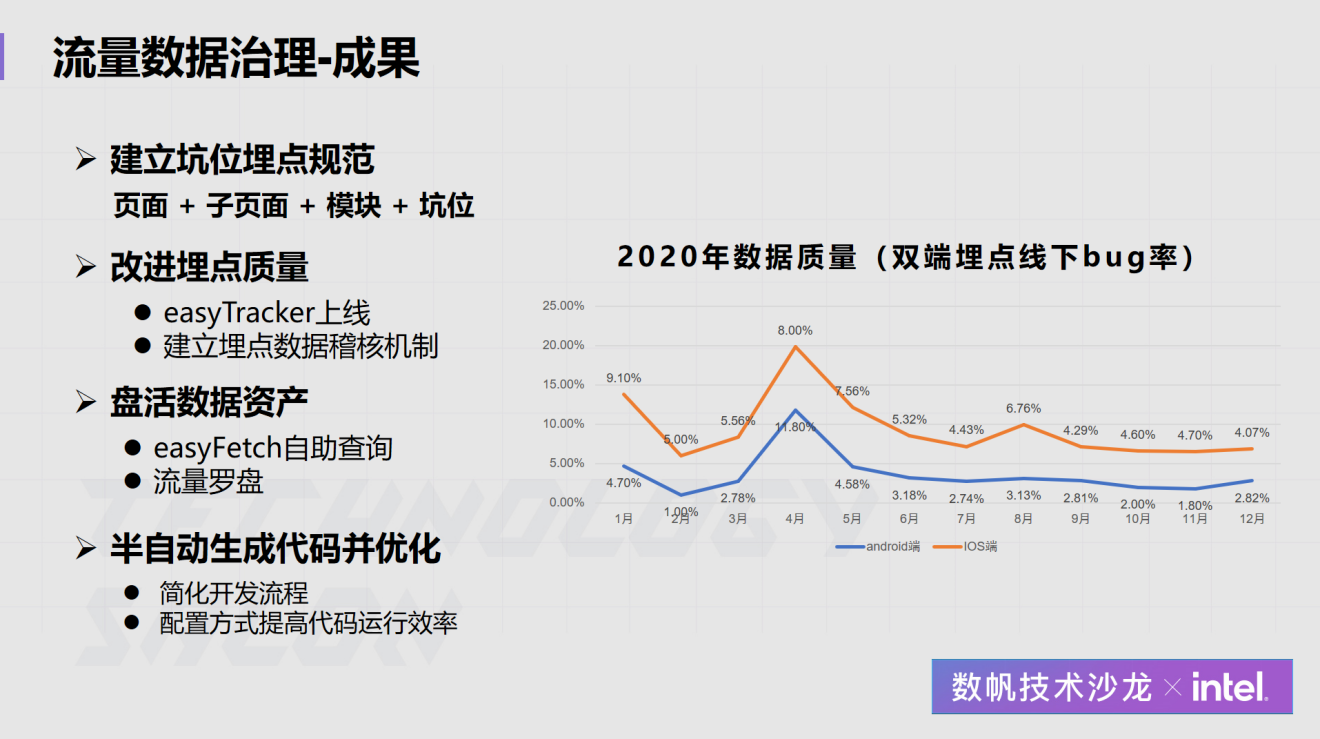
网易云音乐作为一个MAU已经超过亿级的业务,在数据仓库、数据体系、数据应用建设是怎么做的?在近日举办的“网易数帆技术沙龙”上,网易云音乐数据专家雷剑波就此话题做了全面的分享,介绍了数仓建设的目标,为此建立的一系列规范和机制,如何通过系统保证这些规范和机制的落地,以及取得的效果。数仓建设痛点与目 w397090770 3年前 (2021-06-30) 975℃ 0评论1喜欢
Apache Spark 和 Apache HBase 是两个使用比较广泛的大数据组件。很多场景需要使用 Spark 分析/查询 HBase 中的数据,而目前 Spark 内置是支持很多数据源的,其中就包括了 HBase,但是内置的读取数据源还是使用了 TableInputFormat 来读取 HBase 中的数据。这个 TableInputFormat 有一些缺点:一个 Task 里面只能启动一个 Scan 去 HBase 中读取数据;TableIn w397090770 6年前 (2019-04-02) 13073℃ 5评论18喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-09-16) 119806℃ 4评论290喜欢
我下载的Apache Zeppelin和Apache Spark版本分别为:0.6.0-incubating-SNAPSHOT和1.5.2,在Zeppelin中使用SQLContext读取Json文件创建DataFrame的过程中出现了以下的异常:[code lanh="scala"]val profilesJsonRdd =sqlc.jsonFile("hdfs://www.iteblog.com/tmp/json")val profileDF=profilesJsonRdd.toDF()profileDF.printSchema()profileDF.show()profileDF.registerTempTable("profiles") w397090770 9年前 (2016-01-21) 6845℃ 2评论11喜欢
Apache Kafka 0.10.2.0正式发布,此版本供修复超过200个bugs,合并超过500个 PR。本版本添加了一下的新功能: 1、支持session windows,参见KAFKA-3452 2、提供ProcessorContext中低层次Metrics的访问,参见KAFKA-3537 3、不用配置文件的情况下支持为 Kafka clients JAAS配置,参见KAFKA-4259 4、为Kafka Streams提供全局Table支持,参见KAFKA-4490 w397090770 8年前 (2017-02-23) 2561℃ 0评论1喜欢
我们知道,Zookeeper 会将所有事务操作的数据记录到日志文件中,这个文件的存储路径可以通过 dataLogDir 参数配置。在写数据之前,Zookeeper 会采用磁盘空间预分配策略;磁盘空间预分配策略主要有以下几点好处:可以让文件尽可能的占用连续的磁盘扇区,减少后续写入和读取文件时的磁盘寻道开销;迅速占用磁盘空间,防止使用 w397090770 7年前 (2018-03-23) 2064℃ 0评论5喜欢
本文系奇虎360系统部相关工程师投稿。近两年人工智能技术发展迅速,以Google开源的TensorFlow为代表的各种深度学习框架层出不穷。为了方便算法工程师使用各类深度学习技术,减少繁杂的诸如运行环境部署运维等工作,提升GPU等硬件资源利用率,节省硬件投入成本,奇虎360系统部大数据团队与人工智能研究院联合开发了深度学习 w397090770 7年前 (2017-12-08) 2744℃ 0评论15喜欢
Apache Spark于北京时间2015年07月16日05点正式发布。Spark 1.4.1主要是维护版本,包含了大量的稳定性修复。该版本是基于branch-1.4分支。社区推荐所有1.4.0使用升级到这个稳定版本。此版本有85位开发者参与。 Spark 1.4.1包含了大量的Bug修复,这些Bug出现在Spark的DataFrame、外部数据源支持以及其他组建的一些bug修复。一些比较重要 w397090770 9年前 (2015-07-16) 4361℃ 0评论10喜欢
在很多场景中我们会使用Shell命令来发送邮件,而且我们还可能在邮件里面添加附件,本文将介绍使用Shell命令发送带附件邮件的几种方式,希望对大家有所帮助。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop使用mail命令mail命令是mailutils(On Debian)或mailx(On RedHat)包中的一部分,我们可以使 w397090770 8年前 (2017-02-23) 16263℃ 0评论12喜欢
最近,本博客由于流量增加,网站响应速度变慢,于是将全站页面全部静态化了;其中采取的方式主要是(1)、把所有https://www.iteblog.com/archives/\d{1,}全部跳转成https://www.iteblog.com/archives/\d{1,}.html,比如之前访问https://www.iteblog.com/archives/1983链接会自动跳转到https://www.iteblog.com/archives/1983.html;(2)、所有https://www.iteblog.com/page页 w397090770 8年前 (2017-02-22) 3716℃ 2评论9喜欢
本文来自于王新春在2018年7月29日 Flink China社区线下 Meetup·上海站的分享。王新春目前在唯品会负责实时平台相关内容,主要包括实时计算框架和提供实时基础数据,以及机器学习平台的工作。之前在美团点评,也是负责大数据平台工作。他已经在大数据实时处理方向积累了丰富的工作经验。。本文主要内容如下:唯品会实时 zz~~ 6年前 (2018-08-15) 7243℃ 0评论14喜欢
2010年,几个大胡子年轻人在旧金山成立了一家名为 dotCloud 的 PaaS 平台的公司。dotCloud 主要是基于 PaaS 平台为开发者或开发商提供技术服务。PaaS 的全称是 Platform as a Service,也就是平台即服务。dotCloud 把需要花费大量时间的手工工作和重复劳动抽象成组件和服务,并放到了云端,另外,它还提供了各种监控、告警和控制功能,方便开 w397090770 5年前 (2020-01-15) 853℃ 0评论8喜欢
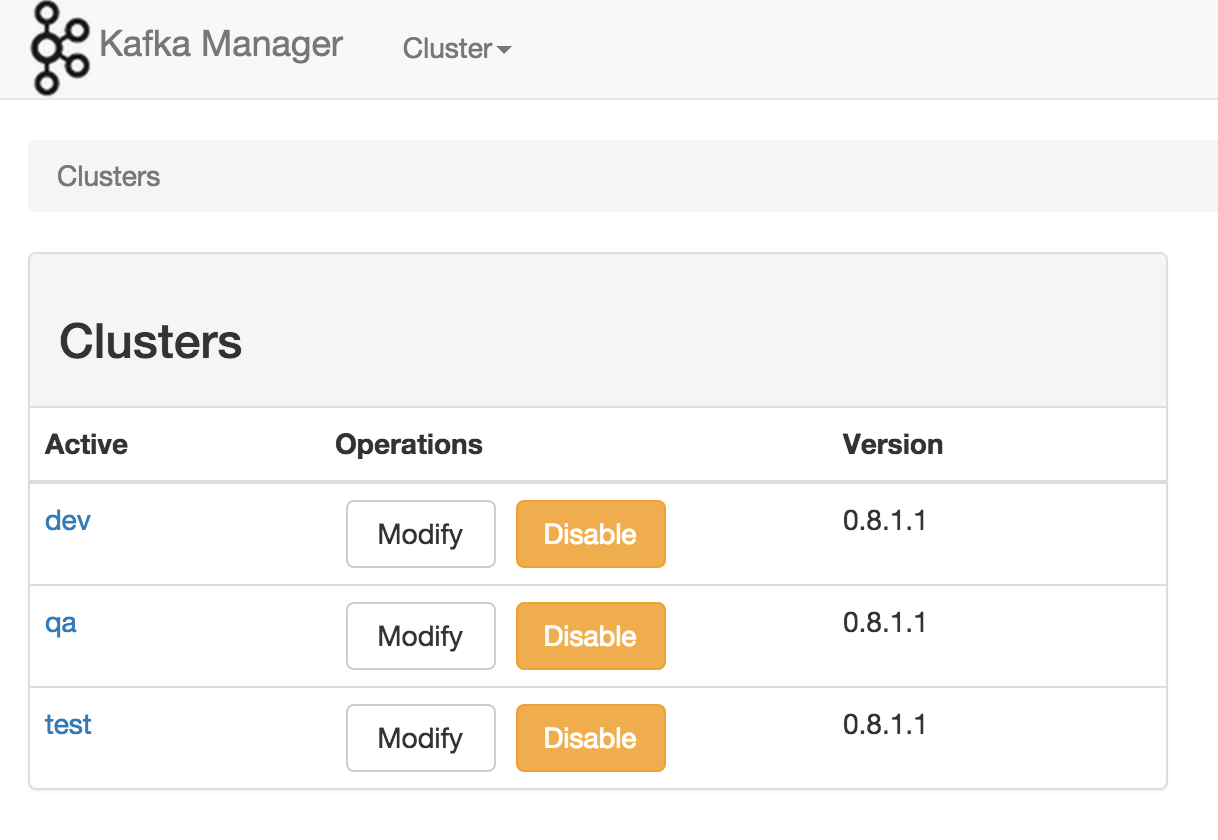
《Apache Kafka监控之Kafka Web Console》《Apache Kafka监控之KafkaOffsetMonitor》《雅虎开源的Kafka集群管理器(Kafka Manager)》Kafka在雅虎内部被很多团队使用,媒体团队用它做实时分析流水线,可以处理高达20Gbps(压缩数据)的峰值带宽。为了简化开发者和服务工程师维护Kafka集群的工作,构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka M w397090770 10年前 (2015-02-04) 22088℃ 0评论14喜欢
Spark SQL从2.0开始已经不再支持ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...)这种语法了(下文简称add columns语法)。如果你的Spark项目中用到了SparkSQL+Hive这种模式,从Spark1.x升级到2.x很有可能遇到这个问题。为了解决这个问题,我们一般有3种方案可以选择: 1、启动一个hiveserver2服务,通过jdbc直接调用hive w397090770 8年前 (2017-02-27) 3033℃ 0评论5喜欢
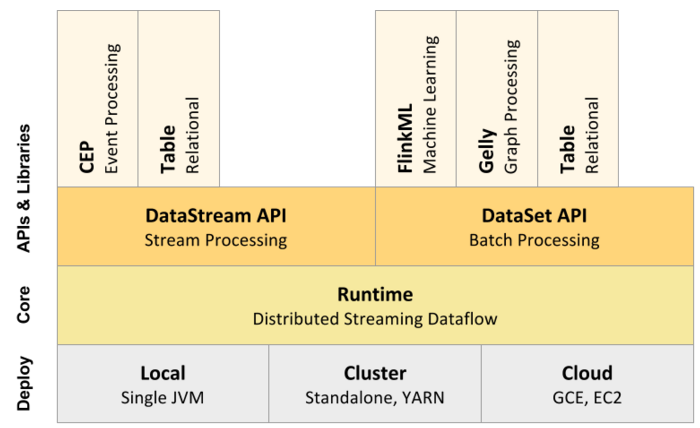
Apache Flink是一个高效、分布式、基于Java和Scala(主要是由Java实现)实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。 从Flink官方文档可以知道,目前Flink支持三大部署模式:Local、Cluster以及Cloud w397090770 9年前 (2016-03-30) 24213℃ 6评论22喜欢
MySQL是一个开放源码的小型关联式数据库管理系统,开发者为瑞典MySQL AB公司。MySQL被广泛地应用在Internet上的中小型网站中。由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,许多中小型网站为了降低网站总体拥有成本而选择了MySQL作为网站数据库。 MySQL是一种跨平台的数据库,在Ubuntu下安装Server的命令 w397090770 11年前 (2013-07-21) 3622℃ 0评论2喜欢
在Linux文件系统中,我们可以使用下面的Shell脚本判断某个文件是否存在:[code lang="bash"]# 这里的-f参数判断$file是否存在 if [ ! -f "$file" ]; then echo "文件不存在!"fi [/code]但是我们想判断HDFS上某个文件是否存在咋办呢?别急,Hadoop内置提供了判断某个文件是否存在的命令:[code lang="bash"][iteblog@www.it w397090770 9年前 (2016-03-21) 10758℃ 0评论19喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事 这几天比较忙,公司里面各种事,所以 w397090770 11年前 (2014-01-14) 30608℃ 4评论42喜欢






![[电子书]Hadoop权威指南第3版中文版PDF下载](https://www.iteblog.com/pic/Hadoop_the_definitive_guide_Third_Edition.jpg)