《Spark 2.0技术预览:更容易、更快速、更智能》文章中简单地介绍了Spark 2.0带来的新技术等。Spark 2.0是Apache Spark的下一个主要版本。此版本在架构抽象、API以及平台的类库方面带来了很大的变化,为该框架明年的发展奠定了方向,所以了解Spark 2.0的一些特性对我们能够使用它有着非常重要的作用。本博客将对Spark 2.0进行一序列的介 w397090770 8年前 (2016-07-05) 8864℃ 0评论12喜欢
本书于2015年03月出版,全书共19页,这里是完整版。 w397090770 9年前 (2015-08-21) 1851℃ 0评论3喜欢
今天将临时表里面的数据按照天分区插入到线上的表中去,出现了Hive创建的文件数大于100000个的情况,我的SQL如下:[code lang="sql"]///////////////////////////////////////////////////////////////////// User: 过往记忆 Date: 2015-11-18 Time: 23:24 bolg: 本文地址:/archives/1533 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量 w397090770 9年前 (2015-11-18) 22941℃ 3评论53喜欢
后缀表达式又叫做逆波兰表达式。在通常的表达式中,二元运算符总是置于与之相关的两个运算对象之间,所以,这种表示法也称为中缀表示。波兰逻辑学家J.Lukasiewicz于1929年提出了另一种表示表达式的方法。按此方法,每一运算符都置于其运算对象之后,故称为后缀表示。运用后缀表达式进行计算的具体做法:建立一个栈S 。从 w397090770 12年前 (2013-04-03) 6242℃ 0评论0喜欢
Java 8 流的新类 java.util.stream.Collectors 实现了 java.util.stream.Collector 接口,同时又提供了大量的方法对流 ( stream ) 的元素执行 map and reduce 操作,或者统计操作。本章节,我们就来看看那些常用的方法,顺便写几个示例练练手。Collectors.averagingDouble()Collectors.averagingDouble() 方法将流中的所有元素视为 double 类型并计算他们的平均值 w397090770 3年前 (2022-03-31) 175℃ 0评论1喜欢
在 《Apache Solr 安装部署及索引创建》 文章里面我创建了一个名为 iteblog 的 core,并在里面导入了一些测试数据,然后在 《使用 Apache Solr 检索数据》 里面介绍了 Solr 中一些简单的查询。可能有同学按照上面文章介绍,在使用下面的查询发现啥都查不到:[code lang="bash"][root@iteblog.com /opt/solr-7.4.0]$ curl http://iteblog.com:8983/solr/iteblog/select w397090770 6年前 (2018-07-27) 1498℃ 0评论4喜欢
本文已经不再更新,谢谢支持。本页面长期更新最新 Google、谷歌学术、维基百科、ccFox.info、ProjectH、3DM、Battle.NET 、WordPress、Microsoft Live、GitHub、Box.com、SoundCloud、inoreader、Feedly、FlipBoard、Twitter、Facebook、Flickr、imgur、DuckDuckGo、Ixquick、Google Services、Google apis、Android、Youtube、Google Drive、UpLoad、Appspot、Googl eusercontent、Gstatic、Google othe w397090770 5年前 (2019-11-19) 1090℃ 0评论3喜欢
4月6日,Apache Hadoop 3.1.0 正式发布了,Apache Hadoop 3.1.0 是2018年 Hadoop-3.x 系列的第一个小版本,并且带来了许多增强功能。不过需要注意的是,这个版本并不推荐在生产环境下使用,如果需要在正式环境下使用,请等待 3.1.1 或 3.1.2 版本。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop这个版 w397090770 7年前 (2018-04-08) 3530℃ 0评论15喜欢
本书由Robert D. Schneider所著,全书共45页,这里提供的是完整版。 w397090770 9年前 (2015-08-21) 2541℃ 0评论2喜欢
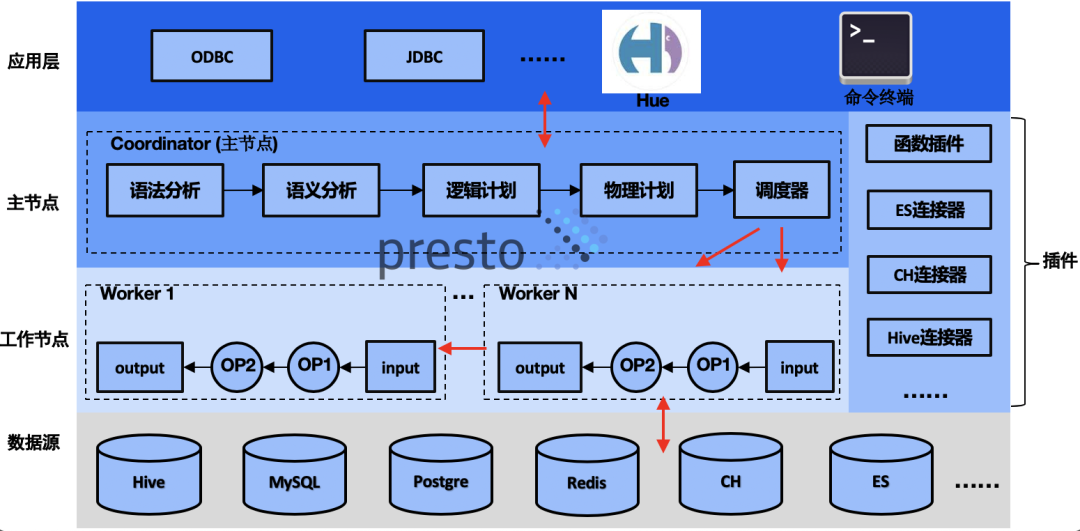
文章来源团队:腾讯医疗资讯与服务部-技术研发中心 前言:随着产品矩阵和团队规模的扩张,跨业务、APP的数据处理、分析总是不可避免。一个显而易见的问题就是异构数据源的连通。我们基于PrestoDB构建了业务线内适应腾讯生态的联邦查询引擎,连通了部门内部20+数据源实例,涵盖了90%的查询场景。同时,我们参与公司级的Pre w397090770 3年前 (2021-09-08) 536℃ 0评论1喜欢
全新美国区 Apple ID 注册教程参见:2021年最新美区 Apple ID 注册教程使用苹果手机的有可能知道,国内使用的 App Store 只能下载国内的一些 APP 应用。有一些 APP 并没有在国内 App Store 上架,这时候就无法下载。我们需要使用一个国外的 Apple ID 账号,但是很多人手上一般都是只有国内的账号,这篇文章就来教大家如何把一个中国区的 w397090770 3年前 (2021-10-10) 1473℃ 0评论2喜欢
本文出自本公众号ChinaScala,由陈超所述。一、Spark能否取代Hadoop? 答: Hadoop包含了Common,HDFS,YARN及MapReduce,Spark从来没说要取代Hadoop,最多也就是取代掉MapReduce。事实上现在Hadoop已经发展成为一个生态系统,并且Hadoop生态系统也接受更多优秀的框架进来,如Spark (Spark可以和HDFS无缝结合,并且可以很好的跑在YARN上).。 w397090770 9年前 (2015-08-26) 7189℃ 1评论42喜欢
这里说明一点:本文提到的解决Spark insertIntoJDBC找不到Mysql驱动的方法是针对单机模式(也就是local模式)。在集群环境下,下面的方法是不行的。这是因为在分布式环境下,加载mysql驱动包存在一个Bug,1.3及以前的版本 --jars 分发的jar在executor端是通过Spark自身特化的classloader加载的。而JDBC driver manager使用的则是系统默认的classloader w397090770 10年前 (2015-04-03) 19109℃ 3评论15喜欢
VSFTP是一个基于GPL发布的类Unix系统上使用的FTP服务器软件,它的全称是Very Secure FTP 从此名称可以看出来,编制者的初衷是代码的安全。本文将介绍如何在CentOS系统上安装、部署和卸载vsftp。1. 安装VSFTP[code lang="bash"][iteblog@www.iteblog.com ~]# yum -y install vsftpd[/code]2. 配置vsftpd.conf文件[code lang="bash"][iteblog@www.iteblog.com ~]# v w397090770 9年前 (2016-04-16) 2100℃ 0评论3喜欢
SQL Join 是最重要和最昂贵的 SQL 操作之一,需要数据库工程师深入理解才能编写高效的 SQL 查询。 从数据库工程师的角度来看,了解 JOIN 操作的工作原理有助于他们优化 JOIN 以实现高效执行。 本文介绍了开源分布式计算引擎 Presto SQL 支持的 join 操作。几乎所有众所周知的数据库都支持以下五种类型的 JOIN 操作:Cross Join, Inner Join, L w397090770 3年前 (2021-11-01) 1470℃ 0评论1喜欢
Spark支持三种模式的部署:YARN、Standalone以及Mesos。本篇说到的Worker只有在Standalone模式下才有。Worker节点是Spark的工作节点,用于执行提交的作业。我们先从Worker节点的启动开始介绍。 Spark中Worker的启动有多种方式,但是最终调用的都是org.apache.spark.deploy.worker.Worker类,启动Worker节点的时候可以传很多的参数:内存、核、工作 w397090770 10年前 (2014-10-08) 11335℃ 3评论7喜欢
由 Ahana 工程师 Vivek Bharathan、David E. Simmen 以及 George Wang 编写的《Learning and Operating Presto》图书计划在2021年11月发布,不过预览版已经可以下载了。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书描述Presto 社区自2012年诞生于 Facebook 后迅速发展起来。但是,即使对最有经验的工程师来说 w397090770 4年前 (2021-01-21) 508℃ 0评论2喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 第三次北京Spark Meetup活动将于2014年10月26日星期日的下午1:30到6:00在海淀区中关村科学院南路2号融科资讯中心A座8层举行,本次分享的主题主要是MLlib与分布式机器学 w397090770 10年前 (2014-10-09) 4463℃ 6评论6喜欢
我们在《Kafka创建Topic时如何将分区放置到不同的Broker中》文章中已经学习到创建 Topic 的时候分区是如何分配到各个 Broker 中的。今天我们来介绍分区分配到 Broker 中之后,会再哪个目录下创建文件夹。我们知道,在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录 w397090770 7年前 (2017-08-09) 5068℃ 0评论15喜欢
Apache Hudi 是一种数据湖平台技术,它提供了构建和管理数据湖所需的几个功能。hudi 提供的一个关键特性是自我管理文件大小,这样用户就不需要担心手动维护表。拥有大量的小文件将使计算更难获得良好的查询性能,因为查询引擎不得不多次打开/读取/关闭文件以执行查询。但是对于流数据湖用例来说,可能每次都只会写入很少的 w397090770 3年前 (2021-08-03) 1067℃ 0评论1喜欢
本文转载至 http://www.ibm.com/developerworks/cn/java/j-dcl.html 单例创建模式是一个通用的编程习语。和多线程一起使用时,必需使用某种类型的同步。在努力创建更有效的代码时,Java 程序员们创建了双重检查锁定习语,将其和单例创建模式一起使用,从而限制同步代码量。然而,由于一些不太常见的 Java 内存模型细节的原因,并不能 w397090770 11年前 (2013-10-18) 4653℃ 4评论6喜欢
美国时间 2018年11月08日 正式发布了。一如既往,为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.4 带来了许多新功能,如下:添加一种支持屏障模式(barrier mode)的调度器,以便与基于MPI的程序更好地集成,例如, 分布式深度学习框架;引入了许多内置的高阶函数,以便更容易处理复杂的数据类型(比如数组和 map); w397090770 6年前 (2018-11-10) 4506℃ 0评论6喜欢
最近在Yarn上使用Spark,不管是yarn-cluster模式还是yarn-client模式,都出现了以下的异常:[code lang="java"]Application application_1434099279301_123706 failed 2 times due to AM Container for appattempt_1434099279301_123706_000002 exited with exitCode: 127 due to: Exception from container-launch:org.apache.hadoop.util.Shell$ExitCodeException:at org.apache.hadoop.util.Shell.runCommand(Shell.java:464) w397090770 9年前 (2015-06-19) 7858℃ 0评论3喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-07-15) 92406℃ 0评论164喜欢
在《ElasticSearch系列文章:基本介绍》中主要介绍了ElasticSearch一些使用场景,本文将对Elasticsearch的核心概念进行介绍,这对后期使用ElasticSearch有着重要的影响。 1、NearRealtime(NRT):准实时Elasticsearch是一个准实时的搜索平台,这意味着当你索引一个文档(document )时,在细微的延迟(通常1s)之后,该文件才能被搜索到。 w397090770 8年前 (2016-08-09) 2425℃ 2评论3喜欢
Short URL or tiny URL is an URL used to represent a long URL. For example, http://tinyurl.com/45lk7x will be redirect to http://www.snippetit.com/2008/10/implement-your-own-short-url.There are 2 main advantages of using short URL: Easy to remember - Instead of remember an URL with 50 or more characters, you only need to remember a few (5 or more depending on application's implementation). More portable - Some systems have limi w397090770 12年前 (2013-04-15) 20484℃ 0喜欢
分布式计算开源框架Hadoop近日发布了今年的第一个版本Hadoop-2.3.0,新版本不仅增强了核心平台的大量功能,同时还修复了大量bug。新版本对HDFS做了两个非常重要的增强:(1)、支持异构的存储层次;(2)、通过数据节点为存储在HDFS中的数据提供了内存缓存功能。 借助于HDFS对异构存储层次的支持,我们将能够在同一个Hado w397090770 11年前 (2014-03-02) 4134℃ 0评论1喜欢
有时候我们需要根据记录的类别分别写到不同的文件中去,正如本博客的 《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(一)》《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(二)》以及《Spark多文件输出(MultipleOutputFormat)》等文章提到的类似。那么如何在Flink Streaming实现类似于《Spark多文件输出(MultipleOutputFormat)》文 w397090770 8年前 (2016-05-10) 8229℃ 4评论7喜欢
写在前面的话,最近发现有很多网站转载我博客的文章,这个我都不介意的,但是这些网站转载我博客都将文章的出处去掉了,直接变成自己的文章了!!我强烈谴责他们,鄙视那些转载文章去掉出处的人!所以为了防止这些,我以后发表文章的时候,将会在文章里面加入一些回复之后才可见的内容!!请大家不要介意,本博 w397090770 10年前 (2014-06-06) 30615℃ 40评论6喜欢
《Spark RDD缓存代码分析》 《Spark Task序列化代码分析》 《Spark分区器HashPartitioner和RangePartitioner代码详解》 《Spark Checkpoint读操作代码分析》 《Spark Checkpoint写操作代码分析》 上次介绍了RDD的Checkpint写过程(《Spark Checkpoint写操作代码分析》),本文将介绍RDD如何读取已经Checkpint的数据。在RDD Checkpint w397090770 9年前 (2015-12-23) 6392℃ 0评论10喜欢