经过七轮投票, Apache Spark™ 3.2 终于在昨天正式发布了。Apache Spark™ 3.2 已经是 Databricks Runtime 10.0 的一部分,感兴趣的同学可以去试用一下。按照惯例,这个版本应该不是稳定版,所以建议大家不要在生产环境中使用。Spark 的每月 Maven 下载数量迅速增长到 2000 万,与去年同期相比,Spark 的月下载量翻了一番。Spark 已成为在单节 w397090770 3年前 (2021-10-20) 1308℃ 0评论3喜欢
spark.cleaner.ttl参数的原意是清除超过这个时间的所有RDD数据,以便腾出空间给后来的RDD使用。周期性清除保证在这个时间之前的元数据会被遗忘,对于那些运行了几小时或者几天的Spark作业(特别是Spark Streaming)设置这个是很有用的。注意:任何内存中的RDD只要过了这个时间就会被清除掉。官方文档是这么介绍的:Duration (secon w397090770 9年前 (2015-05-20) 8113℃ 0评论7喜欢
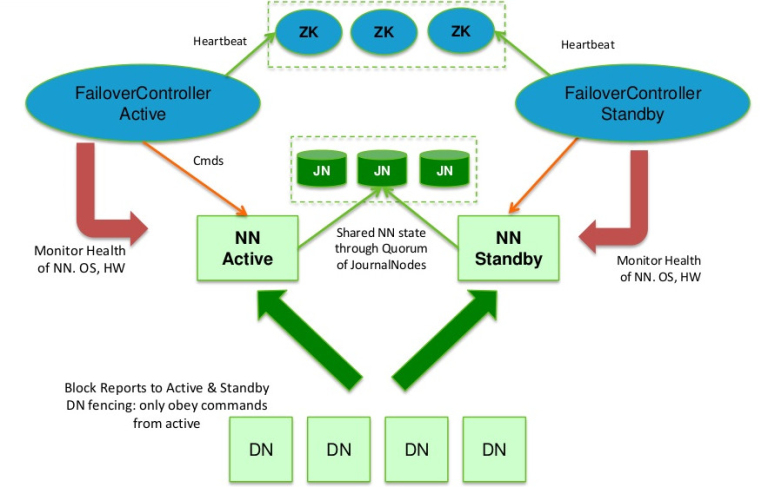
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。 主要在两方面影响了HDFS的可用性: (1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个 w397090770 11年前 (2013-11-14) 10632℃ 3评论22喜欢
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》shuffle调优调优概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。因此,如果要让作业的性能更上一层楼,就有必要对sh w397090770 8年前 (2016-05-15) 22506℃ 2评论52喜欢
在使用Spark streaming消费kafka数据时,程序异常中断的情况下发现会有数据丢失的风险,本文简单介绍如何解决这些问题。 在问题开始之前先解释下流处理中的几种可靠性语义: 1、At most once - 每条数据最多被处理一次(0次或1次),这种语义下会出现数据丢失的问题; 2、At least once - 每条数据最少被处理一次 (1 w397090770 8年前 (2016-07-26) 10905℃ 3评论17喜欢
Spark Summit 2016 San Francisco会议于2016年6月06日至6月08日在美国San Francisco进行。本次会议有多达150位Speaker,来自业界顶级的公司。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料全部通过爬虫程序下载,如有问题 w397090770 8年前 (2016-06-15) 3368℃ 0评论9喜欢
背景 舜飞科技的各个业务线对接全网的各大媒体及APP,从而产生大量数据,实时分析这些数据不仅仅用于监控业务的发展,还会影响产品的服务质量,直接创造价值。比如优化师要时刻关注活动的投放质量,竞价算法会根据投放数据实时调整策略,网站主会进行流量分析和快速事故反馈等等。这些分析需求的特点: 1 w397090770 8年前 (2017-01-03) 4622℃ 0评论6喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-10-10) 163679℃ 11评论384喜欢
在本博客的《Spark 0.9.1源码编译》和《Spark源码编译遇到的问题解决》两篇文章中,分别讲解了如何编译Spark源码以及在编译源码过程中遇到的一些问题及其解决方法。今天来说说如何部署分布式的Spark集群,在本篇文章中,我主要是介绍如何部署Standalone模式。 一、修改配置文件 1、将$SPARK_HOME/conf/spark-env.sh.template文件 w397090770 11年前 (2014-04-21) 9479℃ 1评论5喜欢
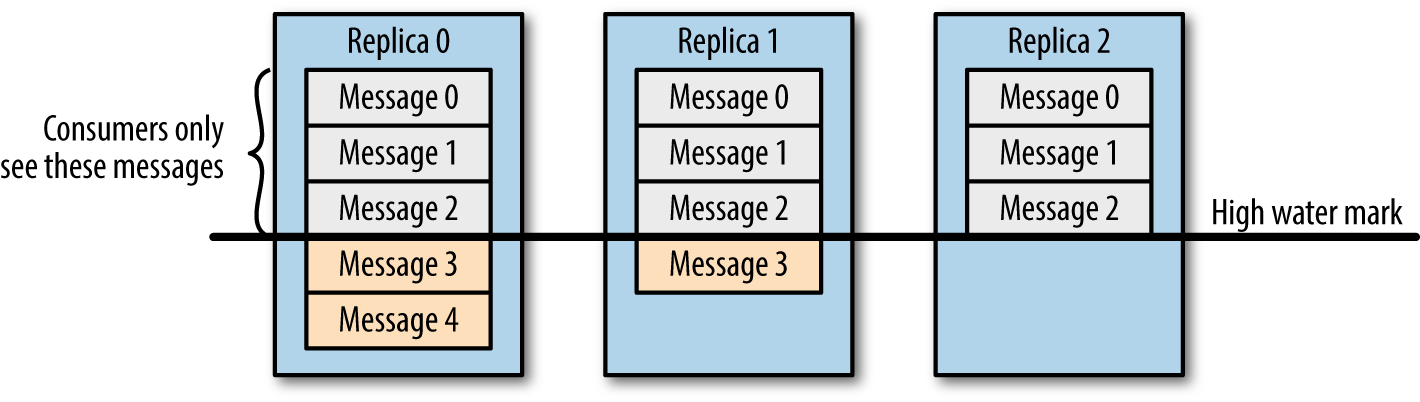
学过大数据的同学应该都知道 Kafka,它是分布式消息订阅系统,有非常好的横向扩展性,可实时存储海量数据,是流数据处理中间件的事实标准。本文将介绍 Kafka 是如何保证数据可靠性和一致性的。数据可靠性Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知。本文从 Producter 往 Broker 发送消息、Topic 分区副本以及 w397090770 5年前 (2019-06-11) 12821℃ 2评论42喜欢
什么是数据迁移Apache Kafka 对于数据迁移的官方说法是分区重分配。即重新分配分区在集群的分布情况。官方提供了kafka-reassign-partitions.sh脚本来执行分区重分配操作。其底层实现主要有如下三步: 通过副本复制的机制将老节点上的分区搬迁到新的节点上。 然后再将Leader切换到新的节点。 最后删除老节点上的分区。重分 zz~~ 3年前 (2021-09-24) 847℃ 0评论5喜欢
本书将为您简要介绍ElasticSearch的基础知识以及Elasticsearch 5的新功能。通过本书将学习到Elasticsearch的基本功能和高级功能,例如查询,索引,搜索和修改数据。本书还介绍了一些高级知识,包括聚合,索引控制,分片,复制和聚类。中间部分介绍了ElasticSearch集群相关的知识,包括备份、监控、恢复等。读完本书,您将掌握Elastics zz~~ 8年前 (2017-02-28) 4963℃ 0评论13喜欢
我们在使用Hive的时候肯定遇到过建立了一张分区表,然后手动(比如使用 cp 或者 mv )将分区数据拷贝到刚刚新建的表作为数据初始化的手段;但是对于分区表我们需要在hive里面手动将刚刚初始化的数据分区加入到hive里面,这样才能供我们查询使用,我们一般会想到使用 alter table add partition 命令手动添加分区,但是如果初始化 w397090770 8年前 (2017-02-21) 16371℃ 0评论31喜欢
Hadoop权威指南英文版第四版,它的内容组织得当,思路清晰,紧密结合实际。但是要把它翻译成中文介绍给中国的读者,并非易事。它不单单要求译者能够熟练地掌握英文,还要求他们对书中的技术性内容有深入、准确的了解和掌握。从这两点来审视,本书的译者团队完全足以胜任。作为大学老师,他们不仅在大数据领域从事一线 w397090770 9年前 (2015-08-15) 4775℃ 0评论9喜欢
我们在 《Presto 中支持的七种 Join 类型》 这篇文章中介绍了 Presto 可用的 JOIN 操作的基础知识,以及如何在 SQL 查询中使用它们。有了这些知识,我们现在可以了解 Presto 的内部结构以及它如何在内部执行 JOIN 操作。本文将介绍 Presto 如何执行 JOIN 操作以及用于 JOIN 的算法。JOIN 的实现几乎所有的数据库引擎一次只 JOIN 两个表。即 w397090770 3年前 (2021-11-17) 786℃ 0评论0喜欢
由Databricks、UC Berkeley以及MIT联合为Apache Spark开发了一款图像处理类库,名为:GraphFrames,该类库是构建在DataFrame之上,它既能利用DataFrame良好的扩展性和强大的性能,同时也为Scala、Java和Python提供了统一的图处理API。什么是GraphFrames 与Apache Spark的GraphX类似,GraphFrames支持多种图处理功能,但得益于DataFrame因此GraphFrames与G w397090770 9年前 (2016-04-09) 4768℃ 0评论6喜欢
假设我们有这样的场景:我们想在 Cassandra 中使用一张表记录用户基本信息(比如 email、密码等)以及用户状态更新。我们知道,用户的基本信息一般很少会变动,但是状态会经常变化,如果每次状态更新都把用户基本信息都加进去,势必会让费大量的存储空间。为了解决这种问题,Cassandra 引入了 static column。同一个 partition key 中被 w397090770 6年前 (2019-04-12) 1367℃ 0评论2喜欢
本书作者:Hari Shreedharan,由O'Reilly Media出版社于2014年09月出版,全书共238页。 如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[code lang="bash"]Chapter 1: Apache Hadoop and Apache HBase:An IntroductionChapter 2: Streaming Data Using Apache FlumeChapter 3:SourcesChapter 4: ChannelsChapter 5: SinksChapter 6: Inter w397090770 9年前 (2015-08-25) 4173℃ 0评论8喜欢
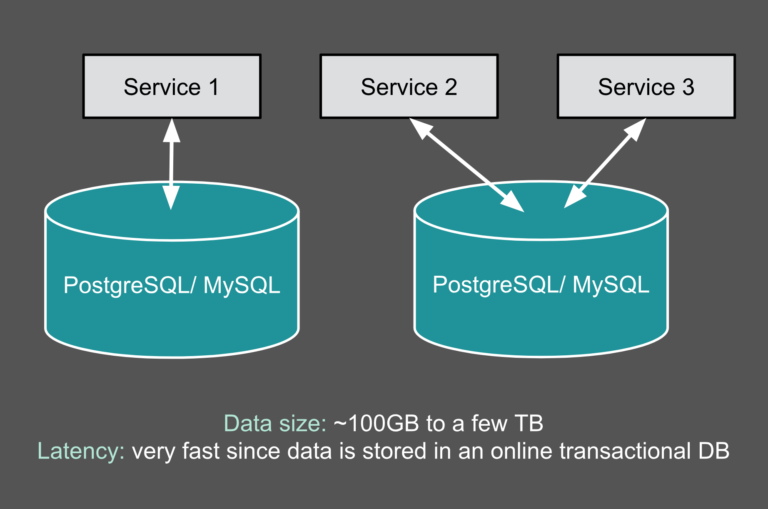
数据处理现状:当前基于Hive的离线数据仓库已经非常成熟,数据中台体系也基本上是围绕离线数仓进行建设。但是随着实时计算引擎的不断发展以及业务对于实时报表的产出需求不断膨胀,业界最近几年就一直聚焦并探索于两个相关的热点问题:实时数仓建设和大数据架构的批流一体建设。实时数仓建设:实时数仓1.0 传统 w397090770 3年前 (2022-02-18) 737℃ 0评论2喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-07-15) 92406℃ 0评论164喜欢
2019年10月22日上午 Databricks 宣布,已经完成了由安德森-霍洛维茨基金(Andreessen Horowitz)牵头的4亿美元F轮融资,参与融资的有微软(Microsoft)、Alkeon Capital Management、贝莱德(BlackRock)、Coatue Management、Dragoneer Investment Group、Geodesic、Green Bay Ventures、New Enterprise Associates、T. Rowe Price和Tiger Global Management。经过这次融资,Databricks 的估值高达62亿美 w397090770 5年前 (2019-10-22) 1119℃ 0评论0喜欢
Spark支持三种模式的部署:YARN、Standalone以及Mesos。本篇说到的Worker只有在Standalone模式下才有。Worker节点是Spark的工作节点,用于执行提交的作业。我们先从Worker节点的启动开始介绍。 Spark中Worker的启动有多种方式,但是最终调用的都是org.apache.spark.deploy.worker.Worker类,启动Worker节点的时候可以传很多的参数:内存、核、工作 w397090770 10年前 (2014-10-08) 11335℃ 3评论7喜欢
本程序实际上是构建了一颗二叉排序树,程序最后输出构建数的中序遍历。代码实现:[code lang="CPP"]#include <stdio.h>#include <stdlib.h>// Author: 过往记忆// Email: wyphao.2007@163.com// Blog: typedef int DataType; typedef struct BTree{ DataType data; struct BTree *Tleft; struct BTree *Tright; }*BTree;BTree CreateTree(); BTree insert(BTree root, DataTy w397090770 12年前 (2013-04-04) 3076℃ 0评论1喜欢
闲来无事,于是把常用的排序算法自己写了一遍,也当做是复习一下。[code lang="CPP"]/*************************************************************** * * * * * Date : 2012. 05. 03 * * Author : 397090770 * * Email : wyphao.2007@163.com * * * * * *************************** w397090770 12年前 (2013-04-04) 3020℃ 0评论3喜欢
在Debian平台,请输入以下的命令[code lang="JAVA"]$ sudo vi /etc/apt/sources.list[/code]在里面加入下面的一行[code lang="JAVA"]deb http://ftp.us.debian.org/debian/ squeeze main non-free[/code]然后保存退出(:wq)之后,执行下面的命令[code lang="JAVA"]$ sudo apt-get update[/code]安装Java执行环境运行下面命令[code lang="JAVA"]$ sudo apt-get install sun-java6-jre[/ w397090770 11年前 (2013-10-21) 6163℃ 2评论3喜欢
With MongoDB 3.6 the query language gains a new level of expressivity: you can now make use of aggregation expressions in a query using the $expr operator. This feature allows you to take full advantage of all expression operators within all queries, much of which previously had to be done within application logic or was restricted to the aggregation pipeline. $expr offers better performance than the $where operator, which while still a w397090770 3年前 (2021-04-27) 2321℃ 0评论2喜欢
Uber 致力于在全球市场上提供更安全,更可靠的运输服务。为了实现这一目标,Uber 在很大程度上依赖于数据驱动的决策,从预测高流量事件期间骑手的需求到识别和解决我们的驾驶员-合作伙伴注册流程中的瓶颈。自2014年以来,Uber 一直致力于开发大数据解决方案,确保数据可靠性,可扩展性和易用性;现在 Uber 正专注于提高他们平 w397090770 5年前 (2019-06-06) 3258℃ 0评论8喜欢
Java 8 流的新类 java.util.stream.Collectors 实现了 java.util.stream.Collector 接口,同时又提供了大量的方法对流 ( stream ) 的元素执行 map and reduce 操作,或者统计操作。本章节,我们就来看看那些常用的方法,顺便写几个示例练练手。Collectors.averagingDouble()Collectors.averagingDouble() 方法将流中的所有元素视为 double 类型并计算他们的平均值 w397090770 3年前 (2022-03-31) 175℃ 0评论1喜欢
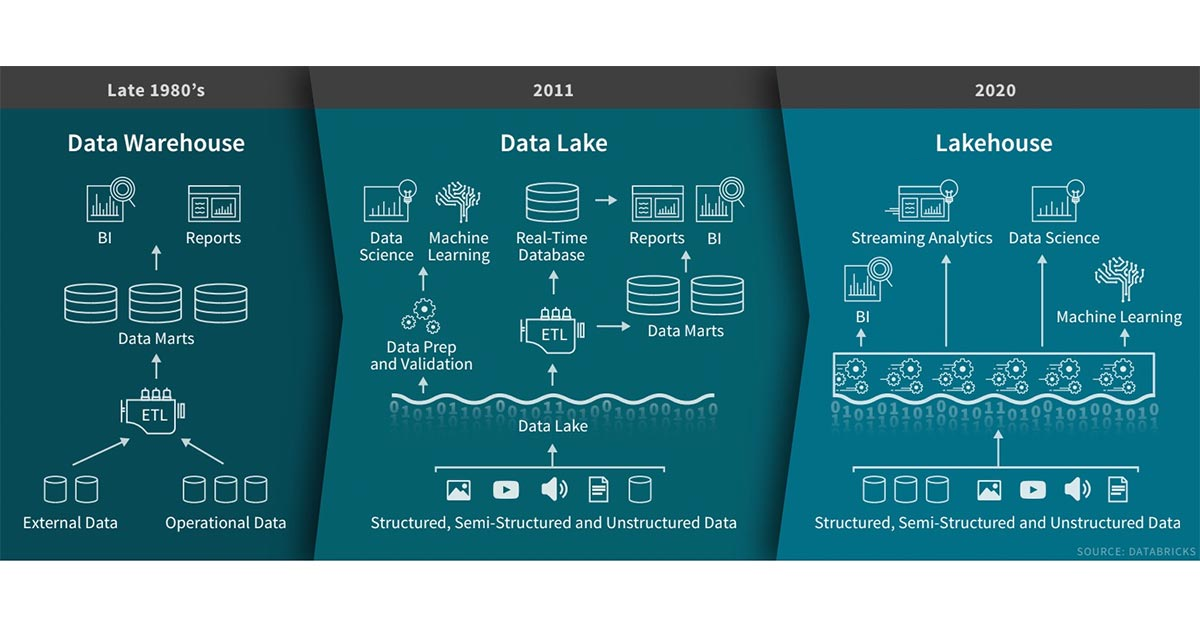
引入在Databricks的过去几年中,我们看到了一种新的数据管理范式,该范式出现在许多客户和案例中:LakeHouse。在这篇文章中,我们将描述这种新范式及其相对于先前方案的优势。数据仓库技术自1980诞生以来一直在发展,其在决策支持和商业智能应用方面拥有悠久的历史,而MPP体系结构使得系统能够处理更大数据量。但是,虽 w397090770 5年前 (2020-02-03) 3002℃ 0评论6喜欢
Elasticsearch提供了近乎实时的数据操作和搜索功能。默认情况下,从你索引/更新/删除你的数据动作开始到它出现在你的搜索结果中,大概会有1秒钟的延迟。这和其它的SQL平台不同,它们的数据在一个事务完成之后就会立即可用。索引/替换文档 我们先前看到,怎样索引一个文档。现在我们再次调用那个命令:[code lan zz~~ 8年前 (2016-09-03) 1578℃ 0评论4喜欢




![[电子书]Mastering Elasticsearch 5.x - Third Edition PDF下载](https://www.iteblog.com/pic/elastic/Mastering_Elasticsearch_5.x-Third_Edition_iteblog.jpg)
![Hadoop: The Definitive Guide, 4th Edition[pdf]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/3.jpg)