经过这段时间的整理以及格式调整,以及纠正其中的一些错误修改,整理出PDF下载。下载地址:[dl href="http://download.csdn.net/detail/w397090770/8337439" rel="nofollow"]CSDN免积分下载[/dl] 完整版可以到这里下载Learning Spark完整版下载附录:Learning Spark目录Chapter 1 Introduction to Data Analysis with Spark What Is Apache Spark? A Unified Stack Who Us w397090770 10年前 (2015-01-07) 32552℃ 6评论83喜欢
OpenTSDB 是基于 HBase 的可扩展、开源时间序列数据库(Time Series Database),可以用于存储监控数据、物联网传感器、金融K线等带有时间的数据。它的特点是能够提供最高毫秒级精度的时间序列数据存储,能够长久保存原始数据并且不失精度。它拥有很强的数据写入能力,支持大并发的数据写入,并且拥有可无限水平扩展的存储容量。目 w397090770 6年前 (2018-11-15) 5143℃ 1评论10喜欢
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器[code lang="JAVA"]$ sbin/mr-jobhistory-daemon.sh start historyserver w397090770 11年前 (2014-02-17) 29784℃ 8评论30喜欢
这里用到的nginx日志是网站的访问日志,比如:[code lang="java"]180.173.250.74 - - [08/Jan/2015:12:38:08 +0800] "GET /avatar/xxx.png HTTP/1.1" 200 968 "/archives/994" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36"[/code] 这条日志里面有九列(为了展示的美观,我在里面加入了换行 w397090770 10年前 (2015-01-08) 14242℃ 2评论17喜欢
Lists类主要提供了对List类的子类构造以及操作的静态方法。在Lists类中支持构造ArrayList、LinkedList以及newCopyOnWriteArrayList对象的方法。其中提供了以下构造ArrayList的函数:下面四个构造一个ArrayList对象,但是不显式的给出申请空间的大小:[code lang="JAVA"] newArrayList() newArrayList(E... elements) newArrayList(Iterable<? w397090770 11年前 (2013-09-10) 19702℃ 2评论8喜欢
《Apache Pulsar in Action》于 2021年10月由 Manning 出版, ISBN 为 9781617296888 ,全书 400 页。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop图书介绍《Apache Pulsar in Action》能够无缝地将理论和抽象概念与清晰的循序渐进的实例结合在一起,我愿意向任何人推荐!--- Matteo Merli, co-creator of Apache PulsarDe w397090770 3年前 (2022-03-02) 850℃ 0评论1喜欢
Spark 1.2.0于美国时间2014年12月18日发布,Spark 1.2.0兼容Spark 1.0.0和1.1.0,也就是说不需要修改代码即可用,很多默认的配置在Spark 1.2发生了变化 1、spark.shuffle.blockTransferService由nio改成netty 2、spark.shuffle.manager由hash改成sort 3、在PySpark中,默认的batch size改成0了, 4、Spark SQL方面做的修改: spark.sql.parquet.c w397090770 10年前 (2014-12-19) 4595℃ 1评论2喜欢
通过使用易于理解的实例,本书将教你如何使用Spark Streaming构建实时应用程序。从安装和设置所需的环境开始,您将编写并执行第一个程序Spark Streaming。接下来将探讨Spark Streaming的架构和组件以及概述Spark公开的库/函数的。接下来,您将通过处理分布式日志文件的用例来了解有关Spark中的各种客户端API编码。然后,您将学习到各 w397090770 8年前 (2017-02-12) 3107℃ 0评论6喜欢
Delta Lake 是一个存储层,为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构建在 HDFS 和云存储上的数据湖(data lakes)带来可靠性。Delta Lake 还提供内置数据版本控制,以便轻松回滚。为了更好的学习 Delta Lake ,本文 w397090770 5年前 (2019-09-09) 3968℃ 0评论4喜欢
最近有个项目需要用到手机归属地信息,所有网上找到了一些免费的API。但是因为是免费的,所有很多都有限制,比如每天只能查询多少次等。本站提供的API地址: /api/mobile.php?mobile=13188888888参数:mobile ->手机号码(7位到11位)返回格式:JSON实例结果:[code lang="scala"]{ "ID": "18889", "prefix": &q w397090770 8年前 (2016-08-02) 8018℃ 4评论16喜欢
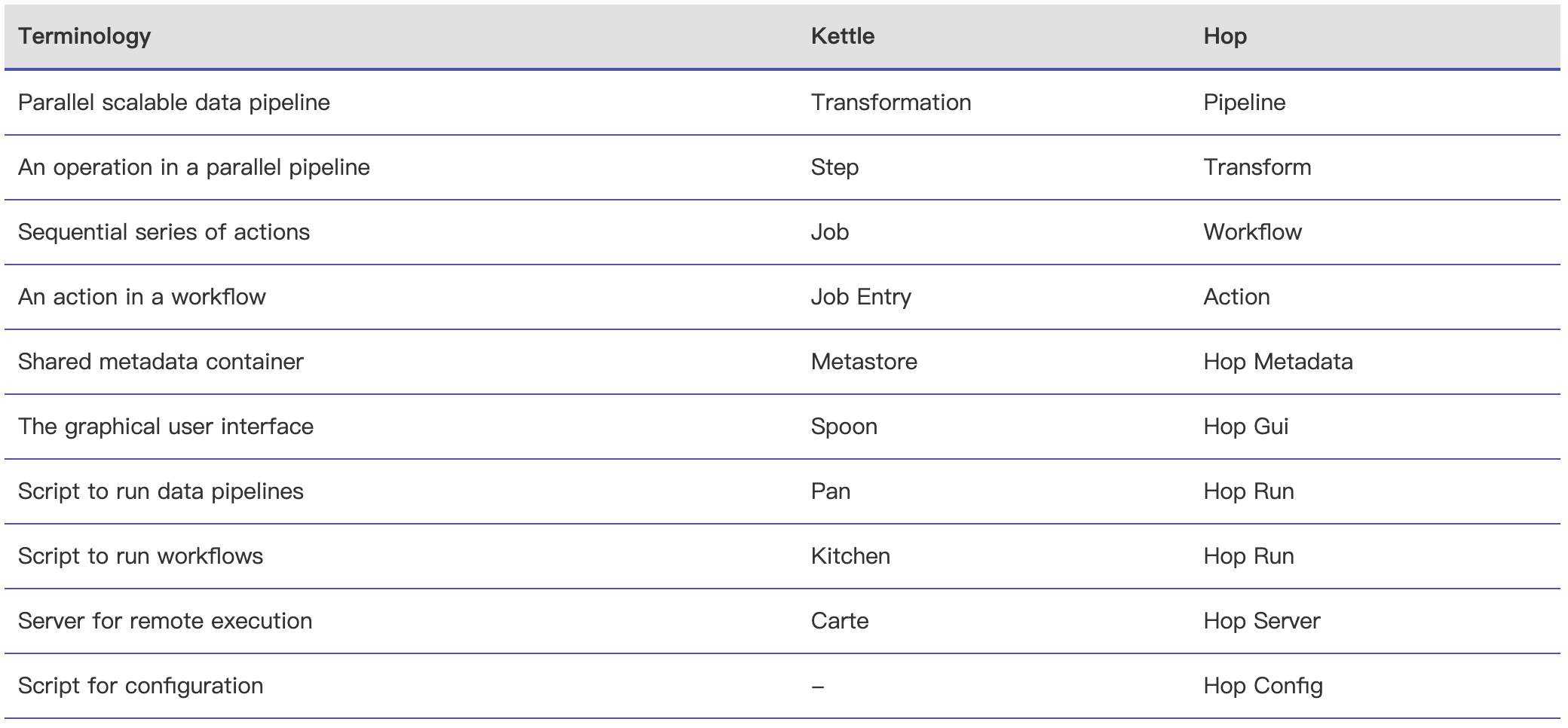
Apache Hop(Hop Orchestration Platform 的首字母缩写)是一种数据编排(data orchestration )和数据工程平台(data engineering platform),旨在促进数据和元数据编制。Hop 可以让我们专注于问题的解决,而不受技术的阻碍。该项目起源于 Kettle,经过数年的重构,并于2020年9月进入 Apache 孵化器;2022年1月18日正式成为 Apache 顶级项目。Hop 允许数据 w397090770 3年前 (2022-01-22) 1587℃ 0评论3喜欢
快速管理和访问 PB 级数据的能力对于整个数据生态系统的可伸缩增长是至关重要的。尽管如此,这种对规模和速度的综合需求并不总是自然地适合现有的批处理和流系统架构。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopHudi 于 2016 年以“Hoodie”为代号开发,旨在解决 Uber 大数据生态系统 w397090770 6年前 (2019-04-20) 933℃ 0评论1喜欢
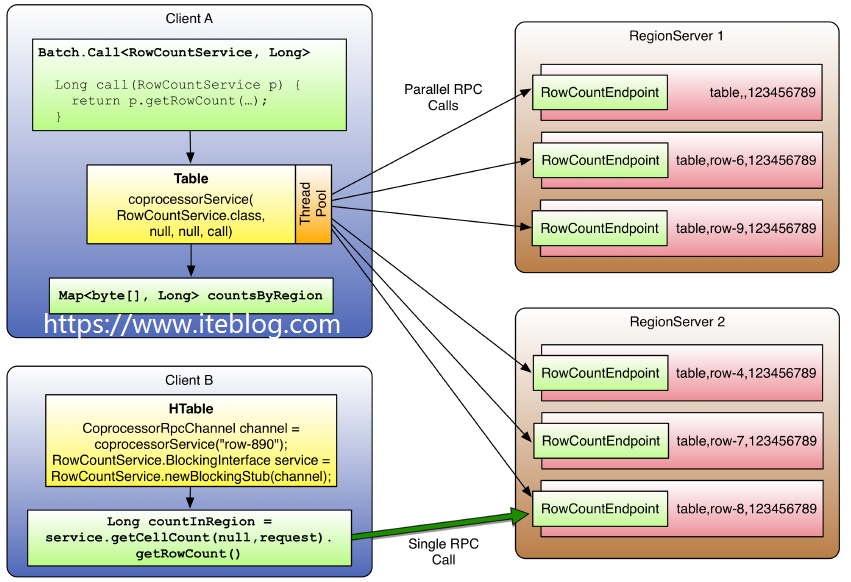
HBase 和 MapReduce 有很高的集成,我们可以使用 MR 对存储在 HBase 中的数据进行分布式计算。但是在很多情况下,例如简单的加法计算或者聚合操作(求和、计数等),如果能够将这些计算推送到 RegionServer,这将大大减少服务器和客户的的数据通信开销,从而提高 HBase 的计算性能,这就是本文要介绍的协处理器(Coprocessors)。HBase w397090770 6年前 (2019-02-17) 6274℃ 2评论13喜欢
七牛云存储直达地址:(点击这里) 随着网站建设的使用时间越来越长,我们的网站可能使用了越来越多的图片、CSS以及js文件,虽然这些的大小都不大,但如果请求的次数多了,这些文件的大小加起来就是一个可观的大小了!而且,如果你们页面图片或者js等文件多了,并且你的网站访问速度不太快的话,这会严重影响到 w397090770 10年前 (2015-01-12) 8795℃ 0评论11喜欢
在Flink中有许多函数需要我们为其指定key,比如groupBy,Join中的where等。如果我们指定的Key不对,可能会出现一些问题,正如下面的程序:[code lang="scala"]package com.iteblog.flinkimport org.apache.flink.api.scala.{ExecutionEnvironment, _}import org.apache.flink.util.Collector///////////////////////////////////////////////////////////////////// User: 过往记忆 Date: 2017 w397090770 8年前 (2017-03-13) 16845℃ 9评论15喜欢
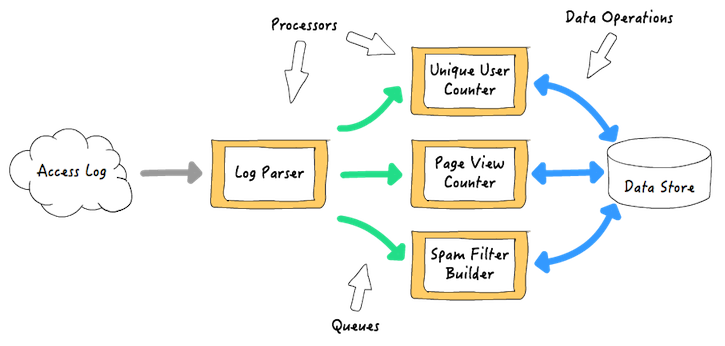
一个实时流处理框架通常需要两个基础架构:处理器和队列。处理器从队列中读取事件,执行用户的处理代码,如果要继续对结果进行处理,处理器还会把事件写到另外一个队列。队列由框架提供并管理。队列做为处理器之间的缓冲,传输数据和事件,这样处理器可以单独操作和扩展。例如,一个web 服务访问日志处理应用,可能是 w397090770 7年前 (2017-07-12) 584℃ 0评论0喜欢
Balloon.css文件允许用户给元素添加提示,而这些在Balloon.css中完全是由CSS来实现,不需要使用JavaScript。 button { display: inline-block; min-width: 160px; text-align: center; color: #fff; background: #ff3d2e; padding: 0.8rem 2rem; font-size: 1.2rem; margin-top: 1rem; border: none; border-radius: 5px; transition: background 0.1s linear;}.butt w397090770 9年前 (2016-03-15) 2474℃ 3评论10喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ 这些天看到很多人在使用H w397090770 11年前 (2013-12-25) 25275℃ 0评论23喜欢
《Kafka in Action》于 2022年01月由 Manning 出版, ISBN 为 9781617295232 ,全书 272 页。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop图书介绍作者有多年使用 Kafka 的真实世界的经验,这本书的实地感觉真的让它与众不同。---- From the foreword by Jun Rao, Confluent CofounderMaster the wicked-fast Apache Kafka streaming w397090770 3年前 (2022-03-02) 589℃ 0评论3喜欢
几天前(2016年7月27日),Apache社区发布了Apache Mesos 1.0.0, 这是 Apache Mesos 的一个里程碑事件。相较于前面的版本, 1.0.0首先是改进了与 docker 的集成方式,弃用了 docker daemon;其次,新版本大力推进解决了接口规范化问题,新的 HTTP API 使得开发者能够更容易的开发 Mesos 框架;最后, 为了更好的满足企业用户的多租户,安全,审 w397090770 8年前 (2016-07-31) 2026℃ 0评论2喜欢
如果我们需要通过编程的方式来获取到Kafka中某个Topic的所有分区、副本、每个分区的Leader(所在机器及其端口等信息),所有分区副本所在机器的信息和ISR机器的信息等(特别是在使用Kafka的Simple API来编写SimpleConsumer的情况)。这一切可以通过发送TopicMetadataRequest请求到Kafka Server中获取。代码片段如下所示:[code lang="scala"]de w397090770 8年前 (2016-05-09) 8251℃ 0评论4喜欢
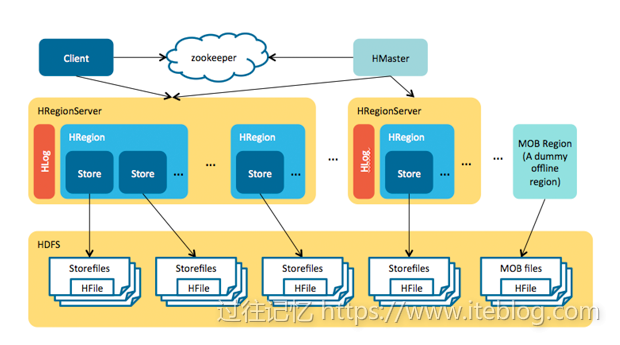
《Apache HBase中等对象存储MOB压缩分区策略介绍》 文章中介绍了 MOB 的一些压缩实现,并提及了一些 MOB 的一些简单使用,本文将详细地介绍 HBase MOB 的使用,本指南适合入门的开发者。将不同大小的文件(比如图片、文档等)存储到 HBase 非常的简单方便。从技术上来说,HBase 可以直接在一个单元格(Cell)存储大小到10MB的二进制对 w397090770 6年前 (2018-12-03) 2794℃ 0评论5喜欢
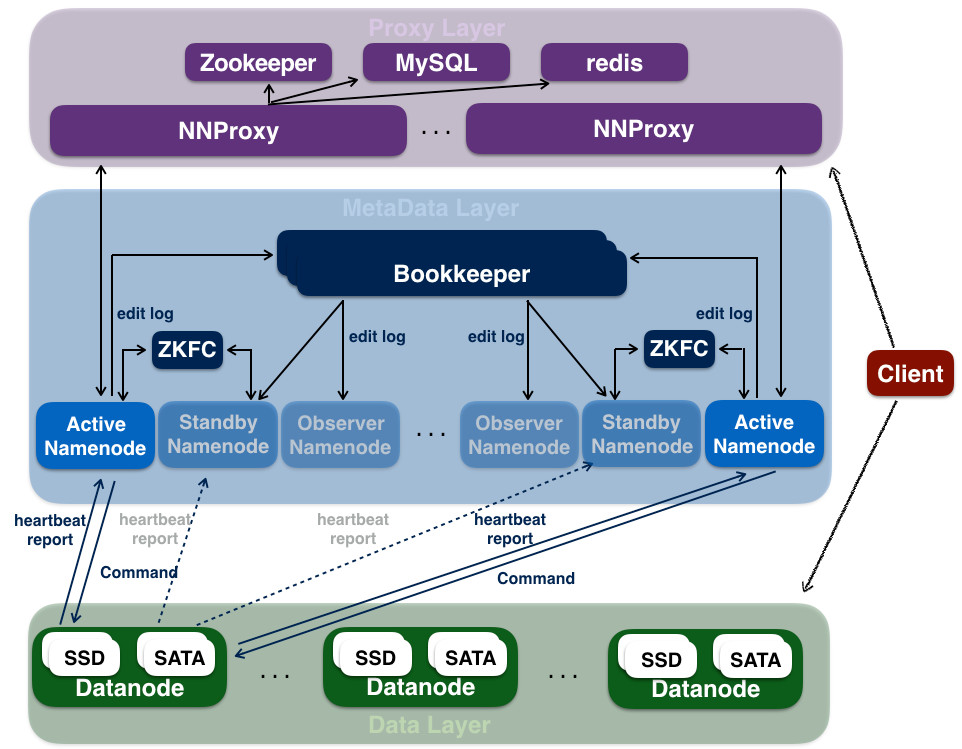
HDFS 简介因为 HDFS 这样一个系统已经存在了非常长的时间,应用的场景已经非常成熟了,所以这部分我们会比较简单地介绍。HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:和本地文件系统一样的目录树视图Append Only 的写入(不支持 w397090770 5年前 (2020-01-10) 2382℃ 0评论4喜欢
本书于2017-08由Packt Publishing出版,作者Ankit Jain, 全书341页。通过本书你将学到以下知识Understand the core concepts of Apache Storm and real-time processingFollow the steps to deploy multiple nodes of Storm ClusterCreate Trident topologies to support various message-processing semanticsMake your cluster sharing effective using Storm schedulingIntegrate Apache Storm with other Big Data technolo zz~~ 7年前 (2017-08-30) 3724℃ 4评论16喜欢
Snappy是用C++开发的压缩和解压缩开发包,旨在提供高速压缩速度和合理的压缩率。Snappy比zlib更快,但文件相对要大20%到100%。在64位模式的Core i7处理器上,可达每秒250~500兆的压缩速度。 Snappy的前身是Zippy。虽然只是一个数据压缩库,它却被Google用于许多内部项目程,其中就包括BigTable,MapReduce和RPC。Google宣称它在这个库本 w397090770 11年前 (2014-03-03) 13575℃ 1评论2喜欢
你可能会在Scala中经常使用for循环已经,所以理解Scala编译器是如何解析for循环语句是非常重要的。我们记住以下四点规则即可: 1、对集合进行简单的for操作,Scala编译器会将它翻译成对集合进行foreach操作; 2、带有guard的for循环,编译器会将它翻译成一序列的withFilter操作,紧接着是foreach操作; 3、带有yield的for w397090770 9年前 (2015-10-20) 4001℃ 0评论6喜欢
JMX(Java Management Extensions,即Java管理扩展)是一个为应用程序、设备、系统等植入管理功能的框架。JMX可以跨越一系列异构操作系统平台、系统体系结构和网络传输协议,灵活的开发无缝集成的系统、网络和服务管理应用。启动JMX监控,在启动java程序的时候最少需要在环境变量里面配置以下的选项:[code lang="bash"]-Dcom.sun.m w397090770 9年前 (2016-03-25) 6185℃ 0评论10喜欢
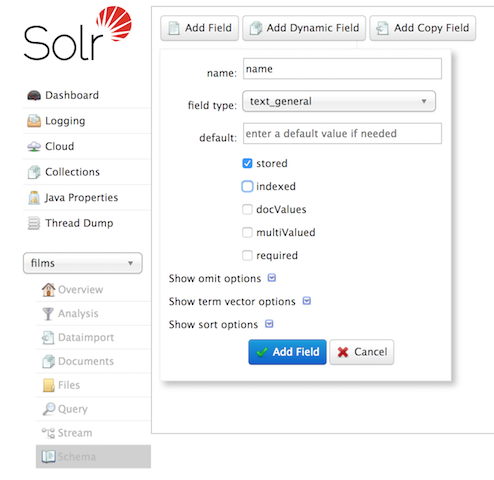
到目前为止,我们往 Solr 里面导数据都没有定义模式,也就是说让 Solr 去猜我们数据的类型以及解析方式,这种方式成为无模式(Schemaless)。Apache Solr 里面的定义为:One reason for this is we’re going to use a feature in Solr called "field guessing", where Solr attempts to guess what type of data is in a field while it’s indexing it. It also automatically creates new fields in th w397090770 6年前 (2018-08-01) 1694℃ 0评论4喜欢
这是Spark北京Meetup第四次活动,主要是SparkSQL专题。可以在这里报名,活动免费。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动时间 12月13日下午14:00活动地点 地址:淀区中关村软件园二期,西北旺东路10号院东区,亚信大厦 一层会议室 时间:13:20-13:40活动内容: w397090770 10年前 (2014-12-02) 4979℃ 0评论3喜欢
本书由Robert D. Schneider所著,全书共45页,这里提供的是完整版。 w397090770 9年前 (2015-08-21) 2541℃ 0评论2喜欢






![[电子书]Learning Real-time Processing with Spark Streaming PDF下载](https://www.iteblog.com/pic/books/Learning_Real-time_Processing_with_Spark_Streaming-iteblog.jpg)







![[电子书]Mastering Apache Storm PDF下载](https://www.iteblog.com/pic/books/Mastering_Apache_Storm_iteblog.png)